
昇腾AI处理器AI Core硬件架构学习
其实所有非端到端的加速器都需要配合软件去做co-design,设计指令集和控制器,最后通过编译器用软件的方式去调度来加速一个网络项目。具体的设计很推荐看看这本书。
昇腾AI处理器AI Core硬件架构学习
本文是本人在阅读《昇腾AI处理器架构与编程——深入理解CANN技术原理及应用》来对AI处理器设计入门学习时的记录和个人理解
其实所有非端到端的加速器都需要配合软件去做co-design,设计指令集和控制器,最后通过编译器用软件的方式去调度来加速一个网络项目。具体的设计很推荐看看这本书。
当然,这本书相对比较上层了,其实可以先去补一点算法的知识,除了矩阵乘法以外网络中还存在很多计算模块,先看看论文和github上的开源项目,理清楚这些比较好
昇腾AI处理器逻辑图:
所有加速器都是通过控制器来调度一堆算子的各种排列,昇腾处理器的核心就是AI CPU控制AI Core进行各种针对神经网络优化过的计算子模块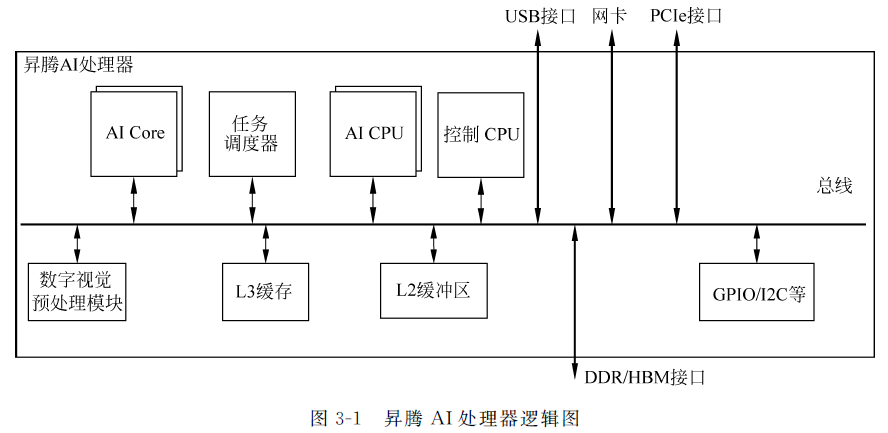
AI Core硬件架构:
1.计算单元

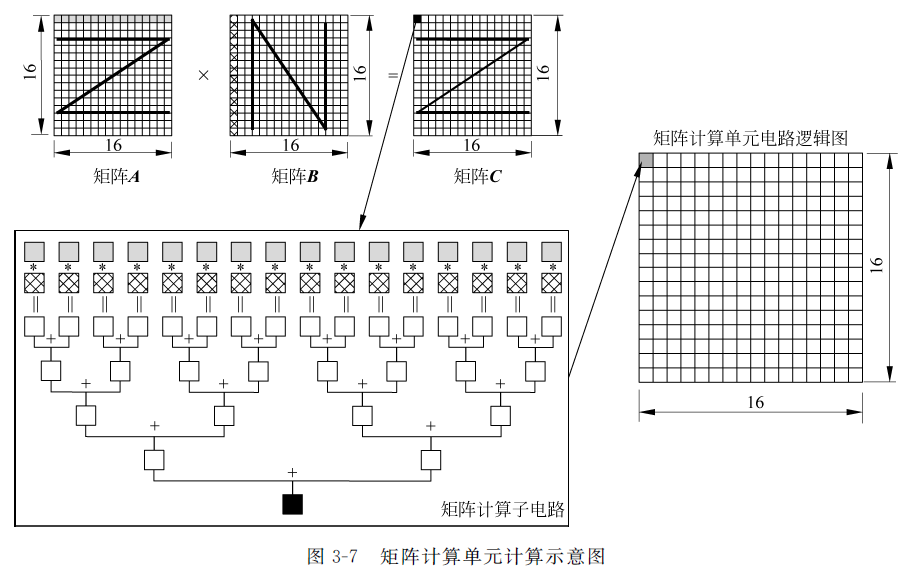
支持16x16 fp16或32x16 int8计算,后面通过累加器连接输出缓冲区
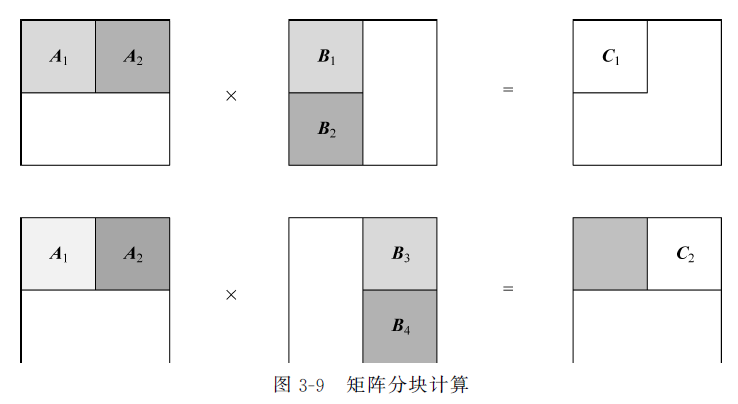
- 矩阵平铺(Tiling)处理(书中p76-80):
- 将矩阵分块多次运算得到子结果矩阵然后组合,充分利用了缓存的容量,最大程度利用数据计算局部性特征实现大规模矩阵计算,是一种常见的优化手段,排不满的地方通常用补0实现
- 向量计算单元:
- 支持多种计算格式FP16 INT32 INT8等,同时连接在矩阵计算单元之后,可以顺便完成ReLU激活函数、池化等功能。计算完成后也可以写回到矩阵计算单元或输出缓冲区

- 标量计算单元:
- 相当于一个微型CPU,控制AI core运行,并且配备GPR SPR,分别存储变量、地址和实现一些特殊功能
2.存储单元
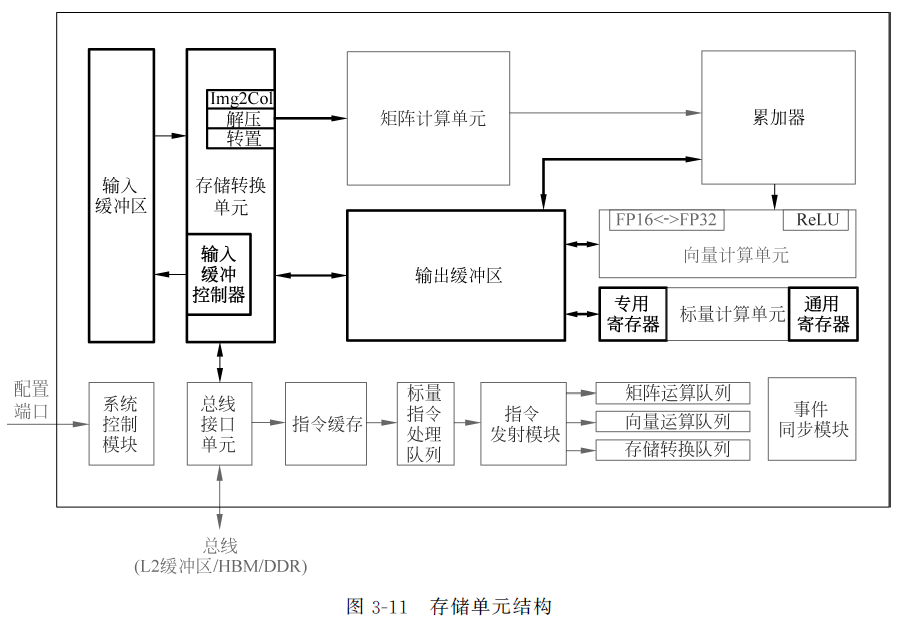
通过总线访问底层次缓存(L2、DDR/HBM),主要由输入缓冲区(原始特征数据)和输出缓冲区(中间数据和结果)以及一些寄存器(主要由标量计算单元使用)组成
-
存储转换单元(实现数据传输同时转换格式:随路指令):
通过和总线接口、输入输出缓冲区和矩阵计算单元连接,完成数据交换的读写管理和一系列格式转换(转置、补0、Img2Col、解压缩等),也可控制输入缓冲区做局部缓存
-
输入缓冲区:
暂存需要频繁使用的数据,降低频繁读取以优化性能功耗,同时通过硬化的转换电路,避免矩阵计算单元阻塞
-
输出缓冲区:
将每层中间结果直接暂存,避免频繁使用总线从而优化计算效率
-
数据通路:
- 通路图

- 达芬奇架构多进单出核外数据可以直接流入矩阵计算单元、输入缓冲区和输出缓冲区,但所有向核外传输数据都要经过输出缓冲区,比如输入缓冲区数据就必须经过矩阵计算单元再到输出缓冲区再向外输出,这种设计主要考虑了神经网络计算的特征,节约硬件和控制资源
3.控制单元
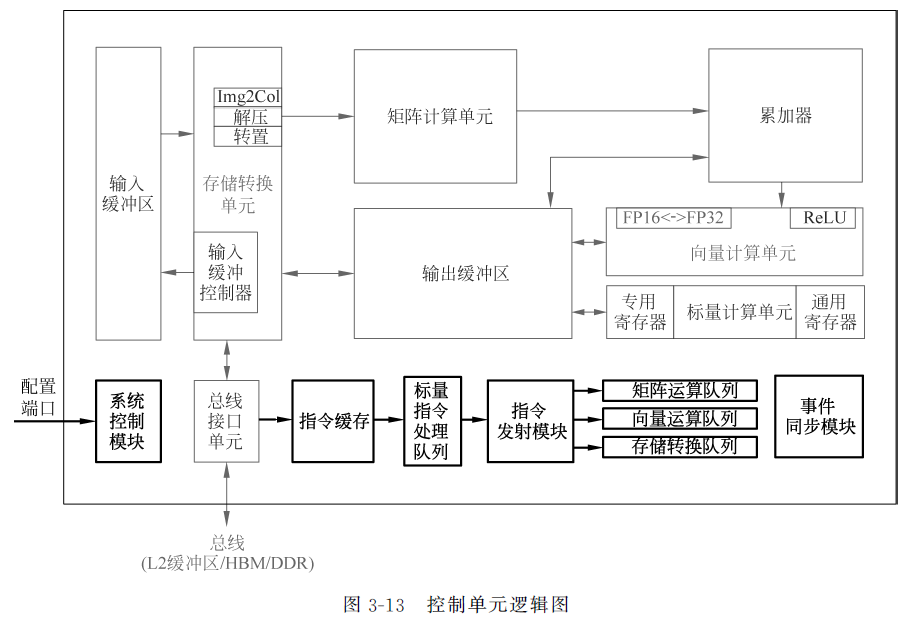
-
指令缓存:
- 提前预取后续指令, 并一次读入多条指令进入缓存, 提升指令执行效率
-
标量指令处理队列、指令发射模块:
- 在进入指令发射模块之前, 所有指令都作为普通标量指令被逐条顺次处理。标量队列将这些指令的地址和参数解码配置好后, 由指令发射模块根据指令的类型分别发送到对应的指令执行队列中, 而标量指令会驻留在标量指令处理队列中进行后续执行
-
指令执行队列:
- 由矩阵运算队列、向量运算队列和存储转换队列组成,不同指令执行队列之间可以并行执行
-
事件同步模块:
- 对于指令流水线之间可能出现的数据依赖, 达芬奇架构的解决方案是通过设置事件同步模块来统一协调各个流水线的进程。事件同步模块时刻控制每条流水线的执行状态, 并分析不同流水线的依赖关系,从而解决数据依赖和同步的问题。在达芬奇架构中, 无论是流水线内部的同步还是流水线之间的同步, 都是通过事件同步模块利用软件控制来实现的
- 一个运行例子:
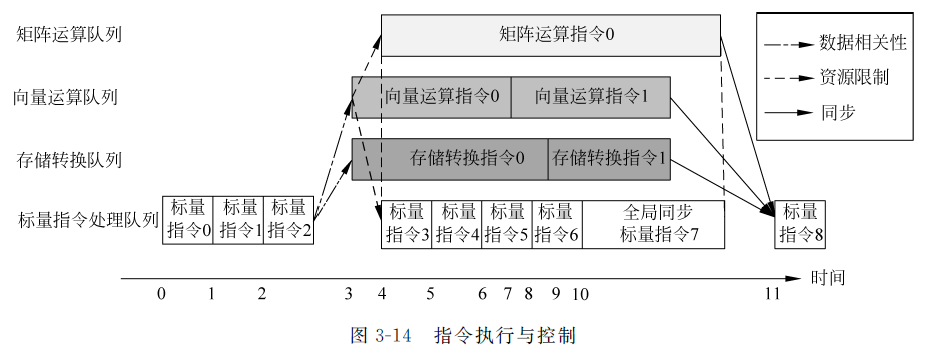
-
系统控制模块
- 在 AI Core 运行之前,需要外部的任务调度器来控制和初始化 AI Core 的各种配置接口, 如指令信息、参数信息以及任务块信息等。这里的任务块是指 AI Core 中的最小的计算任务粒度
- 在配置完成后, 系统控制模块会控制任务块的执行进程, 同时在任务块执行完成后, 系统控制模块会进行中断处理和状态申报。如果在执行过程中出现了错误, 系统控制模块将会把执行的错误状态报告给任务调度器,进而反馈当前 AI Core 的状态信息给整个昇腾 AI 处理器系统
4.指令集设计
未学完待续、、、

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)