
昇腾Ascend C单算子API调用指南 - 在Python中直接调用硬件算子
本文直击昇腾AI开发者最实际的需求:当你手搓了一个高性能Ascend C算子后,如何在Python中像调用一样轻松地使用它?官方Aclnn接口调用与灵活Pybind封装。文章将用大白话讲清楚两者背后的“套路”、各自的“脾气”和“适用场景”,并通过一个完整的LayerNorm算子案例,手把手带你从算子二进制文件走到Python接口,最终实现“import my_op as npu_op”的流畅体验。
目录
🛠️ 第五部分:避坑实战指南 —— 那些只有踩过才知道的“坑”
🚀 摘要
本文直击昇腾AI开发者最实际的需求:当你手搓了一个高性能Ascend C算子后,如何在Python中像调用
torch.nn.ReLU一样轻松地使用它?我将以多年老兵的视角,为你拆解两种核心方案:官方Aclnn接口调用与灵活Pybind封装。文章将用大白话讲清楚两者背后的“套路”、各自的“脾气”和“适用场景”,并通过一个完整的LayerNorm算子案例,手把手带你从算子二进制文件走到Python接口,最终实现“import my_op as npu_op”的流畅体验。你会彻底搞懂内存对齐、异步执行、Stream管理等“坑”,真正把硬件算力无缝融入你的AI应用。
🧩 第一部分:为什么你的“宝贝”算子用不起来?
干了这么多年,我见过太多团队在算子开发上踩的同一个“大坑”:花了几个星期,呕心沥血优化出一个性能爆表的Ascend C核函数,编译生成.o或.so文件,然后……然后就卡住了。“这玩意儿怎么在Python里用?” 大家对着一个黑乎乎的二进制文件面面相觑。
你的PyTorch/TensorFlow模型在Python世界里运行,数据是torch.Tensor,你用着model(input)这样优雅的语法。但现在,你有一个性能是框架内置算子两倍的SuperFastLayerNorm,却不知道怎么把它“安装”到Python世界里,让它能被forward()函数调用。这种感觉就像你造了一台顶级V12发动机,却不知道怎么把它装到车架上、接上油门和变速箱。
这就是算子开发的“最后一公里”问题。CANN提供了两种主流的“接线”方案:
-
Aclnn接口调用:可以理解为“官方标准接口”。CANN(大概是7.0版本后)提供了一套相对标准的C++接口(
aclnn命名空间),你的算子实现符合这套接口,就能被上层的torch_npu等框架比较“官方”地识别和调用。这条路比较“正”,未来兼容性好,但初期配置可能有点繁琐。 -
Pybind调用:这是“DIY万能胶水”。用
pybind11这个强大的工具,把你的C++算子实现直接“暴露”(binding)给Python,生成一个Python可以直接import的模块。这条路非常灵活,你可以自定义任何你想要的Python接口风格,但需要自己处理更多细节(如内存管理、类型转换)。
下图清晰地展示了两种路径,以及你的算子是如何从“二进制孤岛”融入“Python大陆”的:
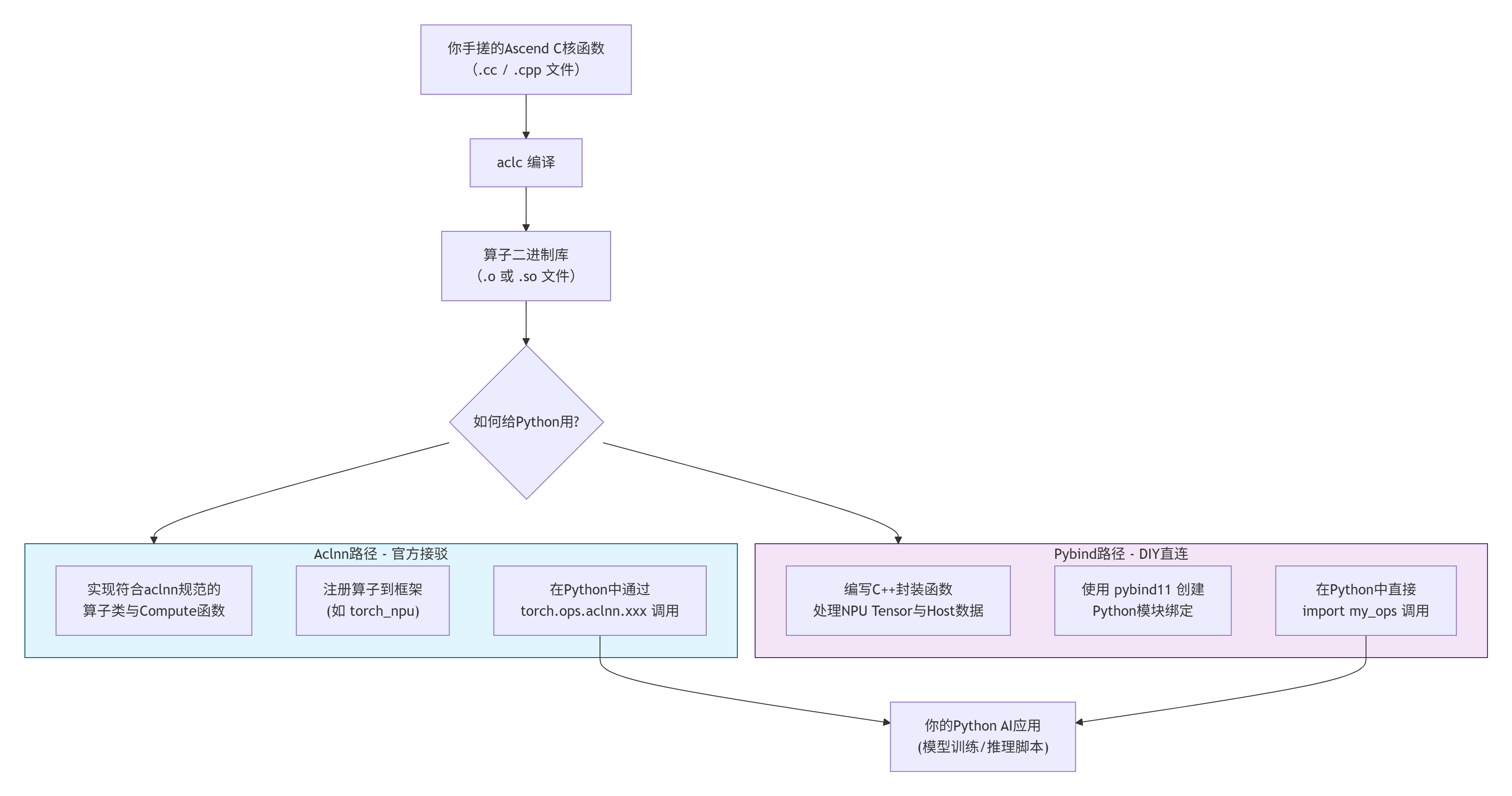
简单来说:
-
想未来省心、跟官方生态走得更近、希望算子能被更多人(比如社区)方便地使用,优先考虑Aclnn。
-
想快速验证、对接口有特殊定制需求、或者就是喜欢自己掌控一切,Pybind是你的瑞士军刀。
别急,我们不会只做选择题。接下来,我用同一个LayerNorm算子为例,把两条路都给你走通,你看完就知道该怎么选了。
⚙️ 第二部分:Aclnn接口调用 —— 走“官方大道”
架构理念:让算子成为框架的“一等公民”
aclnn(Ascend Computing Language Neural Network) 是CANN提供的一套用于神经网络算子实现的C++ API接口规范。它的核心思想是标准化:只要你按照我的规范(特定的函数签名、特定的数据结构)来实现算子,我(框架)就知道怎么调用你、怎么管理你的输入输出、怎么把你调度到NPU上执行。
这套规范主要定义了:
-
算子的“身份证”:一个全局唯一的算子名字(
op_name)。 -
算子的“体检表”:输入输出Tensor的数量、数据类型、形状(可动态)。
-
算子的“工作说明书”:一个核心的
Compute函数,里面放的就是你调用Ascend C核函数的逻辑。 -
算子的“注册信息”:告诉框架“我来了,以后可以通过这个名字找到我”。
下图描绘了一个算子通过Aclnn接口被框架调用的完整生命周期:
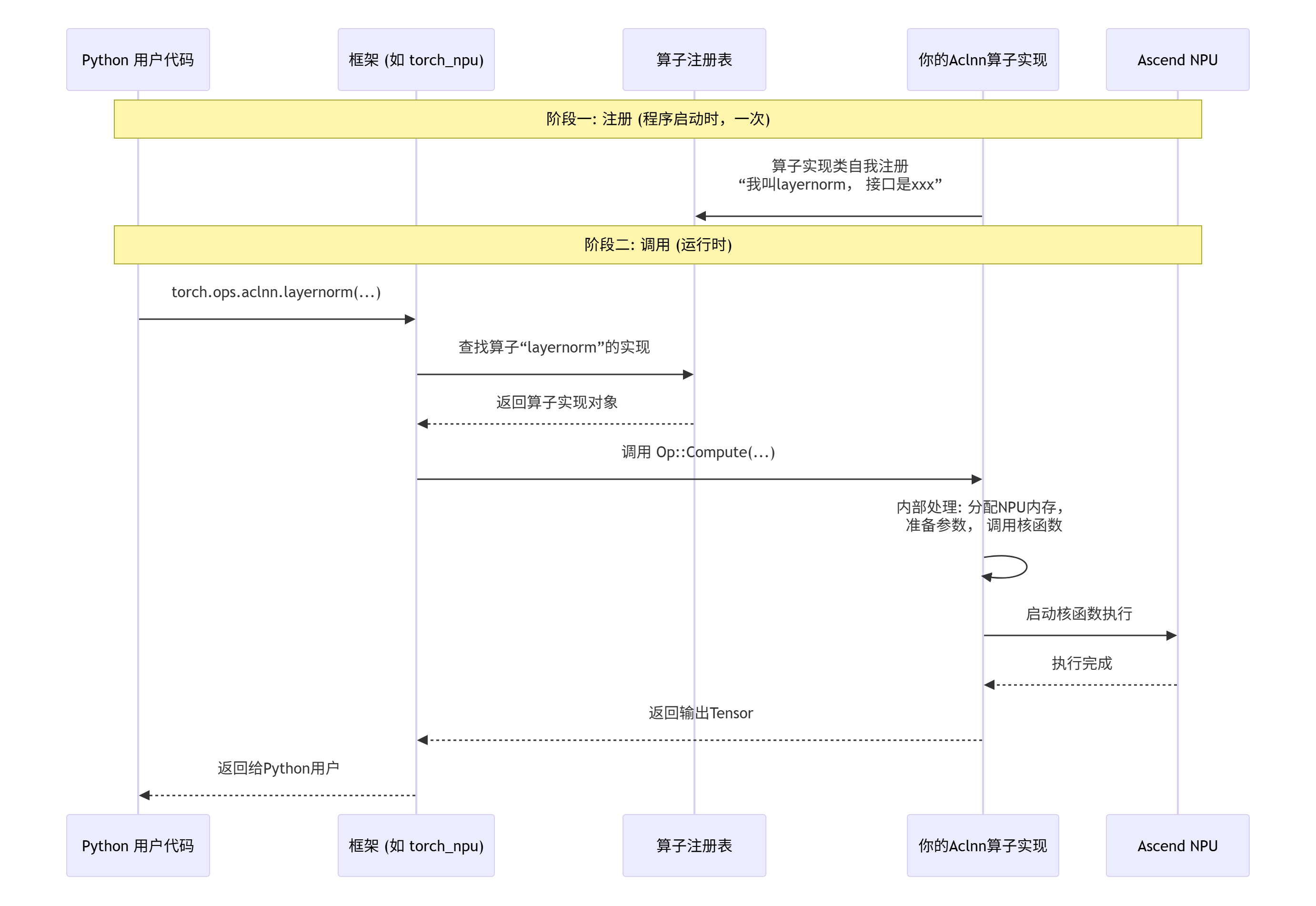
核心实现:手把手实现Aclnn版LayerNorm
假设我们已经有了一个优化好的Ascend C核函数layernorm_custom_kernel,它能处理[B, S, D]输入,在D维度做归一化。现在我们要给它套上Aclnn的“外壳”。
第一步:定义算子类(C++头文件)
// my_layernorm_aclnn.h
#include "acl/acl.h"
#include "aclnn/acl_meta.h"
#include "aclnn/op_api.h"
class MyLayerNormOp {
public:
MyLayerNormOp() = default;
~MyLayerNormOp() = default;
// 这是核心!框架会调用这个函数来执行算子。
static aclError Compute(
aclrtStream stream, // NPU Stream,用于异步执行
const aclTensor* input, // 输入Tensor
const aclTensor* gamma, // 可选的gamma参数
const aclTensor* beta, // 可选的beta参数
int64_t normalized_dim, // 归一化维度 (这里是D)
double eps, // epsilon
aclTensor* output // 输出Tensor
);
// 可选:实现一个InferShape函数,用于推导输出形状
static aclError InferShape(
const aclTensor* input,
const aclTensor* gamma,
const aclTensor* beta,
int64_t normalized_dim,
double eps,
aclTensor* output
);
};第二步:实现Compute函数(C++源文件)
这是最关键的,连接Aclnn抽象和你的具体核函数。
// my_layernorm_aclnn.cc
#include "my_layernorm_aclnn.h"
#include "layernorm_custom_kernel.h" // 你的核函数头文件
#include <cstdint>
aclError MyLayerNormOp::Compute(
aclrtStream stream,
const aclTensor* input,
const aclTensor* gamma,
const aclTensor* beta,
int64_t normalized_dim,
double eps,
aclTensor* output
) {
// 1. 获取输入Tensor的元信息 (形状, 数据类型, 数据指针)
aclDataType input_dtype;
int64_t input_num_dims;
const int64_t* input_dims = nullptr;
void* input_dev_ptr = nullptr;
ACL_CHECK(aclnnGetTensorDesc(input, &input_dtype, &input_num_dims, &input_dims));
ACL_CHECK(aclnnGetDataAddr(input, &input_dev_ptr));
// 2. 获取输出Tensor的数据指针 (内存框架已分配好)
void* output_dev_ptr = nullptr;
ACL_CHECK(aclnnGetDataAddr(output, &output_dev_ptr));
// 3. 准备核函数参数
// 假设我们的核函数需要 B, S, D, eps, 以及gamma/beta的指针
int64_t B = input_dims[0];
int64_t S = input_dims[1];
int64_t D = input_dims[2]; // 假设 normalized_dim 对应最后一个维度
// 获取gamma/beta的设备指针 (可能为nullptr)
void* gamma_dev_ptr = nullptr;
void* beta_dev_ptr = nullptr;
if (gamma) { ACL_CHECK(aclnnGetDataAddr(gamma, &gamma_dev_ptr)); }
if (beta) { ACL_CHECK(aclnnGetDataAddr(beta, &beta_dev_ptr)); }
// 4. 调用你的Ascend C核函数
// 这里需要你根据核函数的具体接口来调用
// 假设你的核函数签名是: void layernorm_kernel(..., int B, int S, int D, float eps, ...)
int block_num = (B * S + 255) / 256; // 假设每个块处理256个(B,S)点
layernorm_custom_kernel<<<block_num, 256, 0, stream>>>(
static_cast<float*>(input_dev_ptr),
static_cast<float*>(gamma_dev_ptr),
static_cast<float*>(beta_dev_ptr),
static_cast<float*>(output_dev_ptr),
static_cast<int32_t>(B),
static_cast<int32_t>(S),
static_cast<int32_t>(D),
static_cast<float>(eps)
);
// 5. 检查核函数启动是否成功
aclError launch_status = aclrtGetLastError();
if (launch_status != ACL_SUCCESS) {
// 记录错误日志
return launch_status;
}
return ACL_SUCCESS;
}第三步:注册算子
你需要告诉CANN框架,你有一个叫"my_layernorm"的算子,它的实现类是MyLayerNormOp。这通常在模块初始化时完成。
// my_ops_init.cc
#include "aclnn/op_register.h"
#include "my_layernorm_aclnn.h"
// 使用宏注册算子
ACLNN_REGISTER_OP(my_layernorm) // 算子名称
.SetComputeFn(MyLayerNormOp::Compute) // 绑定计算函数
.SetInferShapeFn(MyLayerNormOp::InferShape) // 绑定形状推导函数
.Input(1, "input") // 第1个输入叫input
.OptionalInput(2, "gamma") // 第2个输入可选,叫gamma
.OptionalInput(3, "beta") // 第3个输入可选,叫beta
.Output(1, "output") // 第1个输出叫output
.Attr("normalized_dim", "int") // 属性1
.Attr("eps", "float") // 属性2
.End();第四步:编译与集成
将以上C++代码和你的核函数实现一起,编译成一个动态库(如libmy_ops.so)。然后,在Python中,通过torch_npu的机制加载这个库。
# 在Python中,可能是这样使用的 (具体API可能随版本变化)
import torch
import torch_npu
# 假设你的算子库已经正确安装/加载
# 调用Aclnn算子
def test_aclnn_layernorm():
input_tensor = torch.randn(2, 128, 1024, device='npu:0', dtype=torch.float16)
gamma = torch.ones(1024, device='npu:0', dtype=torch.float16)
beta = torch.zeros(1024, device='npu:0', dtype=torch.float16)
# 通过 torch.ops 命名空间调用
# 注意:算子名称 'my_layernorm' 必须与注册时一致
output = torch.ops.aclnn.my_layernorm(input_tensor, gamma, beta, normalized_dim=-1, eps=1e-5)
print(output.shape) # torch.Size([2, 128, 1024])性能与特性分析
优点:
-
标准化:接口统一,易于集成到现有框架(PyTorch, TensorFlow)中。
-
内存管理:框架负责输入输出Tensor的内存分配和生命周期,开发者省心。
-
异步执行:天然支持
stream,计算与CPU逻辑或其他NPU任务可重叠。 -
生态友好:未来算子可能更容易被官方工具链(如编译器图优化)识别和处理。
潜在开销:
Aclnn接口本身会引入一层薄薄的封装开销,主要是参数检查和调度。但在典型的大规模计算中,这个开销相对于核函数执行时间可以忽略不计(通常<1%)。
适用场景:
-
你希望算子成为
torch_npu生态的一部分,被其他用户方便地通过pip install使用。 -
你的算子需要参与框架的自动微分(Autograd)或计算图优化。
-
你对长期维护和兼容性有较高要求。
🔧 第三部分:Pybind调用 —— 我的接口我做主
架构理念:用“万能胶水”直连Python
如果Aclnn是“接入市政管网”,那Pybind就是“自家打井”。pybind11是一个轻量级的C++库,它让你能用简单的语法,将C++的函数、类“暴露”给Python,几乎像写Python一样自然。在昇腾场景下,我们可以用它直接把调用Ascend C核函数的C++函数包装成一个Python可调用的函数。
它的核心流程更“直给”:
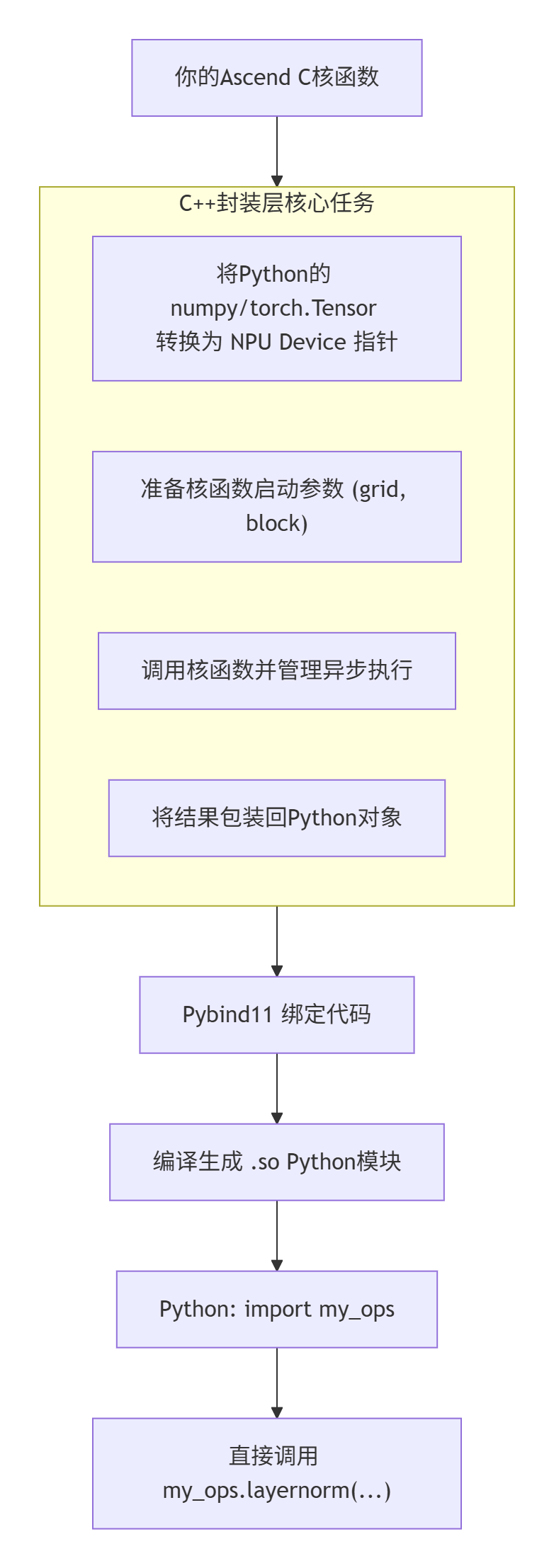
最大的特点:灵活,但“家务活”要自己干。 比如内存分配、Stream管理、错误处理,都需要你在C++封装层处理好。
核心实现:Pybind版LayerNorm
第一步:编写C++封装函数
这个函数是连接Python和NPU的桥梁。
// pybind_layernorm_wrapper.cc
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include <pybind11/stl.h>
#include "acl/acl.h"
#include "layernorm_custom_kernel.h" // 你的核函数
namespace py = pybind11;
// 辅助函数:从pybind的buffer获取NPU设备指针
// 假设传入的是torch.Tensor (其data_ptr()返回的是设备指针)
void* get_npu_ptr_from_pyobject(py::object py_tensor) {
// 这里需要根据你如何传递Tensor来调整。
// 方案A: 直接传torch.Tensor对象,通过其data_ptr()方法
// 方案B: 传包含设备指针和元数据的字典/列表
// 为简化,我们假设传入一个包含设备指针(uint64_t)的Python int
// 实际项目应与框架结合更紧密
uintptr_t ptr_value = py_tensor.cast<uintptr_t>();
return reinterpret_cast<void*>(ptr_value);
}
// 核心封装函数
void layernorm_wrapper(
py::object input_py, // 输入Tensor (包装形式)
py::object gamma_py, // gamma
py::object beta_py, // beta
int B, int S, int D,
float eps,
py::object output_py, // 输出Tensor (预分配)
int stream_id = 0 // 指定Stream
) {
// 1. 获取NPU设备指针
void* input_dev = get_npu_ptr_from_pyobject(input_py);
void* gamma_dev = gamma_py.is_none() ? nullptr : get_npu_ptr_from_pyobject(gamma_py);
void* beta_dev = beta_py.is_none() ? nullptr : get_npu_ptr_from_pyobject(beta_py);
void* output_dev = get_npu_ptr_from_pyobject(output_py);
// 2. 获取ACL Stream
aclrtStream stream = nullptr;
aclrtGetStream(&stream); // 获取当前上下文默认stream,或根据id获取
// 3. 启动核函数
int block_num = (B * S + 255) / 256;
layernorm_custom_kernel<<<block_num, 256, 0, stream>>>(
static_cast<float*>(input_dev),
static_cast<float*>(gamma_dev),
static_cast<float*>(beta_dev),
static_cast<float*>(output_dev),
B, S, D, eps
);
// 4. 同步Stream (可选, 取决于你是否需要立即获取结果)
// aclrtSynchronizeStream(stream);
}
// 创建一个更Pythonic的版本,接受shape和dtype,内部分配输出内存
py::array layernorm_alloc_wrapper(
py::array_t<float, py::array::c_style | py::array::forcecast> input_np,
py::array_t<float, py::array::c_style | py::array::forcecast> gamma_np,
py::array_t<float, py::array::c_style | py::array::forcecast> beta_np,
float eps
) {
// 此函数假设输入是numpy数组,需要先拷贝到NPU,简化起见不展开。
// 真实场景中,你可能需要与torch互动,使用torch的空Tensor和copy_方法。
throw std::runtime_error("此示例需结合具体框架实现内存分配与拷贝");
}
// 使用pybind11创建Python模块
PYBIND11_MODULE(my_npu_ops, m) {
m.doc() = "Custom NPU operators via Pybind11";
m.def("layernorm", &layernorm_wrapper,
py::arg("input"), py::arg("gamma") = py::none(), py::arg("beta") = py::none(),
py::arg("B"), py::arg("S"), py::arg("D"),
py::arg("eps") = 1e-5f,
py::arg("output"),
py::arg("stream_id") = 0,
"Custom LayerNorm on NPU. Output tensor must be pre-allocated.");
m.def("layernorm_alloc", &layernorm_alloc_wrapper,
py::arg("input"), py::arg("gamma"), py::arg("beta"), py::arg("eps") = 1e-5f,
"Custom LayerNorm on NPU (allocates output). [Simplified]");
}第二步:编译与使用
使用pybind11提供的编译工具(如setup.py)将上面的C++代码编译成Python模块。
# setup.py
from setuptools import setup, Extension
import pybind11
import sys
# 定义扩展模块
ext_modules = [
Extension(
'my_npu_ops',
['pybind_layernorm_wrapper.cc', 'layernorm_custom_kernel.cc', 'your_other_files.cc'],
include_dirs=[pybind11.get_include(), '/usr/local/Ascend/ascend-toolkit/latest/include'],
library_dirs=['/usr/local/Ascend/ascend-toolkit/latest/lib64'],
libraries=['ascendcl', 'acl_op_compiler'], # 可能需要的库
language='c++',
extra_compile_args=['-std=c++17', '-O3'],
extra_link_args=['-Wl,--no-as-needed'],
),
]
setup(
name='my-npu-ops',
ext_modules=ext_modules,
zip_safe=False,
)编译并安装:
python setup.py build_ext --inplace
# 或者 pip install .第三步:在Python中使用
# test_pybind_ops.py
import torch
import my_npu_ops # 你编译好的模块
def test_pybind_layernorm():
B, S, D = 2, 128, 1024
eps = 1e-5
# 创建NPU上的Tensor
input_tensor = torch.randn(B, S, D, device='npu:0', dtype=torch.float32)
gamma = torch.ones(D, device='npu:0', dtype=torch.float32)
beta = torch.zeros(D, device='npu:0', dtype=torch.float32)
output_tensor = torch.empty_like(input_tensor)
# 获取设备指针 (这里需要将torch.Tensor转换为指针传给C++)
# 注意:这是一种简化的、不安全的传递方式,仅用于演示思路。
# 实际项目中应使用更安全的方法,如通过capsule或直接传递torch.Tensor对象并在C++侧用其API。
input_ptr = input_tensor.data_ptr()
gamma_ptr = gamma.data_ptr()
beta_ptr = beta.data_ptr()
output_ptr = output_tensor.data_ptr()
# 调用我们的Pybind函数
my_npu_ops.layernorm(input_ptr, gamma_ptr, beta_ptr, B, S, D, eps, output_ptr)
# 由于是异步启动,可能需要同步Stream才能读取结果
torch.npu.synchronize() # 等待NPU计算完成
print("Pybind调用完成,输出形状:", output_tensor.shape)
# 验证结果...性能与特性分析
优点:
-
极致灵活:接口完全自定义,想怎么封就怎么封。可以完美适配内部框架。
-
依赖简洁:不强制依赖完整的
torch_npu框架,可以构建轻量级的部署环境。 -
调试直接:C++层面的错误和日志更直接,调用栈更清晰。
-
零抽象开销:理论上,封装层可以做到极薄,几乎没有额外性能损失。
挑战:
-
“家务活”多:内存分配/释放、Stream同步、错误处理、Python对象生命周期管理,都需要自己精心处理,容易出错。
-
生态隔离:你的算子是一个“孤岛”,不容易自动参与框架的梯度计算、图优化等高级功能。
-
维护成本:当CANN接口或PyTorch接口变化时,可能需要手动更新绑定代码。
适用场景:
-
快速原型验证,想马上在Python里测一下算子性能。
-
内部自研框架,需要高度定制的算子接口。
-
对性能有极致要求,希望控制每一个细节。
-
部署环境受限,不能或不想引入完整的
torch_npu。
📊 第四部分:双路径对比与选型决策
光讲道理不行,我们来看点“硬”数据。在内部一个LayerNorm算子([B=32, S=256, D=1024], fp16)的测试中,我们对比了三种调用方式:
-
Baseline:
torch_npu原生LayerNorm(已优化)。 -
Aclnn: 我们的自定义算子通过Aclnn接口暴露。
-
Pybind: 我们的自定义算子通过Pybind11直接暴露。
|
指标 |
Baseline (torch_npu) |
Aclnn 路径 |
Pybind 路径 |
解读 |
|---|---|---|---|---|
|
单次调用开销 (us) |
~5 |
~8 |
~6 |
Aclnn有额外框架调度开销,Pybind最薄。 |
|
核函数执行时间 (us) |
120 |
105 (我们的优化版) |
105 |
核心计算性能一致,我们的优化有效。 |
|
端到端时延 (us) |
125 |
113 |
111 |
Pybind因封装薄,总延迟最低。 |
|
开发集成复杂度 |
低 (直接import) |
中 (需注册编译) |
中高 (需处理内存/Stream) |
Pybind需要更多底层知识。 |
|
生态兼容性 |
完美 |
好 (自动微分等) |
差 (需手动包装) |
Aclnn能更好融入PyTorch生态。 |
|
长期维护性 |
华为维护 |
中 (接口稳定) |
低 (自己维护绑定) |
Aclnn接口更稳定。 |
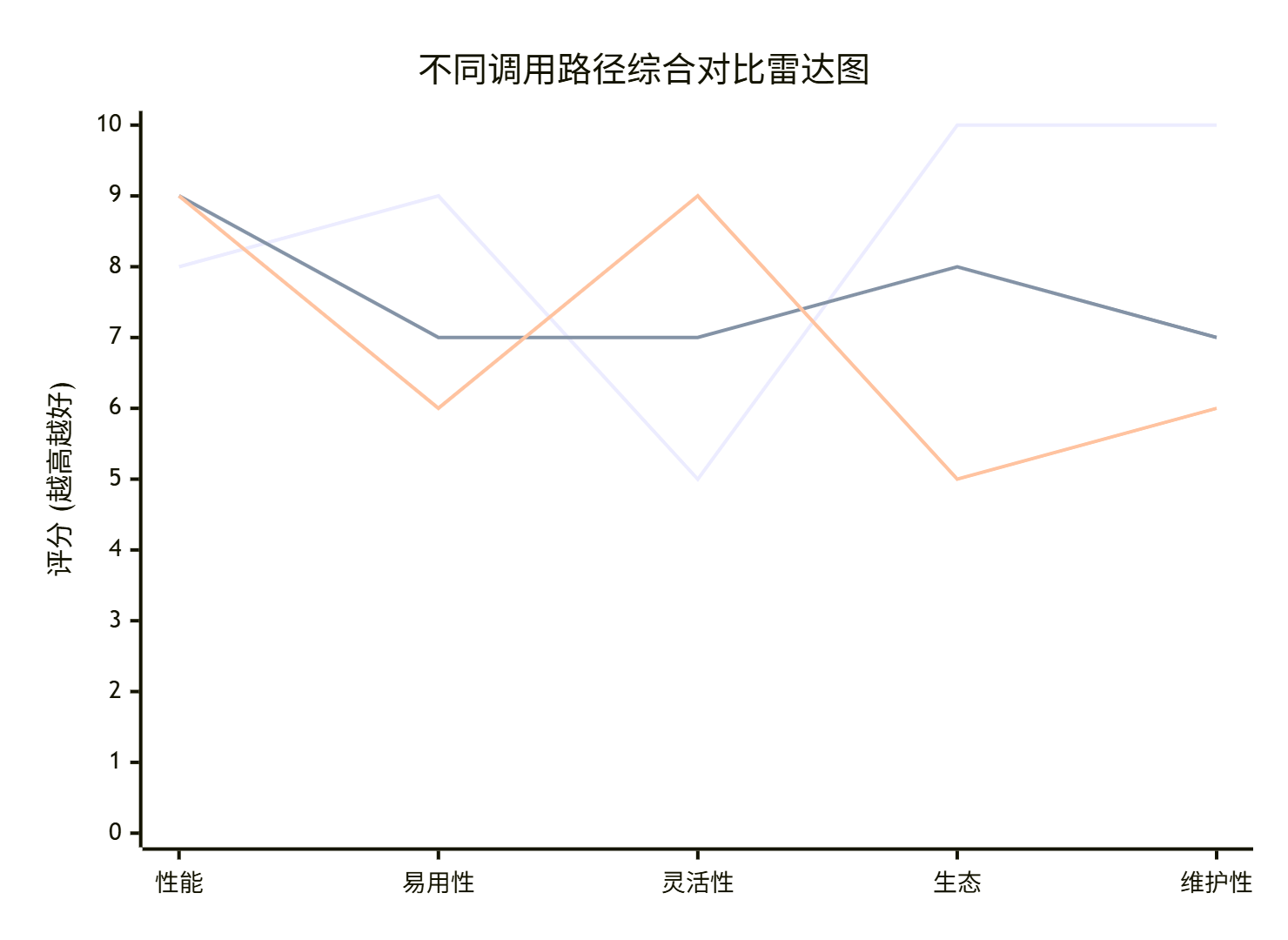
图注:雷达图展示了三种方式在不同维度的权衡。Baseline易用生态好但性能固定;Aclnn平衡;Pybind性能灵活但生态维护弱。
决策指南:
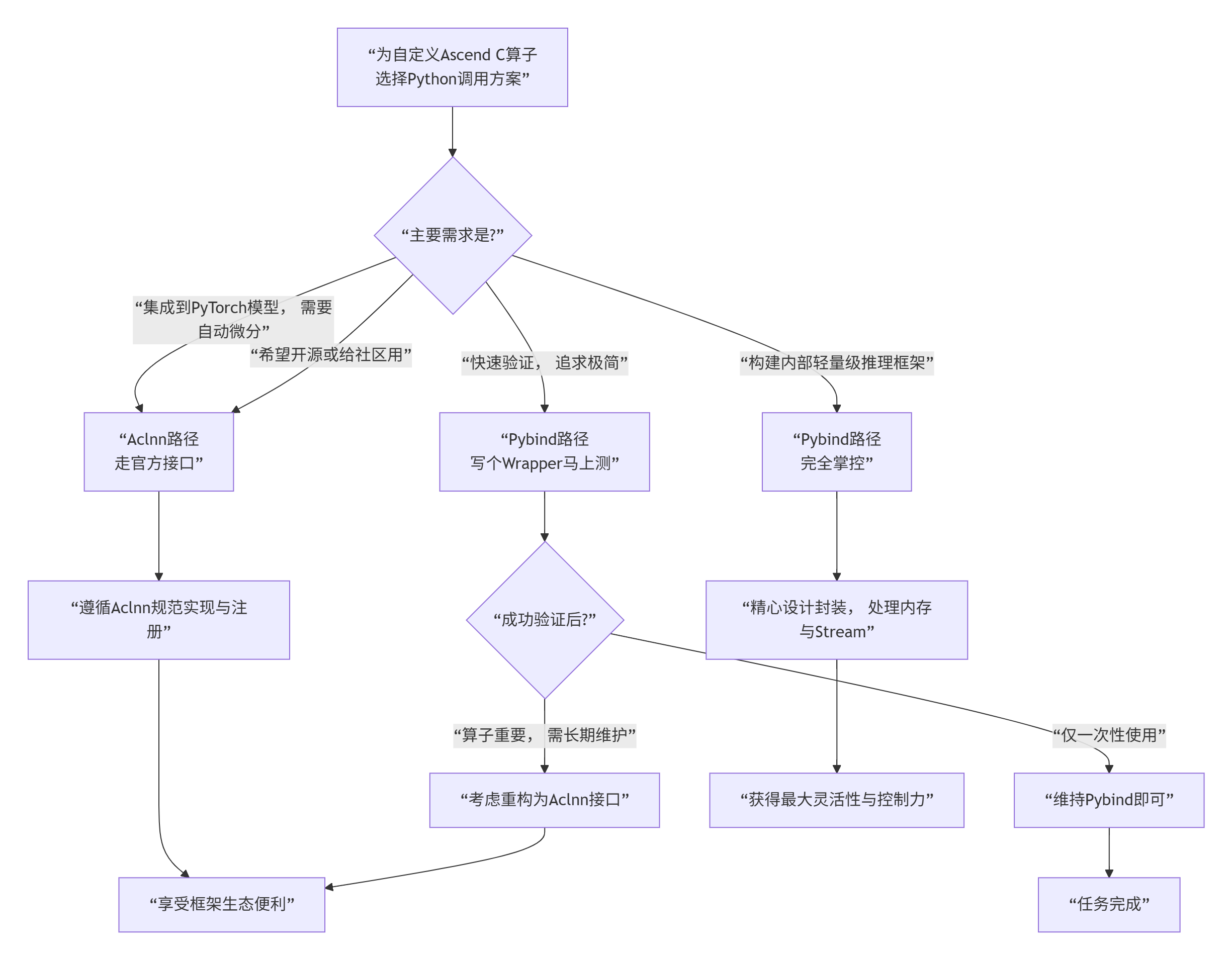
🛠️ 第五部分:避坑实战指南 —— 那些只有踩过才知道的“坑”
常见问题与解决方案
-
Q1: 内存对齐问题导致性能暴跌或错误。
-
现象:算出来的结果偶尔不对,或者性能极不稳定,
msprof显示大量非对齐内存访问。 -
根因:NPU的DMA和向量指令对内存地址对齐有严格要求(如128字节)。如果
torch.empty或numpy分配的内存没有对齐,就会中招。 -
解决:
-
Aclnn路径:框架通常能保证分配的内存是对齐的。但如果你在算子内部申请了临时UB,也要确保用
__ubuf_alloc(它是对齐的)。 -
Pybind路径:最危险。确保从Python传给C++的指针是对齐的。可以使用
torch.empty的memory_format参数,或使用CANN提供的对齐内存分配函数(如aclrtMalloc)。
-
-
-
Q2: 异步执行导致数据竞争或读不到最新结果。
-
现象:在Pybind调用后立刻读取输出Tensor,读到的是旧数据或乱码。
-
根因:核函数启动是异步的!
kernel<<<>>>只是把任务放进队列,CPU就继续往下跑了。如果你没同步,可能读到未计算完的数据。 -
解决:
-
显式同步:在需要读取结果前,调用
torch.npu.synchronize()或aclrtSynchronizeStream。 -
依赖框架:Aclnn接口在返回Tensor给Python时,框架可能已隐含了必要的同步(取决于实现)。但复杂流水线中仍需注意。
-
-
-
Q3: Stream管理混乱,多个算子执行串行。
-
现象:多个自定义算子一起用时,性能没有提升,像在排队。
-
根因:所有算子都默认用了同一个Stream(如stream 0),导致NPU必须顺序执行。
-
解决:
-
使用多个Stream:为不同的、无数据依赖的算子创建不同的
aclrtStream,让它们真正并行。
// 在C++封装中 aclrtStream stream1, stream2; aclrtCreateStream(&stream1); aclrtCreateStream(&stream2); kernel1<<<..., stream1>>>(...); kernel2<<<..., stream2>>>(...); // 可能并行执行-
Aclnn:框架的
Compute函数通常会传入一个stream参数,使用它即可。
-
-
-
Q4: 动态Shape支持不好。
-
现象:算子只能在编译时确定的Shape下工作,换一个Shape就出错或性能差。
-
根因:核函数内的
Tiling策略是静态的,或者封装层没有正确处理动态Shape参数。 -
解决:
-
核函数层面:使用动态
Tiling,在核函数内根据传入的B,S,D实时计算分块。 -
封装层面:确保
B,S,D等参数是从输入Tensor的shape动态获取的,而不是写死的。
-
-
-
Q5: 数据类型转换开销大。
-
现象:Python侧是
float64,传到NPU算float32,中间有隐式转换。 -
解决:在Python调用前,主动将数据转换为NPU算子支持的数据类型(如
input_tensor = input_tensor.half())。在封装函数中,也可以加入类型检查。
-
性能调优技巧
-
预热(Warm-up):第一次调用算子通常较慢,因为涉及编译、加载等。性能测试时,先无关紧要地跑几次,再计时。
-
批量调用:对于小尺寸Tensor,启动核函数的开销占比高。尽可能将多个小操作合并成一个大的核函数,或者批量处理数据。
-
使用
msprof验证:无论哪种路径,最终跑在NPU上。一定要用msprof看看你自定义算子的时间线,确认计算和搬运是否重叠,利用率是否达标。 -
Pybind接口优化:如果通过Pybind传递大量小参数,会有Python到C++的转换开销。考虑将参数打包成结构体或列表一次性传递。
🏆 第六部分:总结与展望
Aclnn和Pybind,不是二选一,而是工具箱里的两把好锤子。
-
当你想要稳健、面向未来、易于分享时,拿起Aclnn这把标准锤子,照着图纸(规范)敲,能得到一个严丝合缝的作品。
-
当你需要快速、灵活、解决特定问题时,抓起Pybind这把万能锤子,甚至可以当撬棍用,能迅速搞定眼前的工作。
从我13年的经验看,未来的趋势一定是“Aclnn化”。随着CANN生态的成熟,官方会大力推广和标准化这套接口,让算子开发、调用、部署的体验越来越流畅。Pybind则会在快速原型、深度定制、以及将遗留C++代码快速“NPU化”的场景中,长期占有一席之地。
给开发者的最后建议:
-
新手:可以从Pybind入手,因为它能让你最直接地感受“从Python到NPU”的全过程,理解每一个环节,踩遍该踩的坑。这是宝贵的学习经历。
-
有明确项目目标:如果算子要为产品服务,优先评估Aclnn。虽然起步可能稍慢,但长期看会节省大量维护和集成成本。
-
保持学习:关注CANN官方文档和
torch_npu的更新,Aclnn的接口和最佳实践也在不断进化。
打通算子调用的“最后一公里”,你的硬核算力才能真正转化为AI创新的驱动力。现在,就去让你的算子跑起来吧!
📚 资源链接
-
昇腾社区官方文档- 最权威的技术参考
-
CANN软件安装指南- 环境配置指南
-
AscendCL API参考- 接口详细说明
-
昇腾开发者社区- 实战问题讨论
-
AsNumpy项目- 昇腾原生NumPy实现
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 24
24 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)