
AI基础概念三:AI芯片技术架构学习
昇腾(Ascend)芯片是华为(海思)自主研发、专为高性能 AI 计算设计的 NPU(神经网络处理器)芯片。昇腾芯片是一个大系列,主要包含昇腾 310 和昇腾 910 两个子系列。昇腾 310主要面向边缘计算与低功耗终端,专注于完成 AI 推理任务。昇腾 910主要面向高性能计算,既能用于 AI 推理任务,也能用于 AI 训练任务。此外还有昇腾 610 也称为 MDC610,是智能驾驶芯片,用于华
一、昇腾芯片简介
昇腾芯片是海思自主研发、专为高性能 AI 计算设计的 NPU(神经网络处理器)芯片。昇腾芯片是一个大系列,主要包含昇腾 310 和昇腾 910 两个子系列。昇腾 310主要面向边缘计算与低功耗终端,专注于完成 AI 推理任务。昇腾 910主要面向高性能计算,既能用于 AI 推理任务,也能用于 AI 训练任务。此外还有昇腾 610 也称为 MDC610,是智能驾驶芯片,用于华为自己的智能驾驶平台(MDC)。
基于昇腾芯片,华为开发了 AI 算力板卡、服务器、集群等一系列硬件产品,覆盖边缘推理、云端推理、云端训练三大场景,满足不同行业用户的 AI 计算需求。基于昇腾系列硬件,华为推出了CANN异构计算架构,支持不同的AI框架,包括华为自研的MindSpore,也兼容业界的其他AI框架。并在此基础上对各种应用进行灵活使能。
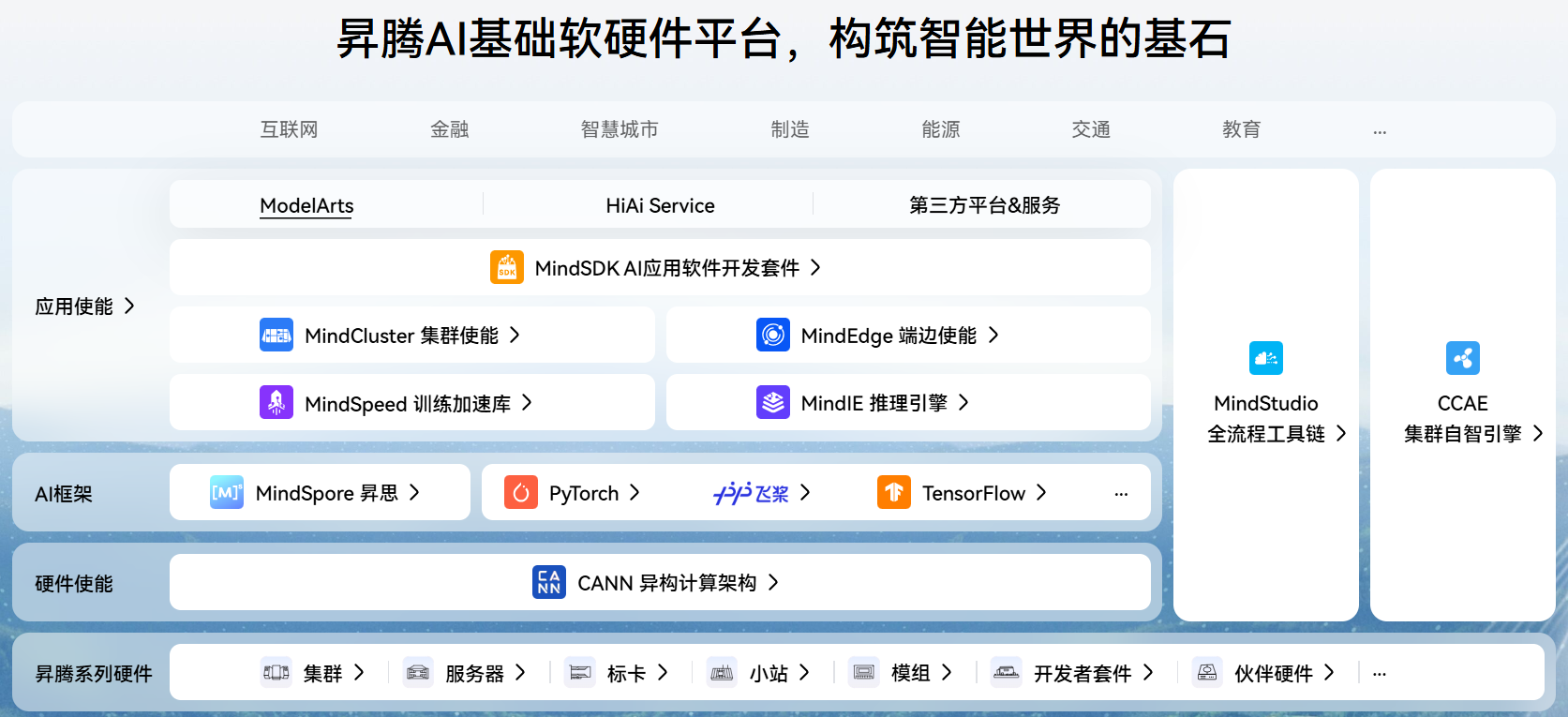
二、昇腾NPU芯片中的典型概念
昇腾 NPU 芯片以 Ascend 910B 为例,采用达芬奇架构,集成多个 AI Core。每个 AI Core 包括向量计算单元和矩阵计算单元等,通常设计有更大的矩阵计算单元,注重提升每个计算单元的计算能力和效率,通过加大片内缓存减少数据 IO 瓶颈。英伟达的Ampere 架构,包含多个图形处理集群(GPC),每个 GPC 由多个纹理处理器集群(TPC)组成,每个 TPC 又包含多个流多处理器(SM)。每个 SM 配备大量的 CUDA 核心和 Tensor 核心,计算单元更加均衡,除了向量或张量计算单元,还包含大量标量计算单元。
纹理处理器集群(Texture Processor Cluster,TPC)是 GPU(图形处理单元)中的重要组成部分。它负责执行与核心绘图功能相关的工作负载,对构建屏幕上的视觉体验起着关键作用。相关介绍如下。坐标转换:将坐标转换为 2D 屏幕坐标,为后续的图形渲染做准备。纹理映射:把纹理(图像)应用于 3D 模型,使模型表面呈现出丰富的细节和材质效果,如让墙壁看起来有砖块纹理,金属表面有光泽等。光栅化:将多边形转换为像素,以便在屏幕上显示出图形。
CUDA 核心:是 GPU 中的通用计算单元,负责执行各种类型的并行计算任务。适用于游戏图形渲染、科学模拟、数值分析、视频转码等多种场景,在传统图形渲染中的像素着色、几何计算和纹理映射等任务中发挥着重要作用。主要支持 FP32(单精度浮点)和 FP64(双精度浮点)计算。基于单指令多线程(SIMT)模型,通过大量 CUDA 核心并行执行多个线程来实现高性能计算,每个核心可以执行单个线程的指令,包括算术运算、逻辑操作和内存访问等。在处理通用并行计算任务时具有良好的性能,但在处理深度学习中的大规模矩阵运算时,效率相对较低。
SIMT(Single Instruction, Multiple Threads,单指令多线程)编程模型是 GPU(图形处理器)特有的并行计算架构,由 NVIDIA 在其 CUDA(Compute Unified Device Architecture)平台中提出并广泛应用,旨在高效利用 GPU 的大规模并行计算能力。
Tensor 核心:是专门针对深度学习需求设计的计算单元,主要功能是加速涉及张量运算的处理任务,尤其是神经网络计算中常见的矩阵乘法和卷积操作,在深度学习模型的训练和推理过程中能发挥出高效的计算能力。支持混合精度计算,包括 FP16、FP32、INT8、INT4 等,能在不显著降低计算精度的情况下,减少计算所需的内存和带宽,提高计算效率。在处理特定类型的深度学习任务时,能比 CUDA 核心提供更高的计算能力和吞吐量,尤其是在处理大规模、重复性强的矩阵运算时,性能优势明显。
可以看出NV的GPU中的Tensor核心的用途与昇腾NPU非常类似。而NV的GPU多了具备通用计算能力的CUDA核心,也是传统显卡所拥有的能力。面对复杂多变的需求,CUDA的通用计算能力被认为是NV芯片具备高易用性的一大关键,硬件上实现了SIMT编程能力(当前昇腾芯片不具备),与CUDA完善生态相辅相成。
三、CANN异构计算架构
CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构,对上支持多种AI框架,对下服务AI处理器与各种硬件,发挥承上启下的关键作用,是提升昇腾AI处理器计算效率的关键平台。
下图所示为CANN计算架构的核心内容。通过工具MindStudio+Ascend C语言+毕昇编译器配合进行开发。往下通过运行时和驱动与硬件进行交互,对上提升算子加速库,集合通信库,图引擎等能力助力AI编程框架高效利用昇腾硬件资源。

与NVIDIA的CUDA架构相比,CANN有一些比较明显的区别:
基于CUDA的开发者,可以使用C/C++编写函数,而CANN提供了Ascend C算子编程语言。Ascend C是CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。尽管如此,新的编程语言和工具环境对于开发者肯定不如C/C++适应,有学习成本。
四、AI框架和应用使能
昇腾软硬件架构中的AI框架和应用使能更多的与AI应用相关,其不与芯片硬件强绑定,而是通过硬件使能架构如CANN/CUDA来屏蔽底层芯片的差异。
事实上一个优秀的硬件使能框架是可以做到兼容不同硬件的,虽然目前CUDA和CANN都未完全开源和兼容其他的厂家AI芯片(CUDA未开源,CANN部分开源),部分厂商通过开发兼容层实现了对CUDA生态的部分兼容。基于商业考虑,厂商为了保证自身芯片的独特价值和生态为我所有,短期内看做完全开源的可能性不大。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)