
MindSpore社区活动:复现小型CNN模型之SqueezeNet网络——体验贴
SqueezeNet是2016年由DeepScale联合加州大学伯克利分校和斯坦福大学提出的一种轻量级卷积神经网络,其核心设计理念是通过结构化创新实现模型参数的极致压缩,同时保持与AlexNet相当的图像分类精度。该网络最显著的特点是将模型参数量从AlexNet的240MB压缩至4.8MB,结合深度压缩技术后更可降至0.47MB,这种突破性设计使其成为移动端和嵌入式设备部署的标杆模型。网络架构层面
欢迎大家加入MindSpore社区一起玩!
1.SqueezeNet简介
SqueezeNet是2016年由DeepScale联合加州大学伯克利分校和斯坦福大学提出的一种轻量级卷积神经网络,其核心设计理念是通过结构化创新实现模型参数的极致压缩,同时保持与AlexNet相当的图像分类精度。该网络最显著的特点是将模型参数量从AlexNet的240MB压缩至4.8MB,结合深度压缩技术后更可降至0.47MB,这种突破性设计使其成为移动端和嵌入式设备部署的标杆模型。
网络架构层面,SqueezeNet创造性地提出了Fire模块作为基本构建单元。每个Fire模块由Squeeze层和Expand层组成:Squeeze层通过1×1卷积将输入通道数压缩至原尺寸的1/4,形成特征瓶颈层;Expand层则并行使用1×1和3×3卷积进行特征扩展,最终将两组特征图在通道维度拼接。这种设计既保留了多尺度特征提取能力,又通过参数瓶颈机制有效控制了模型复杂度。网络整体采用类似VGG的堆叠式结构,但通过8个Fire模块的级联替代传统卷积层,并在特定位置插入最大池化层实现空间降采样。
技术创新点主要体现在三个方面:首先,用1×1卷积全面替代3×3卷积,理论上可减少9倍参数量;其次,通过Squeeze层主动压缩输入通道数,使后续3×3卷积的参数量进一步降低;最后,采用延迟降采样策略,将下采样操作后移至网络中后段,通过保持高分辨率特征图提升分类精度。这些策略共同作用,使SqueezeNet在ImageNet数据集上达到57.5%的Top-1准确率,仅比AlexNet低0.3%,但参数量却减少50倍。
在工程实现层面,SqueezeNet完全摒弃全连接层,改用全局平均池化进行特征聚合,这一改动使参数分布从全连接层的90%以上骤降至不足2%。网络还引入了Dropout层防止过拟合,并采用ReLU激活函数增强非线性表达能力。值得注意的是,其1.1版本通过缩小初始卷积核尺寸(7×7→3×3)和调整通道数,在保持精度的同时将参数量进一步减少至72万,较1.0版本优化1.7%。
SqueezeNet的推出对轻量化网络设计产生深远影响,其参数压缩策略被后续MobileNet、ShuffleNet等网络借鉴。实际应用中,该网络展现出卓越的迁移学习能力,曾在七类物体识别任务中通过20轮训练达到100%准确率,且推理时间仅需42秒。这种高效性使其不仅适用于图像分类,还可扩展至目标检测、语义分割等任务,成为边缘计算场景下深度学习部署的重要解决方案。
2.训练数据集准备与环境准备
2.1 训练环境准备
克隆实例后,pip安装库环境
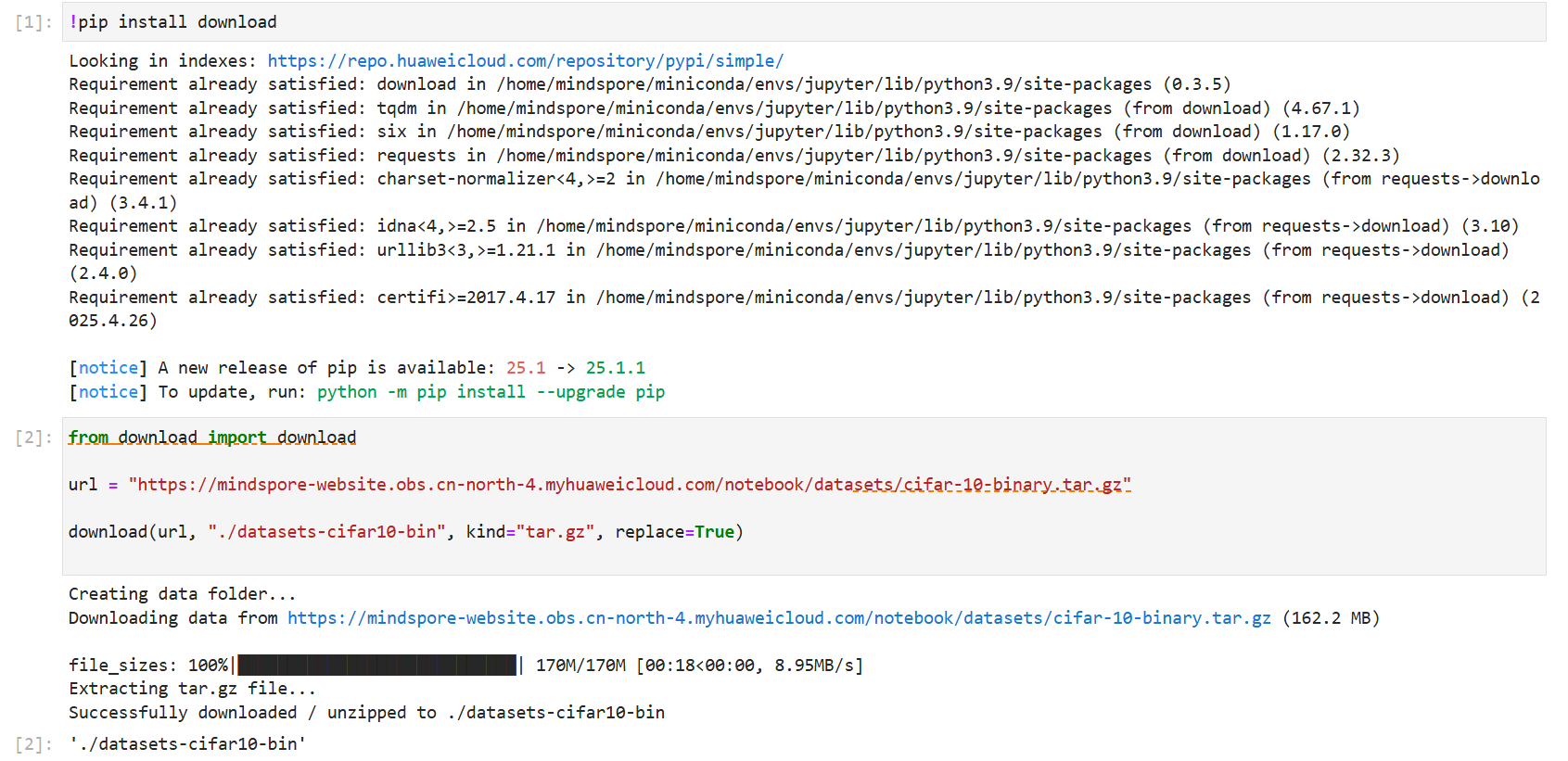
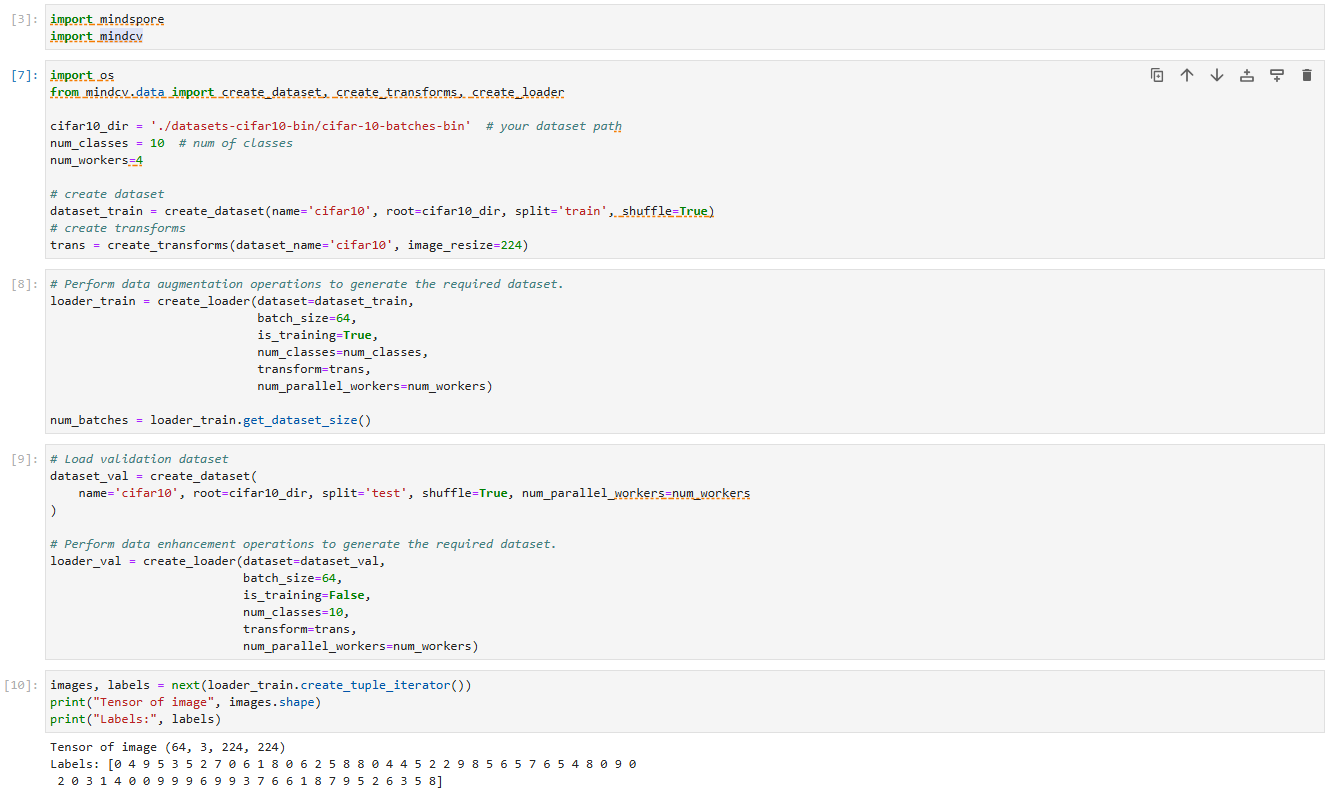
2.2准备数据集
这里使用cifar-10数据集
CIFAR-10数据集是计算机视觉领域中一个标志性的小型图像分类基准数据集,由加拿大高级研究院(CIFAR)的人工智能研究团队于2009年整理发布。该数据集从原始的“8000万张小图”中精选而出,包含60000张32×32像素的RGB彩色图像,共分为10个类别,每类6000张图像,类别涵盖飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车等常见物体。数据集采用分层抽样策略,将50000张图像作为训练集,进一步划分为5个批次(每个批次10000张),剩余10000张作为独立测试集,确保类别分布均衡且测试样本具有代表性。
数据存储方面,CIFAR-10采用二进制格式与NumPy数组结合的方式。每个图像被编码为3072维向量(32×32×3通道),按行优先顺序展开,其中前1024个元素对应红色通道,中间1024个为绿色通道,最后1024个为蓝色通道。图像数据与标签信息通过Python字典结构封装,字典包含‘data’键(存储图像数组)、‘labels’键(存储类别标签)、‘batch_label’键(记录批次名称)及‘filenames’键(存储原始文件名)。这种设计兼顾了存储效率与读取便利性,支持通过pickle等工具快速解析。
在应用场景上,CIFAR-10已成为深度学习模型的“试金石”。其小尺寸图像(32×32)和有限类别数(10类)使其特别适合作为教学案例和算法原型开发平台。研究显示,直接应用线性模型(如Softmax)在该数据集上的准确率不足30%,而卷积神经网络(CNN)可将准确率提升至80%以上,ResNet等先进架构更可达95%以上。数据集还广泛用于迁移学习、模型微调及对比实验,例如通过预训练模型在CIFAR-10上的表现评估其特征提取能力。
数据集获取途径多样,官方网站提供原始二进制文件下载,同时深度学习框架(如PyTorch的torchvision.datasets.CIFAR10和TensorFlow的tf.keras.datasets.cifar10)已内置加载接口。实际使用中,研究者常通过数据增强(随机裁剪、水平翻转等)和归一化预处理提升模型泛化能力。尽管存在分辨率较低、物体占比小等挑战,CIFAR-10仍因其结构清晰、标注准确、使用成本低等优势,持续推动着计算机视觉技术的发展。
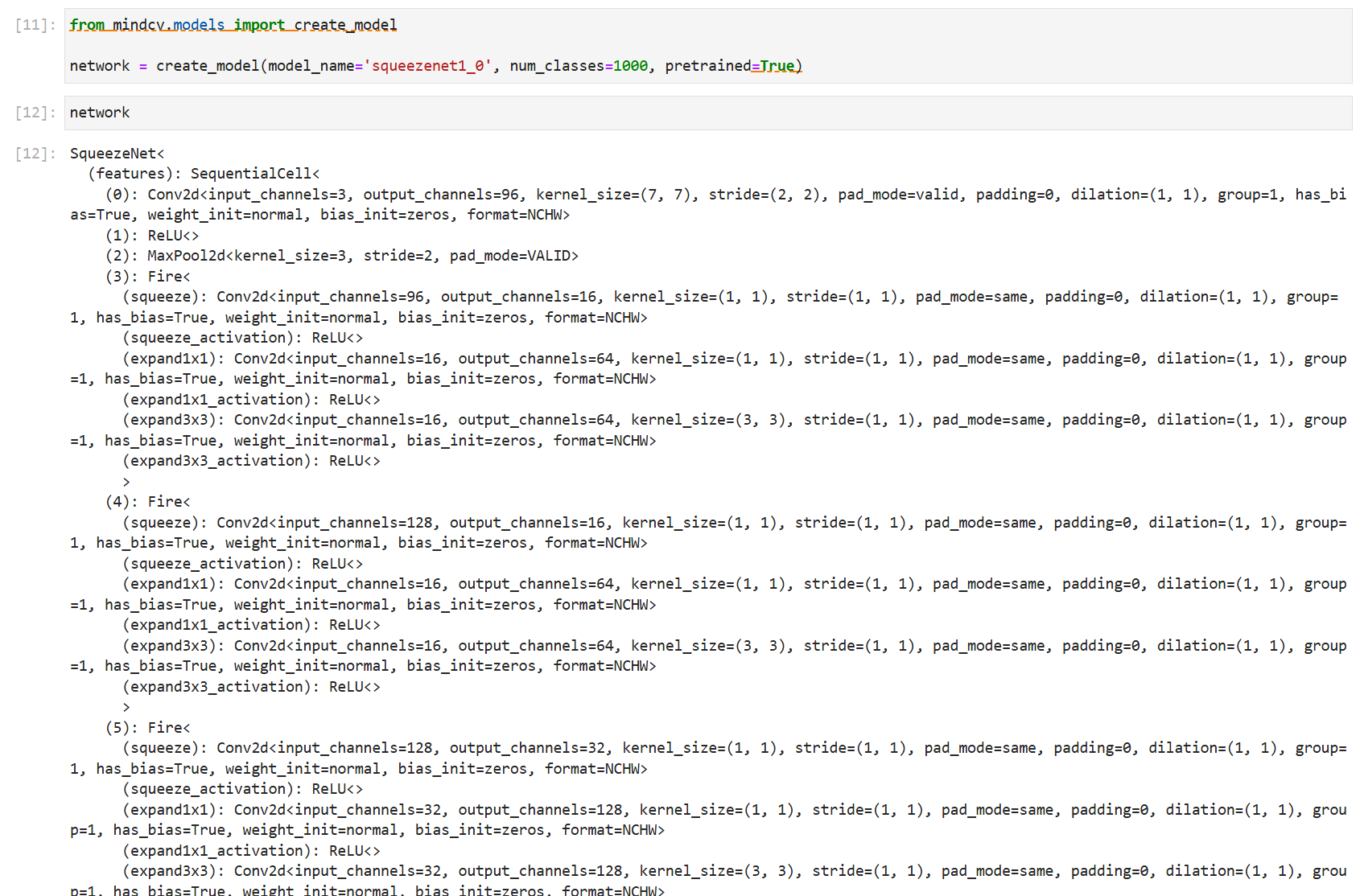
3.模型导入
4.训练评估
4.1 训练
使用下面的代码定义损失函数、优化器、训练参数等设置
代码:
from mindcv.loss import create_loss
loss = create_loss(name='CE')
from mindcv.scheduler import create_scheduler
# learning rate scheduler
lr_scheduler = create_scheduler(steps_per_epoch=num_batches,
warmup_epochs=5,
lr=0.0001)
from mindcv.optim import create_optimizer
# create optimizer
opt = create_optimizer(network.trainable_params(), opt='adam', lr=lr_scheduler)
from mindspore import Model
# Encapsulates examples that can be trained or inferred
model = Model(network, loss_fn=loss, optimizer=opt, metrics={'accuracy'})
from mindspore import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
# Set the callback function for saving network parameters during training.
ckpt_save_dir = './ckpt'
ckpt_config = CheckpointConfig(save_checkpoint_steps=num_batches)
ckpt_cb = ModelCheckpoint(prefix='squeezenet-cifar10',
directory=ckpt_save_dir,
config=ckpt_config)
model.train(50, loader_train, callbacks=[LossMonitor(num_batches//50), TimeMonitor(num_batches//50), ckpt_cb], dataset_sink_mode=False) 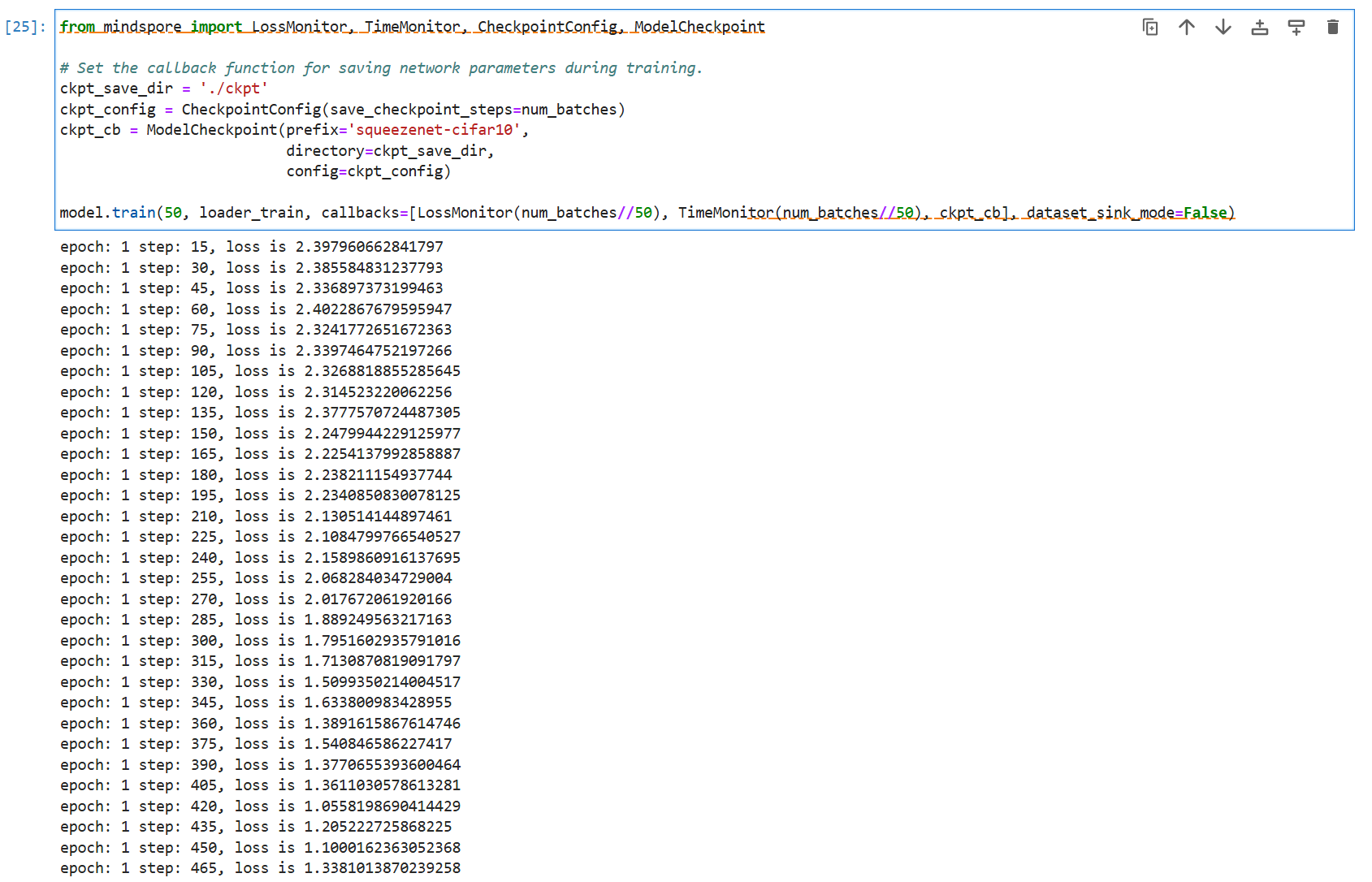
4.2 评估
import matplotlib.pyplot as plt
import mindspore as ms
import numpy as np
import math
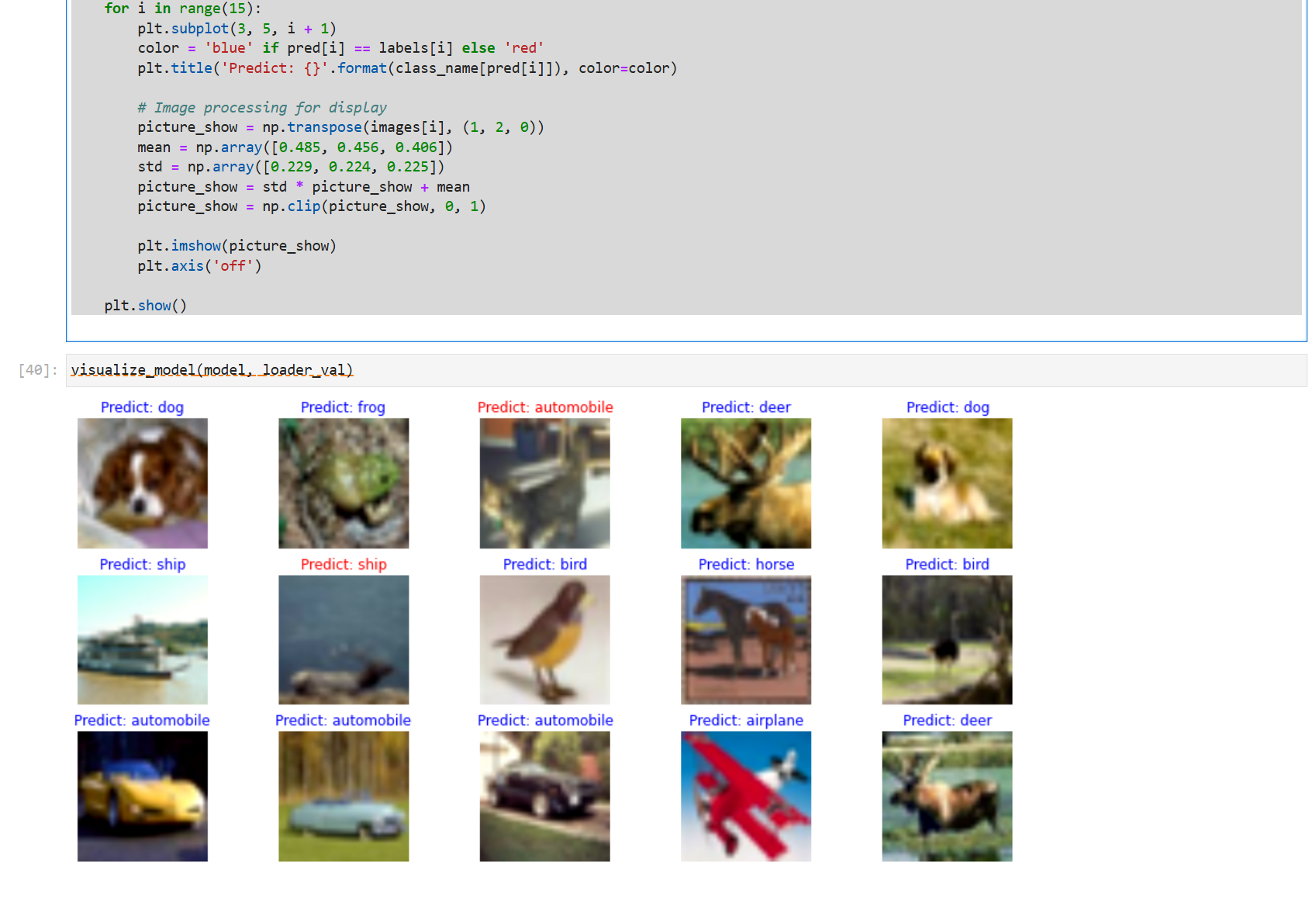
def visualize_model(model, val_dl, num_classes=10):
# Load the data of the validation set for validation
images, labels = next(val_dl.create_tuple_iterator())
# Ensure only 15 images are used
images = images[:15]
labels = labels[:15]
# Predict image class
output = model.predict(images)
pred = np.argmax(output.asnumpy(), axis=1)
# Convert to numpy for visualization
images = images.asnumpy()
labels = labels.asnumpy()
# Define class names
class_name = {
0: "airplane", 1: "automobile", 2: "bird", 3: "cat", 4: "deer",
5: "dog", 6: "frog", 7: "horse", 8: "ship", 9: "truck"
}
# Set up the figure
plt.figure(figsize=(15, 7))
for i in range(15):
plt.subplot(3, 5, i + 1)
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('Predict: {}'.format(class_name[pred[i]]), color=color)
# Image processing for display
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 29
29 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)