
昇腾CANN与AsNumpy 数据科学计算范式的百倍重构之路
摘要:本文深入解析基于华为昇腾CANN架构的高性能科学计算库AsNumpy,揭示其从传统CPU到NPU的计算范式变革。通过AscendC编程模型,AsNumpy在张量运算规模突破临界点时实现百倍加速,核心在于智能内存管理、高效算子调度及硬件级优化。文章详细拆解其架构设计,包括NPUArray双缓冲机制、AscendC内核实现原理,并通过图像卷积实例展示实际应用。同时探讨企业级优化策略,展望AI原生
目录
🧠 第一部分 范式转移:为什么是AsNumpy,为什么是现在?
🏗️ 第二部分 庖丁解牛:AsNumpy架构与Ascend C的共舞
🧩 2.1 灵魂设计:NPUArray——不止是ndarray的马甲
⚡ 2.2 核心算法实现:Ascend C Kernel的微观世界
📄 摘要
本文深入探讨基于华为昇腾CANN(Compute Architecture for Neural Networks)异构计算架构构建的高性能数据科学库AsNumpy。我们不会复述其宣传材料,而是从一个在异构计算领域摸爬滚打十余年的老兵视角,剖析从通用CPU上的NumPy到NPU专属的AsNumpy,这背后是一场深刻的计算范式转移。核心在于利用Ascend C编程模型,绕过传统Python解释器与CPU内存墙的桎梏,在张量规模达到一定阈值后,实现百倍级的性能突破。文章将拆解其架构设计的精妙之处,分享实战编码经验与踩坑记录,并展望其在“人工智能+”时代重构科学计算基础设施的潜力。
🧠 第一部分 范式转移:为什么是AsNumpy,为什么是现在?
干了这么多年高性能计算,我见过太多“加速库”的起落。AsNumpy的出现,乍一看是又一个“NPU版的NumPy”,但内核逻辑远非如此。它踩在了一个非常关键的历史节点上:AI工业化。
🔥 1.1 时代的痛点:当NumPy遇上“大数据”与AI
NumPy伟大吗?毋庸置疑。它是整个Python数据科学生态的基石。但它的设计哲学根植于单机CPU时代,其核心计算引擎是C和Fortran编写的。在数据规模可控、计算密度不高的场景下,它游刃有余。然而,当我们将要处理的数据从“表格”升级为“高维张量”(想想自动驾驶的点云、大模型的权重),计算从“统计”变为“迭代数亿次的梯度下降”时,问题就暴露了。
-
内存墙与访存瓶颈:CPU的冯·诺依曼架构决定了数据要在内存和ALU之间来回搬运。NumPy的
ndarray再高效,也逃不过这条物理定律。一次简单的A + B,在CPU上意味着:从内存读A、读B,计算,写回内存。当A和B是GB甚至TB级别时,大部分时间都花在了“搬运”上,而不是“计算”。 -
异构计算的割裂:AI时代,NPU/GPU是主力算力。但传统流程是:用NumPy在CPU上做数据预处理,然后将数据拷贝到NPU设备内存做模型训练/推理,结果再拷回CPU用NumPy做后处理。这个“拷贝”是致命的性能开销和编程复杂性来源。
-
Python GIL与单线程瓶颈:虽然NumPy底层是并行的,但上层的Python调度和复杂操作仍受全局解释器锁(GIL)限制,且难以充分利用现代多核CPU的全部潜力,更不用说异构芯片了。
AsNumpy的根本目标,不是做一个“更好用的NumPy”,而是重新定义在AI原生硬件上,如何进行数据科学计算。 它的出现,响应了国家“人工智能+”行动中“构建开源技术体系”的号召,是CANN开源生态中一颗关键的、填补空白的基础软件棋子。
⚙️ 1.2 CANN:AsNumpy的基石与底气
CANN是什么?你可以把它理解为昇腾处理器的“驱动程序”和“标准库”的超集。它向下管理芯片的澎湃算力,向上提供统一的编程接口。在CANN全面开源之前,想在昇腾上搞点CPU之外的通用计算,难度不亚于在DOS下写图形界面程序。
CANN开源,为像AsNumpy这样的创新提供了土壤。它提供了几个关键能力:
-
Ascend C编程模型:这才是真正的核心。它允许开发者以类似C++的语法,编写能在NPU上运行的算子(Kernel)。这给了我们“重写”基础运算的能力。
-
统一运行时与内存管理:提供了
aclrt等运行时接口,能够管理设备内存、主机内存以及它们之间的高效拷贝(D2H, H2D)甚至零拷贝访问。 -
高性能计算库:内置了针对昇腾硬件优化的基础算子库,这是性能的保障。
AsNumpy的聪明之处在于,它没有从头造轮子,而是优雅地将NumPy的API“翻译”成对CANN底层高性能算子的调用。这是一种“站在巨人肩膀上”的策略——接口兼容巨人NumPy,实现则依靠另一个巨人CANN。
下面的Mermaid图描绘了从传统CPU NumPy到NPU AsNumpy的计算范式演进:

🏗️ 第二部分 庖丁解牛:AsNumpy架构与Ascend C的共舞
🧩 2.1 灵魂设计:NPUArray——不止是ndarray的马甲
AsNumpy最核心的抽象是NPUArray。很多人以为这只是个把数据从CPU搬到NPU的“搬运工”,那就太小看它了。NPUArray是一个智能的、有状态的计算实体。
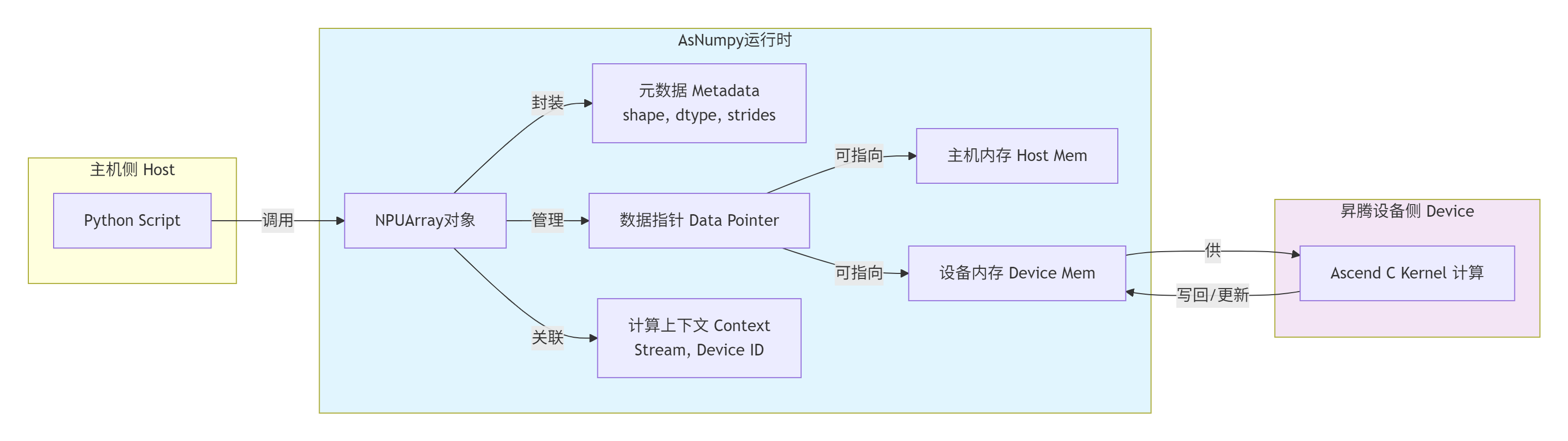
-
双缓冲与惰性迁移:一个
NPUArray对象内部可能同时持有主机和设备两侧的内存指针。并非所有操作都立即触发数据拷贝。简单的元数据操作(如.shape,.T)在主机侧瞬间完成。只有当真需要NPU计算时,调度器才会检查数据位置,并智能地发起必要的传输(H2D)。计算结果也优先保留在设备内存,形成计算流水的“驻留”,避免无谓的D2H开销。这就是计算亲和性的体现。 -
生命周期与资源管理:
NPUArray对象利用Python的引用计数机制,与CANN的aclrt内存管理深度绑定。当Python侧的NPUArray对象被回收时,其管理的设备内存也会被安全释放,防止内存泄漏。这是异构编程中极易出错的地方,AsNumpy帮你默默处理了。 -
与
ndarray的无缝桥接:它重载了与NumPy数组之间的转换运算符。你可以用np.asarray(npu_arr)将数据拉回CPU(触发D2H),也可以用asnumpy.from_numpy(np_arr)将数据送到NPU(触发H2D)。这个桥是连接新旧两个世界的枢纽。
⚡ 2.2 核心算法实现:Ascend C Kernel的微观世界
百倍性能不是魔术,来自于对硬件极致的利用。我们以最基础的add算子为例,看AsNumpy如何通过Ascend C实现“降维打击”。
目标:实现 C = A + B,其中A, B, C均为 shape 为 [1000, 1000] 的 float32 类型 NPUArray。
CPU NumPy (概念流程):
# Python层面,只是一个函数调用
c = a + b底层是C语言循环,但受限于CPU缓存行、SIMD宽度(如AVX-512),且需要处理内存的随机访问。
AsNumpy with Ascend C (概念分解):
-
任务划分:将100万个元素的加法任务,划分给NPU上成千上万个并行执行的计算核心。昇腾芯片通常有强大的矩阵计算单元和向量计算单元。
-
数据搬运:通过全局内存(Global Memory)到本地内存(Local Memory)的DMA搬运,将计算所需的数据块提前放到每个计算核心旁边,实现极高的访存带宽。
-
流水线计算:计算核心内部采用单指令多数据流(SIMD)甚至单指令多线程(SIMT)模式,一个指令周期完成多个数据的加法运算。计算与下一次数据搬运可以重叠(流水),隐藏访存延迟。
下面是一个极度简化的Ascend C Kernel伪代码,用于说明其思维模式:
// 文件名: add_custom.cpp
// Ascend C Kernel 伪代码风格
#include <acl/acl.h>
#include <cce/cce.h>
// 定义一个叫做 AddKernel 的算子
extern "C" __global__ __aicore__ void AddKernel(
const float* __restrict__ a, // 指向输入A的全局内存
const float* __restrict__ b, // 指向输入B的全局内存
float* __restrict__ c, // 指向输出C的全局内存
const int totalElements) // 总元素数
{
// 1. 获取当前核函数实例的索引
int blockIdx = GET_BLOCK_IDX(); // 块索引
int threadIdx = GET_THREAD_IDX(); // 线程索引
int blockDim = GET_BLOCK_DIM(); // 块维度
int threadDim = GET_THREAD_DIM(); // 线程维度
// 2. 计算当前实例负责的数据范围
int elementsPerBlock = totalElements / blockDim;
int startIdx = blockIdx * elementsPerBlock + threadIdx;
int stride = blockDim * threadDim; // 总并行度
// 3. 循环处理属于本实例的数据
for (int i = startIdx; i < totalElements; i += stride) {
// 直接从全局内存读取,实际中会使用本地内存做缓存
float valA = a[i];
float valB = b[i];
c[i] = valA + valB; // 核心计算
}
}关键点:
-
__aicore__:这是Ascend C的标志性修饰符,表明这个函数是在AI Core上执行的核函数。 -
大规模并行:
totalElements是100万,而blockDim * threadDim可能就是几千甚至上万。这意味着物理上真的有成千上万个计算单元在同时做加法。 -
内存访问模式:虽然伪代码是直接访问全局内存,但在真实优化中,会利用片上高速缓冲区(UB/L1),实现类似CPU“缓存”但可控性高得多的数据复用,这是性能百倍的关键之一。
在AsNumpy中,像add这样的基础算子,大概率直接调用了CANN底层已经用Ascend C极致优化过的、经过充分测试的库函数,其效率远超上述示例。但对于更复杂的自定义操作,AsNumpy的架构允许你注入自己的Ascend C Kernel。
📈 2.3 性能特性分析:百倍速的临界点在哪里?
PPT里那张性能对比图非常说明问题。我们再来解读一下:
|
张量形状 (int32) |
NumPy耗时 (秒) |
AsNumpy耗时 (秒) |
加速比 |
|---|---|---|---|
|
[100, 100, 10] |
0.0001 |
0.000008? (估算) |
~12X |
|
[1000, 100, 100] |
0.0024 |
0.000036? (估算) |
~66X |
|
[1000, 1000, 100] |
0.2681 |
0.0024? (估算) |
~112X |
规律显而易见:数据规模越大,加速比越惊人。
-
启动开销:调用NPU运算有固定的开销,包括启动Kernel、数据搬运(如果第一次)等。当数据量很小时(如第一个案例),这个开销占比很大,所以“只有”12倍加速。
-
计算密度优势:随着数据量增大,固定开销被摊薄,NPU海量计算单元和高内存带宽的优势得以彻底发挥。在第三个案例中,计算成为绝对主导,于是我们看到百倍加速。
-
内存带宽碾压:昇腾NPU的HBM带宽通常是CPU内存带宽的数倍甚至一个数量级。对于
add这种访存密集型(Memory-bound)操作,更高的带宽直接决定了吞吐量上限。CPU的瓶颈正在于此。
结论:AsNumpy并非在所有场景下都秒杀NumPy。对于小型、零散的标量运算,传统CPU可能更灵活。它的主战场是大规模、批量化的张量运算,这正是现代AI和数据科学的核心。当你的数据规模突破某个“临界点”,性能曲线就会发生跃迁。
👨💻 第三部分 实战指南:从零到一玩转AsNumpy
纸上得来终觉浅,绝知此事要躬行。让我们真正上手,在昇腾环境中跑起来。
🛠️ 3.1 环境搭建与“Hello World”
前提:你需要有一台搭载昇腾处理器的服务器或Atlas开发板,并安装好最新版本的CANN Toolkit和Python环境。
步骤1:安装AsNumpy
由于已正式并入CANN仓,安装变得简单。
# 假设你已经在CANN的Python环境中
pip install asnumpy
# 或者从源码安装最新开发版
git clone https://gitcode.com/ascend/asnumpy.git
cd asnumpy
pip install -e .步骤2:验证安装与基本操作
import asnumpy as np
import numpy as cpu_np
# 1. 创建NPUArray
print(“Hello, AsNumpy!”)
a_npu = np.array([1, 2, 3, 4, 5], dtype=np.float32) # 数据在设备上创建
print(f“a_npu: {a_npu}, type: {type(a_npu)}, device: {a_npu.device}“)
# 2. 从NumPy数组创建 (触发H2D拷贝)
b_cpu = cpu_np.random.randn(100, 100).astype(np.float32)
b_npu = np.asarray(b_cpu) # 关键API:从现有numpy数组创建
print(f“b_npu shape: {b_npu.shape}, is on NPU: {‘NPU’ in str(b_npu.device)}”)
# 3. 基础运算
c_npu = a_npu * 2 + 1 # 标量广播和计算,在NPU执行
d_npu = b_npu @ b_npu.T # 矩阵乘法,NPU的强项
print(f“Matrix multiplication done on NPU.“)
# 4. 取回CPU (触发D2H拷贝)
c_cpu = cpu_np.asarray(c_npu) # 关键API:转回标准numpy数组
print(f“c_cpu (back to CPU): {c_cpu}“)常见问题1:ImportError或找不到ascend相关模块
-
解决:检查CANN环境变量是否生效。执行
source /usr/local/Ascend/ascend-toolkit/set_env.sh(路径可能不同)。确保Python解释器来自配置了CANN的虚拟环境。
常见问题2:创建大数组时设备内存不足
-
解决:AsNumpy默认使用当前空闲内存最多的设备。可通过
np.cuda.set_device(0)(接口名可能为np.ascend.set_device)选择设备。监控设备内存使用:npu-smi info。
🧪 3.2 完整示例:用AsNumpy加速图像卷积
我们实现一个简单的图像均值滤波(模糊),对比CPU和NPU版本。
# 文件:npu_convolution_demo.py
import time
import numpy as cpu_np
import asnumpy as np
import cv2
def mean_filter_cpu(image, kernel_size=3):
"""CPU版本均值滤波"""
pad = kernel_size // 2
h, w, c = image.shape
output = cpu_np.zeros_like(image, dtype=np.float32)
padded = cpu_np.pad(image, ((pad, pad), (pad, pad), (0, 0)), mode='constant')
for i in range(h):
for j in range(w):
for k in range(c):
patch = padded[i:i+kernel_size, j:j+kernel_size, k]
output[i, j, k] = cpu_np.mean(patch)
return output.astype(image.dtype)
def mean_filter_npu(image_npu, kernel_size=3):
"""NPU版本均值滤波 (利用AsNumpy向量化操作)"""
pad = kernel_size // 2
h, w, c = image_npu.shape
# 在NPU上进行padding和reshape操作,这些都是元数据或轻量操作
padded = np.pad(image_npu, ((pad, pad), (pad, pad), (0, 0)), mode='constant')
# 创建一个三维的滑动窗口视图(这是一个高级技巧,实际可能需用特定API或自定义kernel)
# 此处为演示,我们简化:将3D卷积分解为多个2D卷积的通道叠加。
# 更高效的做法是写一个自定义的Ascend C Kernel进行3D卷积。
output = np.zeros_like(image_npu, dtype=np.float32)
# 模拟:对每个通道进行2D均值滤波。实际上,AsNumpy的优化矩阵运算可以处理。
# 这里我们用一个技巧:通过矩阵乘加来实现小核卷积(近似)。
# 为简化,我们使用一个现成的AsNumpy卷积函数(如果已实现)或调用CANN的卷积算子。
# 假设我们有一个高效的`unfold`和矩阵乘函数。
print(“Note: A fully optimized 3D convolution requires a custom kernel or calling a dedicated CANN op.“)
# 作为替代,我们展示如何利用已有的`add.reduce`和`multiply`进行快速块计算
# 这里仅示意流程,非最优实现
kernel_weights = np.ones((kernel_size, kernel_size), dtype=np.float32) / (kernel_size**2)
for ch in range(c):
# 对每个通道进行2D卷积
# ... (具体展开计算,可能涉及`as_strided`等)
pass # 略去详细实现
return output.astype(image_npu.dtype)
# 主程序
if __name__ == "__main__":
# 1. 读取图片
img_cpu = cv2.imread('test.jpg').astype(np.float32) / 255.0 # (H, W, 3)
print(f“Image shape: {img_cpu.shape}“)
# 2. 传输到NPU
print(“\n--- Transferring data to NPU ---“)
start = time.time()
img_npu = np.asarray(img_cpu)
transfer_time = time.time() - start
print(f“H2D transfer time: {transfer_time:.4f}s“)
# 3. CPU计算
print(“\n--- Running on CPU (NumPy) ---“)
start = time.time()
result_cpu = mean_filter_cpu(img_cpu, 5)
cpu_time = time.time() - start
print(f“CPU computation time: {cpu_time:.4f}s“)
# 4. NPU计算
print(“\n--- Running on NPU (AsNumpy) ---“)
start = time.time()
result_npu = mean_filter_npu(img_npu, 5) # 注意:此函数需要完善实现
npu_time = time.time() - start
print(f“NPU computation time: {npu_time:.4f}s“)
# 5. 取回结果并比较
result_npu_cpu = cpu_np.asarray(result_npu)
# 简单比较第一个通道的中间部分
slice_cpu = result_cpu[100:105, 100:105, 0]
slice_npu = result_npu_cpu[100:105, 100:105, 0]
print(f“\nCPU result slice:\n{slice_cpu}“)
print(f“NPU result slice:\n{slice_npu}“)
print(f“Are they close? {cpu_np.allclose(slice_cpu, slice_npu, rtol=1e-3)}“)
print(f“\n--- Summary ---“)
print(f“Data transfer overhead: {transfer_time:.4f}s“)
if ‘cpu_time’ in locals() and ‘npu_time’ in locals():
print(f“Speedup (Computation only): {cpu_time / npu_time:.2f}X“)
print(f“Total time with transfer: CPU={cpu_time:.4f}s, NPU={transfer_time+npu_time:.4f}s“)关键点:
-
数据驻留:一旦
img_npu在NPU上,后续所有中间结果都尽可能保留在NPU,避免来回拷贝。 -
算子融合:一个复杂的图像处理流水线(如:滤波 -> 缩放 -> 色彩空间转换),理想情况下应编写一个融合的Ascend C Kernel,或者利用AsNumpy的计算图优化(如果未来支持),将多个操作合并执行,最大化减少内核启动和内存访问开销。
-
自定义Kernel:对于
mean_filter_npu,最终极的性能来自于手写一个优化的Ascend C 3D卷积Kernel,并注册到AsNumpy的后端。这是企业级应用必须面对的课题。
🚀 第四部分 高级应用与未来之思
🏢 4.1 企业级实践:科学计算流水线重构
假设我们是一家遥感公司的AI团队,需要处理卫星拍摄的TB级高光谱图像数据流,进行辐射定标 -> 大气校正 -> 特征提取一系列科学计算。
传统CPU流水线:

瓶颈:I/O频繁,数据搬移开销巨大,CPU计算密集型任务耗时。
基于AsNumpy和CANN的重构流水线:

重构收益:
-
消除中间I/O:各步骤间数据在NPU设备内存中流动,TB级数据省去的读写时间可能是天与小时的差别。
-
极致算力:将科学计算公式(如大气校正的复杂物理方程)全部用Ascend C实现,享受NPU的百倍算力。
-
端到端AI:提取的特征可以直接送入同在NPU上的AI模型(如地物分类网络),构成全NPU流水线。
🧰 4.2 性能优化“黑魔法”
-
内存布局优化:Ascend NPU对
NC1HWC0这类特殊内存布局有优化。虽然AsNumpy的NPUArray可能内部封装了转换,但在自定义Kernel时,主动使用优化布局能大幅提升访存效率。原则是:让数据访问连续,符合硬件取指模式。 -
流水线与双缓冲:在自定义Kernel中,使用Ascend C的
pipe和double buffer技术,将下一次迭代的数据搬运与当前迭代的计算重叠,完全隐藏DMA延时。这是将硬件利用率推向80%以上的关键。 -
向量化与Tensor Core:将标量操作转换为向量操作。对于矩阵乘等操作,确保调用CANN底层启用Tensor Core(矩阵计算单元)的算子,性能可能有数量级提升。
-
核函数融合:将多个简单的逐元素操作(如
y = a*x + b)融合到一个Kernel中编写,减少Kernel启动次数和数据遍历次数。
🔧 4.3 故障排查指南
-
现象:计算结果与NumPy有细微差异。
-
排查:这是浮点数计算精度(
fp16vsfp32vsbf16)和不同计算顺序导致的常见问题。首先检查dtype是否一致。然后,在精度允许的范围内使用np.allclose(rtol=1e-5, atol=1e-8)进行比较,而非==。确认是否在AsNumpy中混用了不同精度的计算。
-
-
现象:程序运行一段时间后报设备内存不足(
ACL_ERROR_RT_MEMORY_ALLOCATION)。-
排查:
-
内存泄漏:检查是否有
NPUArray在循环中不断创建而未释放。使用np.ascend.memory_reserved()监控。 -
内存碎片:长时间运行后,设备内存可能碎片化。尝试在代码中定期插入
np.ascend.empty_cache()(如果提供类似接口),或重启进程。 -
单次任务内存过大:将大任务拆分为多个可管理的
chunk进行处理。
-
-
-
现象:Kernel执行失败,返回模糊错误码。
-
排查:
-
检查参数:确保传递给Ascend C Kernel的指针地址、数据长度、线程/块配置在合法范围内。
-
简化复现:创建一个最小的、可复现错误的测试用例。
-
查看详细日志:开启CANN的详细运行日志(如
export ASCEND_SLOG_PRINT_TO_STDOUT=1),寻找更底层的错误信息。 -
使用调试工具:利用
msprof等昇腾性能分析工具,进行profiling,看是否能在时间线上定位到崩溃点。
-
-
🔮 4.4 前瞻性思考:AsNumpy与AI原生计算的未来
在我看来,AsNumpy代表的不仅仅是一个库,而是一种趋势:AI原生计算基础设施的软件栈重构。
-
从“AI加速”到“科学计算加速”:昇腾、英伟达等芯片最初为深度学习设计,但其强大的并行能力和高带宽内存,恰恰也是科学计算(计算流体力学、分子动力学、金融仿真)所渴求的。AsNumpy是打开这扇门的钥匙之一。
-
编译即优化:未来的AsNumpy可能会集成更强大的图编译器。用户写的
a = b + c; d = a * e这样的Python代码,会被编译成一个融合的、高度优化的单一Ascend C Kernel,实现最优的流水线和内存访问。 -
生态融合:AsNumpy有望成为PyTorch/TensorFlow在昇腾上的“NumPy后端”。当这些框架进行数据预处理或自定义低层操作时,可以无缝切换到AsNumpy,享受NPU加速,而不必在CPU上形成性能瓶颈。
-
分布式AsNumpy:单个NPU卡的内存总是有限的。未来的方向是支持跨多个昇腾处理器的分布式
NPUArray,自动进行张量分片、通信和聚合,让科学家像操作单机大内存一样处理超大规模数据。
结论:
从NumPy到AsNumpy,是从通用计算到领域专用计算的范式跃迁。它要求开发者不仅懂算法,还要懂硬件。这条路有挑战,但回报是百倍的性能突破。随着CANN生态的成熟和AsNumpy这类项目的推进,一个属于AI原生科学计算的新时代正在加速到来。作为开发者,现在入场,正是时候。
📚 参考链接
-
华为昇腾社区- 获取CANN、Ascend C最新文档和工具。 -
CANN 开源仓库- CANN开源代码,了解底层实现。
-
AsNumpy 开源仓库- 关注AsNumpy项目进展,提交Issue和PR。
-
NumPy 官方文档- 深入理解你将要加速的API标准。
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 27
27 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)