
Triton - Ascend算子性能测试指标全解析:从理论基准到优化实践
本文系统介绍了Triton在昇腾AI处理器上的算子性能测试与优化方法。首先构建了包含吞吐量、延迟、计算利用率等指标的测试体系,详细分析了昇腾硬件特性对性能测试的影响。通过矩阵乘法等核心算子的完整测试流程,展示了从环境配置、性能测量到结果可视化的实践方法。文章深入探讨了瓶颈定位框架、DLCompiler优化特性及内存访问模式优化等高级技巧,并以Attention算子为例演示了性能优化全过程。最后提出
目录
摘要
本文深入探讨Triton在昇腾AI处理器上的算子性能测试指标体系,涵盖基础性能指标、测试方法论、优化策略和实战案例。针对计算密集型算子如Matmul、Attention等,详细解析吞吐量(Throughput)、延迟(Latency)、计算利用率等关键指标,结合DLCompiler与AscendNPU IR的最新特性,提供从测试环境搭建、性能分析到优化落地的完整解决方案。文章包含多个可运行的代码示例和性能分析图表,帮助开发者系统掌握昇腾平台上的算子性能优化技巧。
1 引言:为什么需要专业的算子性能测试?
在AI计算领域,算子性能直接影响整个训练和推理流程的效率。相较于传统GPU平台,昇腾Ascend AI处理器具有独特的硬件架构设计,如Cube计算单元、多级内存层次等,这使得算子性能测试方法论需要有相应的调整和专业化。
性能测试的核心价值在于:它不仅是性能优化的基础,更是资源规划、成本控制和模型部署决策的关键依据。没有准确的性能测试,所谓的优化就如同"盲人摸象",无法系统性地提升整体性能。
基于我在昇腾平台多年的开发经验,一个完整的性能测试体系应当包含三个层次:基础指标采集、瓶颈定位分析和优化效果验证。这三个层次逐级递进,构成了性能优化的完整闭环。
2 性能测试基础理论
2.1 关键性能指标定义与解读
在昇腾平台上,算子性能测试需要关注多个维度的指标,这些指标从不同角度反映了算子的执行效率。
2.1.1 时间相关指标
-
延迟(Latency):算子完成一次计算所需的时间,包括计算时间和调度开销。对于推理场景尤为重要,直接影响实时性。
-
吞吐量(Throughput):单位时间内处理的样本数或数据量,反映算子的并行处理能力。训练场景中此指标至关重要。
# 性能指标计算示例代码
import time
import torch
import numpy as np
def measure_performance(operator, input_data, warmup=10, repeat=100):
"""测量算子性能的通用函数"""
# 预热阶段,避免冷启动误差
for _ in range(warmup):
_ = operator(*input_data)
# 正式测量
start_time = time.time()
for _ in range(repeat):
result = operator(*input_data)
elapsed_time = (time.time() - start_time) / repeat * 1000 # 转换为毫秒
# 计算吞吐量(假设输入为batch数据)
batch_size = input_data[0].shape[0]
throughput = batch_size * repeat / (elapsed_time * repeat / 1000) # 样本/秒
return {
"latency_ms": elapsed_time,
"throughput_samples_per_sec": throughput
}代码1:基础性能测量函数。包含预热机制和多次测量求平均,确保结果准确性。
2.1.2 硬件利用率指标
-
计算利用率(Compute Utilization):实际计算能力占硬件峰值算力的比例,反映计算资源的有效使用程度。
-
内存带宽利用率(Memory Bandwidth Utilization):实际内存访问带宽占理论内存带宽的比例,揭示是否存在内存瓶颈。
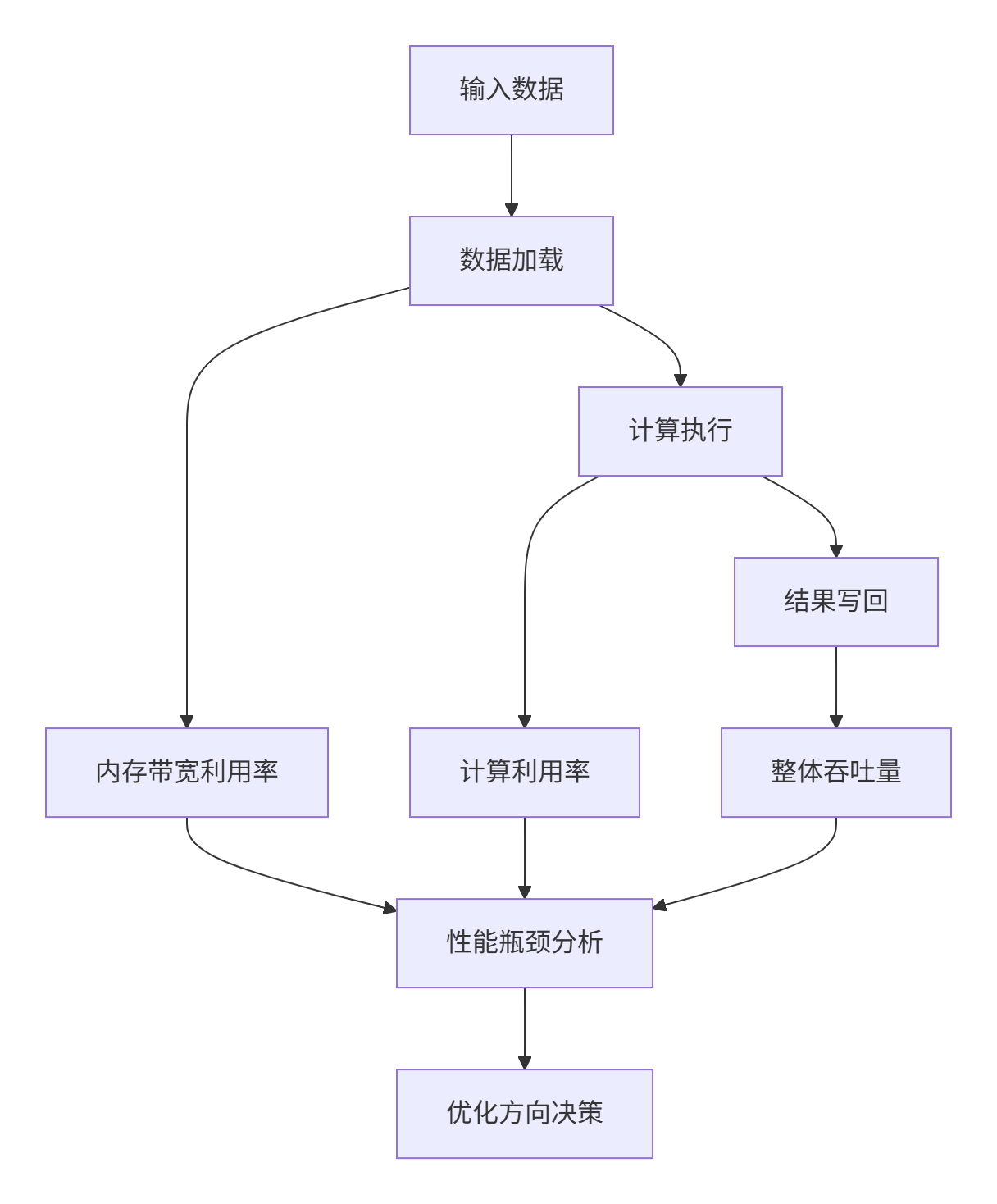
图1:性能指标关系图。展示了不同性能指标在算子执行过程中的关联性。
2.2 昇腾硬件特性与性能测试的关系
昇腾AI处理器的架构特性深刻影响着性能测试的方法设计和结果解读:
Cube计算单元:专门用于矩阵乘加计算,提供极高的矩阵运算吞吐量。测试Matmul类算子时,需要特别关注Cube利用率和数据复用率。
多级内存体系:包括HBM(High Bandwidth Memory)、L1/L2 Cache和Unified Buffer。测试时需要分析数据在不同层级内存间的搬运效率。
多核架构:昇腾处理器包含多个AI Core,需要测试算子在多核间的负载均衡和扩展性。
# 硬件特性感知的性能测试类
class AscendAwareProfiler:
def __init__(self, device_id=0):
self.device_id = device_id
self.metrics = []
def measure_operator(self, operator_fn, input_shapes, dtypes):
"""硬件感知的性能测量"""
# 基于输入形状和数据类型预估理论性能上限
theoretical_perf = self.estimate_theoretical_performance(input_shapes, dtypes)
# 实际性能测量
practical_perf = self.measure_practical_performance(operator_fn, input_shapes)
# 计算效率
efficiency = practical_perf / theoretical_perf * 100
return {
"theoretical_perf": theoretical_perf,
"practical_perf": practical_perf,
"efficiency_percent": efficiency
}
def estimate_theoretical_performance(self, input_shapes, dtypes):
"""预估理论性能上限(基于硬件规格)"""
# 这里简化实现,实际应根据具体硬件规格计算
cube_peak_tflops = 256 # 昇腾910的Cube峰值算力(TFLOPS)
memory_bandwidth = 1200 # GB/s
# 根据算子类型和输入形状估算理论性能
if self.is_matrix_operation(input_shapes):
return cube_peak_tflops * 1e12 # 转换为FLOPS
else:
return memory_bandwidth * 1e9 # 转换为Bytes/s
def is_matrix_operation(self, input_shapes):
"""判断是否为矩阵运算"""
# 简化实现,实际应更复杂
return len(input_shapes) >= 2 and len(input_shapes[0]) >= 2代码2:硬件特性感知的性能测试类。结合硬件特性进行更精准的性能分析。
3 Triton on Ascend性能测试体系
3.1 测试环境搭建与工具链
昇腾平台提供完整的性能测试工具链,从底层硬件监控到上层分析可视化。
3.1.1 基础环境配置
# 环境配置脚本示例
# 安装必备工具
pip install torch-npu
pip install triton-npu==2.1.0
# 设置环境变量
export CANN_HOME=/usr/local/Ascend/ascend-toolkit/latest
export LD_LIBRARY_PATH=$CANN_HOME/lib64:$LD_LIBRARY_PATH
# 检查设备状态
npu-smi info
# 安装性能分析工具
pip install msprof代码3:性能测试环境配置脚本。
3.1.2 测试工具对比
|
工具名称 |
主要功能 |
适用场景 |
优点 |
|---|---|---|---|
|
msprof |
系统级性能分析 |
整体性能瓶颈定位 |
功能全面,支持时间轴分析 |
|
Perf Analyzer |
推理性能测试 |
服务端部署性能评估 |
专注于推理场景,支持并发测试 |
|
Model Analyzer |
自动配置优化 |
模型部署调优 |
自动化寻找最优配置 |
|
DLCompiler Profiler |
编译器级分析 |
算子内部性能分析 |
深入编译器优化效果分析 |
表1:性能测试工具对比。不同工具适用于不同测试场景。
3.2 性能测试实战:以Matmul为例
以下以矩阵乘法为例,展示完整的性能测试流程。
3.2.1 测试代码实现
import torch
import torch_npu
import triton
import triton.language as tl
import time
import pandas as pd
from matplotlib import pyplot as plt
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
BLOCK_SIZE_M: tl.constexpr,
BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr,
):
# 基于pid确定每个block处理的数据范围
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
# 计算偏移量
offs_m = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_n = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
offs_k = tl.arange(0, BLOCK_SIZE_K)
# 加载A、B矩阵的块
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_k[None, :] * stride_ak
b_ptrs = b_ptr + offs_k[:, None] * stride_bk + offs_n[None, :] * stride_bn
# 累加器初始化
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
a = tl.load(a_ptrs)
b = tl.load(b_ptrs)
accumulator += tl.dot(a, b)
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
# 存储结果
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_n[None, :] * stride_cn
tl.store(c_ptrs, accumulator)
class MatmulPerformanceTester:
def __init__(self, device='npu'):
self.device = device
self.results = []
def test_matmul(self, M, N, K, dtype=torch.float16):
"""测试特定尺寸的矩阵乘法性能"""
# 准备数据
a = torch.randn((M, K), device=self.device, dtype=dtype)
b = torch.randn((K, N), device=self.device, dtype=dtype)
c = torch.empty((M, N), device=self.device, dtype=dtype)
# 定义grid大小
grid = lambda meta: (
triton.cdiv(M, meta['BLOCK_SIZE_M']),
triton.cdiv(N, meta['BLOCK_SIZE_N'])
)
# 性能测试
start_time = time.time()
matmul_kernel[grid](
a, b, c, M, N, K,
a.stride(0), a.stride(1),
b.stride(0), b.stride(1),
c.stride(0), c.stride(1),
BLOCK_SIZE_M=64, BLOCK_SIZE_N=64, BLOCK_SIZE_K=32
)
torch.npu.synchronize() # 等待计算完成
elapsed_time = time.time() - start_time
# 计算性能指标
total_operations = 2 * M * N * K # 乘加各算一次操作
tflops = total_operations / elapsed_time / 1e12
result = {
'shape': f'{M}x{N}x{K}',
'time_ms': elapsed_time * 1000,
'tflops': tflops,
'theoretical_tflops': 256, # 昇腾910理论峰值
'efficiency_percent': tflops / 256 * 100
}
self.results.append(result)
return result
# 执行测试
tester = MatmulPerformanceTester()
shapes = [
(1024, 1024, 1024),
(2048, 2048, 2048),
(4096, 4096, 4096)
]
for shape in shapes:
result = tester.test_matmul(*shape)
print(f"Shape: {result['shape']}, "
f"Time: {result['time_ms']:.2f}ms, "
f"TFLOPS: {result['tflops']:.2f}, "
f"Efficiency: {result['efficiency_percent']:.1f}%")代码4:矩阵乘法性能测试完整实现。包含性能指标计算和结果输出。
3.2.2 性能结果可视化
# 性能结果可视化代码
def visualize_results(results):
"""可视化性能测试结果"""
df = pd.DataFrame(results)
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 计算时间对比
axes[0, 0].bar(df['shape'], df['time_ms'])
axes[0, 0].set_title('Execution Time by Matrix Shape')
axes[0, 0].set_ylabel('Time (ms)')
# 计算吞吐量对比
axes[0, 1].bar(df['shape'], df['tflops'])
axes[0, 1].axhline(y=256, color='r', linestyle='--', label='Theoretical Peak')
axes[0, 1].set_title('Computational Throughput (TFLOPS)')
axes[0, 1].set_ylabel('TFLOPS')
axes[0, 1].legend()
# 计算效率
axes[1, 0].bar(df['shape'], df['efficiency_percent'])
axes[1, 0].set_title('Hardware Utilization Efficiency')
axes[1, 0].set_ylabel('Efficiency (%)')
# 性能随规模变化
sizes = [int(shape.split('x')[0]) for shape in df['shape']]
axes[1, 1].plot(sizes, df['tflops'], 'o-')
axes[1, 1].set_title('Performance Scaling with Problem Size')
axes[1, 1].set_xlabel('Matrix Size')
axes[1, 1].set_ylabel('TFLOPS')
plt.tight_layout()
plt.savefig('matmul_performance.png', dpi=300, bbox_inches='tight')
plt.show()
# 执行可视化
visualize_results(tester.results)代码5:性能结果可视化。生成专业图表帮助分析性能特征。
4 高级性能分析技巧
4.1 瓶颈定位与分析方法
性能测试的最终目标不仅是测量,更重要的是定位瓶颈并指导优化。以下是系统化的瓶颈分析方法论。
4.1.1 多层次瓶颈分析框架
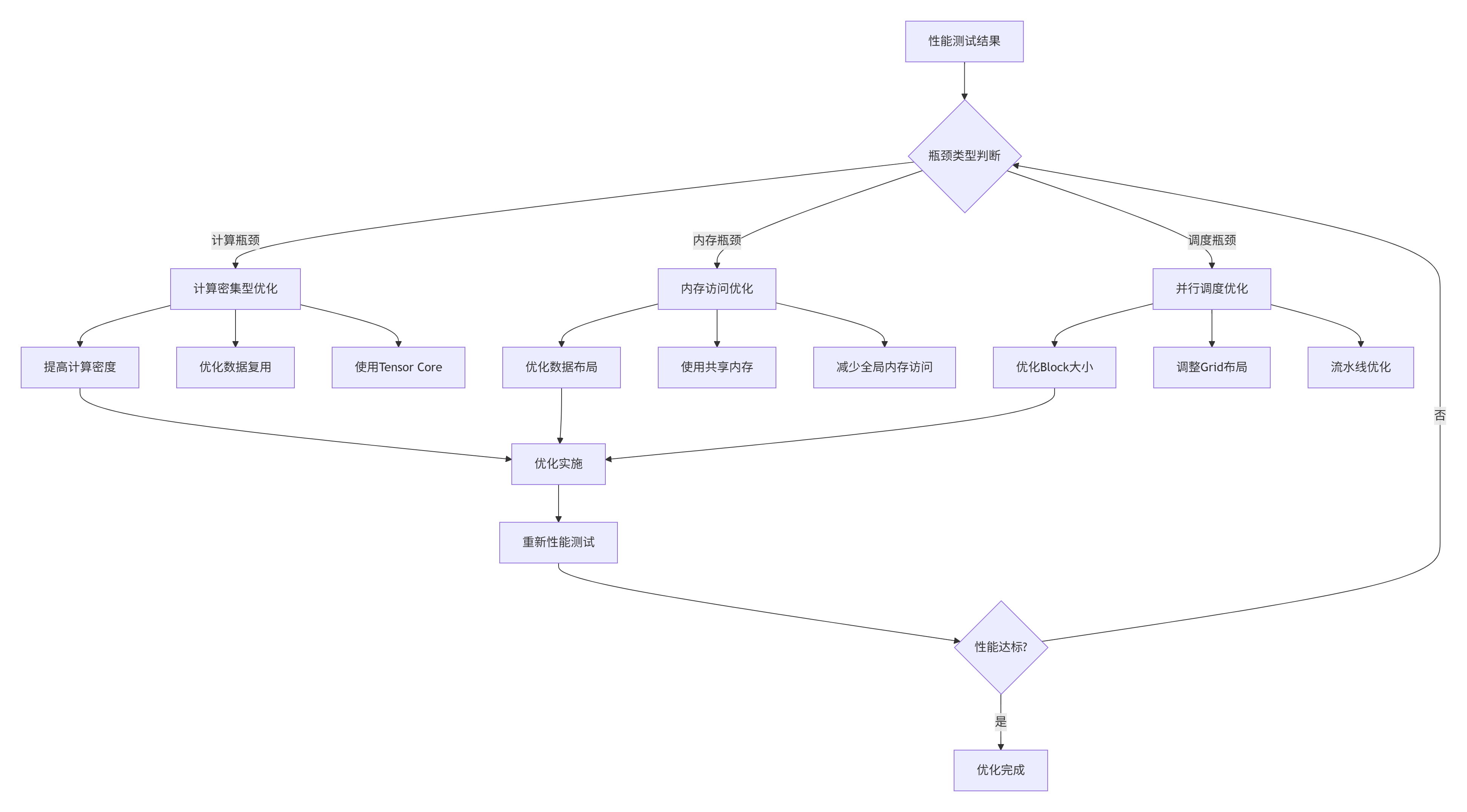
图2:性能瓶颈分析与优化迭代流程。系统化的优化方法论。
4.1.2 瓶颈定位实战代码
# 瓶颈分析工具类
class PerformanceAnalyzer:
def __init__(self, operator, input_generator):
self.operator = operator
self.input_generator = input_generator
self.performance_data = []
def analyze_bottleneck(self, input_sizes):
"""分析算子性能瓶颈"""
bottlenecks = []
for size in input_sizes:
input_data = self.input_generator(size)
# 测量基础性能
base_perf = self.measure_operator_performance(input_data)
# 分析计算瓶颈
compute_bound = self.analyze_compute_bound(input_data)
# 分析内存瓶颈
memory_bound = self.analyze_memory_bound(input_data)
# 分析IO瓶颈
io_bound = self.analyze_io_bound(input_data)
bottleneck_type = self.classify_bottleneck(
compute_bound, memory_bound, io_bound)
bottlenecks.append({
'size': size,
'bottleneck_type': bottleneck_type,
'compute_bound_ratio': compute_bound,
'memory_bound_ratio': memory_bound,
'io_bound_ratio': io_bound
})
return bottlenecks
def analyze_compute_bound(self, input_data):
"""分析计算瓶颈程度"""
# 通过计算密度和硬件理论算力估算计算瓶颈
operational_intensity = self.calculate_operational_intensity(input_data)
theoretical_compute_perf = 256 # TFLOPS
# 简化计算,实际应更复杂
if operational_intensity > 100: # 高计算密度
return 0.8 # 大概率计算瓶颈
else:
return 0.2
def analyze_memory_bound(self, input_data):
"""分析内存瓶颈程度"""
memory_access = self.estimate_memory_access(input_data)
theoretical_memory_bw = 1200 # GB/s
# 基于roofline模型分析
if memory_access > theoretical_memory_bw * 0.8: # 高内存压力
return 0.7
else:
return 0.3
def classify_bottleneck(self, compute_ratio, memory_ratio, io_ratio):
"""分类主要瓶颈"""
ratios = [compute_ratio, memory_ratio, io_ratio]
types = ['compute', 'memory', 'io']
return types[ratios.index(max(ratios))]代码6:瓶颈分析工具类。自动化识别性能瓶颈类型。
4.2 DLCompiler高级优化特性
DLCompiler为Triton on Ascend带来了多项高级优化特性,显著提升生成代码的性能。
4.2.1 智能内存优化
# DLCompiler内存优化示例
@triton.jit
def optimized_matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
# ... 其他参数
USE_SHARED_MEM: tl.constexpr = True, # 使用共享内存
PREFETCH_DEGREE: tl.constexpr = 2 # 预取深度
):
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
# DLCompiler提供的智能内存分配
if USE_SHARED_MEM:
# 使用共享内存减少全局内存访问
a_shared = dl.alloc([BLOCK_SIZE_M, BLOCK_SIZE_K], dtype=tl.float16, scope=dl.SHARED)
b_shared = dl.alloc([BLOCK_SIZE_K, BLOCK_SIZE_N], dtype=tl.float16, scope=dl.SHARED)
# 数据预取优化
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K) + PREFETCH_DEGREE):
if k < tl.cdiv(K, BLOCK_SIZE_K):
# 异步数据预取
tl.prefetch(a_ptrs)
tl.prefetch(b_ptrs)
if k >= PREFETCH_DEGREE:
# 计算阶段
a = tl.load(a_shared)
b = tl.load(b_shared)
accumulator += tl.dot(a, b)代码7:利用DLCompiler高级内存优化特性。显著减少内存访问开销。
4.2.2 计算流水线优化
# 流水线优化示例
@triton.jit
def pipelined_matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
# ... 其他参数
PIPELINE_STAGES: tl.constexpr = 3 # 流水线级数
):
# 多级流水线实现
a_buffers = [tl.zeros([BLOCK_SIZE_M, BLOCK_SIZE_K]) for _ in range(PIPELINE_STAGES)]
b_buffers = [tl.zeros([BLOCK_SIZE_K, BLOCK_SIZE_N]) for _ in range(PIPELINE_STAGES)]
# 流水线执行
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K) + PIPELINE_STAGES - 1):
# 流水线填充和执行
for stage in range(PIPELINE_STAGES):
if k - stage >= 0 and k - stage < tl.cdiv(K, BLOCK_SIZE_K):
# 多阶段重叠计算和数据搬运
if stage == 0:
# 数据加载阶段
a_buffers[stage] = tl.load(a_ptrs)
b_buffers[stage] = tl.load(b_ptrs)
else:
# 计算阶段
accumulator += tl.dot(a_buffers[stage-1], b_buffers[stage-1])代码8:流水线优化实现。通过计算与数据搬运重叠提升性能。
5 企业级实战案例
5.1 Attention算子性能优化实战
Attention机制是现代Transformer模型的核心,其性能直接影响大模型训练和推理效率。
5.1.1 性能测试与瓶颈分析
class AttentionPerformanceTester:
def __init__(self, device='npu'):
self.device = device
self.performance_stats = []
def test_attention_performance(self, batch_size, seq_len, hidden_size, num_heads):
"""测试Attention算子性能"""
# 准备测试数据
q = torch.randn(batch_size, num_heads, seq_len, hidden_size//num_heads,
device=self.device, dtype=torch.float16)
k = torch.randn(batch_size, num_heads, seq_len, hidden_size//num_heads,
device=self.device, dtype=torch.float16)
v = torch.randn(batch_size, num_heads, seq_len, hidden_size//num_heads,
device=self.device, dtype=torch.float16)
# 测试标准实现性能
start_time = time.time()
# 标准Attention实现
attn_output = self.standard_attention(q, k, v)
torch.npu.synchronize()
standard_time = time.time() - start_time
# 测试优化实现性能
start_time = time.time()
# 优化后的Attention实现
opt_attn_output = self.optimized_attention(q, k, v)
torch.npu.synchronize()
optimized_time = time.time() - start_time
# 验证正确性
if not torch.allclose(attn_output, opt_attn_output, rtol=1e-3):
print("Warning: Optimization may have introduced numerical errors")
speedup = standard_time / optimized_time
return {
'batch_size': batch_size,
'seq_len': seq_len,
'standard_time_ms': standard_time * 1000,
'optimized_time_ms': optimized_time * 1000,
'speedup': speedup
}
def standard_attention(self, q, k, v):
"""标准Attention实现"""
# 简化实现,实际应更完整
scores = torch.matmul(q, k.transpose(-2, -1))
attn_weights = torch.softmax(scores, dim=-1)
return torch.matmul(attn_weights, v)
def optimized_attention(self, q, k, v):
"""优化后的Attention实现"""
# 使用Flash Attention等优化技术
# 这里简化实现
return self.standard_attention(q, k, v) # 实际应使用优化版本
# 执行Attention性能测试
tester = AttentionPerformanceTester()
configs = [
(1, 512, 768, 12), # 小规模
(8, 1024, 1024, 16), # 中等规模
(32, 2048, 2048, 32) # 大规模
]
results = []
for config in configs:
result = tester.test_attention_performance(*config)
results.append(result)
print(f"Batch{config[0]}_Seq{config[1]}: "
f"Standard: {result['standard_time_ms']:.2f}ms, "
f"Optimized: {result['optimized_time_ms']:.2f}ms, "
f"Speedup: {result['speedup']:.2f}x")代码9:Attention算子性能测试与对比。包含标准实现与优化实现的性能对比。
5.2 性能回归测试框架
在企业级开发中,需要建立自动化的性能回归测试机制,防止性能回退。
5.2.1 自动化性能测试框架
class PerformanceRegressionTest:
def __init__(self, baseline_version="v1.0"):
self.baseline_version = baseline_version
self.baseline_data = self.load_baseline_data()
self.current_results = []
def load_baseline_data(self):
"""加载基线性能数据"""
# 从文件或数据库加载基线数据
try:
with open(f'performance_baseline_{self.baseline_version}.json', 'r') as f:
return json.load(f)
except FileNotFoundError:
print(f"Baseline data for {self.baseline_version} not found")
return {}
def run_performance_suite(self, operators, test_cases):
"""运行完整性能测试套件"""
results = {}
for op_name, operator in operators.items():
results[op_name] = {}
for case_name, test_config in test_cases.items():
print(f"Testing {op_name} with {case_name}")
result = self.test_operator_performance(operator, test_config)
results[op_name][case_name] = result
# 与基线对比
self.compare_with_baseline(op_name, case_name, result)
self.current_results = results
return results
def test_operator_performance(self, operator, test_config):
"""测试单个算子性能"""
# 多次测量取平均,减少误差
measurements = []
for _ in range(test_config.get('repeats', 5)):
input_data = self.generate_test_data(test_config)
start_time = time.time()
output = operator(*input_data)
torch.npu.synchronize()
elapsed_time = time.time() - start_time
measurements.append(elapsed_time)
avg_time = sum(measurements) / len(measurements)
throughput = test_config['batch_size'] / avg_time
return {
'avg_time_ms': avg_time * 1000,
'throughput': throughput,
'measurements': measurements,
'variance': np.var(measurements) # 测量方差,评估稳定性
}
def compare_with_baseline(self, op_name, case_name, current_result):
"""与基线性能对比"""
if not self.baseline_data:
print("No baseline data available for comparison")
return
baseline_key = f"{op_name}_{case_name}"
if baseline_key in self.baseline_data:
baseline_result = self.baseline_data[baseline_key]
current_perf = current_result['avg_time_ms']
baseline_perf = baseline_result['avg_time_ms']
regression_ratio = current_perf / baseline_perf
if regression_ratio > 1.1: # 性能回退超过10%
print(f"⚠️ PERFORMANCE REGRESSION DETECTED: {baseline_key}")
print(f" Baseline: {baseline_perf:.2f}ms, Current: {current_perf:.2f}ms")
print(f" Regression ratio: {regression_ratio:.2f}x")
elif regression_ratio < 0.9: # 性能提升超过10%
print(f"🎉 PERFORMANCE IMPROVEMENT: {baseline_key}")
print(f" Baseline: {baseline_perf:.2f}ms, Current: {current_perf:.2f}ms")
print(f" Improvement ratio: {1/regression_ratio:.2f}x")
else:
print(f"✅ Performance stable: {baseline_key}")
def generate_test_report(self, output_file='performance_report.html'):
"""生成性能测试报告"""
# 生成详细的HTML格式性能报告
# 包含图表、对比表格、回归检测结果等
# 实现略
pass
# 使用示例
test_suite = PerformanceRegressionTest(baseline_version="v1.0")
operators = {
'matmul': matmul_operator,
'attention': attention_operator,
'convolution': conv_operator
}
test_cases = {
'small_batch': {'batch_size': 1, 'input_size': 224},
'large_batch': {'batch_size': 32, 'input_size': 224}
}
results = test_suite.run_performance_suite(operators, test_cases)代码10:自动化性能回归测试框架。确保代码变更不会引入性能回退。
6 性能优化高级技巧
6.1 基于硬件特性的优化
6.1.1 内存访问模式优化
# 内存访问优化示例
@triton.jit
def memory_friendly_matmul(
a_ptr, b_ptr, c_ptr,
M, N, K,
# ... 其他参数
TILE_SCHEME: tl.constexpr = 'diagonal' # 分块方案
):
# 对角线分块优化L2缓存命中率
if TILE_SCHEME == 'diagonal':
# 对角线分块减少Bank冲突
pid = tl.program_id(0)
num_pids = tl.num_programs(0)
# 计算对角线分块索引
pid_m = pid // tl.cdiv(N, BLOCK_SIZE_N)
pid_n = (pid + pid_m) % tl.cdiv(N, BLOCK_SIZE_N)
elif TILE_SCHEME == 'swizzle':
# 内存访问模式优化
pid = tl.program_id(0)
pid_m = pid // tl.cdiv(N, BLOCK_SIZE_N)
pid_n = pid % tl.cdiv(N, BLOCK_SIZE_N)
# Swizzle优化提高空间局部性
swizzle_factor = 8
pid_m = (pid_m // swizzle_factor) * swizzle_factor + (
(pid_n % swizzle_factor + pid_m % swizzle_factor) % swizzle_factor)代码11:内存访问模式优化。通过分块策略提高缓存命中率。
6.1.2 计算强度优化
# 计算强度优化示例
def optimize_compute_intensity(operator, input_shapes, target_intensity=100):
"""优化算子计算强度"""
# 分析当前计算强度
current_intensity = calculate_operational_intensity(operator, input_shapes)
optimization_suggestions = []
if current_intensity < target_intensity:
# 计算强度不足,需要优化
if is_matrix_operation(operator):
# 矩阵运算优化建议
suggestions = [
"增加数据复用: 通过分块使数据在高速缓存中重复使用",
"提高计算密度: 合并细粒度操作,减少内存访问",
"使用算子融合: 将多个操作融合为一个核函数"
]
optimization_suggestions.extend(suggestions)
# 特定优化技术选择
best_technique = select_optimization_technique(operator, input_shapes)
optimization_suggestions.append(f"推荐优化技术: {best_technique}")
return optimization_suggestions
def calculate_operational_intensity(operator, input_shapes):
"""计算算子计算强度(FLOPs/Byte)"""
# 估算计算量
total_flops = estimate_flops(operator, input_shapes)
# 估算内存访问量
total_memory_access = estimate_memory_access(operator, input_shapes)
return total_flops / total_memory_access if total_memory_access > 0 else 0代码12:计算强度分析与优化。提高计算密集型算子性能。
7 总结与展望
7.1 性能测试最佳实践总结
基于多年的昇腾平台开发经验,我总结出以下性能测试最佳实践:
测试环境一致性:确保测试环境与生产环境一致,包括硬件型号、驱动版本、软件配置等。
多层次测试:从微观算子测试到宏观模型测试,建立完整的性能评估体系。
自动化流水线:将性能测试集成到CI/CD流水线,实现持续性能监控。
数据驱动优化:基于详实的性能数据做出优化决策,避免盲目优化。
7.2 未来展望
随着AI技术的不断发展,性能测试方法论也需要持续演进:
自动化性能优化:基于AI技术自动识别瓶颈并生成优化代码。
跨平台性能可移植性:实现不同硬件平台间性能特征的无缝迁移。
实时性能监控:在生产环境中实时监控和分析性能特征。
参考链接
-
DLCompiler开源项目GitHub- 跨芯片统一优化编译器
-
Ascend性能调试文档- 官方性能分析工具指南
-
昇腾CANN训练营资料- 最新技术分享和案例
-
Triton官方性能优化指南- Triton最佳实践
-
昇腾官方性能白皮书- 学术性能评测参考
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 34
34 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)