
MindSpore社区活动:使用MindSpore实现ICT,玩转图像修复——体验贴
图像修复技术(ICT)的核心目标是通过算法重建图像中缺失或损坏的部分,使其在视觉上与原始图像保持自然和谐。这一过程结合了传统图像处理与深度学习技术,形成了多层次的实现框架。传统方法如基于扩散的修复,通过分析缺失区域边缘的像素梯度与颜色信息,逐步向内部填充内容。这种方法类似于在画布上从已知区域向未知区域延伸纹理,适用于小面积划痕或斑点修复。而纹理合成技术则通过采样图像其他区域的纹理特征,将相似结构拼
欢迎大家加入MindSpore社区一起玩!
1.ICT概念与基本原理简介
图像修复技术(ICT)的核心目标是通过算法重建图像中缺失或损坏的部分,使其在视觉上与原始图像保持自然和谐。这一过程结合了传统图像处理与深度学习技术,形成了多层次的实现框架。传统方法如基于扩散的修复,通过分析缺失区域边缘的像素梯度与颜色信息,逐步向内部填充内容。这种方法类似于在画布上从已知区域向未知区域延伸纹理,适用于小面积划痕或斑点修复。而纹理合成技术则通过采样图像其他区域的纹理特征,将相似结构拼接到缺失位置,尤其擅长处理大面积纹理缺失,如修复老照片中的磨损区域。
深度学习的引入彻底改变了图像修复的范式。卷积神经网络(CNN)通过多层卷积核捕捉图像的局部特征,结合编码器-解码器结构,能够从完整图像中学习特征映射关系。例如,当修复一张被遮挡的人脸图像时,CNN会先提取面部轮廓、眼睛、鼻子等关键特征,再根据这些特征生成缺失部分的像素值。生成对抗网络(GAN)则通过生成器与判别器的博弈机制,使修复结果在细节真实性和纹理连续性上达到更高水平。生成器负责生成填补内容,判别器则判断其是否与周围像素融合自然,二者通过对抗训练不断优化,最终生成难以区分真伪的修复效果。
Transformer模型通过自注意力机制,突破了传统卷积网络的局部感知限制。它能够捕捉图像中长距离的依赖关系,例如在修复建筑图片时,模型会同时参考远处窗户的排列规律和近处砖墙的纹理方向,确保修复区域在几何结构和纹理风格上与整体保持一致。这种特性使得Transformer在处理复杂场景时更具优势,如修复包含周期性纹理的织物或具有透视关系的建筑立面。
图像修复技术的应用场景广泛且深入。在文物保护领域,技术能够还原古代壁画因岁月侵蚀产生的裂痕与褪色,通过分析残留颜料分布与笔触方向,重建缺失部分的原始风貌。医学影像处理中,修复算法可去除CT或MRI图像中的噪声与运动伪影,甚至填补因患者移动导致的缺失切片,辅助医生进行更精准的诊断。视频修复则需考虑时间维度的一致性,通过帧间插值与运动补偿技术,确保修复后的视频在播放时不会出现闪烁或跳跃现象。
尽管技术取得显著进展,仍面临多重挑战。高分辨率图像修复需要消耗大量计算资源,现有模型难以在移动端实现实时处理。复杂结构修复,如同时包含规则纹理与不规则形状的缺失区域,常因特征冲突导致模糊或断裂。视频修复还需解决帧间连贯性问题,避免生成内容在时间轴上产生割裂感。未来发展方向包括融合多模态信息(如结合文本描述引导修复方向)、利用神经渲染技术处理三维场景,以及通过模型压缩与量化技术推动轻量化部署,使图像修复技术能够更广泛地应用于消费级场景。
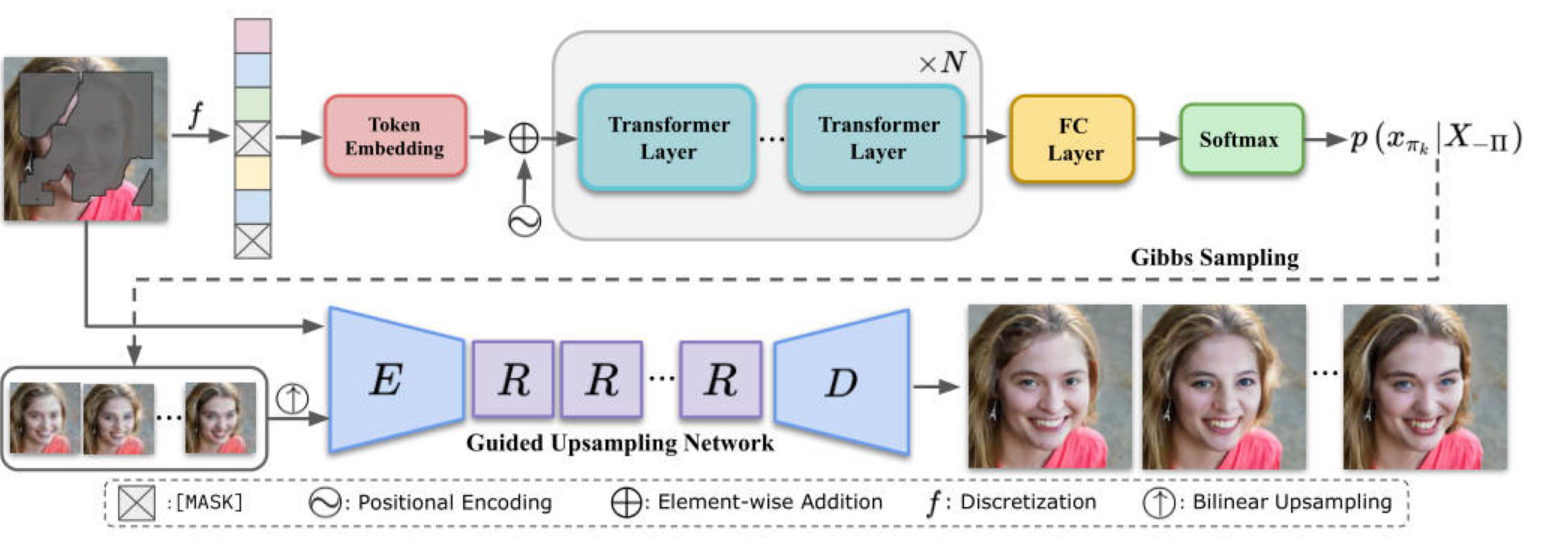
其中大致流程如图所示:
2.训练数据集准备与环境准备
2.1 数据集
本实验需要使用两个数据集,其一是ImageNet数据集,下载地址:ImageNet,其二是掩码修复数据集,下载地址:www.dropbox.com。
2.2 参数设置
其中训练使用的代码参数设置如下面代码所示
import os
import argparse
import mindspore
import numpy as np
from mindspore import context
def parse_args():
"""Parse args."""
parser = argparse.ArgumentParser()
# Parameter of train
parser.add_argument('--data_path', type=str, default='/data0/imagenet2012/train',
help='Indicate where is the training set')
parser.add_argument('--mask_path', type=str, default='/home/ict/ICT/mask/testing_mask_dataset',
help='Where is the mask')
parser.add_argument('--n_layer', type=int, default=35)
parser.add_argument('--n_head', type=int, default=8)
parser.add_argument('--n_embd', type=int, default=1024)
parser.add_argument('--GELU_2', action='store_true', help='use the new activation function')
parser.add_argument('--use_ImageFolder', action='store_true', help='Using the original folder for ImageNet dataset')
parser.add_argument('--random_stroke', action='store_true', help='Use the generated mask')
parser.add_argument('--train_epoch', type=int, default=5, help='How many epochs')
parser.add_argument('--learning_rate', type=float, default=3e-4, help='Value of learning rate.')
parser.add_argument('--input', type=str, default='/data0/imagenet2012/train',
help='path to the input images directory or an input image')
parser.add_argument('--mask', type=str, default='/home/ict/ICT/mask/testing_mask_dataset',
help='path to the masks directory or a mask file')
parser.add_argument('--prior', type=str, default='', help='path to the edges directory or an edge file')
parser.add_argument('--kmeans', type=str, default='../kmeans_centers.npy', help='path to the kmeans')
# 根据VGG19.ckpt的路径,要进行相应修改,VGG19权重文件可在推理部分给出的权重地址进行下载
parser.add_argument('--vgg_path', type=str, default='../ckpts_ICT/VGG19.ckpt', help='path to the VGG')
parser.add_argument('--image_size', type=int, default=256, help='the size of origin image')
parser.add_argument('--prior_random_degree', type=int, default=1, help='during training, how far deviate from')
parser.add_argument('--use_degradation_2', action='store_true', help='use the new degradation function')
parser.add_argument('--mode', type=int, default=1, help='1:train, 2:test')
parser.add_argument('--mask_type', type=int, default=2)
parser.add_argument('--max_iteration', type=int, default=25000, help='How many run iteration')
parser.add_argument('--lr', type=float, default=0.0001, help='Value of learning rate.')
parser.add_argument('--D2G_lr', type=float, default=0.1,
help='Value of discriminator/generator learning rate ratio')
parser.add_argument("--l1_loss_weight", type=float, default=1.0)
parser.add_argument("--style_loss_weight", type=float, default=250.0)
parser.add_argument("--content_loss_weight", type=float, default=0.1)
parser.add_argument("--inpaint_adv_loss_weight", type=float, default=0.1)
parser.add_argument('--ckpt_path', type=str, default='', help='model checkpoints path')
parser.add_argument('--save_path', type=str, default='./checkpoint', help='save checkpoints path')
parser.add_argument('--device_id', type=int, default='0')
parser.add_argument('--device_target', type=str, default='GPU', help='GPU or Ascend')
parser.add_argument('--prior_size', type=int, default=32, help='Input sequence length = prior_size*prior_size')
parser.add_argument('--batch_size', type=int, default=2, help='The number of train batch size')
parser.add_argument("--beta1", type=float, default=0.9, help="Value of beta1")
parser.add_argument("--beta2", type=float, default=0.95, help="Value of beta2")
# Parameter of infer
parser.add_argument('--image_url', type=str, default='/data0/imagenet2012/val', help='the folder of image')
parser.add_argument('--mask_url', type=str, default='/home/ict/ICT/mask/testing_mask_dataset',
help='the folder of mask')
parser.add_argument('--top_k', type=int, default=40)
parser.add_argument('--save_url', type=str, default='./sample', help='save the output results')
parser.add_argument('--condition_num', type=int, default=1, help='Use how many BERT output')
args = parser.parse_known_args()[0]
return args
# 选择执行模式为动态图模式,执行硬件平台为GPU
context.set_context(mode=context.PYNATIVE_MODE, device_target='GPU')
opts = parse_args()
3.训练评估
3.1 训练
由于Transformer计算量偏大,因此在图片输入网络前会先对其进行下采样,在ImageNet数据中,图片会被采样到32*32分辨率,以得到图像低分辨率的图像先验信息。Transformer模型代码构建代码:
import mindspore.nn as nn
import mindspore.ops as ops
import mindspore.ops.operations as P
from mindspore import Tensor
from mindspore.common.initializer import Normal
class CausalSelfAttention(nn.Cell):
"""
The CausalSelfAttention part of transformer.
Args:
n_embd (int): The size of the vector space in which words are embedded.
n_head (int): The number of multi-head.
block_size (int): The context size(Input sequence length).
resid_pdrop (float): The probability of resid_pdrop. Default: 0.1
attn_pdrop (float): The probability of attn_pdrop. Default: 0.1
Returns:
Tensor, output tensor.
"""
def __init__(self, n_embd: int, n_head: int, block_size: int, resid_pdrop: float = 0.1, attn_pdrop: float = 0.1):
super().__init__()
# key, query, value projections for all heads
self.key = nn.Dense(in_channels=n_embd, out_channels=n_embd,
weight_init=Normal(sigma=0.02, mean=0.0))
self.query = nn.Dense(in_channels=n_embd, out_channels=n_embd,
weight_init=Normal(sigma=0.02, mean=0.0))
self.value = nn.Dense(in_channels=n_embd, out_channels=n_embd,
weight_init=Normal(sigma=0.02, mean=0.0))
# regularization
self.attn_drop = nn.Dropout(keep_prob=1.0 - attn_pdrop)
self.resid_drop = nn.Dropout(keep_prob=1.0 - resid_pdrop)
# output projection
self.proj = nn.Dense(in_channels=n_embd, out_channels=n_embd,
weight_init=Normal(sigma=0.02, mean=0.0))
tril = nn.Tril()
self.mask = mindspore.Parameter(
tril(P.Ones()((block_size, block_size), mindspore.float32)).view(1, 1, block_size, block_size),
requires_grad=False)
self.n_head = n_head
def construct(self, x):
B, T, C = P.Shape()(x)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
k = self.key(x).view(B, T, self.n_head, C // self.n_head)
k = k.transpose(0, 2, 1, 3)
q = self.query(x).view(B, T, self.n_head, C // self.n_head)
q = q.transpose(0, 2, 1, 3)
v = self.value(x).view(B, T, self.n_head, C // self.n_head)
v = v.transpose(0, 2, 1, 3)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
k_shape = k.shape[-1]
sz = 1.0 / (Tensor(k_shape) ** Tensor(0.5))
q = mindspore.ops.Cast()(q, mindspore.float16)
k = mindspore.ops.Cast()(k, mindspore.float16)
sz = mindspore.ops.Cast()(sz, mindspore.float16)
att = (ops.matmul(q, k.transpose(0, 1, 3, 2)) * sz)
att = mindspore.ops.Cast()(att, mindspore.float32)
att = P.Softmax()(att)
att = self.attn_drop(att)
att = mindspore.ops.Cast()(att, mindspore.float16)
v = mindspore.ops.Cast()(v, mindspore.float16)
y = mindspore.ops.matmul(att, v)
y = mindspore.ops.Cast()(y, mindspore.float32)
y = y.transpose(0, 2, 1, 3).view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_drop(self.proj(y))
return y
class GELU2(nn.Cell):
"""
The new gelu2 activation function.
Returns:
Tensor, output tensor.
"""
def construct(self, x):
return x * P.Sigmoid()(1.702 * x)
class Block_2(nn.Cell):
"""
Transformer block with original GELU2.
Args:
n_embd (int): The size of the vector space in which words are embedded.
n_head (int): The number of multi-head.
block_size (int): The context size(Input sequence length).
resid_pdrop (float): The probability of resid_pdrop. Default: 0.1
attn_pdrop (float): The probability of attn_pdrop. Default: 0.1
Returns:
Tensor, output tensor.
"""
def __init__(self, n_embd: int, n_head: int, block_size: int, resid_pdrop: float = 0.1, attn_pdrop: float = 0.1):
super().__init__()
self.ln1 = nn.LayerNorm(normalized_shape=[n_embd], epsilon=1e-05)
self.ln2 = nn.LayerNorm(normalized_shape=[n_embd], epsilon=1e-05)
self.attn = CausalSelfAttention(n_embd, n_head, block_size, resid_pdrop, attn_pdrop)
self.mlp = nn.SequentialCell([
nn.Dense(in_channels=n_embd, out_channels=4 * n_embd,
weight_init=Normal(sigma=0.02, mean=0.0)),
GELU2(),
nn.Dense(in_channels=4 * n_embd, out_channels=n_embd,
weight_init=Normal(sigma=0.02, mean=0.0)),
nn.Dropout(keep_prob=1.0 - resid_pdrop),
])
def construct(self, x):
x = x + self.attn(self.ln1(x))
x = x + self.mlp(self.ln2(x))
return x
class Block(nn.Cell):
"""
Transformer block with original GELU.
Args:
n_embd (int): The size of the vector space in which words are embedded.
n_head (int): The number of multi-head.
block_size (int): The context size(Input sequence length).
resid_pdrop (float): The probability of resid_pdrop. Default: 0.1
attn_pdrop (float): The probability of attn_pdrop. Default: 0.1
Returns:
Tensor, output tensor.
"""
def __init__(self, n_embd: int, n_head: int, block_size: int, resid_pdrop: float = 0.1, attn_pdrop: float = 0.1):
super().__init__()
self.ln1 = nn.LayerNorm(normalized_shape=[n_embd], epsilon=1e-05)
self.ln2 = nn.LayerNorm(normalized_shape=[n_embd], epsilon=1e-05)
self.attn = CausalSelfAttention(n_embd, n_head, block_size, resid_pdrop, attn_pdrop)
self.mlp = nn.SequentialCell([
nn.Dense(in_channels=n_embd, out_channels=4 * n_embd,
weight_init=Normal(sigma=0.02, mean=0.0)),
nn.GELU(),
nn.Dense(in_channels=4 * n_embd, out_channels=n_embd,
weight_init=Normal(sigma=0.02, mean=0.0)),
nn.Dropout(keep_prob=1.0 - resid_pdrop),
])
def construct(self, x):
x = x + self.attn(self.ln1(x))
x = x + self.mlp(self.ln2(x))
return x
class GPT(nn.Cell):
"""
The full GPT language model, with a context size of block_size.
Args:
vocab_size (int): The size of the vocabulary in the embedded data.
n_embd (int): The size of the vector space in which words are embedded.
n_layer (int): The number of attention layer.
n_head (int): The number of multi-head.
block_size (int): The context size(Input sequence length).
use_gelu2 (bool): Use the new gelu2 activation function.
embd_pdrop (float): The probability of embd_pdrop. Default: 0.1
resid_pdrop (float): The probability of resid_pdrop. Default: 0.1
attn_pdrop (float): The probability of attn_pdrop. Default: 0.1
Returns:
Tensor, output tensor.
"""
def __init__(self, vocab_size: int, n_embd: int, n_layer: int, n_head: int, block_size: int, use_gelu2: bool,
embd_pdrop: float = 0.1, resid_pdrop: float = 0.1, attn_pdrop: float = 0.1):
super().__init__()
self.tok_emb = nn.Embedding(vocab_size, n_embd, embedding_table=Normal(sigma=0.02, mean=0.0))
self.pos_emb = mindspore.Parameter(P.Zeros()((1, block_size, n_embd), mindspore.float32))
self.drop = nn.Dropout(keep_prob=1.0 - embd_pdrop)
# transformer
if use_gelu2:
self.blocks = nn.SequentialCell(
[*[Block_2(n_embd, n_head, block_size, resid_pdrop, attn_pdrop) for _ in range(n_layer)]])
else:
self.blocks = nn.SequentialCell(
[*[Block(n_embd, n_head, block_size, resid_pdrop, attn_pdrop) for _ in range(n_layer)]])
# decoder head
self.ln_f = nn.LayerNorm(normalized_shape=[n_embd], epsilon=1e-05)
self.head = nn.Dense(in_channels=n_embd, out_channels=vocab_size, has_bias=False,
weight_init=Normal(sigma=0.02, mean=0.0))
self.block_size = block_size
def get_block_size(self):
return self.block_size
def construct(self, idx, masks):
_, t = idx.shape
token_embeddings = self.tok_emb(idx) # each index maps to a (learnable) vector
masks = P.ExpandDims()(masks, 2)
token_embeddings = token_embeddings * (1 - masks)
position_embeddings = self.pos_emb[:, :t, :] # each position maps to a (learnable) vector
x = self.drop(token_embeddings + position_embeddings)
x = self.blocks(x)
x = self.ln_f(x)
logits = self.head(x)
return logits
损失函数定义
class TransformerWithLoss(nn.Cell):
"""
Wrap the network with loss function to return Transformer with loss.
Args:
backbone (Cell): The target network to wrap.
"""
def __init__(self, backbone):
super(TransformerWithLoss, self).__init__(auto_prefix=False)
self.backbone = backbone
self.loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True)
def construct(self, x, targets, masks):
logits = self.backbone(x, masks)
loss = self.loss_fn(logits.view(-1, logits.shape[-1]), targets.view(-1))
masks = P.ExpandDims()(masks, 2)
masks = masks.view(-1)
loss *= masks
loss = P.ReduceMean()(loss)
return loss模型定义与数据集导入
# 修改当前路径至ICT/Transformer
if os.getcwd().endswith('ICT') or os.getcwd().endswith('ict'):
os.chdir("./Transformer")
# 启动ImageNet数据集选项
opts.use_ImageFolder = True
from datasets.dataset import load_dataset
from transformer_utils.util import AverageMeter
kmeans = np.load('../kmeans_centers.npy')
kmeans = np.rint(127.5 * (kmeans + 1.0))
# Define the dataset
train_dataset = load_dataset(opts.data_path, kmeans, mask_path=opts.mask_path, is_train=True,
use_imagefolder=opts.use_ImageFolder, prior_size=opts.prior_size,
random_stroke=opts.random_stroke)
train_dataset = train_dataset.batch(opts.batch_size)
step_size = train_dataset.get_dataset_size()
# Define the model
block_size = opts.prior_size * opts.prior_size
transformer = GPT(vocab_size=kmeans.shape[0], n_embd=opts.n_embd, n_layer=opts.n_layer, n_head=opts.n_head,
block_size=block_size, use_gelu2=opts.GELU_2, embd_pdrop=0.0, resid_pdrop=0.0, attn_pdrop=0.0)
model = TransformerWithLoss(backbone=transformer)
# Define the optimizer
optimizer = nn.Adam(model.trainable_params(), learning_rate=opts.learning_rate, beta1=opts.beta1, beta2=opts.beta2)
train_net = nn.TrainOneStepCell(model, optimizer)
然后开始训练,此处设置100轮epoch进行训练
在得到低维图像重建先验后,我们需要学习一个确定性映射将其重新缩放为原始分辨率,由于卷积神经网络在建模纹理方面具有优势,我们引入了一种基于卷积神经网络的引导上采样网络,它可以在掩码输入的指导下渲染重建的外观先验的高保真细节,上采样网络生成器代码实现如下
class Generator(nn.Cell):
def __init__(self, residual_blocks=8):
super(Generator, self).__init__()
self.encoder = nn.SequentialCell(
nn.Pad(((0, 0), (0, 0), (3, 3), (3, 3)), mode='REFLECT'),
nn.Conv2d(in_channels=6, out_channels=64, kernel_size=7, pad_mode='pad', padding=0, has_bias=True),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=2, pad_mode='pad', padding=1,
has_bias=True),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=4, stride=2, pad_mode='pad', padding=1,
has_bias=True),
nn.ReLU()
)
blocks = []
for _ in range(residual_blocks):
block = ResnetBlock_remove_IN(256, 2)
blocks.append(block)
self.middle = nn.SequentialCell(*blocks)
self.decoder = nn.SequentialCell(
nn.Conv2dTranspose(in_channels=256, out_channels=128, kernel_size=4, stride=2, pad_mode='pad', padding=1,
has_bias=True),
nn.ReLU(),
nn.Conv2dTranspose(in_channels=128, out_channels=64, kernel_size=4, stride=2, pad_mode='pad', padding=1,
has_bias=True),
nn.ReLU(),
nn.Pad(((0, 0), (0, 0), (3, 3), (3, 3)), mode='REFLECT'),
nn.Conv2d(in_channels=64, out_channels=3, kernel_size=7, pad_mode='pad', padding=0, has_bias=True),
)
def construct(self, images, edges, masks):
images_masked = (images * P.Cast()((1 - masks), mindspore.float32)) + masks
x = P.Concat(axis=1)((images_masked, edges))
x = self.encoder(x)
x = self.middle(x)
x = self.decoder(x)
x = (P.Tanh()(x) + 1) / 2
return x
class ResnetBlock_remove_IN(nn.Cell):
def __init__(self, dim, dilation=1):
super(ResnetBlock_remove_IN, self).__init__()
self.conv_block = nn.SequentialCell([
nn.Pad(((0, 0), (0, 0), (dilation, dilation), (dilation, dilation)), mode='REFLECT'),
nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=3, pad_mode='pad', dilation=dilation,
has_bias=True),
nn.ReLU(),
nn.Pad(((0, 0), (0, 0), (1, 1), (1, 1)), mode='SYMMETRIC'),
nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=3, pad_mode='pad', dilation=1, has_bias=True)
])
def construct(self, x):
out = x + self.conv_block(x)
return out
然后定义数据集和网络,并且加入损失函数定义
# 修改当前路径至ICT/Guided_Upsample
if os.getcwd().endswith('Transformer'):
os.chdir("../Guided_Upsample")
elif os.getcwd().endswith('ICT') or os.getcwd().endswith('ict'):
os.chdir("./Guided_Upsample")
from Guided_Upsample.datasets.dataset import load_dataset
from Guided_Upsample.models.loss import GeneratorWithLoss, DiscriminatorWithLoss
train_dataset = load_dataset(image_flist=opts.input, edge_flist=opts.prior, mask_filst=opts.mask,
image_size=opts.image_size, prior_size=opts.prior_size, mask_type=opts.mask_type,
kmeans=opts.kmeans, use_degradation_2=opts.use_degradation_2,
prior_random_degree=opts.prior_random_degree,
augment=True, training=True)
train_dataset = train_dataset.batch(opts.batch_size)
step_size = train_dataset.get_dataset_size()
generator = Generator()
discriminator = Discriminator(in_channels=3)
model_G = GeneratorWithLoss(generator, discriminator, opts.vgg_path, opts.inpaint_adv_loss_weight, opts.l1_loss_weight,
opts.content_loss_weight, opts.style_loss_weight)
model_D = DiscriminatorWithLoss(generator, discriminator)
class PSNR(nn.Cell):
def __init__(self, max_val):
super(PSNR, self).__init__()
base10 = P.Log()(mindspore.Tensor(10.0, mindspore.float32))
max_val = P.Cast()(mindspore.Tensor(max_val), mindspore.float32)
self.base10 = mindspore.Parameter(base10, requires_grad=False)
self.max_val = mindspore.Parameter(20 * P.Log()(max_val) / base10, requires_grad=False)
def __call__(self, a, b):
a = P.Cast()(a, mindspore.float32)
b = P.Cast()(b, mindspore.float32)
mse = P.ReduceMean()((a - b) ** 2)
if mse == 0:
return mindspore.Tensor(0)
return self.max_val - 10 * P.Log()(mse) / self.base10
psnr_func = PSNR(255.0)
# Define the optimizer
optimizer_G = nn.Adam(generator.trainable_params(), learning_rate=opts.lr, beta1=opts.beta1, beta2=opts.beta2)
optimizer_D = nn.Adam(discriminator.trainable_params(), learning_rate=opts.lr * opts.D2G_lr, beta1=opts.beta1,
beta2=opts.beta2)
然后开始训练
3.2 推理
训练完毕后开始推理使用,共分为两个阶段,第一阶段是Transformer模型推理生成部分,代码如下:
from mindspore.train import Model
# Define the model
block_size = opts.prior_size * opts.prior_size
transformer = GPT(vocab_size=C.shape[0], n_embd=opts.n_embd, n_layer=opts.n_layer, n_head=opts.n_head,
block_size=block_size, use_gelu2=opts.GELU_2, embd_pdrop=0.0, resid_pdrop=0.0, attn_pdrop=0.0)
# 根据相应权重文件进行路径修改,如果进行修改,请注意使用绝对路径避免不必要的错误
opts.ckpt_path = './ckpts_ICT/ms_train/Transformer/ImageNet_best.ckpt'
if os.path.exists(opts.ckpt_path):
print('Start loading the model parameters from %s' % (opts.ckpt_path))
checkpoint = mindspore.load_checkpoint(opts.ckpt_path)
mindspore.load_param_into_net(transformer, checkpoint)
print('Finished load the model')
transformer.set_train(False)
model = Model(transformer)
第二阶段是上采样部分,代码如下:
def stitch_images(inputs, *outputs, img_per_row=2):
gap = 5
columns = len(outputs) + 1
width, height = inputs[0][:, :, 0].shape
img = Image.new('RGB',
(width * img_per_row * columns + gap * (img_per_row - 1), height * int(len(inputs) / img_per_row)))
images = [inputs, *outputs]
for ix in range(len(inputs)):
xoffset = int(ix % img_per_row) * width * columns + int(ix % img_per_row) * gap
yoffset = int(ix / img_per_row) * height
for cat in range(len(images)):
im = images[cat][ix].asnumpy().astype(np.uint8).squeeze()
im = Image.fromarray(im)
img.paste(im, (xoffset + cat * width, yoffset))
return img
from upsample_utils.util import postprocess, imsave
opts.mask_type = 3
opts.mode = 2
opts.input = './input/'
opts.kmeans = './kmeans_centers.npy'
# 确保第二阶段的输入与第一阶段的输出相同
opts.prior = opts.save_url
generator = Generator()
generator.set_train(False)
# 根据相应权重文件进行路径修改,如果进行修改,请注意使用绝对路径避免不必要的错误
opts.ckpt_path = './ckpts_ICT/ms_train/Upsample/InpaintingModel_gen_best.ckpt'
if os.path.exists(opts.ckpt_path):
print('Start loading the model parameters from %s' % (opts.ckpt_path))
checkpoint = mindspore.load_checkpoint(opts.ckpt_path)
mindspore.load_param_into_net(generator, checkpoint)
print('Finished load the model')
psnr_func = PSNR(255.0)
test_dataset = load_dataset(image_flist=opts.input, edge_flist=opts.prior, mask_filst=opts.mask,
image_size=opts.image_size, prior_size=opts.prior_size, mask_type=opts.mask_type,
kmeans=opts.kmeans, condition_num=opts.condition_num,
augment=False, training=False)
index = 0
psnr = AverageMeter()
mae = AverageMeter()
test_batch_size = 1
test_dataset = test_dataset.batch(test_batch_size)
for sample in test_dataset.create_dict_iterator():
name = sample['name'].asnumpy()[0]
images = sample['images']
edges = sample['edges']
masks = sample['masks']
inputs = (images * (1 - masks)) + masks
index += test_batch_size
outputs = generator(images, edges, masks)
outputs_merged = (outputs * masks) + (images * (1 - masks))
psnr.update(psnr_func(postprocess(images), postprocess(outputs_merged)), 1)
mae.update((P.ReduceSum()(P.Abs()(images - outputs_merged)) / P.ReduceSum()(images)), 1)
result_merge = stitch_images(
postprocess(images),
postprocess(inputs),
postprocess(outputs_merged),
img_per_row=1
)
result_merge.show()
output = postprocess(outputs_merged)[0]
path = os.path.join(opts.save_url, name[:-4] + "_%d" % (index % opts.condition_num) + '.png')
imsave(output, path)
print('PSNR: {}, MAE: {}'.format(psnr.avg, mae.avg))
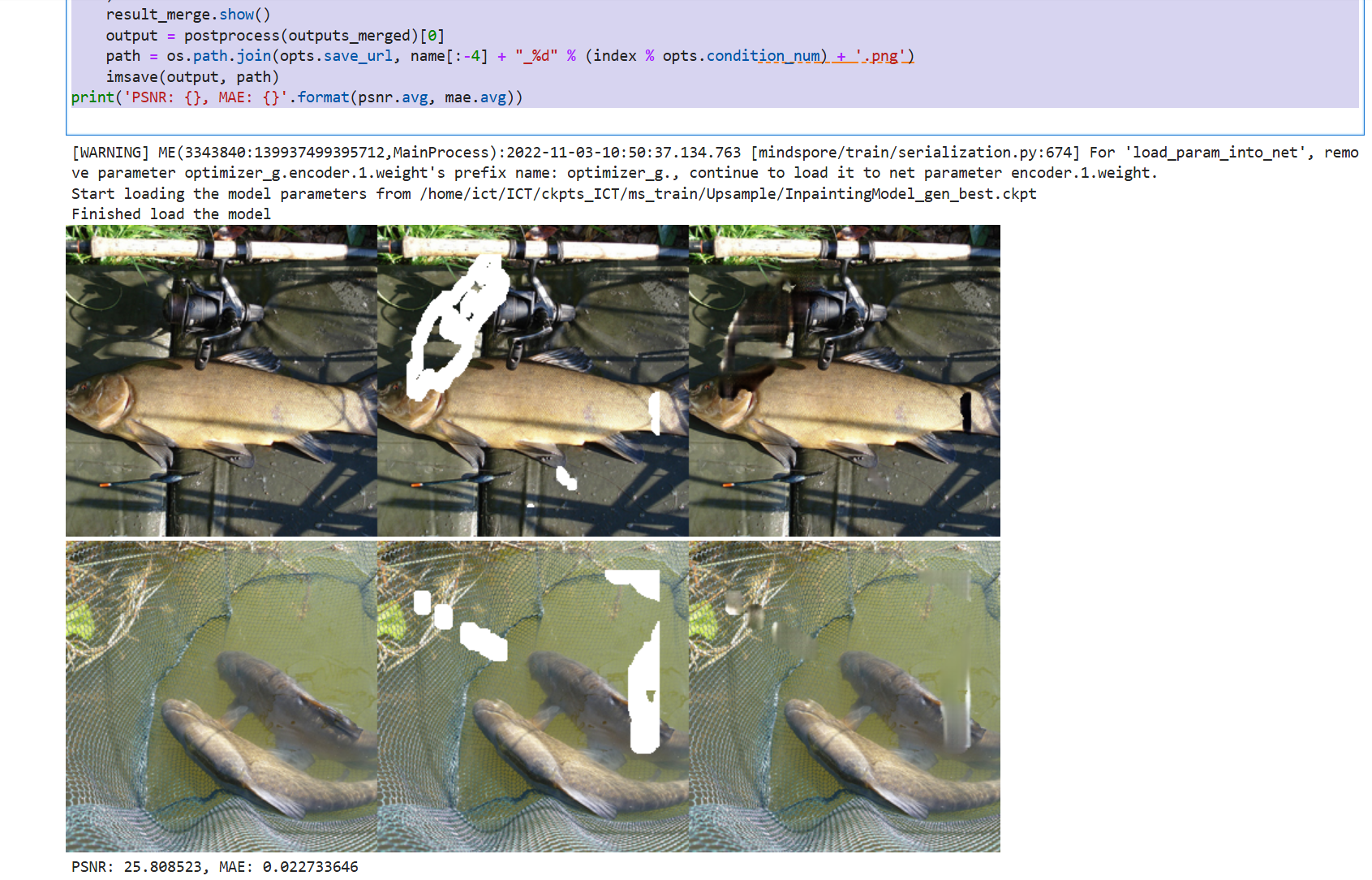
最终执行推理效果如下图所示,可以看到对图像添加掩码扰动,将原图、输入以及结果做了处理后统一输出,第一张图为未被损坏的原图,第二张图则是经过掩码处理后的图片,相当于输入,第三张图是网络的输出,即图像补全的结果。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)