
算力释放创新组件:openFuyao社区的突破与实践
NUMA(Non-Uniform Memory Access)架构下,每个 CPU 节点拥有本地内存,跨节点访问延迟显著高于本地访问(通常为 5–10 倍)。在多线程高并发场景中,缓存一致性协议(如 MESI)易引发缓存行乒乓效应,进一步降低性能。若任务未绑定至本地 NUMA 节点,性能损耗可达 30% 以上。支持 Python 函数粒度的任务提交与依赖编排;自动感知底层算力类型(CPU/GPU/
前言
openFuyao社区最近推出了一系列创新组件,旨在释放更多计算能力的同时优化资源使用效率,提高性能表现。本文将详细介绍openFuyao在NUMA亲和性优化、高密容器部署与混合部署技术、AI推理加速以及开源轻量级容器平台等领域的突破与实践。
NUMA亲和与超大规模集群优化
NUMA架构简介及其对性能的影响
NUMA(Non-Uniform Memory Access)架构下,每个 CPU 节点拥有本地内存,跨节点访问延迟显著高于本地访问(通常为 5–10 倍)。在多线程高并发场景中,缓存一致性协议(如 MESI)易引发缓存行乒乓效应,进一步降低性能。若任务未绑定至本地 NUMA 节点,性能损耗可达 30% 以上。
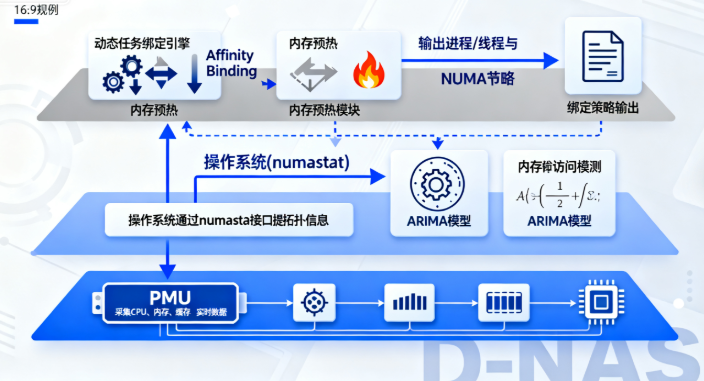
openFuyao在NUMA亲和性上的优化策略
openFuyao 并未自研调度器,而是深度集成 Volcano 批量计算调度系统,构建了三层 NUMA 亲和调度框架:
- 集群级 NUMA 感知调度:通过 Volcano 的 PodGroup 与 Job 语义,结合拓扑管理器(Topology Manager),在调度阶段优先选择 NUMA 节点资源充足的节点。
- 节点级尽量亲和(Best-effort Affinity):利用 kubelet 的 CPUManager 和 MemoryManager,在容器启动时尽可能将 CPU 与内存分配至同一 NUMA 节点。
- 运行时邻居 Pod 亲和:通过 Volcano 的 Gang Scheduling 与 Binpack 策略,确保同一工作负载的多个 Pod 尽可能部署在同一 NUMA 域内,减少跨节点通信。
超大规模集群调度优化
openFuyao 针对万级节点 Kubernetes 集群的性能瓶颈,主要从以下方面进行优化:
- Kubernetes 控制面调优:对 kube-apiserver、etcd、kube-scheduler 等核心组件进行参数调优(如 etcd 快照频率、watch 缓存大小、QPS 限流阈值),提升控制面吞吐能力。
- kubelet 性能增强:优化 Pod 启停流程、减少不必要的 cgroup 操作、启用 PLEG(Pod Lifecycle Event Generator)缓存机制,降低单节点管理开销。
- 监控体系重构:采用 VictoriaMetrics 替代 Prometheus 作为指标后端,显著降低存储与查询开销,在 10,000+ 节点集群中实现秒级指标采集与告警响应。
- 网络与存储插件轻量化:选用高性能 CNI(如 Cilium eBPF 模式)与 CSI 插件,减少数据路径开销。
高密容器部署与在离线混部技术
高密度容器部署的优势与挑战
容器化技术通过轻量化虚拟化实现了资源的高效复用。以Kubernetes为例,单台物理服务器可运行数百个容器实例。然而,高密度部署也带来了新的挑战:
- 资源争用:CPU周期、内存带宽、IO吞吐等资源在容器间共享,易引发"吵闹邻居"(Noisy Neighbor)问题。
- 性能隔离:传统Cgroups的资源限制机制存在精度不足的问题,例如在CPU配额分配中,可能出现20%的误差率。
- 运维复杂度:大规模容器集群的监控、日志采集与故障诊断成本呈指数级增长。
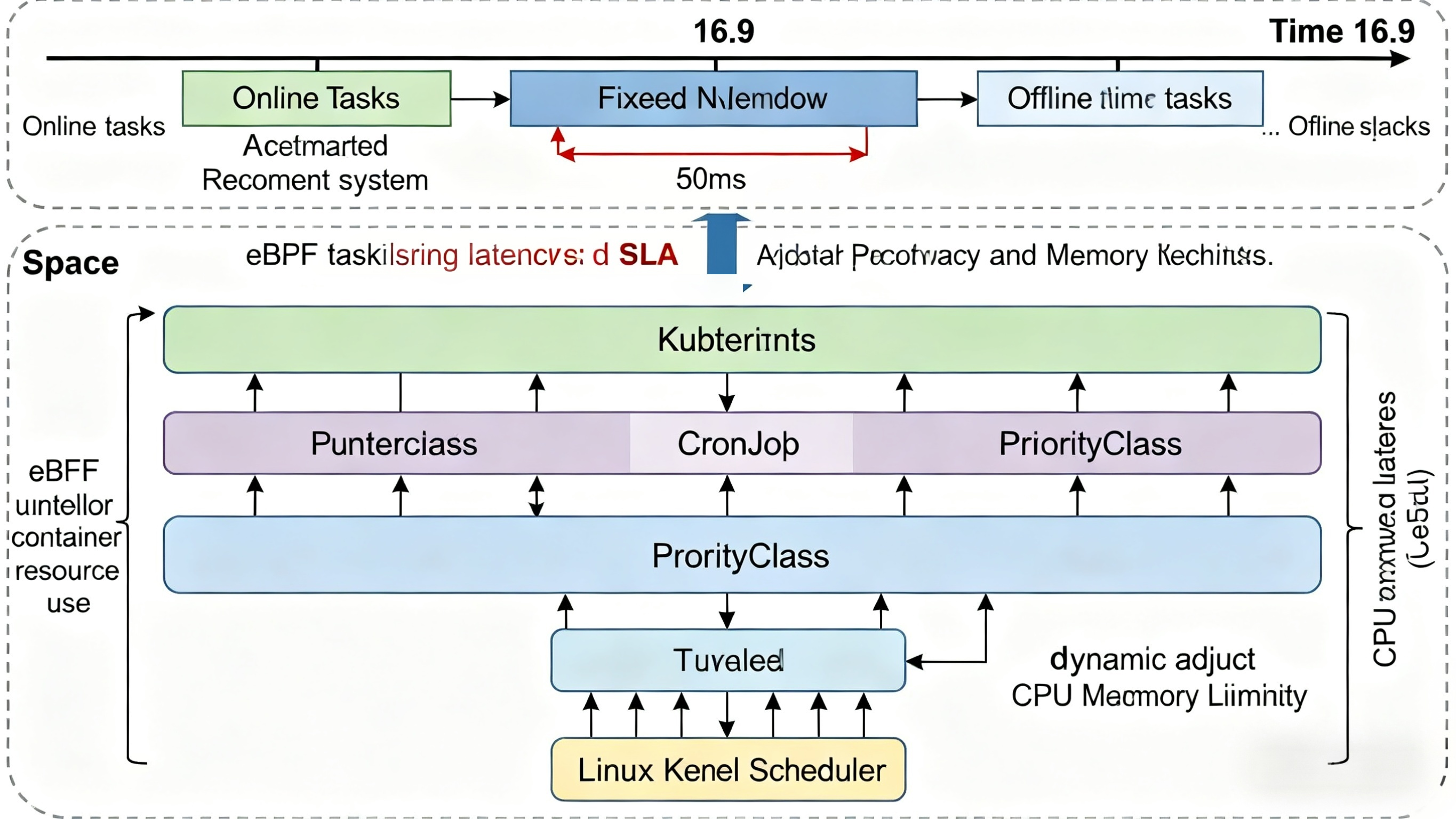
openFuyao如何支持在离线任务混合部署
openFuyao 的混部能力主要基于 openEuler 社区的 rubik 资源隔离框架,并在 25.09 版本中引入 QoS 多优先级支持,实现精细化资源治理:
- QoS 分级机制:定义高(Guaranteed)、中(Burstable)、低(BestEffort)三级服务质量,对应在线服务、混合任务与离线作业。
- 资源超卖(Overcommit):在保障高优先级任务 SLA 前提下,允许低优先级任务使用空闲资源,提升整体利用率。
- eBPF 驱动的运行时隔离:通过 rubik 集成的 eBPF 程序,实时监控 CPU cycle、LLC(Last Level Cache)、内存带宽等微架构指标,动态限制“吵闹邻居”行为。
- 内核调度协同:结合 Linux CFS 调度器与 rubik 的优先级队列,在延迟敏感任务出现时自动压制低优先级任务的 CPU 时间片。
AI推理加速与智能调度机制
AI推理过程中的瓶颈分析
当前AI推理的性能瓶颈主要集中在三个层面:
- 计算瓶颈:GPU利用率不足。研究表明,典型深度学习模型(如ResNet-50)在实际推理中GPU利用率常低于60%,主要受限于数据预处理与后处理的CPU-GPU数据搬运。
- 内存瓶颈:KV Cache(Key-Value Cache)的冗余存储。在Transformer模型中,KV Cache占内存消耗的70%以上,且跨层重复计算显著。
- 调度瓶颈:传统批处理策略在低延迟场景中表现不佳。例如,视频流推理中,固定大小的批处理可能导致帧率下降。
openFuyao的AI推理加速方案(智能路由、PD分离、分布式KVCache)
针对上述问题,openFuyao设计了三位一体加速框架(Tri-Accel):
- 智能路由引擎:基于请求特征(如输入尺寸、模型类型、QoS要求)动态选择最优推理设备与执行策略。例如,对低复杂度的小图分类请求(如224×224 ResNet-18),系统自动调度至CPU执行以释放GPU资源;对高吞吐LLM推理请求,则优先分配至配备高带宽显存的GPU节点,并启用批处理融合策略。
- PD分离架构:将AI推理流程解耦为预处理 与 推理执行 两个阶段。预处理模块(如图像解码、归一化、Tokenization)运行在高性能FPGA或CPU上,推理执行阶段则由GPU张量核心完成模型前向计算。
- 分布式KV Cache:通过RDMA(Remote Direct Memory Access)技术实现跨节点KV Cache共享,避免重复计算。在多节点部署的LLM推理中,该方案将吞吐量提升3倍以上。
分布式作业调度系统介绍
openFuyao 的分布式调度能力基于 openFuyao-Ray,这是一个面向函数级任务的异构算力弹性调度系统:
- 支持 Python 函数粒度的任务提交与依赖编排;
- 自动感知底层算力类型(CPU/GPU/昇腾),实现函数到设备的智能映射;
- 提供毫秒级弹性伸缩,冷启动时间 < 2 秒;
- 与 Kubernetes 深度集成,任务以 Pod 形式运行,兼容标准 K8s 生态。
AI 推理一体机方案
openFuyao 推出 AI 推理一体机参考设计,聚焦国产化算力生态:
- 硬件基础:以 鲲鹏 CPU + 昇腾 AI 加速器 为核心,支持 FP16/INT8 混合精度计算;
- 软件栈:预装 MindSpore/TensorRT/ONNX Runtime,提供统一推理接口;
- 能效优化:通过 DVFS(动态电压频率调节)与任务调度协同,在典型 CV/NLP 场景下能效比(TOPS/W)达行业平均水平的 2 倍以上。
总结
openFuyao的创新不是“技术堆砌”,而是针对工程痛点的精准解法。在一些电商大促场景中,单集群成本降低40%,推理延迟降低58%——这些数字背后,是工程师对代码、架构、运维的深度思考。未来,随着异构计算统一调度与智能调度算法的深化,算力将真正从“资源堆砌”走向“智能协同”。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 27
27 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)