
昇思25天学习打卡营第15天|SSD目标检测
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster R
模型简介
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster RCNN(73.2%mAP)。具体可参考论文[1]。
SSD目标检测主流算法分成可以两个类型:
-
two-stage方法:RCNN系列
通过算法产生候选框,然后再对这些候选框进行分类和回归。
-
one-stage方法:YOLO和SSD
直接通过主干网络给出类别位置信息,不需要区域生成。
SSD是单阶段的目标检测算法,通过卷积神经网络进行特征提取,取不同的特征层进行检测输出,所以SSD是一种多尺度的检测方法。在需要检测的特征层,直接使用一个3 ×\times× 3卷积,进行通道的变换。SSD采用了anchor的策略,预设不同长宽比例的anchor,每一个输出特征层基于anchor预测多个检测框(4或者6)。采用了多尺度检测方法,浅层用于检测小目标,深层用于检测大目标。SSD的框架如下图:
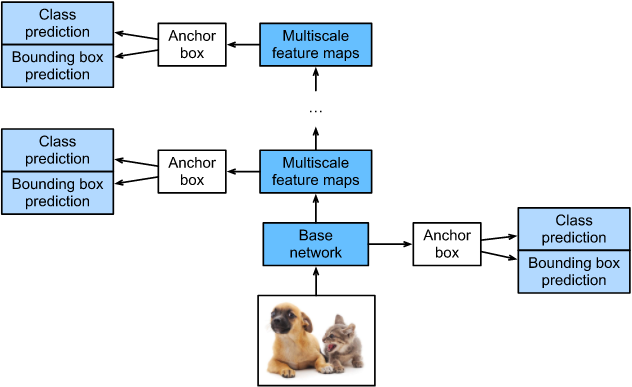
模型结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如图所示。上面是SSD模型,下面是YOLO模型,可以明显看到SSD利用了多尺度的特征图做检测。
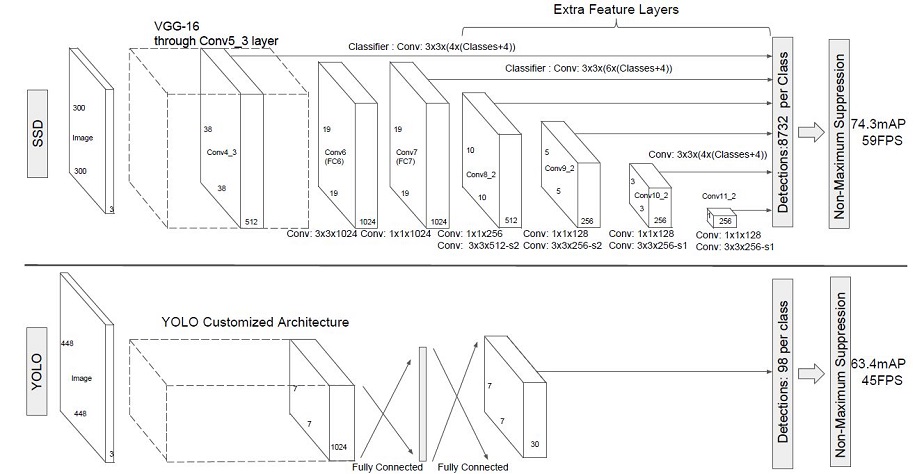
两种单阶段目标检测算法的比较:
SSD先通过卷积不断进行特征提取,在需要检测物体的网络,直接通过一个3 ×\times× 3卷积得到输出,卷积的通道数由anchor数量和类别数量决定,具体为(anchor数量*(类别数量+4))。
SSD对比了YOLO系列目标检测方法,不同的是SSD通过卷积得到最后的边界框,而YOLO对最后的输出采用全连接的形式得到一维向量,对向量进行拆解得到最终的检测框。
模型特点
-
多尺度检测
在SSD的网络结构图中我们可以看到,SSD使用了多个特征层,特征层的尺寸分别是38 ×\times× 38,19 ×\times× 19,10 ×\times× 10,5 ×\times× 5,3 ×\times× 3,1 ×\times× 1,一共6种不同的特征图尺寸。大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。多尺度检测的方式,可以使得检测更加充分(SSD属于密集检测),更能检测出小目标。
-
采用卷积进行检测
与YOLO最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m ×\times× n ×\times× p的特征图,只需要采用3 ×\times× 3 ×\times× p这样比较小的卷积核得到检测值。
-
预设anchor
在YOLOv1中,直接由网络预测目标的尺寸,这种方式使得预测框的长宽比和尺寸没有限制,难以训练。在SSD中,采用预设边界框,我们习惯称它为anchor(在SSD论文中叫default bounding boxes),预测框的尺寸在anchor的指导下进行微调。
模型构建
SSD的网络结构主要分为以下几个部分:
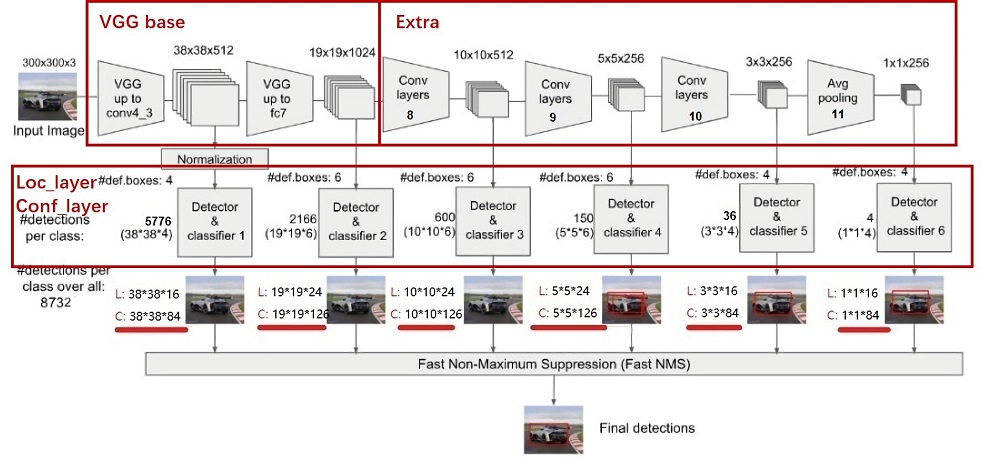
-
VGG16 Base Layer
-
Extra Feature Layer
-
Detection Layer
-
NMS
-
Anchor
Backbone Layer

输入图像经过预处理后大小固定为300×300,首先经过backbone,本案例中使用的是VGG16网络的前13个卷积层,然后分别将VGG16的全连接层fc6和fc7转换成3 ×\times× 3卷积层block6和1 ×\times× 1卷积层block7,进一步提取特征。 在block6中,使用了空洞数为6的空洞卷积,其padding也为6,这样做同样也是为了增加感受野的同时保持参数量与特征图尺寸的不变。
Extra Feature Layer
在VGG16的基础上,SSD进一步增加了4个深度卷积层,用于提取更高层的语义信息:

block8-11,用于更高语义信息的提取。block8的通道数为512,而block9、block10与block11的通道数都为256。从block7到block11,这5个卷积后输出特征图的尺寸依次为19×19、10×10、5×5、3×3和1×1。为了降低参数量,使用了1×1卷积先降低通道数为该层输出通道数的一半,再利用3×3卷积进行特征提取。
Anchor
SSD采用了PriorBox来进行区域生成。将固定大小宽高的PriorBox作为先验的感兴趣区域,利用一个阶段完成能够分类与回归。设计大量的密集的PriorBox保证了对整幅图像的每个地方都有检测。PriorBox位置的表示形式是以中心点坐标和框的宽、高(cx,cy,w,h)来表示的,同时都转换成百分比的形式。
PriorBox生成规则:
SSD由6个特征层来检测目标,在不同特征层上,PriorBox的尺寸scale大小是不一样的,最低层的scale=0.1,最高层的scale=0.95,其他层的计算公式如下:
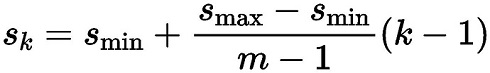
在某个特征层上其scale一定,那么会设置不同长宽比ratio的PriorBox,其长和宽的计算公式如下:
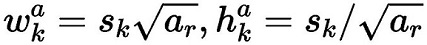
在ratio=1的时候,还会根据该特征层和下一个特征层计算一个特定scale的PriorBox(长宽比ratio=1),计算公式如下:
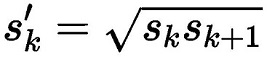
每个特征层的每个点都会以上述规则生成PriorBox,(cx,cy)由当前点的中心点来确定,由此每个特征层都生成大量密集的PriorBox,如下图:

SSD使用了第4、7、8、9、10和11这6个卷积层得到的特征图,这6个特征图尺寸越来越小,而其对应的感受野越来越大。6个特征图上的每一个点分别对应4、6、6、6、4、4个PriorBox。某个特征图上的一个点根据下采样率可以得到在原图的坐标,以该坐标为中心生成4个或6个不同大小的PriorBox,然后利用特征图的特征去预测每一个PriorBox对应类别与位置的预测量。例如:第8个卷积层得到的特征图大小为10×10×512,每个点对应6个PriorBox,一共有600个PriorBox。定义MultiBox类,生成多个预测框。
Detection Layer
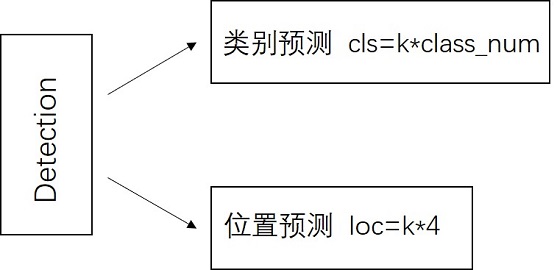
SSD模型一共有6个预测特征图,对于其中一个尺寸为m*n,通道为p的预测特征图,假设其每个像素点会产生k个anchor,每个anchor会对应c个类别和4个回归偏移量,使用(4+c)k个尺寸为3x3,通道为p的卷积核对该预测特征图进行卷积操作,得到尺寸为m*n,通道为(4+c)m*k的输出特征图,它包含了预测特征图上所产生的每个anchor的回归偏移量和各类别概率分数。所以对于尺寸为m*n的预测特征图,总共会产生(4+c)k*m*n个结果。cls分支的输出通道数为k*class_num,loc分支的输出通道数为k*4。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 24
24 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)