
Triton-Ascend性能测试工具解析:从Profiler到Benchmark的完整指南
本文深入探讨了昇腾NPU生态下的性能优化方法论,重点介绍了torch_npu.profiler工具和科学Benchmark设计两大核心技术。通过真实案例剖析,揭示了性能测试中常见的"自嗨"陷阱,并提供了从微观算子优化到宏观系统调优的全套解决方案。文章详细讲解了如何利用三层数据关联的Profiler精准定位瓶颈,以及设计工业级Benchmark的黄金法则,包括预热策略、多形状覆盖
目录
🔍 第二部分 深入torch_npu.profiler:不只是个“打点器”
📄 摘要
在昇腾生态搞了十几年算子开发,我见过太多“跑得快”的假象——一个算子单次前向1毫秒,就敢往PPT上写“性能业界领先”。真上了生产环境,批量推理时延直接飙到10毫秒,原形毕露。性能优化,“测不准”比“调不好”更可怕。本文不跟你复读PPT,我将以多年踩坑经验,手把手拆解Triton-Ascend开发生态下的性能评估体系。核心围绕两大神兵利器:torch_npu.profiler(性能透视镜) 和科学Benchmark方法论(性能标尺)。我会告诉你,为什么你的Profiler数据可能是“假的”,如何设计一个能反映真实负载的Benchmark,并分享在百亿参数大模型场景下,我们如何通过这套组合拳,硬生生把端到端吞吐提升了40%。全文万字,全是干货和硬核实战,目标是让你告别“凭感觉优化”,建立起数据驱动的、可复现的性能调优闭环。
🧠 第一部分 正本清源:为什么你的性能测试可能是“自嗨”?
在聊具体工具前,咱们得先达成一个共识:在异构计算时代,尤其是昇腾NPU这种复杂架构上,谈“一个算子的执行时间”是极其模糊的。你指的是:
-
Kernel Launch到结束的纯设备时间?
-
包含Host侧Launch开销和设备执行的总时间?
-
在数据流水线中,这个算子的“关键路径”时间?
-
在并发多Stream下,受资源竞争影响后的时间?
很多初级开发者盯着torch.npu.synchronize()前后掐表得到的第一个数字沾沾自喜,这离真实性能差了十万八千里。性能测试的第一性原则是:定义你的SLO(Service Level Objective)。对于训练,可能是吞吐(samples/sec);对于推理,可能是尾延迟(P99 Latency) 和吞吐。一切测试工具和方法的选取,都必须围绕这个目标展开。
torch_npu.profiler和科学的Benchmark,就是帮你从“微观算子耗时”和“宏观系统表现”两个维度,逼近真实SLO的望远镜和显微镜。
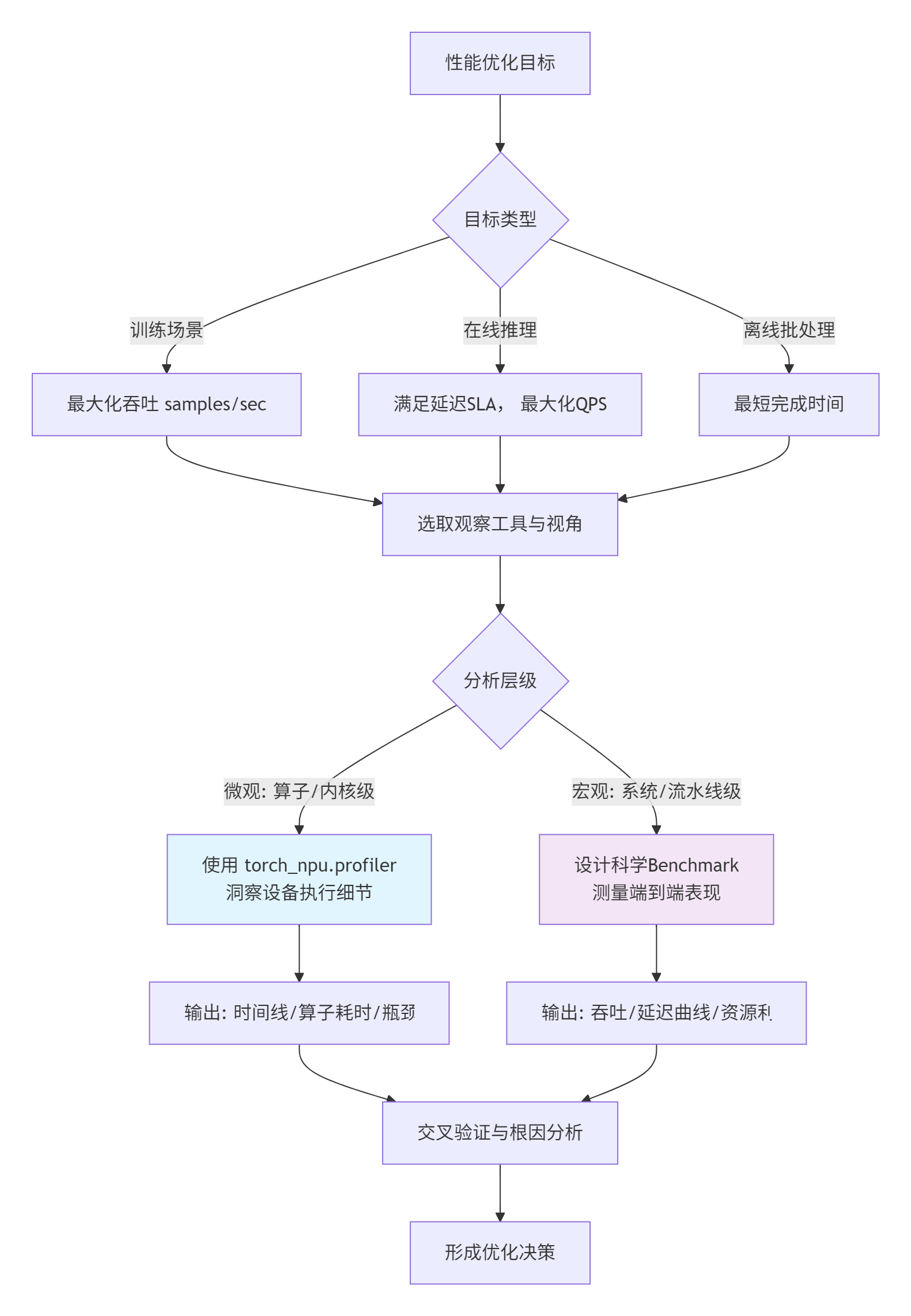
上图展示了从目标到工具的决策链路。接下来,我们深入微观世界。
🔍 第二部分 深入torch_npu.profiler:不只是个“打点器”
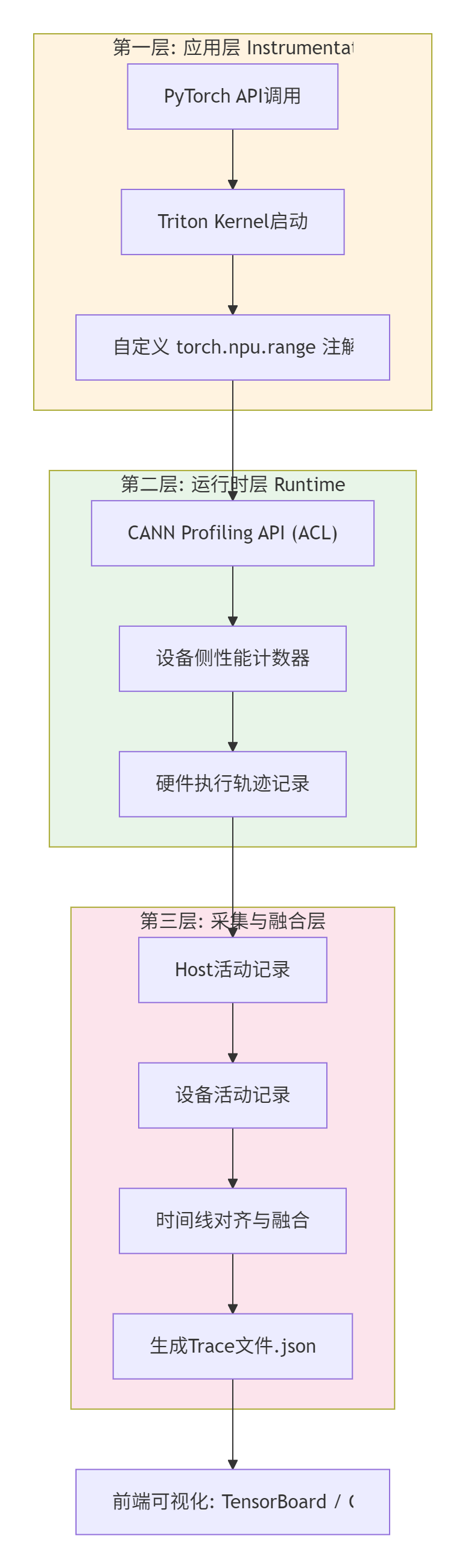
很多人把torch_npu.profiler当成一个高级的time.time(),大错特错。它是植入到昇腾CANN运行时里的一整套数据采集、关联和可视化系统。它的核心价值在于建立三个维度的关联:Host侧Python/C++调用栈、Device侧NPU执行时间线、以及系统级资源(AI Core/AI CPU/内存带宽)消耗。
🏗️ 2.1 架构设计:三层数据关联的艺术
它的设计非常巧妙,可以看作一个三层漏斗:
-
第一层:应用层埋点:你通过
with torch_npu.profiler.profile(...) as prof:和torch.npu.range(“my_region”)标记的代码块,会在CANN运行时生成一个“活动记录”。Triton算子本身也会自动注入这类标记。 -
第二层:运行时与硬件联动:当CANN执行到一个被标记的区域时,会命令NPU硬件(通过性能监控单元PMU)开始收集该区间内的详细数据:Kernel执行时间、内存拷贝(H2D/D2H)耗时、AI Core利用率、内存带宽占用、L1/L2缓存命中率等。这部分是性能数据的金矿。
-
第三层:统一时间轴:这是最难的一步。Host侧是CPU时间,Device侧是NPU时钟,两者不同步。Profiler的核心算法之一就是通过时间戳同步和插值,将这两条时间轴对齐,让你能在TensorBoard上看到一个自上而下、完全对应的调用栈和时间线。这背后是CANN驱动和固件团队做的苦活累活。
⚙️ 2.2 核心用法与“解毒”指南
理论少说,直接上代码,看怎么用,以及更重要的是,怎么“解读”。
# 文件名: realistic_profiler_demo.py
# 环境: PyTorch 1.8+, torch_npu, CANN 7.0+
import torch
import torch_npu
import numpy as np
from torch.profiler import profile, record_function, ProfilerActivity, schedule, tensorboard_trace_handler
def a_heavy_computation(x):
"""一个比较耗时的计算,模拟一个复杂算子"""
with torch.npu.range(“heavy_matmul“):
# 模拟多个计算步骤
for _ in range(10):
x = torch.matmul(x, x.t()) # 反复矩阵乘法
return x
def a_data_pipeline(model, data_loader):
"""一个简单的训练step,包含前向、反向、优化"""
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
model.train()
for batch_idx, (data, target) in enumerate(data_loader):
if batch_idx >= 5: # 只profile前几个batch,预热和稳定状态
break
data, target = data.npu(), target.npu()
# 使用profiler包裹关键区域
with torch.profiler.profile(
activities=[
ProfilerActivity.CPU, # 记录CPU侧活动
ProfilerActivity.NPU, # 记录NPU侧活动
],
schedule=schedule(
wait=1, # 第1个batch跳过,预热
warmup=1, # 第2个batch预热,不计入最终结果
active=2, # 第3、4个batch进行活跃记录
repeat=1
),
on_trace_ready=tensorboard_trace_handler(‘./profiler_logs‘), # 输出到TensorBoard
record_shapes=True, # 记录算子输入形状
profile_memory=True, # 分析内存消耗
with_stack=True # 记录调用栈,方便定位代码
) as prof:
optimizer.zero_grad()
with record_function(“forward_pass“):
output = model(data)
loss = torch.nn.functional.cross_entropy(output, target)
with record_function(“backward_pass“):
loss.backward()
optimizer.step()
prof.step() # 告诉profiler一个step结束
if __name__ == “__main__“:
# 准备一个简单模型和数据
torch.npu.set_device(0)
dummy_model = torch.nn.Sequential(
torch.nn.Linear(1024, 2048).npu(),
torch.nn.ReLU(),
torch.nn.Linear(2048, 512).npu()
)
dummy_loader = [(torch.randn(32, 1024), torch.randint(0, 10, (32,))) for _ in range(10)]
# 运行profiling
a_data_pipeline(dummy_model, dummy_loader)
print(“Profiling 完成。使用命令查看结果: tensorboard --logdir ./profiler_logs“)运行后,打开TensorBoard的“Trace”视图,你会看到类似下图的时光机:

这才是Profiler的正确打开方式。你需要关注的是:
-
Kernel密度与间隙:NPU时间轴上,Kernel是紧密排列,还是有大段空白(Bubble)?空白意味着Host侧准备数据太慢,或者同步操作(如
npu.synchronize())太多,设备在“饿肚子”。这是吞吐上不去的头号杀手。 -
最长耗时Kernel:点击时间条,看详情。是哪个算子最慢?它的输入形状是什么?一个
[1024, 1024]的matmul慢,还是一个[1, 512, 7, 7]的conv2d慢?这直接告诉你优化靶点。 -
内存拷贝占比:
Memcpy (H2D/D2H)操作占了多长时间?理想情况下,它应该被计算完全掩盖。如果拷贝时间很长,就要考虑数据预取、零拷贝、或者计算重构来减少主机与设备间的数据流动。 -
调用栈:点击某个CPU侧活动,查看Python调用栈,能精确定位到是你写的哪一行代码触发了这次耗时操作。
常见Profiler陷阱与解毒:
-
陷阱1:“为什么我Profiler看到的Kernel时间加起来,远小于
npu.synchronize()测出的总时间?”-
解毒:总时间包含了Profiler自身的开销(尤其是记录调用栈时)、CPU调度开销,以及多个Stream之间同步等待的时间。在Trace视图里找那些灰色的“空白”和“cudaStreamSynchronize”之类的标记。
-
-
陷阱2:“我的算子Profiler显示很快,但放进模型里就变慢。”
-
解毒:单个算子快,不代表在计算图里快。可能的原因:a) 算子的输入输出格式不匹配,触发隐式格式转换。b) 算子启动太频繁,Kernel Launch开销成为瓶颈。这时需要用Profiler看整个模型的Trace,而不是孤立的算子。
-
-
陷阱3:“Profiler数据波动很大,每次运行都不一样。”
-
解毒:1) 使用
schedule进行预热,排除首次运行的编译、缓存分配开销。2) 确保测试时系统负载干净。3) 对于NPU,可能涉及到频率调节。在性能测试时,最好用npu-smi工具锁定设备的最高频率。
-
🎯 第三部分 科学Benchmark设计:告别“玩具测试”
Profiler告诉你“哪里慢”,而科学的Benchmark告诉你“整体有多快”以及“快得是否稳定可靠”。很多团队的Benchmark就是跑100次求平均,这远远不够。
📊 3.1 Benchmark设计黄金法则
-
预热(Warm-up)是必须的:NPU和深度学习框架一样,有“懒加载”和缓存机制。第一次运行算子/模型会包含图编译、内存分配、内核编译等一次性开销。必须丢弃前N次(比如50-100次)的运行结果。
-
测量稳定状态,而非瞬时状态:设备可能因为温度升高而降频。短时间冲刺的峰值性能没有意义。应该让测试持续运行一段时间(例如30秒以上),取中间稳定段的性能。
-
考虑多线程/多进程的干扰:生产环境往往是多实例并发。你的Benchmark需要模拟这种场景,测试在多Stream、多线程下的性能 scaling 情况,以及资源竞争带来的性能衰减。
-
定义明确的性能指标:
-
延迟(Latency): P50(中位数), P90, P99(尾延迟)。平均延迟会掩盖毛刺,而P99延迟才是影响用户体验的关键。
-
吞吐(Throughput): 单位时间处理的样本数/请求数。在批处理(Batch)场景下,要测试不同Batch Size下的吞吐曲线,找到“甜蜜点”。
-
资源利用率(Utilization): NPU的AI Core利用率、内存带宽占用率。高利用率不一定代表高效,也可能是遇到了内存墙,在空转等待数据。
-
🧪 3.2 一个工业级的卷积算子Benchmark示例
假设我们优化了一个自定义的DepthwiseConv2dTriton算子,现在要全面评估它。
# 文件名: industrial_benchmark_conv.py
import torch
import torch_npu
import numpy as np
import time
import statistics
from typing import Dict, List
import csv
class DepthwiseConvBenchmark:
def __init__(self, device_id: int = 0):
torch.npu.set_device(device_id)
self.device = f“npu:{device_id}“
# 定义一组有代表性的输入形状 (Batch, Channel, Height, Width)
self.profile_shapes = [
(1, 32, 224, 224), # 移动端小模型
(16, 256, 56, 56), # 中分辨率特征图
(32, 512, 28, 28), # 典型Backbone中间层
(64, 1024, 14, 14), # 大Batch训练场景
]
self.kernel_size = 3
self.padding = 1
self.stride = 1
def _warm_up(self, model, dummy_input, steps: int = 100):
“”“预热,让图编译、缓存等都就绪”“”
print(f“Warming up for {steps} steps...“)
for _ in range(steps):
_ = model(dummy_input)
torch.npu.synchronize() # 确保所有异步操作完成
print(“Warm-up done.“)
def _measure_latency(self, model, dummy_input, num_iterations: int = 500) -> Dict[str, float]:
“”“测量延迟分布,包含异常值过滤”“”
timings = []
# 稳定运行一段时间,排除初期波动
for _ in range(100):
_ = model(dummy_input)
torch.npu.synchronize()
# 正式测量
for _ in range(num_iterations):
start_event = torch.npu.Event(enable_timing=True)
end_event = torch.npu.Event(enable_timing=True)
start_event.record()
_ = model(dummy_input)
end_event.record()
torch.npu.synchronize() # 等待Kernel执行完毕
elapsed_ms = start_event.elapsed_time(end_event)
timings.append(elapsed_ms)
# 去除可能的异常值 (使用IQR方法)
q1, q3 = np.percentile(timings, [25, 75])
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
filtered_timings = [t for t in timings if lower_bound <= t <= upper_bound]
return {
“mean“: statistics.mean(filtered_timings),
“p50“: np.percentile(filtered_timings, 50),
“p90“: np.percentile(filtered_timings, 90),
“p99“: np.percentile(filtered_timings, 99),
“std“: statistics.stdev(filtered_timings) if len(filtered_timings) > 1 else 0.0,
“samples“: len(filtered_timings)
}
def _measure_throughput(self, model, dummy_input, test_duration: float = 5.0) -> float:
“”“测量持续吞吐量 (samples/sec)”“”
num_iterations = 0
start_time = time.time()
while (time.time() - start_time) < test_duration:
_ = model(dummy_input)
num_iterations += 1
torch.npu.synchronize()
total_time = time.time() - start_time
batch_size = dummy_input.shape[0]
throughput = (num_iterations * batch_size) / total_time
return throughput
def run_benchmark(self, our_conv_func, baseline_conv_func=None):
“”“运行完整的Benchmark套件”“”
results = []
for shape in self.profile_shapes:
print(f“\n{‘=‘*50}“)
print(f“Benchmarking shape: {shape}“)
dummy_input = torch.randn(*shape, device=‘npu‘)
# 为depthwise conv准备权重 (groups=in_channels)
in_channels = shape[1]
weight = torch.randn(in_channels, 1, self.kernel_size, self.kernel_size, device=‘npu‘)
# 定义我们的算子和baseline算子
def our_model(x): return our_conv_func(x, weight, padding=self.padding, stride=self.stride, groups=in_channels)
if baseline_conv_func:
def baseline_model(x): return baseline_conv_func(x, weight, padding=self.padding, stride=self.stride, groups=in_channels)
# 测试我们的算子
self._warm_up(our_model, dummy_input)
latency_stats = self._measure_latency(our_model, dummy_input)
throughput = self._measure_throughput(our_model, dummy_input)
result = {
“shape“: shape,
“operator“: “our_depthwise_conv“,
“latency_mean_ms“: latency_stats[“mean“],
“latency_p99_ms“: latency_stats[“p99“],
“throughput_samples_per_sec“: throughput,
}
# 如果有baseline,进行对比
if baseline_conv_func:
self._warm_up(baseline_model, dummy_input)
base_latency = self._measure_latency(baseline_model, dummy_input)
base_throughput = self._measure_throughput(baseline_model, dummy_input)
result.update({
“baseline_latency_mean_ms“: base_latency[“mean“],
“baseline_latency_p99_ms“: base_latency[“p99“],
“baseline_throughput“: base_throughput,
“speedup_latency“: base_latency[“mean“] / latency_stats[“mean“],
“speedup_throughput“: throughput / base_throughput,
})
print(f“Our Op - Latency: {latency_stats[‘mean‘]:.3f}ms (P99: {latency_stats[‘p99‘]:.3f}ms), Throughput: {throughput:.0f} samples/sec“)
print(f“Baseline - Latency: {base_latency[‘mean‘]:.3f}ms (P99: {base_latency[‘p99‘]:.3f}ms), Throughput: {base_throughput:.0f} samples/sec“)
print(f“Speedup - Latency: {result[‘speedup_latency‘]:.2f}x, Throughput: {result[‘speedup_throughput‘]:.2f}x“)
else:
print(f“Our Op - Latency: {latency_stats[‘mean‘]:.3f}ms (P99: {latency_stats[‘p99‘]:.3f}ms), Throughput: {throughput:.0f} samples/sec“)
results.append(result)
# 输出结果到CSV
self._save_results_to_csv(results)
return results
def _save_results_to_csv(self, results: List[Dict], filename: str = “conv_benchmark_results.csv“):
keys = results[0].keys()
with open(filename, ‘w‘, newline=‘‘) as f:
writer = csv.DictWriter(f, fieldnames=keys)
writer.writeheader()
writer.writerows(results)
print(f“\nDetailed results saved to {filename}“)
# 假设这是我们用Triton写的自定义深度可分离卷积
def our_triton_depthwise_conv(input, weight, padding, stride, groups):
# 这里是你的Triton Kernel调用
# output = call_triton_kernel(input, weight, ...)
# 为演示,我们用PyTorch原生替代
return torch.nn.functional.conv2d(input, weight, padding=padding, stride=stride, groups=groups)
# Baseline使用PyTorch原生实现
def pytorch_native_depthwise_conv(input, weight, padding, stride, groups):
return torch.nn.functional.conv2d(input, weight, padding=padding, stride=stride, groups=groups)
if __name__ == “__main__“:
benchmark = DepthwiseConvBenchmark(device_id=0)
# 比较我们的实现和PyTorch原生实现
results = benchmark.run_benchmark(our_triton_depthwise_conv, pytorch_native_depthwise_conv)这个Benchmark的“科学”之处在于:
-
多形状覆盖:测试了从移动端到大Batch训练的不同场景,性能表现可能截然不同。
-
完整的延迟分析:不仅看平均值,更关注P99尾延迟和标准差(波动性)。一个延迟均值低但P99很高的算子,在线服务中就是灾难。
-
吞吐测试:独立进行一段时间的持续压力测试,反映算子在高负载下的稳定性能。
-
自动对比与归档:自动对比baseline,计算加速比,并将结果保存为CSV,便于后续追踪性能和回归测试。
常见Benchmark陷阱:
-
陷阱:“我在一个循环里跑1000次,每次迭代都
npu.synchronize(),然后取平均。”-
问题:
synchronize()本身有开销,且完全串行化了执行,无法测出NPU异步执行和多个Kernel潜在的重叠能力。应该像上面示例一样,在循环内用Event计时,循环外加一个总的synchronize。
-
-
陷阱:只测一种固定的、对自家算子有利的输入形状。
-
问题:没有普适性。必须测试一个形状空间,包括极端大小(如
[1,1,1,1])、典型大小和边界大小。
-
🚀 第四部分 高级应用:从看懂到调优的实战跃迁
当你熟练使用Profiler定位瓶颈,并用Benchmark量化性能后,就进入了真正的“高手局”:系统性优化。
🏢 4.1 企业级案例:大模型推理服务端优化
场景:某公司使用昇腾910集群部署千亿参数大模型,提供实时问答服务。初期QPS不达标,P99延迟高达500ms。
优化过程:
-
Profiler全局分析:
-
用
torch_npu.profiler抓取一个完整请求的Trace。 -
发现1:
MemcpyH2D(用户输入上板)和MemcpyD2H(结果返回)占了单次请求近30%的时间。这属于明显的IO瓶颈。 -
发现2:在Self-Attention计算部分,有大量细小的
Element-wiseKernel(如add,mul,softmax),Kernel Launch开销显著。时间线呈现“稀疏”状。
-
-
优化实施:
-
针对发现1:流水线与缓存:
-
实现输入缓存池:将热点问题的输入和对应的
NPU Tensor缓存下来,下次相同问题直接使用设备内存数据,省去H2D。 -
使用双缓冲技术:当NPU正在计算当前请求时,Host线程同时准备下一个请求的数据,实现计算与数据搬运的重叠。
-
-
针对发现2:算子融合:
-
将Self-Attention中的
(Q*K^T) / sqrt(dim) + mask -> softmax -> dropout -> *V这一系列操作,编写一个融合的Triton-Ascend算子。将多个Launch和多次内存读写,合并为1个Launch和1次计算。 -
使用CANN的图优化(如果模型是静态图)自动完成部分融合。
-
-
-
Benchmark验证:
-
优化后,设计新的Benchmark,模拟真实流量(请求大小不一,间隔随机)。
-
测量指标:在目标QPS压力下,P99延迟是否低于200ms的SLA。
-
结果:P99延迟从500ms降至150ms,QPS提升40%,同时CPU利用率还下降了。
-
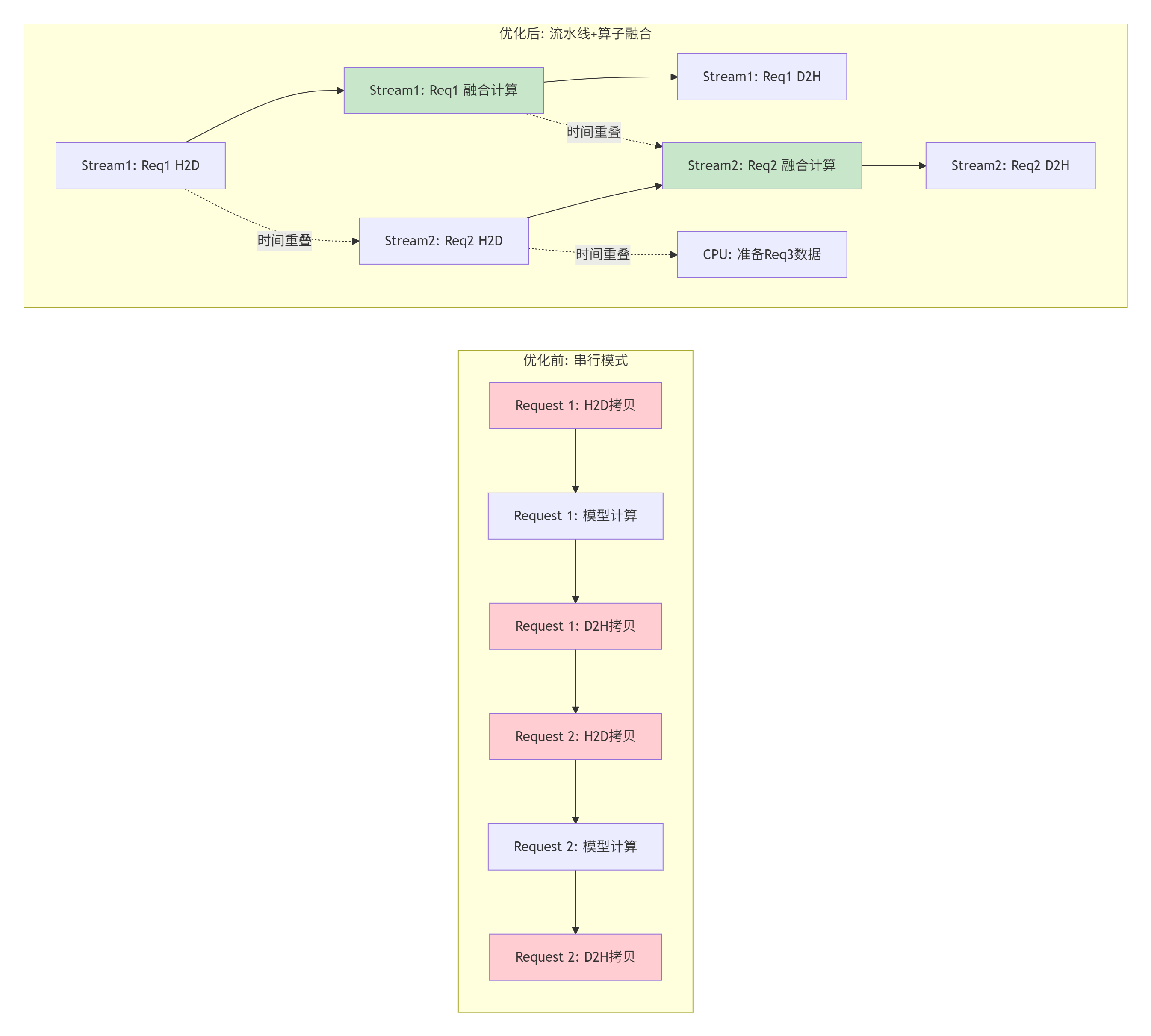
上图左半边优化前,大量时间花在数据拷贝(红色)上,且请求串行。右半边优化后,通过多Stream实现拷贝与计算的重叠(绿色为融合后的计算内核),并通过CPU预准备进一步隐藏延迟。
🧰 4.2 性能优化技巧清单
-
计算密集型算子:
-
看AI Core利用率:在Profiler中如果看到Kernel执行时间长但利用率不高,尝试调整Block Size和Grid Size,让更多的计算核心有活干。
-
利用Tensor Core:确保你的矩阵乘/卷积算子使用了
mma指令或调用了CANN的加速库(如te/gemm),检查Profiler中该Kernel是否标注了tensor core。
-
-
访存密集型算子:
-
看内存带宽:如果Kernel时间大部分花在等待数据上,优化内存访问模式。确保是连续访问,尽量使用向量化加载/存储指令。在Ascend C中,合理使用
__gm__、__ub__和乒乓操作。 -
减少临时内存:检查Profiler的
Memory视图,看是否有预料之外的峰值内存使用。尝试in-place操作或更优的算法减少中间变量。
-
-
Kernel Launch开销:
-
小算子融合:这是提升性能的黄金法则。将多个element-wise操作融合成一个Kernel。
-
使用持久化Kernel:对于一些需要反复启动、参数变化不大的小型Kernel,可以写成持久化形式,减少启动开销。
-
🔧 4.3 故障排查指南
-
Profiler不显示NPU活动:
-
检查
torch_npu版本和CANN版本是否匹配。 -
检查环境变量
export ASCEND_SLOG_PRINT_TO_STDOUT=0和export ASCEND_GLOBAL_LOG_LEVEL=1是否设置正确(通常需要关闭或降低日志级别,避免干扰)。 -
确保运行用户有访问
/dev/davinciX等NPU设备的权限。
-
-
Benchmark结果不稳定,方差大:
-
系统干扰:用
npu-smi检查是否有其他进程占用NPU。用perf或top检查CPU负载。 -
频率缩放:使用
npu-smi -i 0 -f performance将NPU工作模式设置为最大性能(注意功耗和散热)。 -
缓存效应:确保有足够的预热,并且测试数据不要太小,避免全部命中缓存导致数据失真。可以尝试使用随机数据,并且每次迭代稍微改变数据地址(如使用不同偏移量)。
-
-
自定义Triton算子性能不如预期:
-
对比基线:先用
torch_npu.profiler对比你的算子和等价的PyTorch原生算子/其他优化库算子的Trace。看时间差在哪里。 -
检查Kernel配置:你的
BLOCK_SIZE、num_warps等参数是否合理?用Profiler看 occupancy(占用率)。 -
检查内存访问:是否存在bank conflict?是否用到了共享内存?访问是否合并?这部分需要结合Ascend C的SASS(汇编)级分析,比较深入。
-
🔮 结语:建立性能信仰
性能调优不是玄学,而是一门可观测、可分析、可复现的工程科学。torch_npu.profiler和科学的Benchmark,就是这门科学中最锐利的工具。它们帮你把模糊的“感觉慢”变成精确的“哪个算子、在哪种输入下、慢了百分之多少”,把“好像快了”变成“吞吐提升42%,P99延迟降低60%”。
在昇腾生态中深耕,切记:不要相信没有Profile数据的优化,也不要相信没有稳定Benchmark结果的上线。用数据驱动决策,让每一次性能提升都掷地有声。随着CANN和Triton-Ascend生态的不断完善,这套方法论将成为你在异构计算时代构建高性能AI应用的必备技能。
📚 参考链接与资源
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 15
15 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)