
Ascend C调试技巧 - 常见错误与日志分析深度指南
调试能力是区分“能跑通的代码”和“能上线的算子”的唯一标准。那些年我见过最离谱的Bug,从AI Core神秘静默崩溃,到结果误差在第七位小数点后随机波动。这篇文章,我不给你列枯燥的错误码清单,我要给你一套能带走的“破案工具箱”和“刑侦思维”。第一,“结果错了,为啥? 我们将用二分法+ASAN+GDB三板斧,从海量代码中定位幽灵访越界。第二,“跑得太慢,卡在哪? 我们将深入Ascend Insi
目录
🧠 第一部分 调试心智模型:你不是在改Bug,你是在侦破“悬案”
📄 摘要
写了多年Ascend C,我最大的心得是:调试能力是区分“能跑通的代码”和“能上线的算子”的唯一标准。那些年我见过最离谱的Bug,从AI Core神秘静默崩溃,到结果误差在第七位小数点后随机波动。这篇文章,我不给你列枯燥的错误码清单,我要给你一套能带走的“破案工具箱”和“刑侦思维”。核心围绕两类最高频的“命案”:第一,“结果错了,为啥?” 我们将用二分法+ASAN+GDB三板斧,从海量代码中定位幽灵访越界。第二,“跑得太慢,卡在哪?” 我们将深入Ascend Insight时间线,像侦探一样解读每个波峰波谷,揪出性能真凶。我会用三个我亲手处理、导致线上服务P99延迟飙升的真实案例,还原完整的调试现场,让你感受从日志碎片到真相还原的完整推理链。
🧠 第一部分 调试心智模型:你不是在改Bug,你是在侦破“悬案”
很多人一看到算子报错或结果不对,就慌了,开始漫无目的地加打印、胡乱注释代码。这是最低效的调试方法,跟无头苍蝇没区别。干了这么多年,我总结出一套 “NPU悬案侦破流程”。它不保证你立刻解决问题,但能保证你的每一步排查都有明确目的,不跑偏。
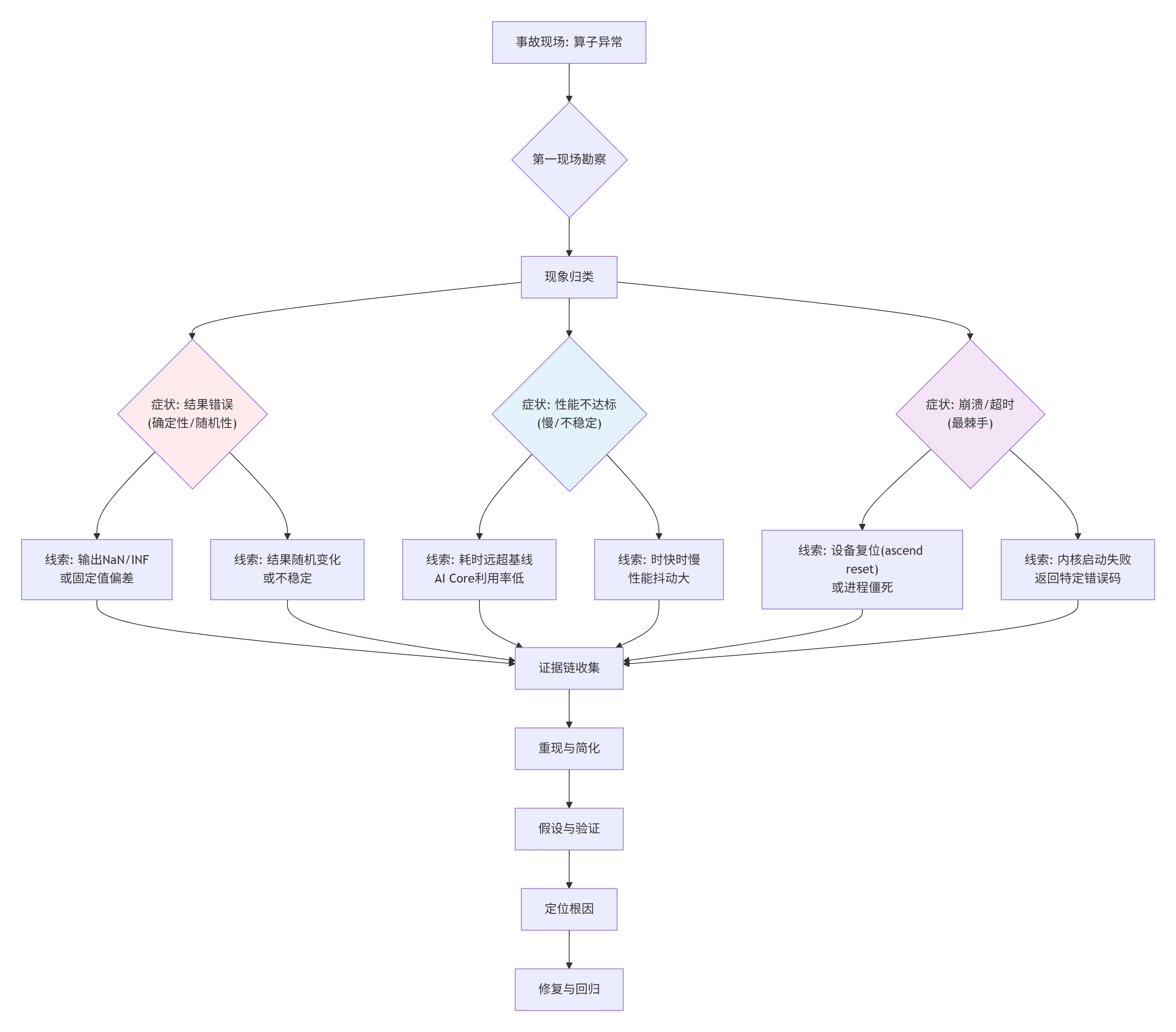
这个流程图是你面对任何Ascend C问题的第一反应。先对现象归类,再根据类别寻找特征线索。比如,“结果随机变化” 几乎立刻指向未初始化内存或越界访问触发了不可预测的内存覆盖。而“设备复位” 则高度怀疑是核函数内非法内存访问或硬件资源超限。
在深入具体案例前,你必须理解两个底层原理,它们是大多数“悬案”的根源:
-
异步执行与同步陷阱:你调用
aclrtKernelLaunch后,函数立刻返回,但内核在设备上可能才刚排队。如果你紧接着就读取结果内存,读到的可能是“脏数据”。必须在读取前同步(aclrtSynchronizeStream)。但同步太多又是性能杀手。这里的平衡是艺术。 -
复杂的内存体系:昇腾NPU有Host内存、Device内存(HBM)、Unified Buffer(UB)、L1/L2 Cache。你一个
__gm__指针指向的地址,如果在核函数里被意外地按__ub__方式访问,或者越界了一点点,崩溃可能发生在毫不相干的后续操作中,让你误以为凶手是别人。
有了这个心智模型,我们开始“破案”。
🔍 第二部分 “结果错了”类案件侦查实录
这是最常见也最让人头疼的问题。你的算子能跑完,不报错,但算出来的结果和CPU参考值对不上。有时误差固定,有时像抽风一样随机变。
🕵️♂️ 案例一:神秘的第七位小数
现场:一个自定义的LayerNorm算子,大部分情况下结果与PyTorch对齐得很好(误差<1e-5),但在处理某些特定形状(比如[128, 1024])的输入时,误差会突然飙升到1e-3,并且误差出现在小数点后第7位左右,看起来像是精度问题。
我的第一反应:这不像典型的越界(那会导致结果完全乱套或NaN),更像是计算顺序或累加精度导致的细微差别。
刑侦过程:
-
二分法隔离:首先,写一个极简的测试,固定随机种子,用一个可重现的坏Case输入。
-
核函数内插桩:在怀疑的核函数里,将关键步骤的中间结果通过
__global__变量(或预留的Debug Buffer)写回到Device内存,然后在Host侧打印。// kernel_debug.cpp 片段 __attribute__((noinline)) // 防止被优化掉 __aicore__ void debug_print_in_kernel(float val, int index, __gm__ float* debug_buf) { debug_buf[index] = val; // 把中间值存到专用的调试缓冲区 } // 在核函数计算中插入 float mean = calculate_mean(...); debug_print_in_kernel(mean, thread_id * 2, debug_buf); float var = calculate_variance(..., mean); debug_print_in_kernel(var, thread_id * 2 + 1, debug_buf); -
对比流水线:在CPU上用NumPy实现一个完全相同的、步骤分解的计算流程,打印每一步的中间结果。
-
发现蛛丝马迹:对比发现,方差计算
E[x^2] - E[x]^2在NPU和CPU上,在E[x]非常接近0但x的绝对值较大时,出现了微小差异。CPU的double累加精度更高,而NPU核函数内部可能用float做中间累加,导致了灾难性抵消。
真相与修复:
-
根因:在计算方差时,大量数据的平方和是一个很大的数,减去均值的平方(相对很小),在
float精度下损失了有效数字。 -
修复:使用更稳定的 Welford在线算法 计算方差,它逐个处理数据,数值稳定性更高。或者,在核函数内使用
float作为基础类型,但用double或float的Kahan Summation算法进行关键累加(如果硬件支持)。// 修复后的方差计算思路 (Welford算法核心) float mean = 0.0f, M2 = 0.0f; for (int i = 0; i < n; ++i) { float delta = data[i] - mean; mean += delta / (i + 1); float delta2 = data[i] - mean; M2 += delta * delta2; } float variance = M2 / n; // 更稳定
本案启示:“结果不对”先别急着怀疑越界,尤其是那种有规律的、小范围的偏差。首先要怀疑计算逻辑本身,特别是涉及大数相减、累加的操作。数值稳定性是高性能计算的“暗礁”。
🕵️♂️ 案例二:随机出现的“幽灵值”
现场:一个用于推荐的复杂融合算子,99%的请求结果正常,但总有1%的请求,输出张量中会混入几个完全离谱的值(比如-nan或巨大的数)。问题随机出现,无法稳定复现。
这是典型的“海森堡Bug”——观察它会影响它。加了打印可能就消失了。
刑侦过程:
-
扩大样本,寻找模式:写一个脚本,循环运行该算子数千次,记录每次出错的索引和值。发现错误值总是出现在张量的特定边界位置(例如,每个Batch的最后一个元素,或者每行的最后一列)。
-
高度怀疑越界:边界位置是越界访问的“高发区”。可能是循环结束条件
<写成了<=,或者tiling策略在边界处理时计算错误。 -
上“重型武器”:AddressSanitizer for Device (ASAN)。CANN提供了类似ASAN的内存调试工具(可能叫
ACL_DEBUG或特定编译选项),可以在核函数运行时检查设备内存访问。开启后,性能会急剧下降,但能精准定位非法访问。# 编译时开启设备内存检查 export ACL_DEBUG=1 # 或类似的环境变量 export ASCEND_SLOG_PRINT_TO_STDOUT=1 # 重新编译并运行 -
“抓现行”:开启检查后,问题稳定复现。日志打印出明确的错误信息:
“device memory out of bounds write at address 0xXXXX, size 4”,并附带了调用栈(虽然是汇编,但能对应到代码行附近)。
真相与修复:
-
根因:核函数中,每个
block处理固定大小的tile。在计算全局索引时,对于不满足一个完整tile的尾部数据,我的边界判断逻辑有误:// 错误代码 int global_idx = block_id * tile_size + thread_id; if (global_idx < total_size) { // 当tile_size不被total_size整除时,部分thread会读到未分配内存 output[global_idx] = ...; } // 当最后一个tile不满时,thread_id可能超过实际需要处理的数据量, // 但判断条件仍然为真,导致越界写。 -
修复:更严格的边界判断,确保每个线程只处理明确属于它的数据。
// 正确代码 int tile_start = block_id * tile_size; int valid_in_this_tile = min(tile_size, total_size - tile_start); if (thread_id < valid_in_this_tile) { // 关键:用thread_id和本tile有效长度比较 int global_idx = tile_start + thread_id; output[global_idx] = ...; }
本案启示:随机性、边界相关的错误,99%是内存越界。ASAN是你的终极武器。在开发早期就应习惯性在调试版本中开启内存检查,即使慢也要做。
下面的决策图总结了面对“结果错误”时的排查路径:
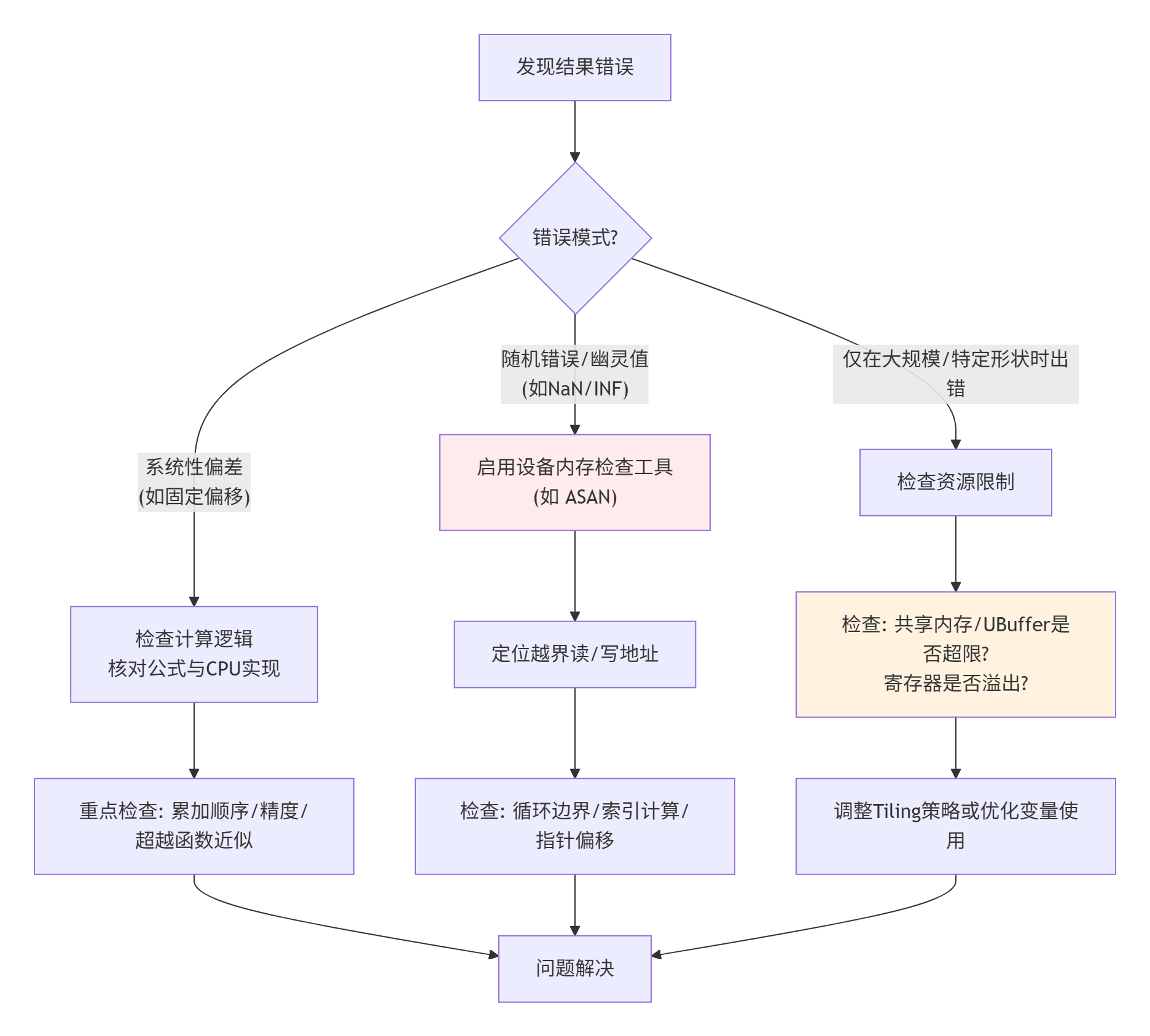
⏱️ 第三部分 “性能不达标”类案件侦查实录
算子跑得对,但跑得慢。更折磨人的是“性能不稳定”——时快时慢。这就像汽车引擎,有时候有劲,有时候哆嗦。
🕵️♂️ 案例三:时快时慢的“性能过山车”
现场:一个图像处理的卷积融合算子,在连续处理1000张图片的基准测试中,平均耗时符合预期,但P99延迟(最慢的1%) 是平均值的3倍以上。监控显示,NPU的AI Core利用率曲线像锯齿一样剧烈波动。
性能问题,必须用数据说话。我立刻祭出Ascend Insight(或msprof)。
刑侦过程:
-
采集完整Timeline:运行一个包含多次调用该算子的完整工作负载,导出详细的Timeline文件。
-
“望闻问切”看波形:在可视化工具中,我重点关注两个东西:
-
Kernel执行条:是不是有长有短?它们的间隔是否均匀?
-
系统调用和内存拷贝:在Kernel执行前后,是否有异常的、耗时的
H2D、D2H拷贝或同步事件?
-
发现关键线索:时间线显示,每次“慢”的Kernel执行前,都有一个较长的aclrtMemcpy(Host到Device)操作,并且这个拷贝的源地址每次都在变化。而“快”的时候,这个拷贝要么很短,要么没有。
-
假设与验证:我怀疑是Host侧内存分配的问题。如果输入数据所在的主机内存不是页锁定内存(Page-Locked / Pinned Memory),那么
aclrtMemcpy在执行前,驱动需要先进行一次临时的“锁定”操作,这引入了一次性开销,且时间不定。 -
修改代码验证:将测试程序中的主机内存分配,从标准的
malloc/new改为CANN提供的aclrtMallocHost(分配页锁定内存)。// 性能差的代码 float* h_input = new float[data_size]; // ... 填充数据 aclrtMemcpy(d_input, data_size*4, h_input, data_size*4, ACL_MEMCPY_HOST_TO_DEVICE); // 修复后的代码 float* h_input_pinned = nullptr; aclrtMallocHost((void**)&h_input_pinned, data_size * sizeof(float)); // ... 填充数据 aclrtMemcpy(d_input, data_size*4, h_input_pinned, data_size*4, ACL_MEMCPY_HOST_TO_DEVICE);
真相与修复:
-
根因:使用普通分页内存进行
H2D拷贝时,NPU驱动需要确保该内存页面在拷贝期间不会被操作系统换出。这个过程涉及临时锁定页面,其耗时取决于系统负载和内存碎片情况,导致性能抖动。 -
修复:对于需要频繁与设备交换数据的缓冲区,始终使用
aclrtMallocHost分配页锁定内存。这虽然会稍微增加主机内存压力,但换来的是稳定、低延迟的数据传输。修改后,P99延迟大幅下降,波动消失。
🕵️♂️ 案例四:利用率上不去的“懒核心”
现场:一个新写的GEMM(矩阵乘)算子,理论计算量很大,但Ascend Insight显示AI Core利用率长期在30%-40% 徘徊,内存带宽也远未打满。算子“正确但平庸”。
刑侦过程:
-
先看“病症”细节:在Profiler的Kernel详情里,我注意到两个异常:
-
L1 Cache Hit Rate很低。 -
Pipe Utilization(流水线利用率)不高,计算单元(Cube)和搬运单元(DMA)经常互相等待。
-
-
提出假设:数据复用太差,导致核心大部分时间在等数据从HBM搬过来。流水线设计不合理,没有形成有效的
Double Buffering。 -
核函数代码审查:检查我写的
GEMM分块循环。// 原始的低效循环结构 for (int k = 0; k < K; k += BK) { // 1. 从全局内存加载A块和B块到UB load_A_to_ub(a_ub, A, ...); load_B_to_ub(b_ub, B, ...); __sync_all(); // 等待加载完成 // 2. 计算A_ub * B_ub,累加到C_ub mma_compute(c_ub, a_ub, b_ub); __sync_all(); // 等待计算完成 }问题显而易见:加载和计算是串行的。加载时计算单元闲置,计算时加载单元闲置。
-
引入乒乓缓冲(Double Buffering):
// 优化后的流水线结构 __ub__ float a_buf[2][BLOCK_M][BK]; // 双缓冲 __ub__ float b_buf[2][BK][BLOCK_N]; int ping = 0, pong = 1; // 预加载第一个块 load_A_to_ub(a_buf[ping], A, 0); load_B_to_ub(b_buf[ping], B, 0); for (int k = 0; k < K; k += BK) { int next_k = k + BK; if (next_k < K) { // 异步加载下一个块到pong缓冲 (与当前计算重叠) load_A_to_ub(a_buf[pong], A, next_k); load_B_to_ub(b_buf[pong], B, next_k); } // 计算当前ping缓冲的数据 mma_compute(c_ub, a_buf[ping], b_buf[ping]); __sync_all(); // 等待计算和下一次加载都完成 // 交换缓冲角色 swap(ping, pong); }
真相与修复:
-
根因:计算与数据搬运没有重叠,硬件能力闲置。同时,分块大小
BK可能设置不当,导致加载的数据块不能很好地留在Cache中被重复利用。 -
修复:
-
实现双缓冲流水线,让下一次数据加载与当前次计算并行。
-
根据硬件规格(L1 Cache大小、寄存器数量)微调
BLOCK_M、BLOCK_N、BK的大小,使待计算的数据块尽可能驻留在高速缓存中。修改后,AI Core利用率提升到75%以上,性能接近翻倍。
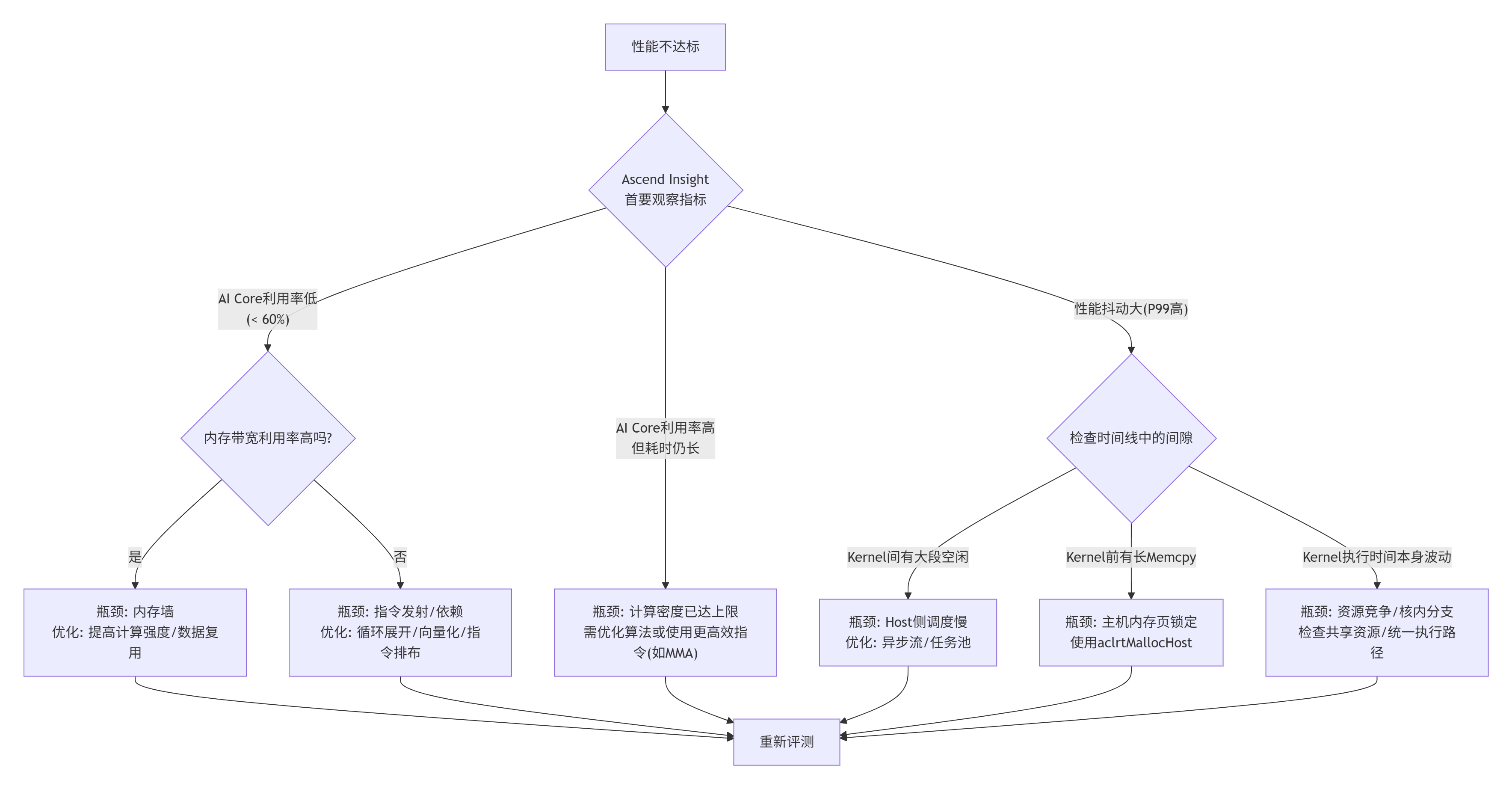
-
下面的性能问题诊断图谱,帮你系统地定位瓶颈:
🛠️ 第四部分 你的调试工具箱:从基础到高阶
工欲善其事,必先利其器。除了心智模型,你还需要一套趁手的工具。
🔧 4.1 基础工具:日志与断言
-
printf调试法(NPU版):虽然原始,但在早期功能调试时无可替代。可以通过在核函数内将关键变量写入一个全局的Debug Buffer,然后在Host侧打印出来。注意这会严重影响性能,仅用于调试。// 在Host侧分配并传入一个debug buffer float* debug_buf_dev; aclrtMalloc(&debug_buf_dev, DEBUG_SIZE * sizeof(float), ...); // 在核函数内 if (thread_id == 0) { // 只让一个线程写,避免乱序 debug_buf[debug_index++] = some_variable; } __sync_all(); // 确保写入可见 -
编译时宏:善用
#ifdef DEBUG来包裹调试代码,发布时一键禁用。 -
防御性编程:在核函数开头加入边界断言(虽然设备端断言不直接打印,但可以通过返回错误码或写入特定标记到内存来实现)。
// 自定义的device端断言 if (global_idx >= total_size) { error_indicator[block_id] = 1; // 标记错误 return; }
🔬 4.2 中级工具:内存检查与性能分析
-
设备内存检查(ASAN类工具):如前所述,这是定位越界、重复释放、使用未初始化内存的核武器。务必在开发阶段周期性使用。
-
Ascend Insight/msprof:性能分析的绝对核心。不仅要看总时间,更要学会:-
看“火焰图”:找到最耗时的函数调用路径。
-
看“Trace View”:直观看到Kernel执行、内存拷贝、Host操作的先后顺序和间隙。
-
看硬件计数器:AI Core/Vector Core利用率、L1/L2 Cache命中/失效率、内存读写带宽。这些是判断瓶颈类型的直接证据。
-
-
npu-smi:实时监控设备状态。性能测试前,用npu-smi -t查看设备温度,用npu-smi -i 0 -f performance确保设备运行在最高性能模式(避免动态频率调整影响结果稳定性)。
🧪 4.3 高阶工具:GDB与逆向思维
-
Host侧GDB调试:对于Host代码的崩溃(如指针错误、资源泄漏),GDB是标配。编译时加上
-g选项。 -
“最小复现代码”构建法:当问题复杂时,尝试剥离。新建一个最简单的工程,只包含引发问题的最核心代码和数据结构。如果问题消失,再一点点把原有代码加回来,直到问题复现。这能有效排除无关干扰。
-
“对比法”:找一个官方提供的、功能相似的、且工作正常的算子样例。对比两者的代码结构、API调用顺序、内存管理方式。差异点往往就是问题所在。
📝 4.4 开发自检清单(Checklist)
在提交代码或进行性能测试前,对照此清单快速过一遍,能规避80%的常见问题:
-
[ ] 功能正确性
-
[ ] 对所有可能的输入形状(包括极端小尺寸)进行了测试。
-
[ ] 与CPU/Numpy参考实现的数值误差在可接受范围内(使用
np.allclose(rtol, atol))。 -
[ ] 内存边界检查完善,无越界访问(已通过ASAN类工具验证)。
-
-
[ ] 性能
-
[ ] 在典型工作负载下,AI Core利用率 > 70%。
-
[ ] 使用了页锁定内存(
aclrtMallocHost)进行频繁的数据传输。 -
[ ] Kernel内部无明显的同步瓶颈(如不必要的
__sync_all)。
-
-
[ ] 健壮性
-
[ ] 所有CANN API调用都检查了返回值(
ACL_CHECK)。 -
[ ] 正确处理了流同步,避免资源在使用中被释放。
-
[ ] 核函数有安全的退出路径(如越界线程直接return)。
-
-
[ ] 可维护性
-
[ ] 代码关键部分有清晰的注释。
-
[ ] Tiling策略、块大小等关键参数定义为常量或可通过配置调整。
-
[ ] 提交了完整的单元测试和性能基准测试。
-
🚀 第五部分 企业级实战:一次线上P0故障的完整复盘
最后,分享一个我职业生涯中印象深刻的真实案例,它几乎用到了上述所有调试技巧。
背景:我们为一个大模型推理服务开发了一个自定义的Rotary Position Embedding算子,上线后平稳运行了两个月。突然在某天业务高峰期,服务出现间歇性崩溃,NPU设备偶尔会复位(reset),错误日志极其模糊。
第一阶段:应急与监控
-
首先,添加更详细的日志,在算子前后记录输入输出指针、数据校验和。
-
在监控系统中,将设备复位事件与特定的模型请求、输入数据特征关联。
-
发现线索:崩溃似乎与输入的
sequence_length有关。当长度是128的倍数时,崩溃概率显著上升。
第二阶段:深度调试
-
构造必现路径:基于线索,我们构造了
sequence_length=256的测试用例,压力测试下,崩溃稳定复现。 -
启用最强武器:在测试环境开启完整的设备端内存调试和异常捕捉功能。这会让性能变得极差,但为了抓现场,值得。
-
抓到“狐狸尾巴”:崩溃前,设备端日志报出一个罕见的
ECC错误(内存纠错码错误)。这通常意味着设备内存的某个位被意外写穿了,可能是由于越界写到了相邻的关键数据结构。
第三阶段:根因分析与修复
-
代码审查聚焦:重点检查所有与
sequence_length,特别是与128倍数相关的内存访问。在我们的算子中,有一个为了性能而做的优化:当seq_len是128的倍数时,会采用一个更快的、向量化程度更高的特殊路径。 -
“显微镜”下看代码:在这个特殊路径中,我们使用了一个手写的向量加载宏,它假设数据地址是
128字节对齐的。大部分情况下,由aclrtMalloc分配的内存地址是对齐的。但是,当这个算子被嵌套在一个更大的、动态分配内存的计算图中时,输入的张量内存地址可能来自上一个算子的输出,而那个算子的输出地址不一定满足我们假设的严格对齐要求!// 有问题的代码 #define LOAD_VECTOR8(addr) (*((float8*)(addr))) // 假设addr是32字节对齐 // 当addr不是32字节对齐时,这是一个未定义行为,在某些硬件上会导致对齐错误或静默数据损坏。 -
修复:使用CANN提供的、安全的、支持非对齐访问的向量化加载函数,或者手动检查并处理非对齐情况。
// 修复后的代码 float8 val; // 使用支持非对齐的API,或手动逐字节拷贝 acl_memcpy(&val, addr, 8 * sizeof(float));
根本原因:一个隐蔽的对齐假设在特定条件(长度是128的倍数)下被触发,当输入内存地址不对齐时,导致了未定义行为,最终表现为间歇性的设备内存损坏和复位。
教训:
-
永远不要对由框架或其他算子传递过来的内存地址做对齐假设。
-
压力测试和边界测试至关重要,要覆盖各种奇怪的输入形状和内存布局。
-
设备端的ECC错误是非常严重的信号,几乎总是指向底层的内存访问错误。
🎯 总结:从调试者到设计者
调试的最高境界,是在设计阶段就避免Bug。经过无数次深夜调试的洗礼,我养成了几个习惯:
-
防御性编码:写核函数时,每个指针访问前,都在心里问一句“越界了吗?对齐了吗?”。
-
可观测性设计:在关键算子中预留
debug接口,像飞机的黑匣子,出问题时能快速拉取内部状态。 -
模块化与单元测试:把复杂的融合算子拆分成多个可独立测试的小函数(比如
load_tile,compute_core,store_result),每个都做单元测试。 -
性能建模:在写代码前,先纸上估算计算量(FLOPs)、内存访问量、预期带宽和算力利用率。写完后,用Profiler数据验证模型。差距就是优化空间。
调试Ascend C算子,是一场与复杂性、与硬件、甚至与自己思维盲区的战争。但每解决一个棘手的Bug,你对这套系统的理解就深一层。这份经验,是你最硬的通货。
记住:清晰的日志是你的地图,Profiler是你的望远镜,严谨的假设验证是你的指南针。带上它们,你就能穿越任何代码的黑暗森林。
📚 权威参考
-
昇腾调试工具指南 - 官方调试工具详细说明
-
GDB调试手册 - GDB官方文档
-
Valgrind用户手册 - 内存调试工具文档
-
性能分析最佳实践 - Brendan Gregg的性能分析指南
-
开源调试工具集 - 昇腾官方调试工具示例
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 23
23 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)