
潞晨昇腾技术联创:昇腾RL深度思考模型解决方案发布,Open-Sora 2.0模型上线魔乐社区
Open-Sora 2.0模型已经完成对昇腾硬件的全面适配,相关模型权重已开源并上传至魔乐社区,开发者可快速下载使用
在人工智能技术飞速发展的今天,大模型已从简单的数据匹配逐步演进到具备逻辑推理能力的深度思考阶段。这种能力使得AI能够真正理解复杂问题,进行多步推理,并在多领域展现出巨大潜力。
潞晨团队与昇腾团队密切合作,实现了强化微调技术的创新全栈优化方案,并在鲲鹏昇腾开发者大会2025上进行了开源与分享,推动深度思考模型的落地实践,助力各行业实现 AI 的国产化覆盖。
此外,潞晨团队的OpenSora 2.0模型也已经完成对昇腾硬件的全面适配,相关模型权重已开源并上传至魔乐社区,开发者可快速下载使用。为降低部署门槛,昇腾团队同步开源了完整的部署方案及适配代码,涵盖环境搭建、权重转换等关键步骤。团队后续还将通过魔乐社区逐步释放部分训练数据集,助力开发者开展研究
与创新。
🔗分布式强化学习框架链接:
https://modelers.cn/models/HPC_AI_TECH/Distributed_RL_Framework
🔗Open-Sora2.0模型链接:https://modelers.cn/models/HPC_AI_TECH/Open-Sora2.0 (点击文末阅读原文直达)
🔗Open-Sora2.0模型部署方案及适配代码:
https://gitee.com/ascend/MindSpeed-MM/tree/master/examples/opensora2.0
以下为潞晨团队在鲲鹏昇腾开发者大会2025上精彩分享的回顾。
1
强化微调:深度思考能力的突破性进展

传统微调方法在面对复杂思维链任务时,往往存在收敛慢、效果差的问题。我们的强化微调技术通过创新的解耦架构和Producer-Consumer模式,实现了三大突破性进展:
• 训练效率提升:流水线式强化学习和异步式强化学习有效实现并发执行,极大提升训练吞吐效率;
• 系统灵活性:有效解决资源耦合问题,打破工作负载瓶颈,并实现更轻松的主流推理框架对接;
• 高可扩展性:支持灵活扩展训练资源,独立调整不同类型任务的训练资源,并支持异构硬件训练,提升整体资源利用率。
强化微调解耦架构
对于强化学习架构,我们摒弃了传统架构(Colocated Architecture),使用解耦架构(Disaggregated Architecture),使得生成(Generation)和训练(Train)分布在不同的资源集群上,支持灵活的资源调度与弹性扩容,显著提升了多阶段任务的效率与独立性。
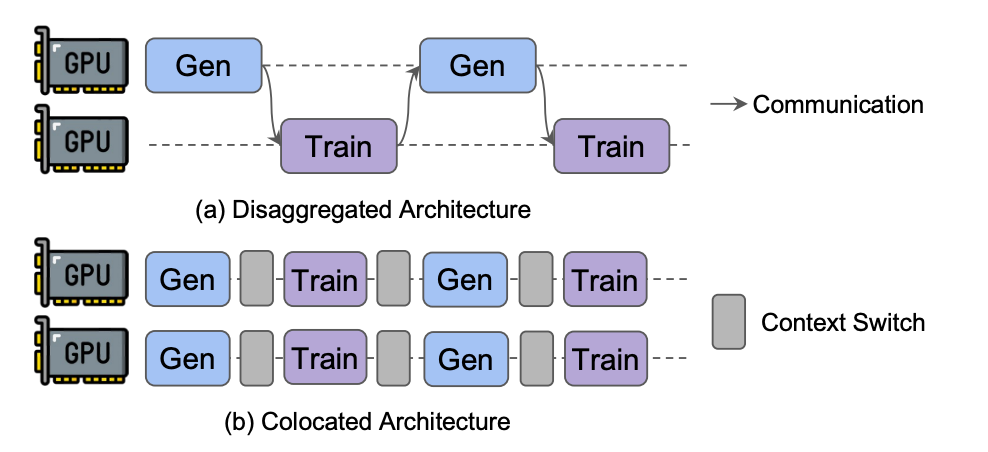
图源StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Producer-Consumer Pattern
Producer-Consumer Pattern是一种经典的软件设计模式,用于在两个进程或线程之间管理资源、数据或任务的传递。我们将这种设计模式扩展到强化学习训练上,通过生产者与消费者模式,实现高效的数据采样与训练解耦,支撑 GRPO 等大规模、分组、自适应的训练策略。用户可根据资源情况,灵活地配置推理组(生产者)与训练组(消费者)的数量,从而达到高效利用资源的目的。
在强化学习如GRPO算法中,训练的核心流程可以分为推理/采样(Rollout)和训练(Training)两部分。前者使用当前策略模型与环境交互(Reward),收集数据;后者使用收集的数据来更新策略模型。因此,在这个模式中,推理引擎(如vLLM)作为生产者(Producer),将数据存入共享缓冲区(Shared Buffer);而训练框架(如Colossal-AI)则持续读取缓冲区数据,高效地进行策略更新;更新后的模型可以再被推理引擎加载从而进入下一个rollout循环。
使用共享缓冲区作为桥梁,生产者与消费者两个步骤可以独立运行。同时,异步 RL 可以使得生产者与消费者尽量重叠,从而避免了资源的浪费。
2
全栈优化:三大技术支柱构建核心竞争力

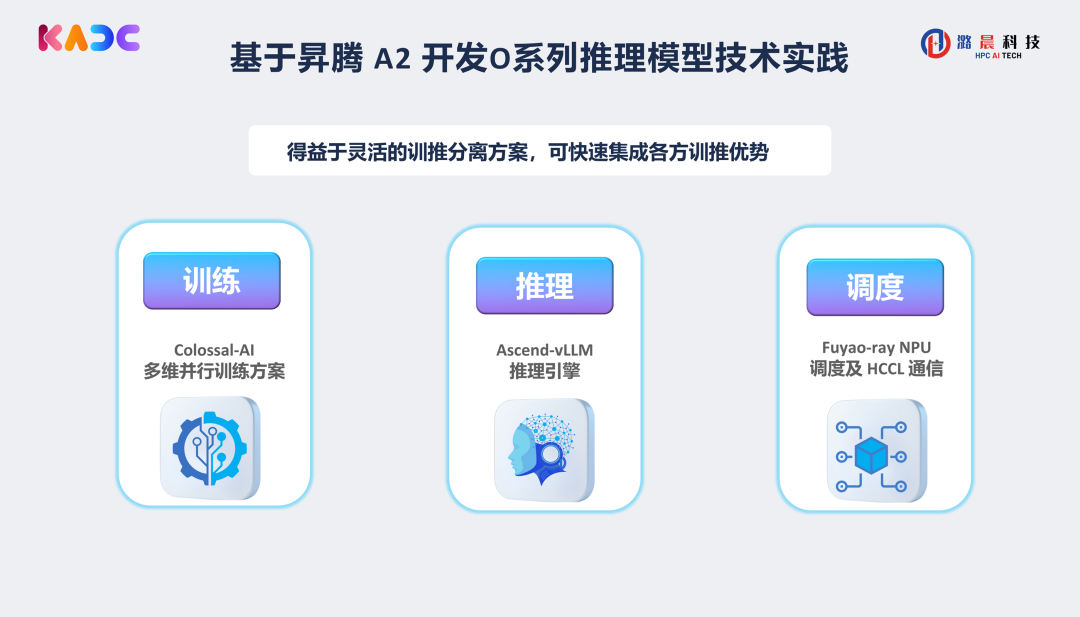
本次潞晨联合昇腾,从训练、推理、调度三方面打通了基于昇腾硬件原生开发深度思考模型的链路。通过结合Colossal-AI多维并行训练方案的训练加速、Ascend-vLLM引擎的推理加速和Fuyao-ray的NPU调度机HCCL通信管理,我们成功实现了在昇腾硬件上开箱即用地开发基于Qwen系列模型的深度思考模型,并实现训推50%以上的提速。同时,我们支持 GRPO,DAPO 等强化学习算法,并支持长序列训练。
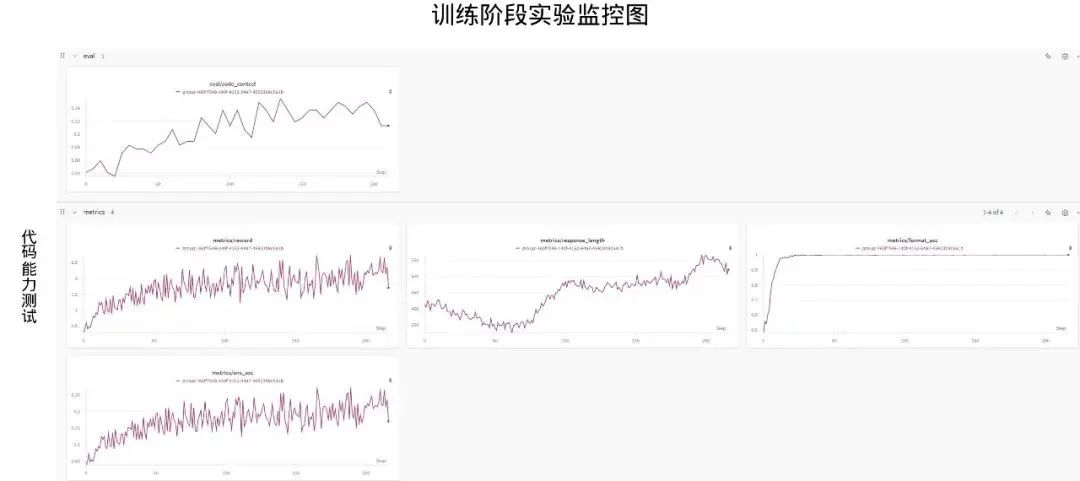
我们在 Qwen2.5-7B 模型上的训练验证实验中,分别验证了数学与代码的训练的可靠性。其中,在数学的训练过程中,模型的 reward 持续上升,同时伴随着在Math500 evaluation 过程中的上升。在代码的训练中,模型 reward 持续上升,同时伴随着 code contest 的分数持续上升。
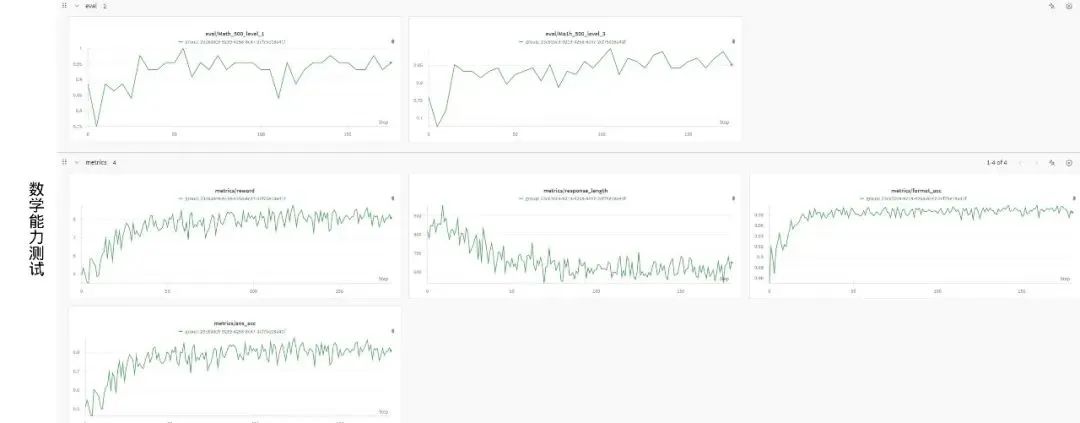
同时,我们基于昇腾训练的 Qwen2.5-7B preview 版本在经过一系列优化后,在 AIME24,25 等 benchmark 中已体现出明显的进步。
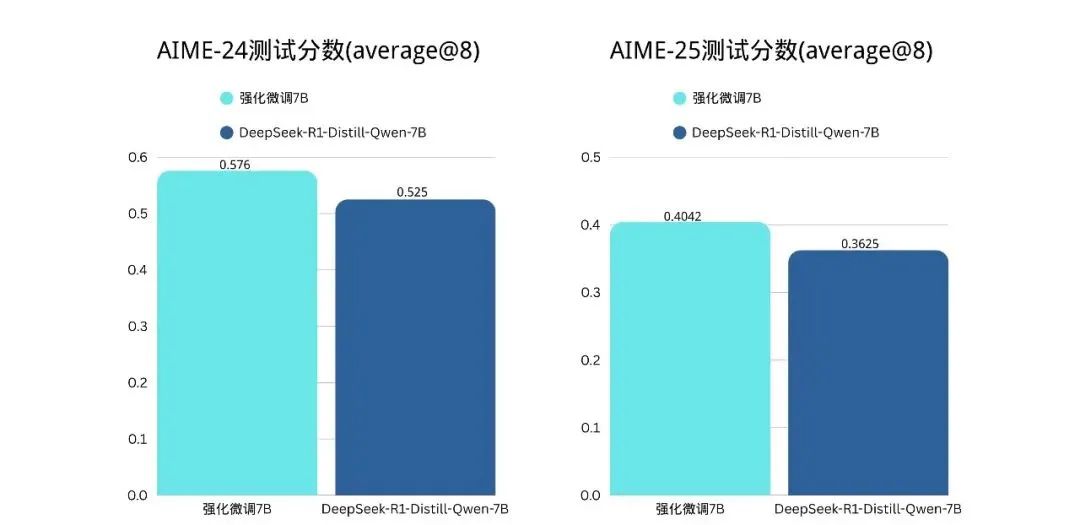
随着强化微调技术的持续演进,深度思考类O模型将在更多领域展现其变革性价值。我们正与昇腾等合作伙伴共同推进更深入的研发,包括潞晨一体机、AI Agent设计与开发等多种产品与方案,助力更多行业实现AI的国产化覆盖。


鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)