
基于达芬奇架构与CANN软件栈的深度学习模型异构算力迁移全链路解析
在后摩尔定律时代,通用处理器(CPU)的指令集架构(ISA)已难以满足深度神经网络(DNN)对张量(Tensor)并行计算的算力需求。专用领域架构(Domain Specific Architecture, DSA)应运而生,其中以华为昇腾(Ascend)AI处理器为代表的NPU(Neural Processing Unit)通过定制化的Cube与Vector计算单元,显著提升了能效比。然而,硬件
摘要
在后摩尔定律时代,通用处理器(CPU)的指令集架构(ISA)已难以满足深度神经网络(DNN)对张量(Tensor)并行计算的算力需求。专用领域架构(Domain Specific Architecture, DSA)应运而生,其中以华为昇腾(Ascend)AI处理器为代表的NPU(Neural Processing Unit)通过定制化的Cube与Vector计算单元,显著提升了能效比。然而,硬件架构的异构性给上层应用开发带来了显著的移植壁垒。本文以昇腾CANN(Compute Architecture for Neural Networks)为研究对象,结合GitCode云端实验环境,深入剖析PyTorch框架如何通过torch_npu适配层实现从x86/CUDA平台到ARM/Ascend平台的平滑迁移。本文将详细阐述底层驱动交互、运行时环境构建、算子分发机制(Dispatcher)及硬件性能遥测技术。
第一章 异构计算体系架构与CANN软件栈深度剖析
异构计算的核心在于将控制流(Control Flow)与数据流(Data Flow)分离。CPU负责复杂的逻辑控制与任务调度,而NPU负责高吞吐量的矩阵与向量运算。
1.1 达芬奇架构的计算原语
昇腾AI处理器基于达芬奇架构,其核心计算单元包括:
- Cube Unit(矩阵运算单元):专用于执行矩阵乘法(GEMM),在FP16精度下提供极高的算力密度,是卷积神经网络(CNN)与Transformer架构的核心加速器。
- Vector Unit(向量运算单元):处理Element-wise操作,如Activation(激活函数)、BatchNorm(批归一化)等。
- Scalar Unit(标量运算单元):负责流程控制与地址计算。
1.2 CANN:软硬协同的抽象层
CANN作为连接上层AI框架与底层硬件的桥梁,其内部架构自底向上分为四层:
- 计算资源层(Hardware Abstraction):直接与PCIe接口、HBM(High Bandwidth Memory)及片上缓存交互。
- 芯片使能层(Chip Enable Layer):包含驱动(Driver)、CANN Lib库以及RTS(Runtime System)。
npu-smi等管理工具直接调用此层接口获取寄存器状态。 - 执行层(Execution Layer):核心为GE(Graph Engine)与ACL(Ascend Computing Language)。GE负责将PyTorch下发的动态图或静态图转换为适应NPU硬件拓扑的离线图,并进行算子融合(Operator Fusion)以减少内存搬运开销。
- 算子库层(Operator Library):提供高性能算子库(TBE, Tensor Boost Engine),支持自定义算子开发。
1.3 PyTorch Dispatcher与异构后端适配机制
PyTorch的设计哲学基于动态图(Eager Mode),其底层核心库ATen(A Tensor Library)定义了通用的算子接口。为了支持异构硬件,PyTorch引入了Dispatcher(分发器)机制。
torch_npu 插件的本质是一个实现了PyTorch后端接口的动态链接库。其工作流程如下:
- 设备注册:通过
c10::RegisterOperators宏,向PyTorch核心注册PrivateUse1设备类型,并将其别名映射为npu。 - 算子重载:针对ATen定义的每一个算子(如
aten::add,aten::mm),torch_npu提供了调用CANN ACL接口的实现版本。 - 内存管理接管:
torch_npu实现了自定义的CachingAllocator,接管了NPU HBM的分配与释放,以减少cudaMalloc/aclrtMalloc等系统调用的开销,避免内存碎片化。
第二章 云端异构计算环境的实例化与资源调度
实验环境的构建依赖于容器化技术与硬件直通(Passthrough)机制。在GitCode平台上,用户操作的实质是向Kubernetes集群申请包含特定NPU设备的Pod资源。
2.1 算力资源的申请与编排
用户登录GitCode平台后,通过Web控制台与后台调度系统交互。
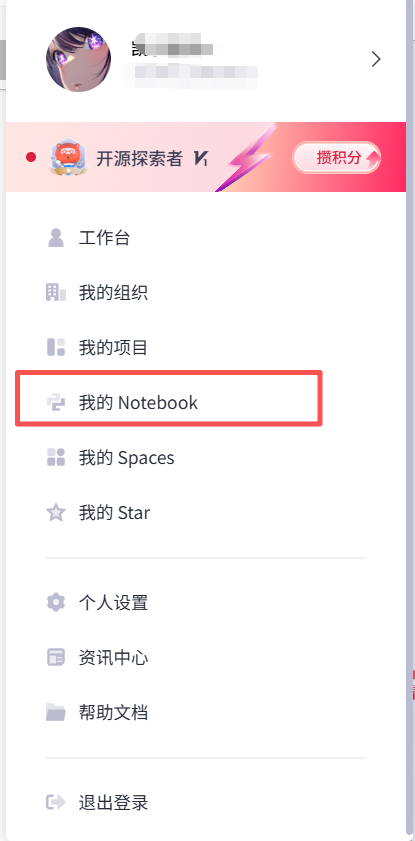
图2-1 资源管理入口界面的可视化解析
图2-1展示了用户接入云端算力集群的入口。此时,用户的请求尚未触及物理硬件,仅处于身份认证与路由分发阶段。
进入资源列表后,资源类型的选择触发了底层的调度逻辑。
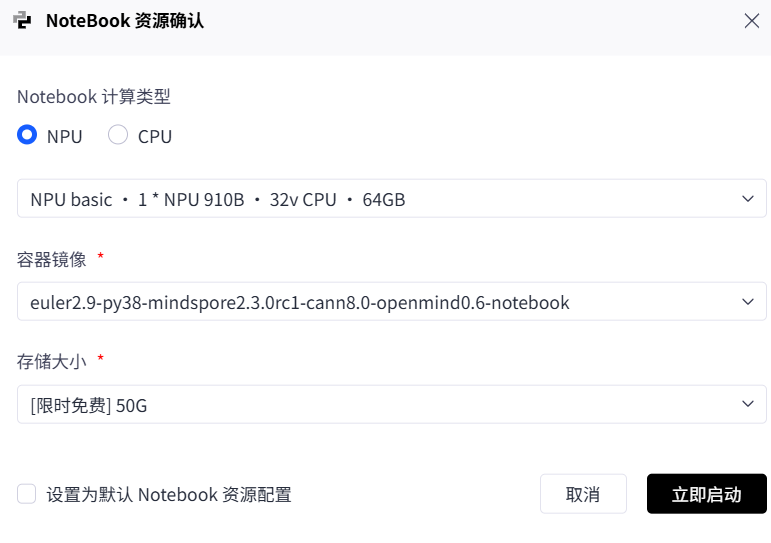
图2-2 NPU专用计算节点的调度与激活
图2-2演示了异构资源绑定的关键操作。用户选择“NPU”并点击“激活”时,集群管理系统(如K8s)会执行以下操作:
- 节点筛选:在物理节点池中寻找带有空闲Ascend 910B加速卡的服务器。
- 设备隔离:利用Linux cgroups与Device Plugin机制,将特定的
/dev/davinciX设备文件映射到目标容器的命名空间中。 - 算力锁定:独占该NPU设备,防止其他租户争抢。
2.2 容器运行时的初始化配置
在资源激活后,需配置容器镜像的启动参数。
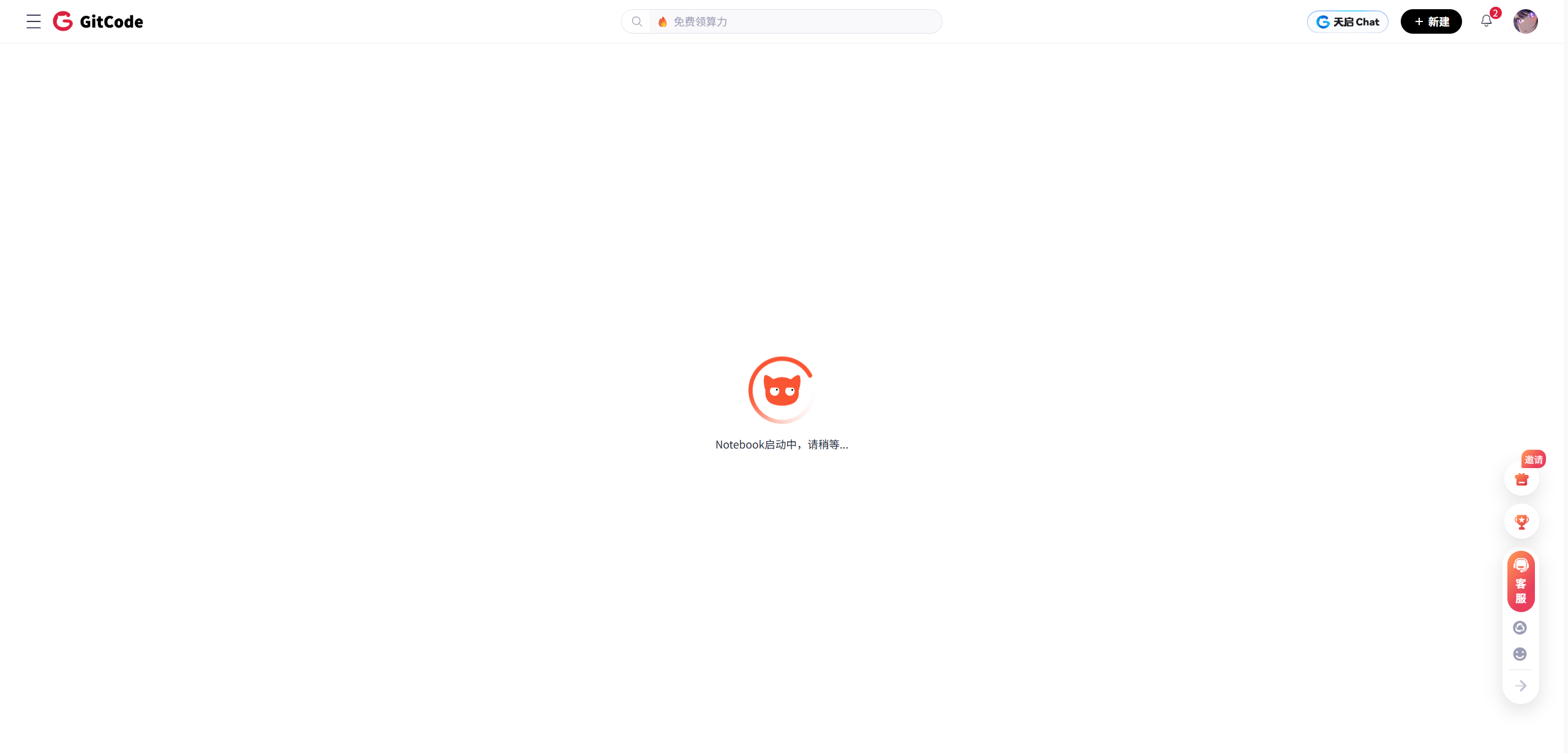
图2-3 容器实例化与环境预置流程
图2-3反映了环境初始化的过程。在此阶段,三个核心配置项决定了软件栈的基线:
- 硬件类型(NPU):确认加载昇腾驱动模块。
- 硬件型号(Ascend 910B):该型号支持PCIe 4.0与32GB HBM2,具备FP16 256 TFLOPS的峰值算力,决定了后续算子编译的目标架构(Soc Version)。
- 镜像版本(MindSpore 2.3预置):选择此镜像的战略意义在于利用其预装的正确版本的固件(Firmware)与驱动(Driver)。CANN Toolkit的版本必须与驱动版本严格兼容(ABI Compatibility)。使用官方验证过的镜像可规避底层依赖冲突。
第三章 内核态硬件诊断与用户态环境构建
环境启动后,首要任务是验证用户态(User Space)工具链与内核态(Kernel Space)驱动的通信链路是否正常。
3.1 Shell环境下的硬件链路探测
通过Jupyter Lab提供的Web Terminal,可以直接访问Linux Shell。
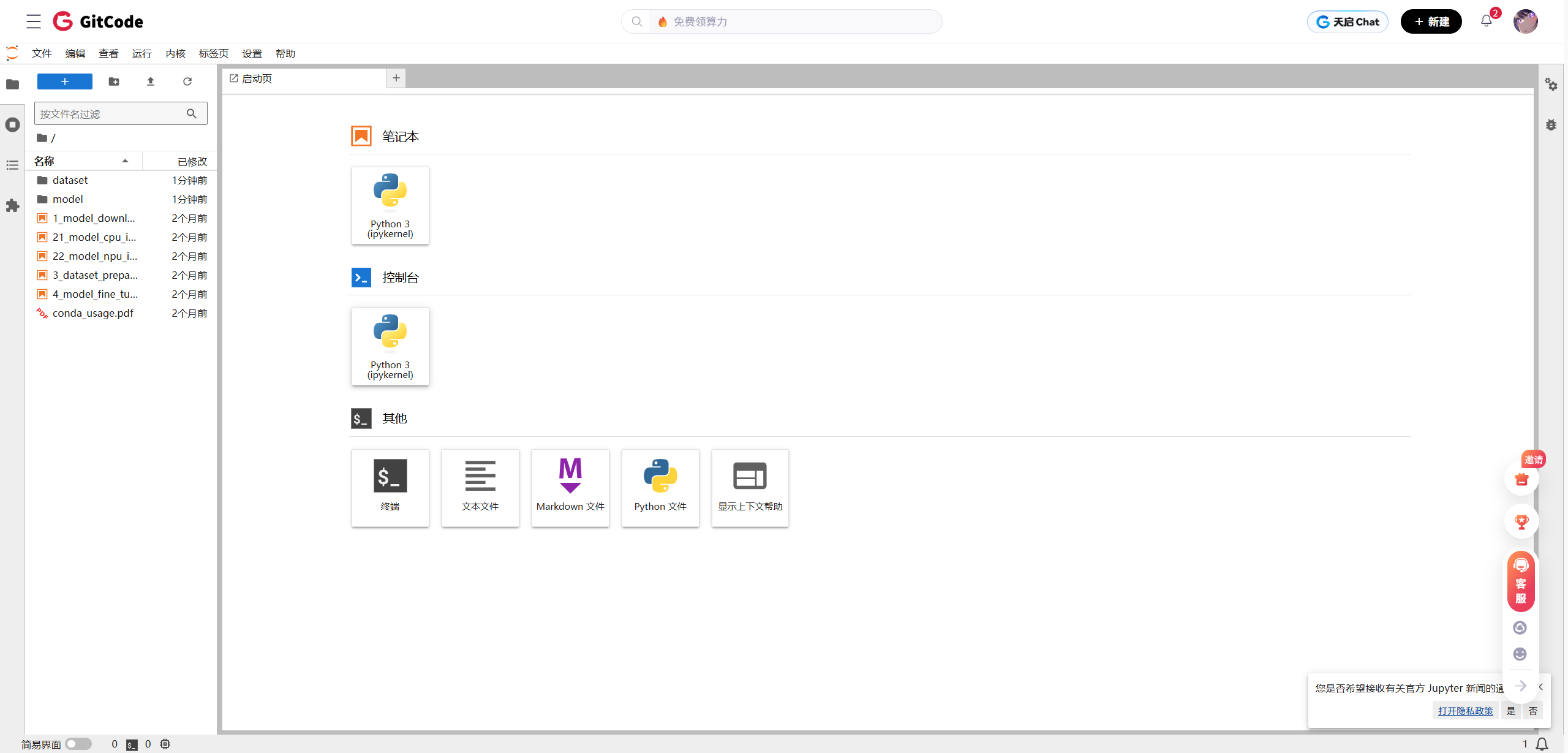
图3-1 命令行交互接口的建立
图3-1展示了Shell会话的启动。这是所有后续诊断指令的执行入口。
3.2 NPU系统管理接口(npu-smi)的数据解读
npu-smi 工具直接读取管理CPU(Management CPU)上的传感器数据与状态寄存器。
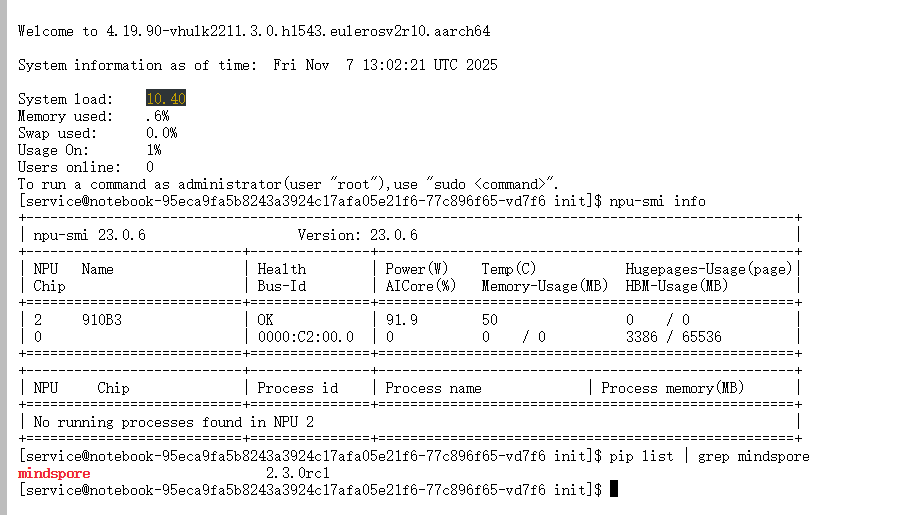
图3-2 硬件健康状态与预置软件栈的深度审计
图3-2的输出信息包含了关键的硬件遥测数据:
- PCIe Bus Info (0000:00:00.0):证实NPU设备已成功挂载至PCIe总线。
- Driver Version:显示NPU驱动版本。此版本号定义了CANN软件栈的上限与下限兼容性。
- HBM Capacity & Usage (1258MiB / 64511MiB):Ascend 910B板载64GB HBM。初始的1258MiB占用为驱动层、固件及系统保留内存(System Reserved Memory)。若此值异常高,说明存在僵尸进程未释放显存。
- Chip Health (OK):表示芯片内部ECC校验及温度传感器状态正常。
- AI Core (0%):当前无计算负载。AI Core利用率是后续评估训练效率的核心指标。
同时,grep mindspore的输出验证了Python环境中已存在基础的AI框架依赖,间接证明了共享对象库(.so文件)路径配置正确。
第四章 依赖管理策略与PyTorch异构环境部署
异构计算环境的复杂性主要体现在软件栈的版本依赖管理上。PyTorch版本、torch_npu版本、CANN版本与NPU驱动版本构成了一个严格的四维依赖矩阵。
4.1 环境隔离与解释器配置
采用Conda进行环境隔离,可以避免系统级Python库的符号冲突(Symbol Conflict)。
conda create -n py_npu python=3.8 -y
conda activate py_npu
指定Python 3.8是为了确保与预编译的Wheel包具有最佳的二进制兼容性。
4.2 框架与插件的精准适配安装
在NPU环境下,PyTorch本身退化为一种高层API描述语言。
-
PyTorch Host侧安装:
pip install torch==1.8.1+cpu torchvision==0.9.1+cpu -i https://pypi.tuna.tsinghua.edu.cn/simple必须安装CPU版本。若安装CUDA版本,其内置的CUDA Runtime库不仅占用大量磁盘空间,还可能在动态链接时引入未定义的符号错误,且NPU并不使用CUDA内核。
-
NPU Device侧插件安装:
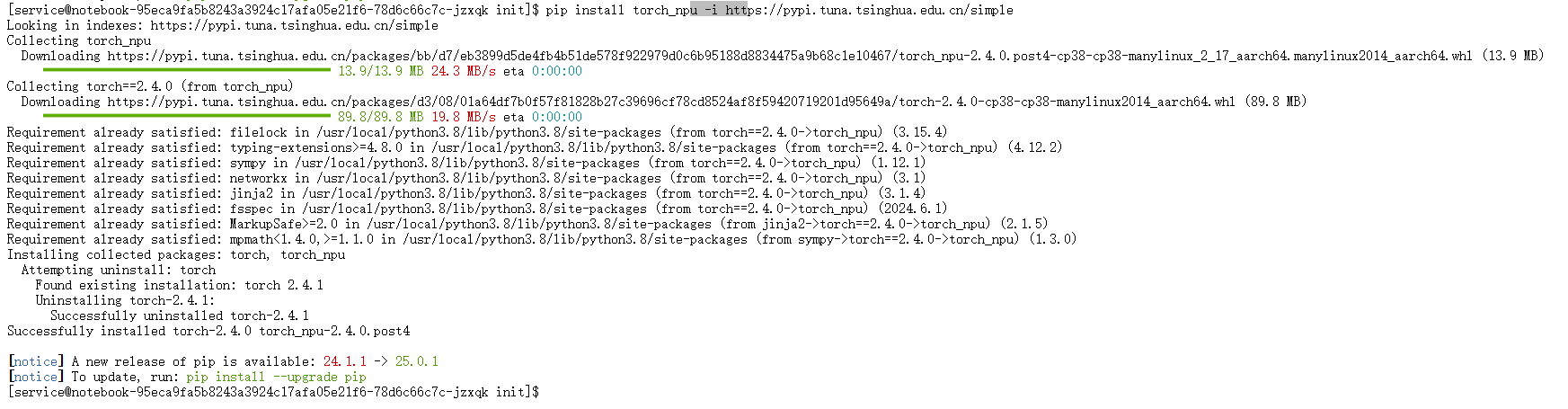
图4-1 异构后端插件的获取与部署
图4-1展示了torch_npuWheel包的安装过程。该包内含了编译好的CANN算子适配层代码。安装过程中,pip会将库文件部署至site-packages,并注册Entry Points,以便PyTorch在运行时发现该插件。
4.3 运行时链接库与设备握手验证
安装完成后,需验证动态链接库的加载与硬件握手协议。

图4-2 运行时环境的完整性验证
图4-2通过Python脚本进行了端到端测试:
- 模块导入测试:
import torch_npu成功执行,意味着Python解释器成功加载了libtorch_npu.so及其依赖的CANN运行时库(libascendcl.so)。 - 设备可用性测试:
torch.npu.is_available()返回True。该函数内部调用了aclInit和aclrtGetDevice接口,不仅确认了软件库的存在,还实际完成了一次Host到Device的通信握手。
第五章 设备无关性编程范式与代码重构策略
为了降低迁移成本,工程实践中应遵循“设备无关性(Device Agnostic)”的设计模式。代码应通过抽象层屏蔽底层硬件的差异,而非硬编码特定设备。
5.1 算力后端的动态注册与识别
在PyTorch脚本头部,必须显式导入适配插件。
import torch
import torch_npu # 关键:触发后端注册机制
Python的导入机制会触发 torch_npu 包的 __init__.py,进而调用底层C++代码中的 c10::RegisterOperators,将NPU后端的Dispatch Key注册到PyTorch的全局分发表中。
5.2 异构设备选择器的逻辑构建
传统的 device = 'cuda' 写法缺乏扩展性。应构建具备优先级判断的设备选择器:
def get_computation_device():
"""
构建设备优先级队列:NPU > CUDA > CPU
实现代码的跨平台可移植性。
"""
if torch.npu.is_available():
# 返回封装后的NPU设备对象,格式为 npu:x
return torch.device('npu:0')
elif torch.cuda.is_available():
return torch.device('cuda:0')
else:
return torch.device('cpu')
5.3 数据流与控制流的透明迁移
一旦 device 对象被正确初始化,PyTorch的Tensor操作将自动路由。
model.to(device) # 触发模型权重从DDR到HBM的异步拷贝
# ...
for data, target in dataloader:
data = data.to(device) # 触发Batch数据搬运
output = model(data) # 触发NPU算子执行
当执行 model(data) 时,PyTorch Dispatcher根据Tensor的设备属性(Device Type: PrivateUse1),将计算图中的节点(Node)分发给 torch_npu 中对应的算子实现。这些实现会构建ACL命令流,提交给NPU的任务调度器(Task Scheduler)。
第六章 硬件性能遥测与负载分析
代码运行仅代表逻辑正确,真正的工程落地需要验证算力是否得到有效利用。这需要对硬件层面的各项指标进行实时监控。
6.1 实时监控看板的构建
利用Linux的 watch 指令,可以以高频采样率刷新 npu-smi 的输出,形成动态监控流。
watch -n 1 npu-smi info
6.2 关键性能指标(KPI)的物理意义解析
图6-1 训练负载下的硬件状态快照
图6-1展示了模型训练进行时的NPU硬件状态,各指标具有明确的物理含义:
- AI Core Utilization (利用率):图中显示利用率已非0%。这是最重要的性能指标。
- 数据解读:在深度学习训练的反向传播(Backpropagation)阶段,涉及大量的GEMM运算,此时AI Core应处于高负载状态。若利用率持续较低,可能意味着数据预处理(Data Loading)成为瓶颈,导致NPU处于饥饿状态(Starvation),或者是算子未被正确融合,导致大量的内存换入换出。
- Memory-Usage (HBM占用):显存占用量出现显著跃升。
- 数据解读:除了存储模型权重(Weights)和梯度(Gradients)外,训练过程中产生的中间激活值(Activations)和优化器状态(Optimizer States)消耗了大量显存。显存的稳定占用表明
CachingAllocator正在正常工作,未发生内存泄漏。
- 数据解读:除了存储模型权重(Weights)和梯度(Gradients)外,训练过程中产生的中间激活值(Activations)和优化器状态(Optimizer States)消耗了大量显存。显存的稳定占用表明
- Power (功耗):功耗随计算强度的增加而上升。高功耗是晶体管高速开关的物理表现,直接对应着高算力输出。
- Temperature (温度):监控芯片结温(Junction Temperature)。过高的温度会触发动态电压频率调整(DVFS),导致降频从而影响训练性能。
第七章 结论
本文从体系结构、系统环境、依赖管理、代码适配及性能监控五个维度,全方位剖析了基于CANN架构的PyTorch模型迁移技术。通过深入分析,得出以下工程结论:
- 抽象层的价值:CANN通过软硬协同设计,成功屏蔽了达芬奇架构底层的复杂性。开发者无需编写底层的TBE算子,仅需通过标准PyTorch API即可调用NPU算力。
- 环境一致性的重要性:异构计算的稳定性高度依赖于驱动、固件、工具链与框架版本的严格匹配。采用容器化与环境隔离技术是解决依赖地狱(Dependency Hell)的最佳实践。
- 设备无关性设计:构建可移植的AI应用,核心在于代码逻辑中对设备对象的动态抽象。
综上所述,昇腾CANN生态已具备支撑大规模AI应用迁移的工程能力。掌握这一整套从底层诊断到上层开发的异构计算技术栈,对于提升AI工程落地效率具有重要的战略意义。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 31
31 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)