
基于MindSpore的RoBERTa-Large模型IA3微调并部署gradio
使用MindNLP组件加载Roberta-Large模型, 设置IA3算法配置并初始化微调模型,加载数据进行训练,最后通过部署gradio呈现。数据集:GLUE-MRPC
基于MindNLP的RoBERTa-Large大模型的IA3微调并部署gradio
——兰大昇思学习小组3组
任务描述
使用MindNLP组件对Roberta-Large模型进行IA3微调训练
使用MindNLP组件加载Roberta-Large模型, 设置IA3算法配置并初始化微调模型,加载数据进行训练,最后通过部署gradio呈现。
数据集:GLUE-MRPC
以下是本篇文章正文内容
一、微调任务的摸索
最开始参考了CSDN某帖——Roberta-Large的Prompt Turning微调方法:https://blog.csdn.net/LuoHangSF/article/details/143988389
在此基础上将prompt tuning配置改为IA3 tuning配置,完成了最初版:
https://github.com/Snape001/MindSpore-Learning-Records/blob/main/Roberta-Large%E6%A8%A1%E5%9E%8BIA3%E5%BE%AE%E8%B0%83/Previous_version_of_ia3.ipynb
但是定睛一看,所有训练轮次的accuracy都是0.68,像是根本没有训练,没有更新模型参数:

进一步推理发现不管输入哪两个sentence,输出的output都是1(等价)。
MRPC是一个经典的NLP数据集,广泛用于评估语言模型对句子语义相似性的识别能力,其包含大量经过人工标注的句子对,被分为“语义相同”和“语义不同”两个类别,而MRPC评估数据集的分布恰好68%的标签为“1”,其余为“0”,也就是说模型参数都是在初始化之后没有改变过。
后来尝试更新mindnlp0.4.1版本,模型参数更新正常,完成最终版:
https://github.com/Snape001/MindSpore-Learning-Records/blob/main/Roberta-Large%E6%A8%A1%E5%9E%8BIA3%E5%BE%AE%E8%B0%83/ia3.ipynb
二、微调代码演示
1.环境安装&&引入库
代码如下:
# 安装 mindnlp
!pip install git+https://github.com/mindspore-lab/mindnlp.git@master
!pip show mindnlp # 确保为0.4.1版本
from tqdm import tqdm
import mindspore
from mindnlp.core.optim import AdamW
from mindnlp.dataset import load_dataset
import mindnlp.peft as peft
import mindnlp.evaluate as evaluate
from mindnlp.dataset import load_dataset
from mindnlp.common.optimization import get_linear_schedule_with_warmup
from mindnlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
2.参数配置
代码如下:
# 启用Ascend
from mindspore import context
context.set_context(device_target="Ascend")
#配置训练微调参数
batch_size = 8
model_name_or_path = "AI-ModelScope/roberta-large"
task = "mrpc"
peft_type = peft.PeftType.IA3
num_epochs = 6
peft_config = peft.IA3Config(task_type="SEQ_CLS", inference_mode=False)
lr = 1e-3
昇思大模型平台提供算力支持,启用Ascend进行模型训练。
为了便于调试,训练轮数设为了6。
3.加载tokenizer
代码如下:
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side, mirror='modelscope')
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
如模型为GPT、OPT或BLOOM类模型,从序列左侧添加padding,其他情况下从序列右侧添加padding。
镜像选用modelscope,国外源经常连不上。
4.数据集预处理
代码如下:
# 加载数据集
datasets = load_dataset("glue", task)
print(next(datasets['train'].create_dict_iterator()))
# 数据预处理
from mindnlp.dataset import BaseMapFunction
class MapFunc(BaseMapFunction):
def __call__(self, sentence1, sentence2, label, idx):
outputs = tokenizer(sentence1, sentence2, truncation=True, max_length=None)
return outputs['input_ids'], outputs['attention_mask'], label
def get_dataset(dataset, tokenizer):
input_colums=['sentence1', 'sentence2', 'label', 'idx']
output_columns=['input_ids', 'attention_mask', 'labels']
dataset = dataset.map(MapFunc(input_colums, output_columns),
input_colums, output_columns)
dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),
'attention_mask': (None, 0)})
return dataset
train_dataset = get_dataset(datasets['train'], tokenizer)
eval_dataset = get_dataset(datasets['validation'], tokenizer)
test_dataset = get_dataset(datasets['test'], tokenizer)
print(next(train_dataset.create_dict_iterator()))
# 加载用于评估的指标
metric = evaluate.load("glue", task)
get_dataset 函数分别处理训练集、验证集和测试集,包含了已经经过处理和填充的 batch,最后输出数据集的一个样本。
5.加载预训练模型
代码如下:
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, mirror='modelscope')
model = peft.get_peft_model(model, peft_config)
model.print_trainable_parameters()
AutoModelForSequenceClassification专门用于序列分类任务。
IA3 (Integrated Attention Approximation Adjustment) 是一种参数高效微调方法,旨在通过调整特定注意力层的缩放参数来实现模型的微调。训练过程中冻结大模型参数,只缩放可学习的部分向量部分。
trainable params: 1,223,682 || all params: 356,585,476 || trainable%: 0.34316652874555104
可见只有0.34%的参数参与更新,很高效。
6.配置优化器
代码如下:
# 指定优化器和学习率调整策略
optimizer = AdamW(params=model.trainable_params(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0.06 * (len(train_dataset) * num_epochs),
num_training_steps=(len(train_dataset) * num_epochs),
)
7.模型微调训练
代码如下:
from mindnlp.core import value_and_grad
def forward_fn(**batch):
outputs = model(**batch)
loss = outputs.loss
return loss
grad_fn = value_and_grad(forward_fn, tuple(model.trainable_params()))
for epoch in range(num_epochs):
model.set_train()
train_total_size = train_dataset.get_dataset_size()
for step, batch in enumerate(tqdm(train_dataset.create_dict_iterator(), total=train_total_size)):
optimizer.zero_grad()
loss = grad_fn(**batch)
optimizer.step()
lr_scheduler.step()
model.set_train(False)
eval_total_size = eval_dataset.get_dataset_size()
for step, batch in enumerate(tqdm(eval_dataset.create_dict_iterator(), total=eval_total_size)):
outputs = model(**batch)
predictions = outputs.logits.argmax(axis=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(f"epoch {epoch}:", eval_metric)
模型参数实现了正常更新: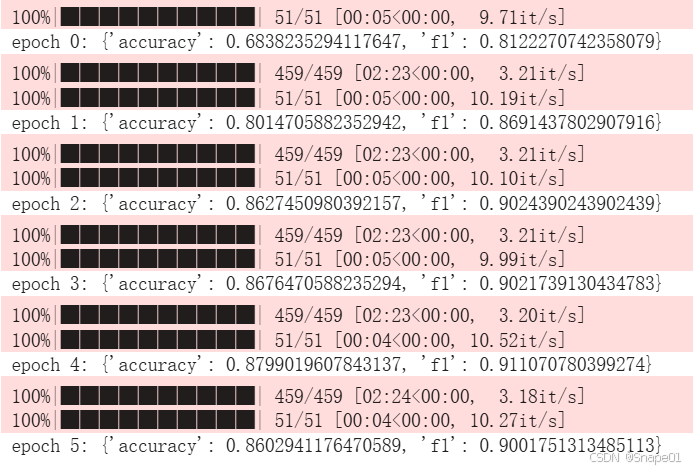
8.保存模型参数
代码如下:
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
#查看保存位置
ckpt = f"{peft_model_id}/adapter_model.ckpt"
!du -h $ckpt
保存模型参数,便于后续的本地gradio的部署。
会发现保存下来的模型参数只有3.4M,为什么刚开始下载的大模型有1.32G?
答:模型文件大小差异是因为预训练模型和适配器模型的不同。
①适配器模型(adapter_model.ckpt)通常是针对特定任务或数据集微调后的模型,只包含了任务特定的调整部分,而不包括整个大模型的所有权重,所以文件较小(4.7MB)。
②预训练大模型(如 roberta-large)通常包含了一个庞大的神经网络,包含了大量的参数和权重,因此更大一些(1.32GB)。
这种做法的好处是:
适配器模型可以在多个任务上复用相同的预训练模型,只需加载任务特定的适配器,节省存储空间。我们可以在不改变大模型的情况下,针对不同任务应用不同的适配器。
三、本地部署gradio
起初在昇思大模型平台的在线Jupyter无法部署,显示拒绝连接。因为其为远程资源,而127.0.0.1只能打开本地,除非内网穿透把本地服务器的gradio转到公网。
目前有两种解决方案:
①翻找昇思大模型平台文档,发现平台支持自动搭建在线推理:
https://xihe-docs-mindspore.osinfra.cn/zh/tutorial/inference/
②最终采用了“平台NPU训练,本地GPU推理”的方法,将训练好的模型下载到本地,在本地部署gradio。
Software Environment / 软件环境 (Mandatory):
-mindspore_2.3.0
-py_3.9
-MindNLP_0.4.1
1.环境安装&&引入库
代码如下:
# 安装MindSpore
……
# 安装 mindnlp
!pip install git+https://github.com/mindspore-lab/mindnlp.git@master
!pip show mindnlp # 确保为0.4.1版本
# 安装 gradio
!pip install gradio
import gradio as gr
import mindspore
from mindnlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from mindnlp.peft import PeftModel, IA3Config
2.加载预训练模型
代码如下:
import os
# 加载IA3配置文件
config = IA3Config.from_pretrained("/home/snape/roberta-large_IA3_SEQ_CLS")
# 加载预训练模型权重
model = AutoModelForSequenceClassification.from_pretrained("/home/snape/", local_files_only=True)
#加载针对特定任务进行微调的模型
model = PeftModel.from_pretrained(model, "/home/snape/roberta-large_IA3_SEQ_CLS")
# 加载分词器(tokenizer)
tokenizer = AutoTokenizer.from_pretrained("AI-ModelScope/roberta-large", padding_side="right", mirror='modelscope')
预训练大模型也可通过modelscope自动下载,但我本地多次自动下载模型失败,所以手动下载模型,手动加载。
加载过程中,这两部分代码作用不同:
# 加载IA3配置文件
config = IA3Config.from_pretrained("/home/snape/roberta-large_IA3_SEQ_CLS")
上面这个步骤是加载模型的配置文件(如 config.json),它包含了模型架构的设置和超参数。
#加载针对特定任务进行微调的模型
model = PeftModel.from_pretrained(model, "/home/snape/roberta-large_IA3_SEQ_CLS")
上面这个步骤是加载针对特定任务进行微调的模型权重,即我们先前保存的训练好的模型参数。
3.定义推理函数
代码如下:
from mindspore import Tensor
def predict(sentence1, sentence2):
inputs = tokenizer(sentence1, sentence2, truncation=True, padding=True, max_length=128, return_tensors="ms")
outputs = model(Tensor(inputs['input_ids']), Tensor(inputs['attention_mask']))
logits = outputs.logits
prediction = logits.argmax(axis=-1).asnumpy()[0]
if prediction == 1:
return "同义"
else:
return "不同义"
4.部署gradio
代码如下:
app = gr.Interface(fn=predict,
inputs=["text", "text"],
outputs="text",
title="文本分类模型",
description="请输入两个句子进行分类,判断它们是否同义")
app.launch(share=True)
本地创建连接显示拒绝访问,采用公共链接可正常访问了。
效果展示: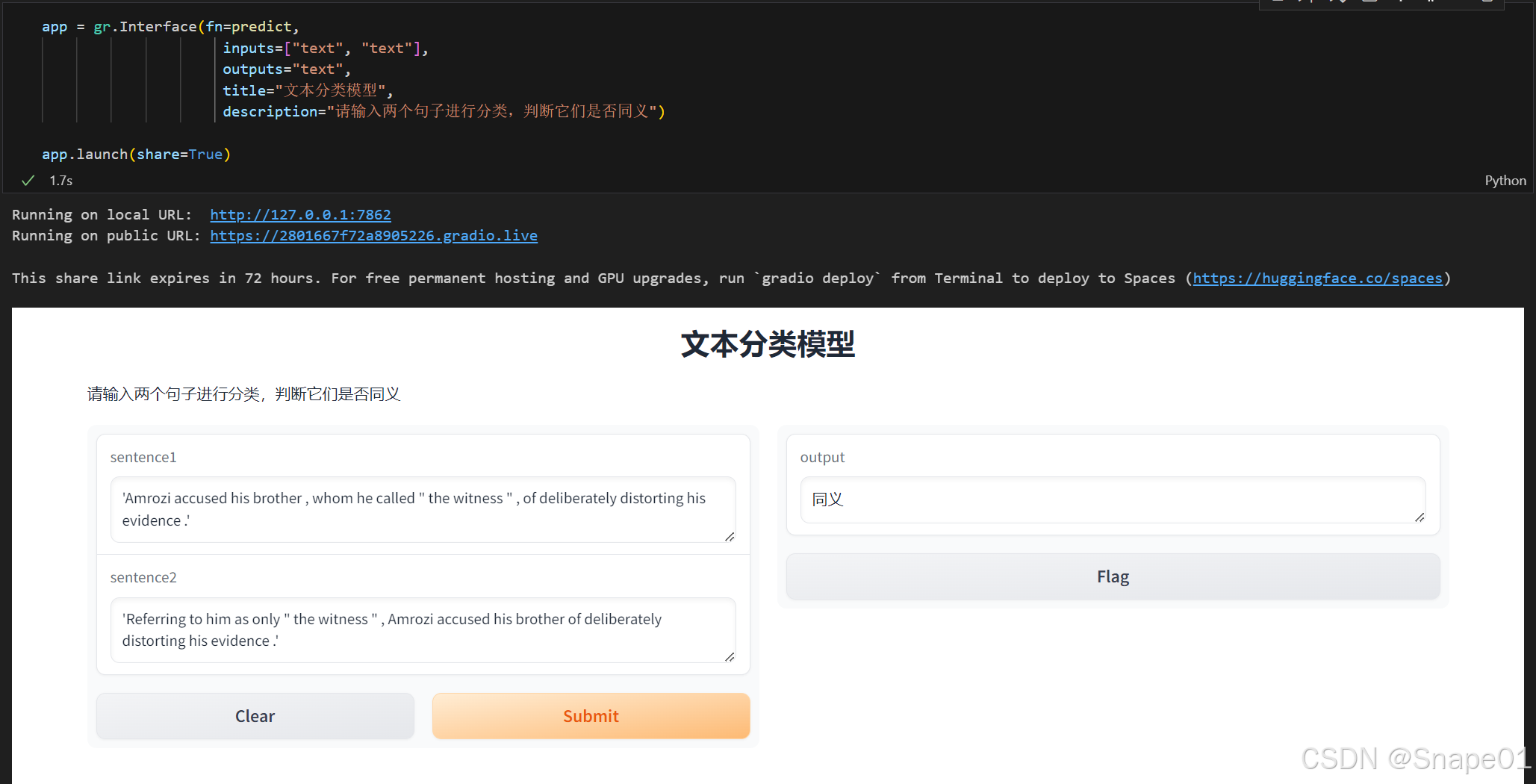

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)