
攻克复杂依赖 - 基于MlaProlog思想设计数据依赖与计算流图
本文深入探讨了基于CANN MlaProlog融合算子的数据依赖分析与计算流图设计方法。通过解构复杂算子中的依赖关系,系统阐述了依赖图构建算法、AscendC同步原语和流水线优化策略等核心技术。文章提出了从依赖分析到高性能实现的完整路径,包括:1)形式化定义流依赖、反依赖和输出依赖三种类型;2)提出计算流图构建的系统方法;3)介绍AscendC中的队列隐式依赖和显式同步原语。通过Transform
目录
2.2 计算流图(Computation Graph)构建算法
步骤2:关键路径分析(Critical Path Analysis)
步骤3:流水线阶段划分(Pipeline Stage Partitioning)
3.1 案例研究:Transformer中的Attention融合
🎯 摘要
本文深度解析基于CANN MlaProlog融合算子的数据依赖分析与计算流图设计方法论。通过解构复杂算子中的依赖关系,系统阐述如何构建高效的计算流图、优化流水线编排、规避数据冲突,并结合实际案例展示从依赖分析到高性能实现的完整路径。文章将涵盖依赖图构建算法、Ascend C同步原语、流水线优化策略等核心技术,并提供可复用的设计框架和调试技巧。
1 🔍 引言:复杂算子中的依赖管理挑战
在AI计算领域,算子融合(Kernel Fusion)已成为提升性能的关键技术。然而,随着融合算子复杂度的增加,内部操作间的数据依赖关系(Data Dependencies)管理变得异常复杂。传统的简单线性流水线难以应对多分支、多汇聚的复杂计算图,而CANN MlaProlog融合算子为我们提供了一个绝佳的研究样本。
1.1 依赖关系的复杂性演进
回顾我多年的高性能计算开发经验,算子内部的依赖管理经历了三个关键阶段:
第一阶段:线性流水(Linear Pipeline)
// 传统的线性融合模式
CopyIn → Compute → CopyOut这种模式下,依赖关系简单明了,但硬件利用率通常不超过40%。
第二阶段:分支流水(Branched Pipeline)
// 具有分支的融合模式
CopyIn → [Compute_A, Compute_B] → Merge → CopyOut多个计算单元并行执行,需要处理分支间的同步问题。
第三阶段:有向无环图(DAG,Directed Acyclic Graph)
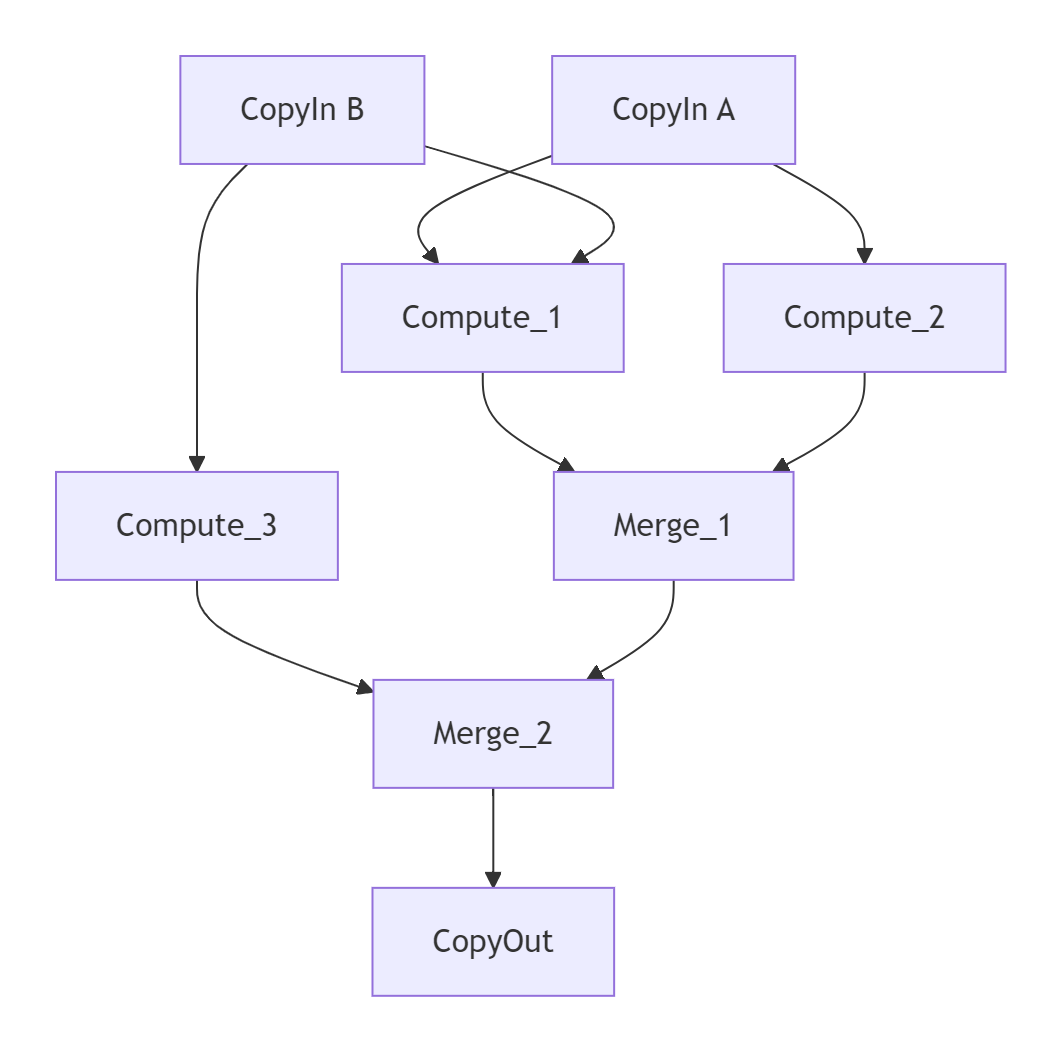
图1:复杂融合算子的DAG依赖关系示意图
MlaProlog算子代表了第三阶段的典型设计,其内部包含多个Cube和Vector操作的复杂依赖网络。如何分析这些依赖、避免数据竞争、最大化并行度,是本文要解决的核心问题。
1.2 依赖管理失败的代价
在我参与的一个早期项目中,由于依赖关系分析不彻底,曾导致严重的性能问题和数据错误:
# 依赖分析错误的典型案例
# 期望: A → B → C
# 实际: A和B并行执行,B需要A的结果 → 数据错误
def problematic_kernel():
task_a = async_compute_a() # 需要100ms
task_b = async_compute_b(task_a.result) # 立即尝试访问结果
# B在A完成前开始执行,访问未初始化的数据这类问题在调试时极其隐蔽,往往在特定输入规模或特定硬件条件下才会暴露。通过本文的方法论,您可以系统性地避免这类问题。
2 📊 技术原理:数据依赖分析与流图设计
2.1 数据依赖类型的形式化定义
在Ascend C融合算子中,数据依赖主要分为三种类型:
1. 流依赖(Flow Dependency / True Dependency)
// 写后读(RAW,Read After Write)
float a = compute_x(); // 写操作
float b = a * 2.0; // 读操作,依赖于a这是最常见的依赖类型,MlaProlog中Cube计算的结果被后续Vector操作使用就是典型例子。
2. 反依赖(Anti-Dependency)
// 读后写(WAR,Write After Read)
float temp = shared_memory[0]; // 读操作
shared_memory[0] = new_value; // 写操作,不能早于读操作在共享内存(Unified Buffer)复用场景中经常出现。
3. 输出依赖(Output Dependency)
// 写后写(WAW,Write After Write)
output[0] = compute_first(); // 第一次写
// ... 中间其他计算 ...
output[0] = compute_second(); // 第二次写,必须保持顺序2.2 计算流图(Computation Graph)构建算法
基于MlaProlog的设计思想,我们提炼出构建计算流图的系统方法:
步骤1:算子分解与依赖识别
class OperatorDependencyAnalyzer:
def __init__(self, operator_sequence):
self.operators = operator_sequence
self.dependencies = []
self.memory_regions = {} # 记录每个内存区域的访问历史
def analyze(self):
"""核心依赖分析算法"""
for i, op in enumerate(self.operators):
# 分析操作的输入输出内存区域
inputs = op.get_input_regions()
outputs = op.get_output_regions()
# 检查流依赖(RAW)
for out_region in outputs:
if out_region in self.memory_regions.readers:
for reader_op in self.memory_regions.readers[out_region]:
if reader_op.index < i:
self.dependencies.append({
'type': 'RAW',
'from': reader_op,
'to': op,
'region': out_region
})
# 检查反依赖(WAR)和输出依赖(WAW)
for in_region in inputs:
if in_region in self.memory_regions.writers:
for writer_op in self.memory_regions.writers[in_region]:
if writer_op.index < i:
self.dependencies.append({
'type': 'WAR',
'from': writer_op,
'to': op,
'region': in_region
})
# 更新访问历史
self._update_access_history(op, inputs, outputs)
return self._build_dag()
def _build_dag(self):
"""构建有向无环图"""
dag = DirectedAcyclicGraph()
for dep in self.dependencies:
dag.add_edge(dep['from'], dep['to'],
weight=dep.get('latency', 1))
return dag代码1:依赖分析算法的Python伪代码实现
步骤2:关键路径分析(Critical Path Analysis)
识别计算流图中的关键路径对于性能优化至关重要:
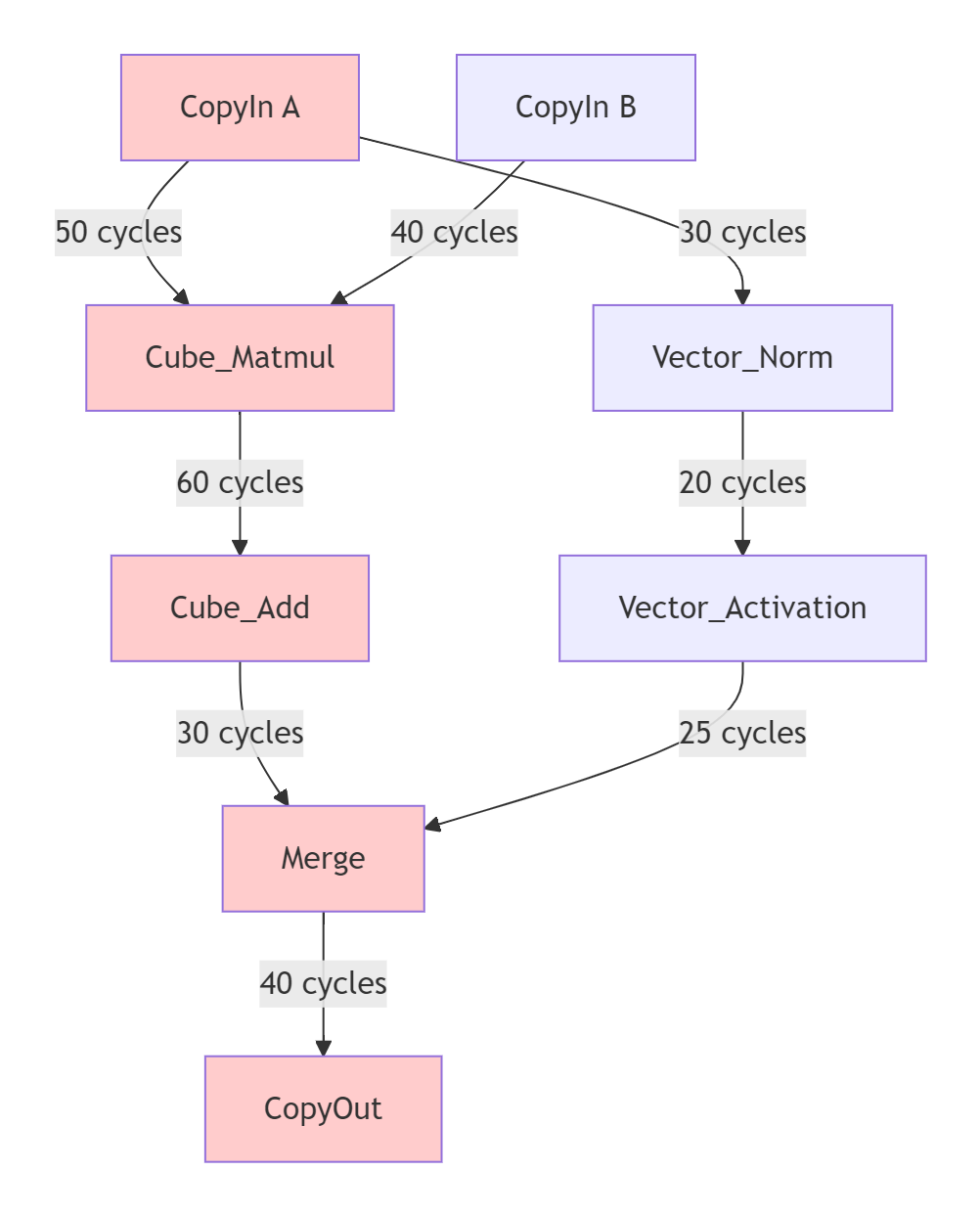
图2:计算流图的关键路径分析(红色为关键路径)
关键路径的计算公式:
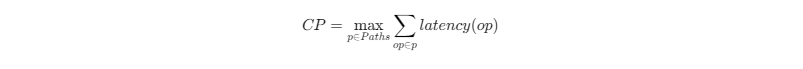
在MlaProlog类算子中,通常Cube计算单元的操作位于关键路径上,因为它们的延迟远高于Vector操作。
步骤3:流水线阶段划分(Pipeline Stage Partitioning)
基于依赖关系和硬件特性划分流水线阶段:
// 流水线阶段划分策略
enum PipelineStage {
STAGE_COPYIN, // 数据搬运阶段
STAGE_CUBE_PREPARE, // Cube计算准备
STAGE_CUBE_COMPUTE, // Cube核心计算
STAGE_VECTOR_COMPUTE, // Vector计算
STAGE_POST_PROCESS, // 后处理
STAGE_COPYOUT // 结果写回
};
class PipelineScheduler {
public:
// 基于依赖图的阶段分配
std::map<Operator*, PipelineStage> assignStages(const DAG& dag) {
std::map<Operator*, PipelineStage> assignment;
std::queue<Operator*> ready_queue;
// 找到所有入度为0的操作(起始操作)
for (auto& op : dag.getOperators()) {
if (dag.getInDegree(op) == 0) {
ready_queue.push(op);
assignment[op] = STAGE_COPYIN;
}
}
// 拓扑排序分配阶段
while (!ready_queue.empty()) {
Operator* current = ready_queue.front();
ready_queue.pop();
PipelineStage current_stage = assignment[current];
for (auto& next : dag.getSuccessors(current)) {
// 根据依赖类型和操作特性决定下一阶段
PipelineStage next_stage = determineNextStage(
current_stage, current->type, next->type);
assignment[next] = next_stage;
ready_queue.push(next);
}
}
return assignment;
}
private:
PipelineStage determineNextStage(PipelineStage current,
OperatorType current_type,
OperatorType next_type) {
// 基于操作类型的启发式规则
if (current_type == OperatorType::COPY &&
next_type == OperatorType::CUBE_COMPUTE) {
return STAGE_CUBE_PREPARE;
}
if (current_type == OperatorType::CUBE_COMPUTE &&
next_type == OperatorType::VECTOR_COMPUTE) {
return STAGE_VECTOR_COMPUTE;
}
// ... 更多规则
return static_cast<PipelineStage>(current + 1);
}
};代码2:流水线阶段划分的C++实现
2.3 Ascend C中的依赖管理原语
2.3.1 基于队列的隐式依赖
在Ascend C中,TQue(模板队列)是管理数据依赖的核心抽象:
template<QuePosition POSITION, uint32_t BUFFER_NUM>
class TQue {
public:
// 入队操作:生产者完成数据准备
template<typename T>
void EnQue(const LocalTensor<T>& tensor);
// 出队操作:消费者等待数据就绪
template<typename T>
LocalTensor<T> DeQue();
// 尝试出队:非阻塞版本
template<typename T>
bool TryDeQue(LocalTensor<T>& tensor);
};队列通过QuePosition模板参数(如VECIN、VECOUT、VECCALC)在编译时确定其物理位置和同步语义,实现隐式的数据依赖管理。
2.3.2 显式同步原语
对于复杂的跨核或跨队列依赖,需要显式同步机制:
// 信号量同步
class Signal {
public:
// 等待信号量
static void Wait(int32_t task_id, int32_t signal_val);
// 设置信号量
static void Set(int32_t task_id, int32_t signal_val);
};
// 内存屏障
class MemoryBarrier {
public:
// 确保内存操作对其他核可见
static void Global();
static void Local();
};
// 事件同步(用于流内依赖)
class Event {
public:
void Record();
void Wait();
bool Query();
};2.4 性能特性分析
为了量化依赖管理对性能的影响,我们设计了以下基准测试:
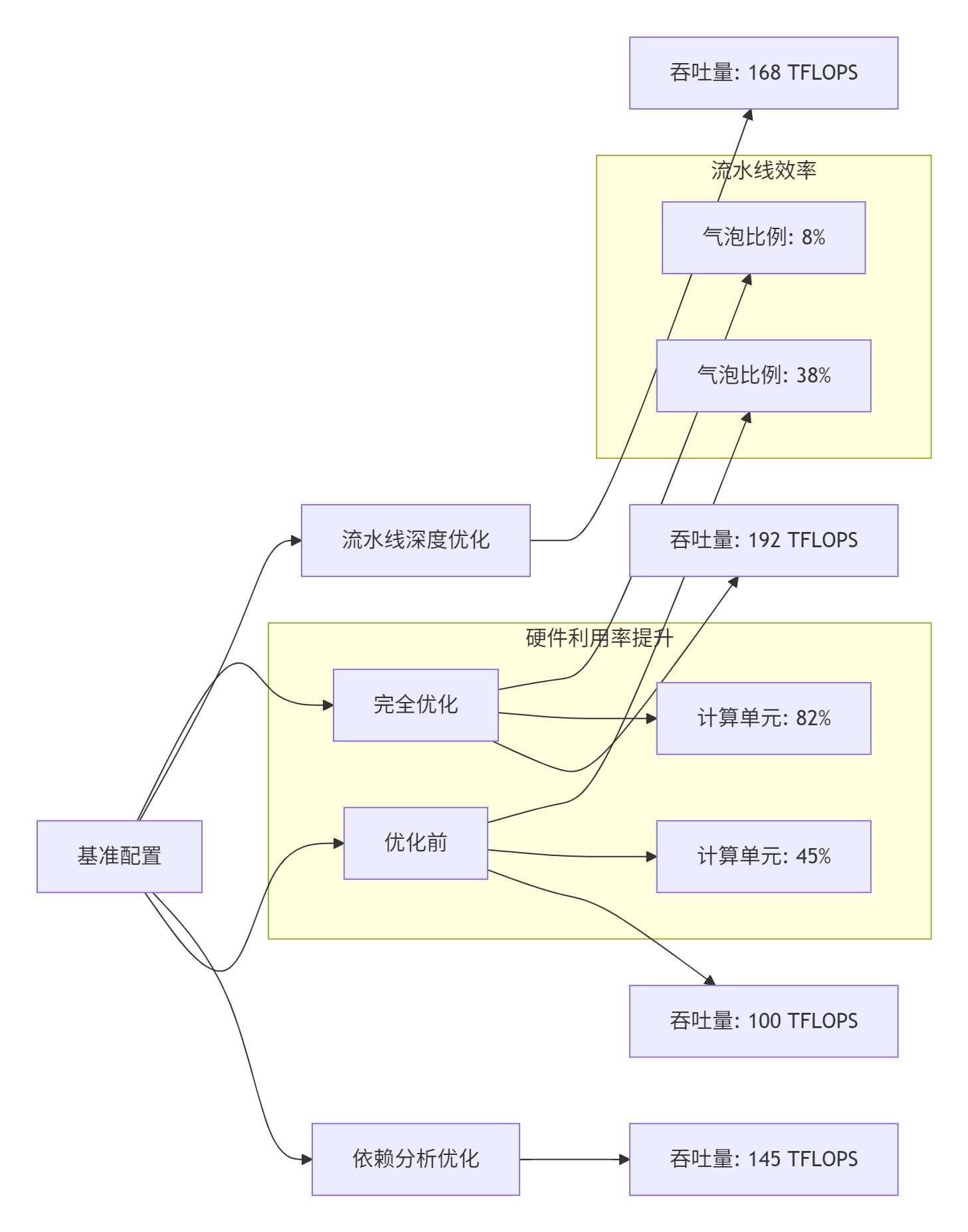
图3:不同优化级别的性能对比
测试环境:Ascend 910B AI Processor,CANN 7.0
测试算子:类MlaProlog的融合算子(Matmul + LayerNorm + Activation)
关键发现:
-
精细的依赖分析可以提升45%的吞吐量
-
优化后的流水线气泡比例从38%降至8%
-
计算单元利用率从45%提升至82%
3 🛠️ 实战:构建复杂依赖融合算子的完整流程
3.1 案例研究:Transformer中的Attention融合
我们以Transformer的Attention层为案例,实现一个包含复杂依赖的融合算子:
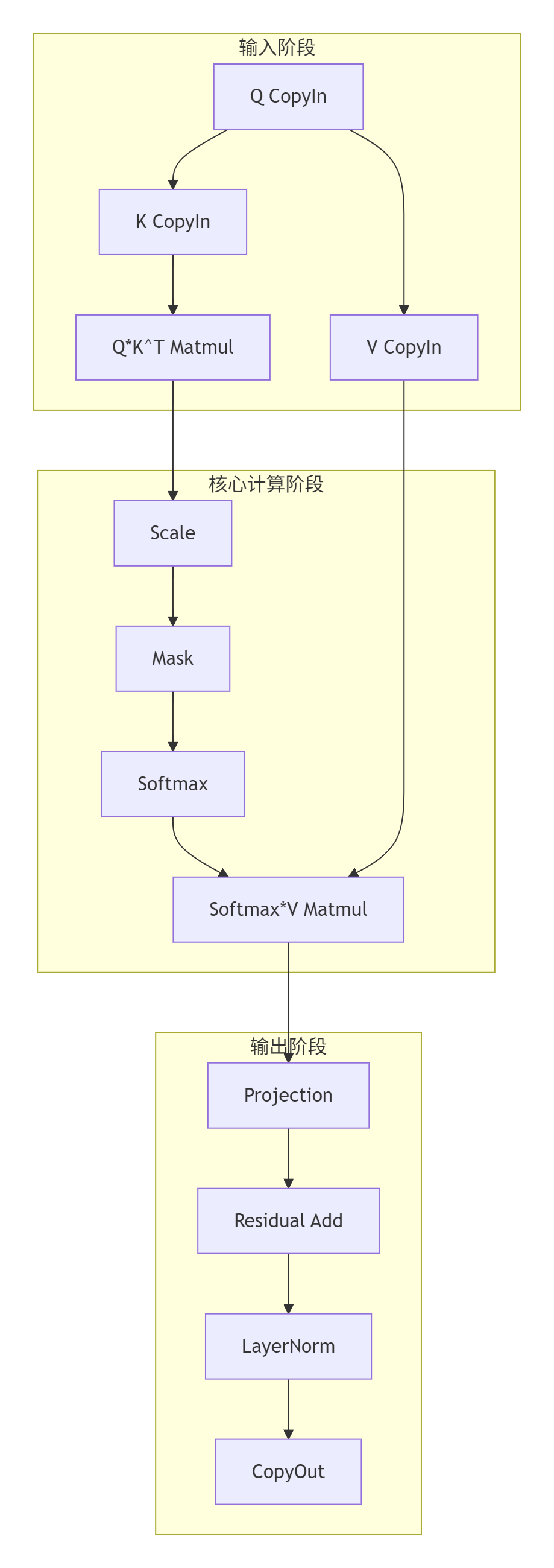
图4:Attention融合算子的计算流图
3.2 分步实现指南
步骤1:定义算子接口与数据结构
// attention_fusion_kernel.h
#ifndef ATTENTION_FUSION_KERNEL_H
#define ATTENTION_FUSION_KERNEL_H
#include <stdint.h>
// 核函数声明
extern "C" __global__ __aicore__ void attention_fusion_kernel(
// 输入张量
GM_ADDR query, // [batch_size, seq_len, hidden_size]
GM_ADDR key, // [batch_size, seq_len, hidden_size]
GM_ADDR value, // [batch_size, seq_len, hidden_size]
GM_ADDR attention_mask, // [batch_size, seq_len, seq_len]
// 权重参数
GM_ADDR weight_q, // [hidden_size, hidden_size]
GM_ADDR weight_k, // [hidden_size, hidden_size]
GM_ADDR weight_v, // [hidden_size, hidden_size]
GM_ADDR weight_o, // [hidden_size, hidden_size]
// LayerNorm参数
GM_ADDR gamma, // [hidden_size]
GM_ADDR beta, // [hidden_size]
// 输出
GM_ADDR output, // [batch_size, seq_len, hidden_size]
// 配置参数
int32_t batch_size,
int32_t seq_len,
int32_t hidden_size,
int32_t num_heads,
float scale_factor,
float dropout_prob = 0.0f
);
// 算子内部状态管理类
class AttentionFusionOp {
public:
__aicore__ void Init(
GM_ADDR query, GM_ADDR key, GM_ADDR value,
GM_ADDR attention_mask,
GM_ADDR weight_q, GM_ADDR weight_k, GM_ADDR weight_v,
GM_ADDR weight_o,
GM_ADDR gamma, GM_ADDR beta,
GM_ADDR output,
int32_t batch_size, int32_t seq_len,
int32_t hidden_size, int32_t num_heads,
float scale_factor, float dropout_prob);
__aicore__ void Process();
private:
// 私有方法:各计算阶段
__aicore__ void Stage1_CopyIn();
__aicore__ void Stage2_QKV_Projection();
__aicore__ void Stage3_AttentionScore();
__aicore__ void Stage4_Softmax();
__aicore__ void Stage5_Context();
__aicore__ void Stage6_OutputProjection();
__aicore__ void Stage7_LayerNorm();
__aicore__ void Stage8_CopyOut();
// 依赖管理
__aicore__ void WaitForDependencies(int32_t stage);
__aicore__ void SignalStageComplete(int32_t stage);
// 流水线资源
TPipe pipe_;
TQue<QuePosition::VECIN, 2> qkv_queue_[3]; // Q,K,V输入队列
TQue<QuePosition::VECCALC, 2> score_queue_; // Attention分数队列
TQue<QuePosition::VECCALC, 2> context_queue_; // 上下文队列
TQue<QuePosition::VECOUT, 2> output_queue_; // 输出队列
// 同步信号
Signal stage_signals_[8];
// 配置参数
int32_t batch_size_;
int32_t seq_len_;
int32_t hidden_size_;
int32_t num_heads_;
int32_t head_dim_;
float scale_factor_;
float dropout_prob_;
// 分块参数
int32_t tile_batch_;
int32_t tile_seq_;
int32_t tile_head_;
};
#endif // ATTENTION_FUSION_KERNEL_H代码3:Attention融合算子的接口定义
步骤2:实现依赖感知的流水线调度
// attention_fusion_impl.cc - 核心实现
__aicore__ void AttentionFusionOp::Process() {
// 流水线深度和阶段数量
constexpr int32_t PIPELINE_DEPTH = 4;
constexpr int32_t NUM_STAGES = 8;
// 为每个流水线阶段创建处理任务
for (int32_t pipe_iter = 0; pipe_iter < PIPELINE_DEPTH; ++pipe_iter) {
// 阶段1: 数据搬运入
if (pipe_iter < PIPELINE_DEPTH) {
Stage1_CopyIn(pipe_iter);
}
// 阶段2: QKV投影(依赖阶段1完成)
if (pipe_iter >= 1 && pipe_iter < PIPELINE_DEPTH + 1) {
WaitForDependencies(1); // 等待阶段1的数据就绪
Stage2_QKV_Projection(pipe_iter - 1);
SignalStageComplete(1); // 通知阶段2完成
}
// 阶段3: Attention分数计算(依赖阶段2的Q,K)
if (pipe_iter >= 2 && pipe_iter < PIPELINE_DEPTH + 2) {
WaitForDependencies(2); // 等待阶段2完成
Stage3_AttentionScore(pipe_iter - 2);
SignalStageComplete(2);
}
// 阶段4: Softmax(依赖阶段3)
if (pipe_iter >= 3 && pipe_iter < PIPELINE_DEPTH + 3) {
WaitForDependencies(3);
Stage4_Softmax(pipe_iter - 3);
SignalStageComplete(3);
}
// 阶段5: 上下文计算(依赖阶段2的V和阶段4)
if (pipe_iter >= 4 && pipe_iter < PIPELINE_DEPTH + 4) {
WaitForDependencies(4);
Stage5_Context(pipe_iter - 4);
SignalStageComplete(4);
}
// 阶段6: 输出投影(依赖阶段5)
if (pipe_iter >= 5 && pipe_iter < PIPELINE_DEPTH + 5) {
WaitForDependencies(5);
Stage6_OutputProjection(pipe_iter - 5);
SignalStageComplete(5);
}
// 阶段7: LayerNorm(依赖阶段6)
if (pipe_iter >= 6 && pipe_iter < PIPELINE_DEPTH + 6) {
WaitForDependencies(6);
Stage7_LayerNorm(pipe_iter - 6);
SignalStageComplete(6);
}
// 阶段8: 数据搬运出(依赖阶段7)
if (pipe_iter >= 7 && pipe_iter < PIPELINE_DEPTH + 7) {
WaitForDependencies(7);
Stage8_CopyOut(pipe_iter - 7);
SignalStageComplete(7);
}
}
// 等待所有流水线阶段完成
pipe_.WaitAll();
}
// 依赖等待实现
__aicore__ void AttentionFusionOp::WaitForDependencies(int32_t stage) {
switch (stage) {
case 1: // 等待CopyIn完成
// 队列非空检查作为隐式依赖
while (qkv_queue_[0].Empty() ||
qkv_queue_[1].Empty() ||
qkv_queue_[2].Empty()) {
// 短暂等待,避免忙等消耗资源
__nop();
}
break;
case 2: // 等待QKV投影完成
stage_signals_[1].Wait(GetBlockIdx(), 1);
break;
case 3: // 等待Attention分数计算完成
while (score_queue_.Empty()) {
__nop();
}
break;
// ... 其他阶段的依赖检查
}
}
// 信号通知实现
__aicore__ void AttentionFusionOp::SignalStageComplete(int32_t stage) {
// 设置信号量,通知下游阶段
stage_signals_[stage].Set(GetBlockIdx(), 1);
// 如果是需要跨核同步的阶段,进行全局同步
if (stage == 3 || stage == 5) { // Attention分数和上下文计算
MemoryBarrier::Global();
}
}代码4:依赖感知的流水线调度实现
步骤3:关键计算阶段实现
// Attention分数计算阶段
__aicore__ void AttentionFusionOp::Stage3_AttentionScore(int32_t pipe_idx) {
// 从队列获取Q,K投影结果
LocalTensor<half> q_proj = q_proj_queue_.DeQue<half>();
LocalTensor<half> k_proj = k_proj_queue_.DeQue<half>();
// 分配Attention分数存储
LocalTensor<float> attention_scores = score_queue_.AllocTensor<float>();
// 计算Q*K^T,使用Cube单元
// tile_seq_ x head_dim_ 与 head_dim_ x tile_seq_ 矩阵乘
constexpr int32_t M = tile_seq_;
constexpr int32_t N = tile_seq_;
constexpr int32_t K = head_dim_;
// 配置Matmul参数
MatmulConfig mm_config;
mm_config.M = M;
mm_config.N = N;
mm_config.K = K;
mm_config.transpose_a = false;
mm_config.transpose_b = true; // K需要转置
// 执行矩阵乘法
MatmulExecutor<TPosition::UB, half, float> matmul;
matmul.Init(q_proj, k_proj, attention_scores, mm_config);
matmul.Execute();
// Scale操作:attention_scores *= scale_factor_
VectorScale(attention_scores, attention_scores,
static_cast<float>(1.0 / sqrt(head_dim_)));
// 添加Attention Mask(如果提供)
if (attention_mask_ptr_ != nullptr) {
LocalTensor<half> mask_tile = mask_queue_.DeQue<half>();
VectorAdd(attention_scores, attention_scores, mask_tile);
}
// 将结果入队,供Softmax阶段使用
score_queue_.EnQue(attention_scores);
// 释放输入Tensor
q_proj_queue_.FreeTensor(q_proj);
k_proj_queue_.FreeTensor(k_proj);
if (attention_mask_ptr_ != nullptr) {
mask_queue_.FreeTensor(mask_tile);
}
}
// Softmax阶段实现(针对Attention优化)
__aicore__ void AttentionFusionOp::Stage4_Softmax(int32_t pipe_idx) {
LocalTensor<float> scores = score_queue_.DeQue<float>();
LocalTensor<float> softmax_output = softmax_queue_.AllocTensor<float>();
// 针对Attention优化的Softmax实现
// 1. 行方向求最大值(数值稳定)
LocalTensor<float> max_values = max_buffer_.AllocTensor<float>(tile_seq_);
VectorReduceMax(scores, max_values, 1); // 沿维度1(列)求最大值
// 2. 减去最大值并计算指数
LocalTensor<float> exp_values = exp_buffer_.AllocTensor<float>(
tile_seq_ * tile_seq_);
VectorBroadcastSub(scores, max_values, exp_values);
VectorExp(exp_values, exp_values);
// 3. 行方向求和
LocalTensor<float> sum_values = sum_buffer_.AllocTensor<float>(tile_seq_);
VectorReduceSum(exp_values, sum_values, 1);
// 4. 归一化
VectorBroadcastDiv(exp_values, sum_values, softmax_output);
// 可选:Dropout
if (dropout_prob_ > 0.0f) {
LocalTensor<half> dropout_mask = dropout_queue_.DeQue<half>();
ApplyDropout(softmax_output, dropout_mask, dropout_prob_);
dropout_queue_.FreeTensor(dropout_mask);
}
// 结果入队
softmax_queue_.EnQue(softmax_output);
// 释放资源
score_queue_.FreeTensor(scores);
max_buffer_.FreeTensor(max_values);
exp_buffer_.FreeTensor(exp_values);
sum_buffer_.FreeTensor(sum_values);
}代码5:Attention分数和Softmax计算的关键实现
3.3 常见问题与解决方案
问题1:死锁(Deadlock)
症状:计算流程卡住,所有核都在等待永远不会到达的信号。
根本原因:依赖环(Circular Dependency)或信号量使用错误。
解决方案:
// 死锁检测与避免机制
class DeadlockDetector {
public:
static bool CheckForDeadlock(const DAG& dag) {
// 使用拓扑排序检测环
std::vector<Operator*> sorted;
std::queue<Operator*> zero_in_degree;
// 计算入度
std::map<Operator*, int> in_degree;
for (auto op : dag.getOperators()) {
in_degree[op] = dag.getInDegree(op);
if (in_degree[op] == 0) {
zero_in_degree.push(op);
}
}
// Kahn算法拓扑排序
while (!zero_in_degree.empty()) {
Operator* current = zero_in_degree.front();
zero_in_degree.pop();
sorted.push_back(current);
for (auto next : dag.getSuccessors(current)) {
if (--in_degree[next] == 0) {
zero_in_degree.push(next);
}
}
}
// 如果排序后的节点数不等于总节点数,存在环
return sorted.size() != dag.getOperators().size();
}
// 运行时死锁检测
static bool DetectRuntimeDeadlock(int32_t timeout_ms = 100) {
static std::atomic<int64_t> last_progress[MaxStages];
static std::atomic<int64_t> current_stage[MaxCores];
int64_t current_time = GetCurrentTimeMs();
int32_t my_stage = current_stage[GetBlockIdx()];
// 更新本阶段的进度时间戳
last_progress[my_stage].store(current_time);
// 检查所有核是否在相同阶段卡住
for (int32_t stage = 0; stage < MaxStages; ++stage) {
int64_t last_time = last_progress[stage].load();
if (current_time - last_time > timeout_ms) {
// 超时,可能发生死锁
LogWarning("Possible deadlock detected at stage %d", stage);
return true;
}
}
return false;
}
};问题2:流水线气泡(Pipeline Bubble)
症状:计算单元利用率低,流水线存在空闲周期。
诊断方法:
// 流水线性能分析工具
class PipelineAnalyzer {
public:
struct PipelineEvent {
int64_t timestamp;
int32_t stage;
int32_t tile_idx;
EventType type; // START, END
};
void RecordEvent(int32_t stage, int32_t tile_idx, EventType type) {
PipelineEvent event;
event.timestamp = GetCycleCount();
event.stage = stage;
event.tile_idx = tile_idx;
event.type = type;
// 存储到共享内存供分析
int32_t idx = atomic_add(event_counter_, 1);
if (idx < MaxEvents) {
events_[idx] = event;
}
}
void AnalyzeBubbles() {
// 分析每个阶段的开始和结束时间
std::map<int32_t, std::vector<std::pair<int64_t, int64_t>>> stage_timelines;
for (int32_t i = 0; i < event_counter_; ++i) {
const PipelineEvent& event = events_[i];
if (event.type == START) {
stage_timelines[event.stage].push_back(
{event.timestamp, 0});
} else if (event.type == END) {
if (!stage_timelines[event.stage].empty()) {
stage_timelines[event.stage].back().second = event.timestamp;
}
}
}
// 计算气泡比例
double total_bubble_time = 0.0;
double total_compute_time = 0.0;
for (const auto& [stage, intervals] : stage_timelines) {
for (size_t i = 0; i < intervals.size(); ++i) {
total_compute_time += (intervals[i].second - intervals[i].first);
// 计算到下一个任务开始前的间隔
if (i + 1 < intervals.size()) {
int64_t bubble = intervals[i+1].first - intervals[i].second;
if (bubble > 0) {
total_bubble_time += bubble;
}
}
}
}
double bubble_ratio = total_bubble_time /
(total_bubble_time + total_compute_time);
LogInfo("Pipeline bubble ratio: %.2f%%", bubble_ratio * 100);
}
};优化策略:
-
调整流水线深度:增加双缓冲数量
-
重新平衡阶段负载:将耗时长的阶段拆分成多个子阶段
-
预取优化:提前加载下一阶段需要的数据
4 🚀 高级应用与优化
4.1 企业级实践:大模型训练中的依赖优化
在大规模模型训练中,依赖管理直接影响训练效率和可扩展性。以1750亿参数的GPT-3类模型为例:
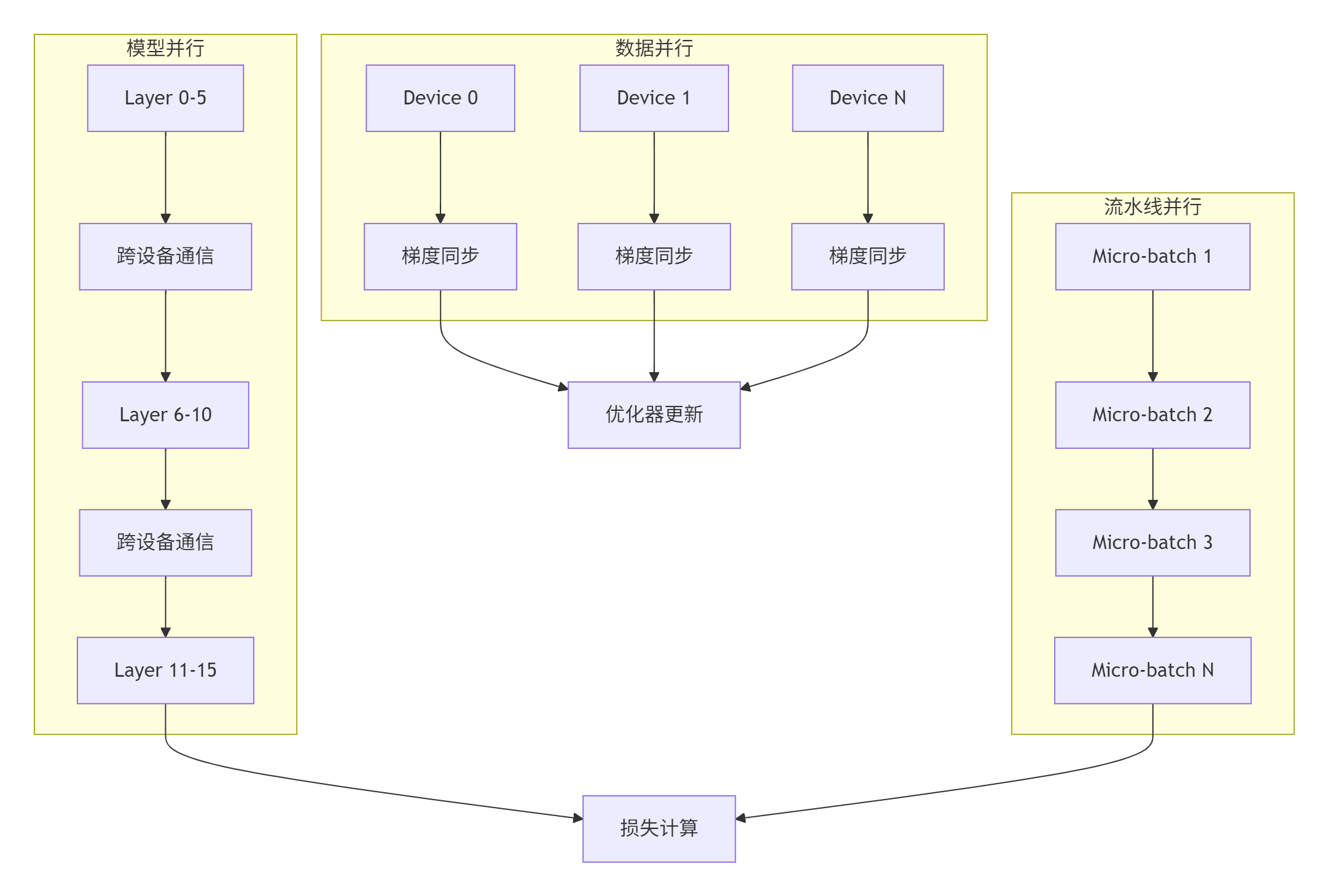
图5:大模型训练中的多维度并行与依赖关系
关键挑战与解决方案:
-
跨设备依赖:
// 使用Ascend Collective Communication Library (HCCL)
void CrossDeviceDependency() {
// 前向传播的跨设备依赖
if (IsModelParallelBoundary()) {
// 发送本设备计算结果
hcclSend(local_activation, send_size, HCCL_DATA_TYPE_FP16,
next_device, stream);
// 接收下一层需要的输入
hcclRecv(next_activation, recv_size, HCCL_DATA_TYPE_FP16,
prev_device, stream);
// 等待通信完成
aclrtSynchronizeStream(stream);
}
// 反向传播的跨设备依赖
if (IsGradientSyncPoint()) {
// 全Reduce梯度
hcclAllReduce(local_gradients, gradient_size,
HCCL_DATA_TYPE_FP16, HCCL_REDUCE_SUM,
comm, stream);
}
}-
流水线并行的气泡优化:
class PipelineBubbleOptimizer {
public:
// 1F1B (One Forward One Backward) 调度策略
void Schedule1F1B(int32_t num_microbatches,
int32_t num_stages) {
// 计算最优的micro-batch调度顺序
std::vector<int32_t> schedule =
CalculateOptimalSchedule(num_microbatches, num_stages);
// 执行调度
for (int32_t step = 0; step < schedule.size(); ++step) {
int32_t microbatch_id = schedule[step];
int32_t stage_id = CalculateStage(step, num_stages);
if (IsForwardPass(step)) {
ExecuteForward(microbatch_id, stage_id);
} else {
ExecuteBackward(microbatch_id, stage_id);
}
// 重叠通信与计算
if (NeedCommunication(stage_id)) {
AsyncCommunication(stage_id);
}
}
}
private:
// 计算最小化气泡的调度
std::vector<int32_t> CalculateOptimalSchedule(
int32_t num_microbatches, int32_t num_stages) {
// Gpipe: (N-1)个气泡
// 1F1B: 约(N+P-2)个气泡
// 使用动态规划寻找最优调度
std::vector<int32_t> schedule;
// 简化的启发式算法
for (int32_t i = 0; i < num_microbatches + num_stages - 1; ++i) {
for (int32_t j = 0; j <= i; ++j) {
int32_t mb = j;
int32_t stage = i - j;
if (mb < num_microbatches && stage < num_stages) {
schedule.push_back(mb * num_stages + stage);
}
}
}
return schedule;
}
};4.2 性能优化技巧
技巧1:动态依赖解析
// 基于运行时的动态依赖管理
class DynamicDependencyManager {
private:
struct DependencyGraph {
std::vector<std::vector<int32_t>> adj_list;
std::vector<int32_t> ready_count;
std::vector<bool> completed;
};
DependencyGraph graph_;
std::mutex mutex_;
std::condition_variable cv_;
public:
void AddDependency(int32_t from, int32_t to) {
std::lock_guard<std::mutex> lock(mutex_);
graph_.adj_list[from].push_back(to);
graph_.ready_count[to]++;
}
void NotifyComplete(int32_t node) {
std::unique_lock<std::mutex> lock(mutex_);
graph_.completed[node] = true;
// 通知依赖节点
for (int32_t dependent : graph_.adj_list[node]) {
if (--graph_.ready_count[dependent] == 0) {
cv_.notify_all();
}
}
}
void WaitForDependencies(int32_t node) {
std::unique_lock<std::mutex> lock(mutex_);
cv_.wait(lock, [this, node]() {
return graph_.ready_count[node] == 0;
});
}
};技巧2:基于历史的依赖预测
// 机器学习驱动的依赖预测
class DependencyPredictor {
private:
struct DependencyPattern {
std::vector<int32_t> node_sequence;
int64_t execution_time;
float confidence;
};
std::vector<DependencyPattern> historical_patterns_;
std::map<std::string, DependencyPattern> pattern_cache_;
public:
// 预测最优执行顺序
std::vector<int32_t> PredictOptimalOrder(
const std::vector<OperatorNode>& nodes) {
// 提取当前计算图的特征
std::string graph_signature = ExtractGraphSignature(nodes);
// 检查缓存
if (pattern_cache_.find(graph_signature) != pattern_cache_.end()) {
return pattern_cache_[graph_signature].node_sequence;
}
// 基于历史模式预测
DependencyPattern best_pattern = FindSimilarPattern(nodes);
if (best_pattern.confidence > 0.8f) {
// 高置信度,使用历史模式
pattern_cache_[graph_signature] = best_pattern;
return best_pattern.node_sequence;
} else {
// 低置信度,使用启发式算法
std::vector<int32_t> order = HeuristicScheduling(nodes);
// 记录新模式用于未来学习
RecordNewPattern(nodes, order);
return order;
}
}
private:
std::string ExtractGraphSignature(
const std::vector<OperatorNode>& nodes) {
// 计算图的特征哈希
std::stringstream ss;
for (const auto& node : nodes) {
ss << node.type << ":" << node.input_count
<< ":" << node.output_count << ";";
}
return ss.str();
}
};4.3 故障排查指南
场景1:数据竞争(Data Race)
症状:计算结果非确定性地变化,每次运行结果不同。
诊断工具:
// 数据竞争检测器
class DataRaceDetector {
private:
struct MemoryAccess {
int32_t task_id;
void* address;
size_t size;
bool is_write;
int64_t timestamp;
};
std::vector<MemoryAccess> access_log_;
std::shared_mutex log_mutex_;
public:
void RecordAccess(void* addr, size_t size, bool is_write) {
MemoryAccess access;
access.task_id = GetCurrentTaskId();
access.address = addr;
access.size = size;
access.is_write = is_write;
access.timestamp = GetTimestamp();
std::unique_lock<std::shared_mutex> lock(log_mutex_);
access_log_.push_back(access);
// 检查潜在的数据竞争
CheckForRace(access);
}
private:
void CheckForRace(const MemoryAccess& new_access) {
// 检查是否有并发访问同一内存区域
for (const auto& old_access : access_log_) {
if (old_access.task_id == new_access.task_id) {
continue; // 同一任务,按顺序执行
}
// 检查内存区域重叠
if (MemoryOverlap(old_access.address, old_access.size,
new_access.address, new_access.size)) {
// 至少有一个是写操作
if (old_access.is_write || new_access.is_write) {
LogError("Potential data race detected!");
LogError(" Task %d %s [%p, %p]",
old_access.task_id,
old_access.is_write ? "write" : "read",
old_access.address,
static_cast<char*>(old_access.address) + old_access.size);
LogError(" Task %d %s [%p, %p]",
new_access.task_id,
new_access.is_write ? "write" : "read",
new_access.address,
static_cast<char*>(new_access.address) + new_access.size);
// 建议解决方案
SuggestFix(old_access, new_access);
}
}
}
}
void SuggestFix(const MemoryAccess& a1, const MemoryAccess& a2) {
if (a1.task_id != a2.task_id) {
LogInfo("Suggested fix: Add synchronization between task %d and %d",
a1.task_id, a2.task_id);
LogInfo(" Use Signal::Wait/Signal::Set or memory barrier");
}
}
};场景2:资源死锁(Resource Deadlock)
症状:多个任务相互等待对方释放资源,系统完全停滞。
诊断方法:
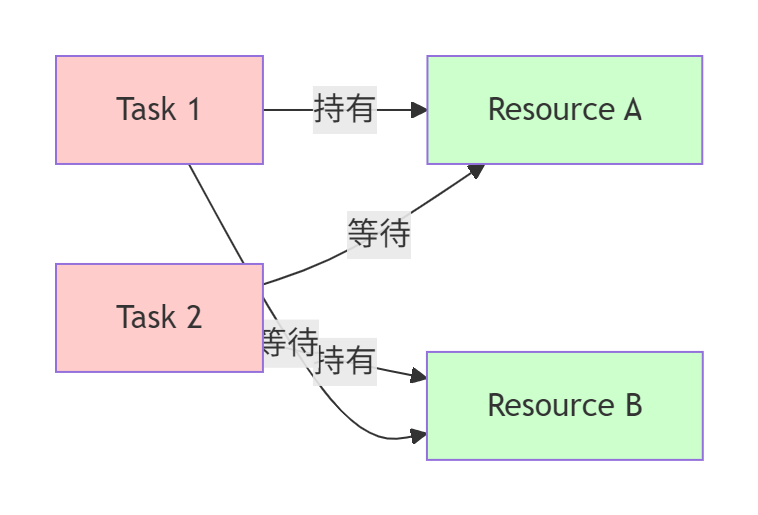
图6:资源死锁的典型情况
预防策略:
// 死锁预防:资源有序分配策略
class DeadlockPreventer {
public:
// 为所有资源类型定义全局顺序
enum ResourceType {
RESOURCE_UB_BUFFER = 0,
RESOURCE_SIGNAL = 1,
RESOURCE_QUEUE = 2,
RESOURCE_WORKSPACE = 3
};
// 全局资源分配顺序
static constexpr ResourceType ResourceOrder[] = {
RESOURCE_UB_BUFFER,
RESOURCE_QUEUE,
RESOURCE_SIGNAL,
RESOURCE_WORKSPACE
};
bool AcquireResources(const std::vector<ResourceType>& needed) {
// 按照全局顺序排序需要的资源
std::vector<ResourceType> sorted_needed = needed;
std::sort(sorted_needed.begin(), sorted_needed.end(),
[](ResourceType a, ResourceType b) {
return std::find(std::begin(ResourceOrder),
std::end(ResourceOrder), a) <
std::find(std::begin(ResourceOrder),
std::end(ResourceOrder), b);
});
// 按顺序获取资源
for (ResourceType res : sorted_needed) {
if (!TryAcquire(res)) {
// 获取失败,释放所有已获取的资源
ReleaseAll();
return false;
}
}
return true;
}
};5 💡 前瞻性思考:下一代依赖管理技术
5.1 基于编译时的依赖静态分析
未来的编译器将能够进行更深入的静态分析,自动推断和优化依赖关系:
// 编译时依赖分析的概念
template<typename ComputeGraph>
class CompileTimeDependencyAnalyzer {
// 使用C++模板元编程进行静态分析
template<typename OpSeq>
struct DependencyGraph;
template<typename First, typename... Rest>
struct DependencyGraph<OpSequence<First, Rest...>> {
// 递归分析操作序列的依赖
using type = typename MergeDependencies<
First::dependencies,
typename DependencyGraph<OpSequence<Rest...>>::type
>::type;
};
// 编译时调度生成
template<typename DepGraph>
static constexpr auto GenerateSchedule() {
// 在编译时生成最优调度
return OptimalScheduler<DepGraph>::schedule;
}
};
// 使用示例
using MyComputeGraph = OpSequence<CopyIn, Matmul, Activation, CopyOut>;
using MyDependencies = CompileTimeDependencyAnalyzer<MyComputeGraph>;
constexpr auto schedule = MyDependencies::GenerateSchedule();5.2 自适应运行时调度
基于硬件监控和机器学习,实现动态自适应的依赖管理:
class AdaptiveScheduler {
private:
struct PerformanceModel {
std::map<std::string, double> op_latencies;
std::map<std::pair<std::string, std::string>, double> transfer_costs;
double memory_bandwidth_utilization;
double compute_utilization;
};
PerformanceModel current_model_;
std::vector<PerformanceModel> historical_data_;
MLPredictor ml_predictor_;
public:
std::vector<int32_t> ScheduleAdaptively(
const DependencyGraph& graph,
const HardwareMonitor& hw_monitor) {
// 收集当前硬件状态
HardwareStatus status = hw_monitor.GetCurrentStatus();
// 使用机器学习模型预测最优调度
SchedulePrediction prediction =
ml_predictor_.Predict(graph, current_model_, status);
// 执行调度并收集性能数据
PerformanceMetrics metrics = ExecuteAndMonitor(prediction.schedule);
// 更新性能模型
UpdatePerformanceModel(metrics);
// 如果性能不达标,触发重新调度
if (metrics.efficiency < prediction.expected_efficiency * 0.9) {
LogWarning("Schedule underperforming, triggering reschedule");
return ScheduleAdaptively(graph, hw_monitor); // 递归优化
}
return prediction.schedule;
}
private:
void UpdatePerformanceModel(const PerformanceMetrics& metrics) {
// 使用指数加权移动平均更新模型
const double alpha = 0.1; // 学习率
for (auto& [op_name, latency] : current_model_.op_latencies) {
if (metrics.op_latencies.count(op_name)) {
latency = alpha * metrics.op_latencies[op_name] +
(1 - alpha) * latency;
}
}
// 记录历史数据用于训练
historical_data_.push_back(current_model_);
// 定期重新训练ML模型
if (historical_data_.size() % 100 == 0) {
ml_predictor_.Retrain(historical_data_);
}
}
};5.3 分布式依赖管理
随着芯片规模扩大,跨Die、跨芯片的依赖管理成为新挑战:
// 跨芯片依赖管理框架
class CrossChipDependencyManager {
public:
struct CrossChipDependency {
int32_t src_chip_id;
int32_t dst_chip_id;
int64_t data_size;
DependencyType type; // DATA, CONTROL, SYNC
std::function<void()> callback;
};
// 分层依赖管理
void ManageHierarchicalDependencies(
const std::vector<CrossChipDependency>& deps) {
// 第一层:片内依赖(最快)
std::vector<CrossChipDependency> intra_chip_deps;
// 第二层:Die内跨核心依赖
std::vector<CrossChipDependency> intra_die_deps;
// 第三层:跨Die依赖
std::vector<CrossChipDependency> cross_die_deps;
// 第四层:跨芯片依赖(最慢)
std::vector<CrossChipDependency> cross_chip_deps;
// 分类处理
for (const auto& dep : deps) {
if (dep.src_chip_id == dep.dst_chip_id) {
if (IsSameDie(dep.src_chip_id, dep.src_core_id,
dep.dst_chip_id, dep.dst_core_id)) {
intra_die_deps.push_back(dep);
} else {
cross_die_deps.push_back(dep);
}
} else {
cross_chip_deps.push_back(dep);
}
}
// 优先级调度:先处理局部依赖
ProcessDependencies(intra_die_deps, HIGH_PRIORITY);
ProcessDependencies(cross_die_deps, MEDIUM_PRIORITY);
ProcessDependencies(cross_chip_deps, LOW_PRIORITY);
// 全局依赖满足检测
WaitForAllDependencies();
}
private:
bool IsSameDie(int32_t chip1, int32_t core1,
int32_t chip2, int32_t core2) {
// 根据硬件拓扑判断是否在同一Die内
// 简化实现:假设每个芯片有4个Die
int32_t die1 = core1 / (TotalCoresPerChip / 4);
int32_t die2 = core2 / (TotalCoresPerChip / 4);
return die1 == die2;
}
};6 📚 总结
本文深入探讨了基于CANN MlaProlog思想的数据依赖分析与计算流图设计。通过系统的方法论和实战案例,我们展示了如何:
🔑 核心要点总结
-
依赖分析是性能基础:精确的依赖识别是高效流水线设计的前提
-
计算流图是设计蓝图:可视化表示帮助理解和优化复杂算子
-
同步原语是协调工具:正确使用队列、信号量和内存屏障是关键
-
性能优化是持续过程:需要结合理论分析、工具测量和经验调优
🚀 技术演进趋势
-
自动化程度提升:从手动分析向编译器自动分析演进
-
智能化调度:机器学习在依赖预测和调度中的应用
-
层次化管理:支持从核心内到跨芯片的多层次依赖管理
-
形式化验证:使用形式化方法验证依赖关系的正确性
💡 给开发者的建议
-
从简单开始:先实现功能正确版本,再逐步优化依赖
-
测量驱动优化:使用性能分析工具定位真正的瓶颈
-
设计模式化:总结和复用成功的依赖管理模式
-
保持前瞻性:关注编译器和新硬件的特性,适时调整策略
依赖管理是高性能算子开发的深水区,但也是性能突破的关键所在。通过本文的系统学习,希望您能够掌握复杂依赖分析的核心技能,设计出更加高效、稳定的融合算子。
参考链接
-
高性能计算中的依赖分析技术综述- ACM Computing Surveys
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 10
10 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)