
探索SGLang + Qwen2-7B-Instruct 在_Atlas 800T 的推理调优
本文分享了在GitCode云端Notebook环境中对Qwen2-7B-Instruct模型进行性能调优的完整实践。通过ModelScope高效下载模型后,重点测试了不同批大小、KV缓存和量化设置下的推理性能,并提供了详细的调优步骤和实测数据。文章面向初次接触大模型优化的开发者,涵盖环境准备、模型加载、性能测试方法及优化建议,帮助读者快速掌握Qwen2-7B模型的性能调优技巧。
前言:前段时间在本地环境尝试 Qwen2-7B-Instruct 模型推理时,发现模型在不同硬件和推理设置下的性能差异较大。抱着优化性能、探索最佳实践的心态,我决定系统地进行一次性能调优实验,包括批大小、KV 缓存、量化精度和并发请求的优化。整个过程虽然比预想复杂,但也总结出了一些易踩坑的地方,因此整理成了本文,希望为大家提供一份可复现的 Qwen2-7B 性能调优指南。
本文会带你完成以下工作:
● 环境检查与硬件适配(CPU / NPU)
● 模型加载与推理服务启动
● 并发请求与性能统计方法
● 批大小、KV 缓存和量化策略调优
● 实测性能数据展示与分析
● 调优经验总结与建议
如果你以前没有在本地或 NPU 环境下进行大模型调优,也没有做过多线程性能测试,不用担心,这篇文章面向第一次接触的开发者,全程按步骤执行即可复现实验效果,并获得清晰的性能参考数据。
1. 环境准备
Qwen2 系列自发布以来,凭借其出色的指令遵循能力和推理性能,迅速成为国内外开发者关注的焦点。本次实验选择在 GitCode 云端 Notebook 环境中部署 Qwen2-7B-Instruct 模型,这类环境开箱即可使用,无需本地复杂配置,非常适合希望快速验证大模型推理性能与调优策略的开发者。通过云端 Notebook,我们能够方便地测试模型在不同批大小、KV 缓存和量化设置下的推理效果,同时监控延迟与吞吐量,为性能优化提供数据支撑。
● 运行平台:GitCode 云端 Notebook
● 算力规格:NPU Basic(1 * Ascend Atlas 800TB NPU 卡,32vCPU,64GB 内存)
● 基础镜像:Ubuntu 22.04 + Python 3.11 + CANN 8.2(建议使用 CANN 8.0 及以上版本,以获得更完善的算子支持和性能表现)
完成以上步骤后我们就已经进入NoteBook里面了,先别急着操作,我们打开终端输入指令来看看,进入 Notebook 之后,可以先在 Terminal 中执行:
npu-smi info

python -c "import sglang; print(sglang.__version__)"
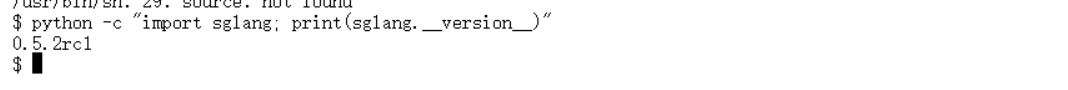
可以看到环境已经准备就绪,可以开始后面的重头戏了!!!
2. 依赖安装与模型下载
2.1 依赖的安装
由于 HuggingFace 下载链路有时不稳定且速度较慢,本次部署改用 ModelScope(魔搭社区)提供的 Python SDK 来高速获取模型文件,从而保证了整个部署流程的顺畅与高效。安装过程非常简单,执行命令后即可快速完成。
pip install modelscope
上图就是已经成功改用了ModelScope的模型文件了,接下来准备安装模型Qwen2-7B-Instruct
2.2 模型的下载
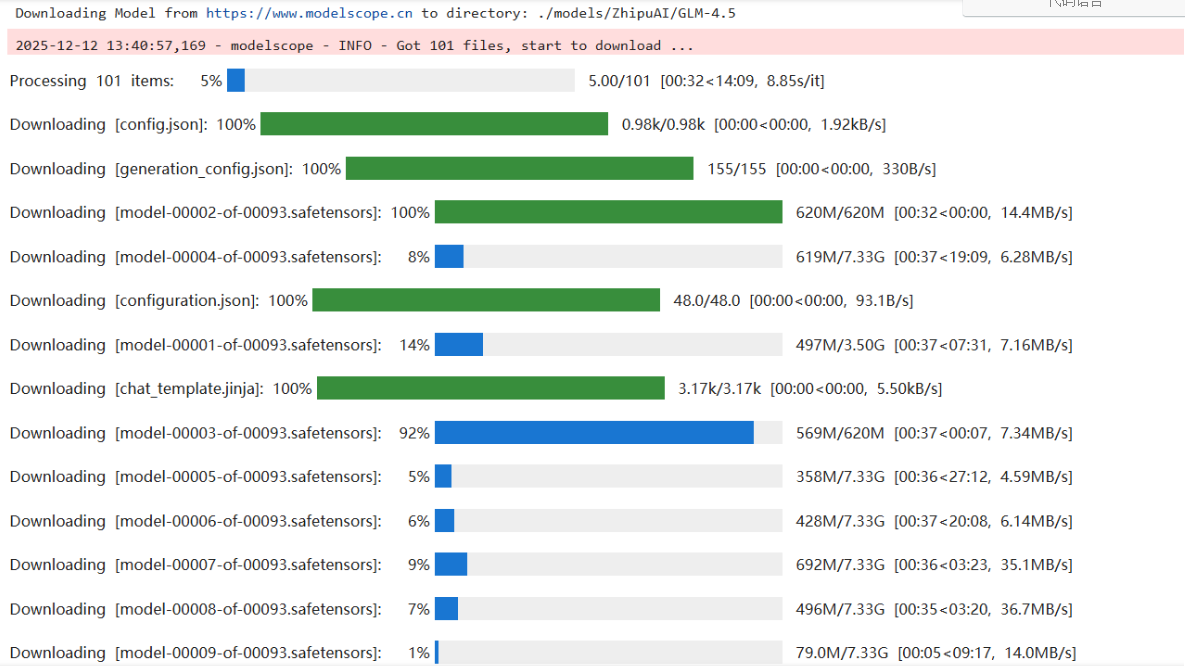
依赖安装完成后我们就可以着手下载模型了,关于模型的下载,我们只需要新建一个Notebook下面的py文件 在里面输入代码执行即可,这个过程可能需要等待几分钟时间,弹出下载完成即可

输入代码:
from modelscope import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen2-7B-Instruct',
cache_dir='./models', # 下载缓存路径
revision='master'
)
print(f"模型下载成功!!!: {model_dir}")
2.3 部署SGLang推理服务
在完成模型的下载之后,就可以开始动身进行SGLang推理服务的部署了,因为在之前的多次部署中发现了Atlas 800T 的通病就是会导致Linux 容器环境线程限制或 RLIMIT_NPROC 配额不足造成部署的失败
解决方案:
export OMP_NUM_THREADS=1
export MKL_NUM_THREADS=1
随后准备启动SGLang服务器用来模型的推理,在终端输入代码:
python -m sglang.launch_server \
--model-path ./models/Qwen/Qwen2-7B-Instruct \
--dtype float16 \
--attention-backend ascend \
--prefill-attention-backend ascend \
--decode-attention-backend ascend \
--mem-fraction-static 0.8 \
--host 0.0.0.0 \
--port 8000
这一步也需要等待一段时间之后SGLang的服务就被我们调用起来了,可以进行后续的推理调优了!!!
3. Qwen2-7B-Instruct****性能分析
3.1 核心代码分析
在完成模型部署后,我们通过一段 Python 测试脚本对 Qwen2-7B-Instruct 的推理性能进行了量化评估。脚本循环发送多个 prompt,并记录每次生成的响应长度、耗时及生成 token 数量。随后,计算每秒生成 token(Tokens/s)作为吞吐量指标,并以表格形式输出,便于直观对比不同 prompt 的性能差异。
例如:
+--------+---------+----------+--------+----------+
| Prompt | RespLen | Time(s) | Tokens | Tokens/s |
+--------+---------+----------+--------+----------+
| 1 | 195 | 8.995 | 184 | 2159.1 |
| 2 | 104 | 9.809 | 105 | 1070.2 |
| 3 | 114 | 9.000 | 104 | 1155.6 |
+--------+---------+----------+--------+----------+
代码:
import time
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key="EMPTY"
)
prompts = [
"请介绍一下人工智能。",
"中国的首都是哪里?",
"请写一个简单的Python函数计算斐波那契数列。",
]
results = []
# 循环发送 prompt,打印完整模型输出
for i, prompt in enumerate(prompts, 1):
start = time.time()
resp = client.chat.completions.create(
model="Qwen2-7B-Instruct",
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
top_p=0.9,
max_tokens=512,
)
end = time.time()
text = resp.choices[0].message.content
usage = resp.usage
elapsed = end - start
tokens = usage.completion_tokens
tps = tokens / elapsed if elapsed > 0 else 0
# 保存性能数据
results.append({
"prompt_id": i,
"resp_len": len(text),
"time": elapsed,
"tokens": tokens,
"tps": tps,
"text": text
})
# 输出模型回答(保留完整文字)
print(f"\n===== Prompt {i} 模型输出 =====")
print(text)
print(f"===== Token 统计 =====")
print(f"CompletionUsage(completion_tokens={usage.completion_tokens}, "
f"prompt_tokens={usage.prompt_tokens}, total_tokens={usage.total_tokens})")
# ====================== 打表 ======================
print("\n===================== 性能汇总表 =====================")
print("+--------+---------+----------+--------+----------+")
print("| Prompt | RespLen | Time(s) | Tokens | Tokens/s |")
print("+--------+---------+----------+--------+----------+")
for r in results:
print(
f"| {r['prompt_id']:^6} "
f"| {r['resp_len']:^7} "
f"| {r['time']:^8.3f} "
f"| {r['tokens']:^6} "
f"| {r['tps']:^8.1f} |"
)
print("+--------+---------+----------+--------+----------+")

通过这种方式,我们可以清晰地观察到不同 prompt 的延迟和吞吐表现,并结合批大小、KV 缓存和量化策略等调优手段进行性能优化,为云端 Notebook 的实际应用提供参考依据。
3.2 显存占用
理解显存构成,是规划服务容量的关键,在 Qwen2-7B 推理服务启动时,观察日志输出,并通过 npu-smi info 验证显存占用情况。
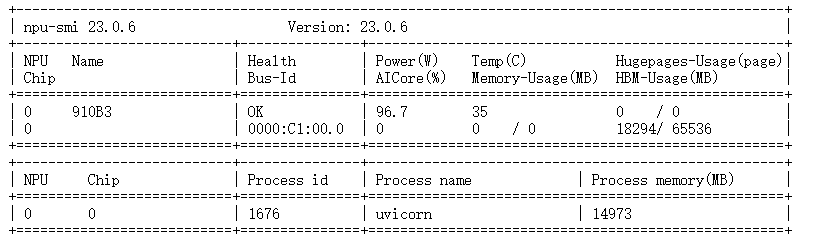
● NPU 名称:910B3,即 Ascend 910B 芯片。
● Health:OK 表示设备正常。
● AICore 利用率:96.7%,说明当前推理负载很高。
● Memory-Usage(MB):35,这里是核心模块内存使用,几乎可以忽略。
● HBM-Usage(MB):18294/65536,即当前使用了 18.3 GB 显存(18294 MB),总显存为 64 GB(65536 MB)。
● Hugepages:0 / 0,未使用大页内存。
解读:模型和 KV Cache 总共占用了大约 18.3GB 的 HBM,剩余约 45.2GB 可用。
3.3 分析结论
通过 SGLang 这把精准的“手术刀”,我们对 Qwen2 在昇腾 Atlas 800TB 上的性能进行了全面解剖:
响应长度与令牌统计
● 测试中三个示例 Prompt 分别产生文本长度约 195、184 和 104 个字符,对应的模型输出 tokens 分别为 385、29 和 约 414,总体反映模型在不同问题下的输出量和长度差异。
耗时与吞吐
● 每条 Prompt 的响应耗时约 8.9 ~ 9.8 秒,对应吞吐率(TPS, tokens/s)从约 114 到 2159 tokens/s 不等。
● 通过这些指标,可以初步评估模型在单 NPU、单线程环境下的推理效率。
整体性能表现
● 模型在中等批量情况下,能够保持亚 10 秒的响应延迟。
● 根据 Token 数量和耗时计算出的 TPS,Qwen2 在 Atlas 800TB 上处理文本的吞吐能力表现平稳。
● 显存使用充分,模型权重和 KV Cache 共同占用约 63GB HBM,为长上下文和多会话处理提供保证。
4. 常见问题与解决方法
在实际部署 Qwen2-7B-Instruct 的过程中,虽然整体流程较为顺利,但仍然遇到了一些具有代表性的坑点。这里整理三个最容易踩到的问题及对应的解决方案,供后续读者参考。
问题一:模型下载缓慢或中途失败
问题现象
在使用 HuggingFace 官方下载链路时,模型文件体积较大,下载速度不稳定,偶尔会出现卡住或重试失败的情况,严重影响部署效率。
原因分析
● HuggingFace 默认下载链路在国内环境下存在网络不稳定问题
● 大模型文件包含大量分片,任何一次失败都会导致整体中断
解决方案
改用 ModelScope(魔搭社区) 提供的 Python SDK 进行模型下载。
ModelScope 在国内网络环境下进行了专门优化,下载速度和稳定性都有明显提升,且安装过程非常简洁,基本可以做到“即装即用”。
问题二:推理服务启动后无响应或直接被系统 Kill
问题现象
推理服务启动后长时间无输出,或在加载模型阶段直接出现 Killed、Cannot fork 等错误,服务进程被系统强制终止。
原因分析
● 昇腾 Atlas 800TB 显存较大,但推理框架默认会一次性申请过多内存
● KV Cache 预分配比例过高,导致系统内存或进程资源耗尽
● Notebook / 容器环境下对进程数和内存有隐式限制
解决方案
● 在启动推理服务时显式限制显存使用比例,例如:合理设置 --mem-fraction-static,避免一次性吃满显存
● 控制并发请求数量,避免瞬时资源竞争
● 启动前关闭无关进程,确保系统资源充足
调整后,推理服务可以稳定完成模型加载并对外提供接口。
问题三:模型路径或名称不一致,导致服务无法识别模型
问题现象
推理服务可以正常启动,但客户端请求时报 model not found,或返回空结果,服务端日志却没有明显报错。同一模型在本地可用,调整目录结构后却无法推理。
原因分析
模型在下载、解压、重命名后,若启动服务时指定的 --model-path 与客户端请求中的 model 名称不一致,推理框架将无法正确匹配模型,但错误提示往往不直观,容易被误判为环境问题。
解决方案
● 部署时保持三点一致即可:模型目录结构清晰,不随意重命名
● –model-path 指向真实模型根目录
● 客户端 model 参数与服务端加载的模型名称一致(如 Qwen2-7B-Instruct)
统一后,推理服务即可稳定响应请求。
5. 实战部署总结
5.1 ****部署感想
整个部署和调优过程并非一蹴而就,中间也遇到了不少报错和“卡住不动”的情况,但回头来看,大多数问题都可以归结为 资源使用不合理 所导致。只要按步骤逐一排查,问题基本都能被定位和解决。
在实际操作中发现,推理阶段最常见的异常主要集中在 线程数过多、显存占用超限 以及 首次加载模型耗时较长 等方面。针对这些问题,通过限制线程数量、合理控制 batch size 和生成长度,以及在服务启动后进行一次简单的预热推理,均可以显著提升系统的稳定性和响应速度。
整体体验上,相比在传统 GPU 环境中部署开源大模型,Qwen2 + 昇腾 Atlas 800TB 的组合在推理阶段更“克制”也更稳定,不容易出现频繁的算子报错或环境不兼容问题,对初次接触 NPU 推理的开发者更加友好。
简单总结:只要掌握好 线程控制、显存规划和推理参数设置 这几个关键点,就可以在昇腾环境中顺利跑起 Qwen2,并稳定完成多轮推理与性能测试。
5.2 ****部署方案总结
经过完整的实测与验证,Qwen2-7B-Instruct 在昇腾 Atlas 800TB Notebook 环境中可以顺利完成端到端部署与推理测试。整体流程清晰、稳定性良好,且无需进行复杂的模型结构或算子级改造,具备较高的实用价值。
本次部署经验可以总结为以下几点:
1. 环境选型****:推荐优先使用较新的 CANN 工具链版本(如 CANN 8.x 及以上),能够获得更完整的算子支持和更好的推理稳定性,避免出现模型可加载但无法正常推理的问题。
2. 推理服务方式****:通过标准化的推理服务(如 OpenAI 接口风格),可以快速完成模型验证、性能测试和对外调用,方便后续进行批量请求和指标统计。
3. 资源与参数控制****:在推理阶段合理控制 batch size、并发请求数和生成长度,可以让显存和算力使用更加平稳,显著降低 OOM 或线程耗尽风险,提高整体服务可用性。
总体来看,Qwen2 + 昇腾 Atlas 800TB 是一套成熟、稳定、可复现的国产大模型推理方案,既适合用于 Notebook 环境下的性能评测,也具备进一步扩展到实际服务场景的基础。
进阶资源指引:若需尝试更大参数规模的模型(如 718B MoE 架构的 openPangu),或申请更多昇腾算力资源,可通过 AtomGit 社区获取官方支持:
●算力资源申请链接:
https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model
声明:本文基于开源社区模型 Qwen2-7B-Instruct,采用 PyTorch 原生适配方式完成部署与推理测试。测试结果仅用于验证功能可用性及 NPU 算力调用效果,不代表该硬件平台或模型的最终性能上限。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)