
NN算子——MatMul算子性能优化深度剖析
这次CANN算子开源周Meetup的NN算子专场让我受益匪浅。从OPS-NN算子仓的整体架构,到MatMul算子的深度优化,再到"望闻问切"的性能分析方法论,每一部分都让我对昇腾NPU的算子开发有了更深的理解。核心要点回顾OPS-NN提供完整的神经网络算子覆盖MatMul是神经网络的"心脏",优化它至关重要性能优化的四大关键:计算强度、负载均衡、内存访问、流水线调度算子融合可以实现1+1>2的效果
【CANN训练营学习笔记】NN算子专场——MatMul算子性能优化深度剖析
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
📖 本文思维导图
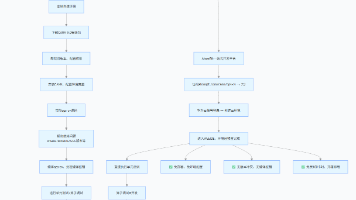
mindmap
root((NN算子优化))
OPS-NN算子仓
算子分类
基础操作
融合操作
数学运算
优化相关
核心计算
应用场景
MatMul算子
矩阵乘法基础
神经网络地位
全连接90%
CNN70%
Transformer
Cube加速
性能优化技术
计算强度优化
提升算力
减少搬运
提高带宽
并行执行
负载均衡
分块策略
全载模式
内存访问优化
L2缓存优化
大包搬运
权重预取
流水线调度
双缓冲
搬出优化
算子融合
Transpose+MatMul
Cube+ReduceSum
精度保持
望闻问切方法论
望-数据采集
闻问-数据分析
切-深入诊断
优化实施
一、与神经网络算子的初次相遇
今天参加了CANN算子开源周Meetup的NN算子专场,两位技术大牛陈奇老师和唐超老师给我们带来了关于OPS-NN算子仓的深度解析。作为一个深度学习从业者,我平时用的最多的就是各种神经网络算子,但从未如此深入地了解过它们在NPU上的实现原理和优化技巧。这次学习让我大开眼界,特别是MatMul算子的优化实践,简直就是一堂生动的性能优化课!
二、OPS-NN算子仓全景图
2.1 算子仓的定位
陈奇老师首先给我们介绍了OPS-NN算子仓在整个CANN架构中的定位:
核心定位:提供神经网络计算能力的高阶算子库
架构层次:处于算子库架构的高阶计算层,包含Math模块和Extension扩展模块
这让我想起平时用PyTorch时,那些看似简单的API调用(如torch.matmul、torch.relu),背后都是这些高性能算子在支撑。
2.2 算子能力全覆盖

老师给我们展示了OPS-NN仓的算子分类,我整理成了一个思维导图式的结构:
1. 基础操作类
- 循环操作
- 控制类操作
- 索引操作
- 哈希操作
2. 融合操作类
- RNN核心算子
- LSTM、GRU等循环神经网络算子
3. 数学运算类
- 激活函数(ReLU、Sigmoid、Tanh等)
- 集合操作
- 聚合函数(Sum、Mean、Max等)
- 损失函数(CrossEntropy、MSE等)
4. 优化相关类
- 优化器(Adam、SGD等)
- 归一化(BatchNorm、LayerNorm等)
- 量化操作
5. 核心计算类
- MatMul(矩阵乘法)
- 卷积操作
2.3 一个简单神经网络的算子组成
老师用一个最简单的两层神经网络来说明算子的使用:
# 第一层:线性变换 + ReLU激活
hidden = ReLU(Linear(input))
# 第二层:线性变换
output = Linear(hidden)
# 损失计算
loss = Loss(output, target)
# 优化器更新
Optimizer.step()
看似简单的几行代码,背后涉及到:
- Linear层用到了MatMul算子
- ReLU是激活函数算子
- Loss是损失函数算子
- Optimizer涉及多个优化器算子
所有这些算子都在OPS-NN仓中!
三、MatMul算子:神经网络的心脏
3.1 矩阵乘法基础回顾
唐超老师接下来深入讲解了MatMul算子,他首先回顾了矩阵乘法的基础:
定义:两个矩阵的二元运算
Cm×n=Am×k×Bk×nC_{m \times n} = A_{m \times k} \times B_{k \times n}Cm×n=Am×k×Bk×n
维度要求:A的列数必须等于B的行数
计算过程:对于结果矩阵C的每个元素
Ci,j=∑r=1kAi,r×Br,jC_{i,j} = \sum_{r=1}^{k} A_{i,r} \times B_{r,j}Ci,j=r=1∑kAi,r×Br,j
虽然这是基础知识,但老师强调理解这个计算过程对后续的优化非常重要。
3.2 MatMul在神经网络中的地位
老师给出的几个数据让我震惊:
- 全连接网络:MatMul计算量占比90%以上!
- CNN网络:MatMul计算量占比70%以上!
- Transformer架构:注意力机制中大量使用MatMul
也就是说,优化好MatMul算子,就能显著提升整个模型的性能!
3.3 NPU硬件加速的威力
老师对比了向量计算单元和Cube计算单元:
向量计算单元:
- 一次处理一个数的乘加运算
- 适合向量运算
Cube计算单元:
- 专门为矩阵计算设计
- 一次完成16×16×16的大Cube计算
- 针对AI计算场景优化,达到极致能效比
理论算力公式(FP16数据类型):
算力=16×16×16×频率×AI核数×2\text{算力} = 16 \times 16 \times 16 \times \text{频率} \times \text{AI核数} \times 2算力=16×16×16×频率×AI核数×2
其中因子2代表乘法和加法两种操作。
计算耗时模型:
计算耗时=计算数据量计算算力\text{计算耗时} = \frac{\text{计算数据量}}{\text{计算算力}}计算耗时=计算算力计算数据量
很明显,算力越高,耗时越小,模型跑得越快!
四、性能优化的四大关键技术
4.1 计算强度优化
老师提出了一个关键概念:计算强度
定义:从内存单元读取数据后参与计算的算力比
总运行时间:
总耗时=计算时间+搬运时间\text{总耗时} = \text{计算时间} + \text{搬运时间}总耗时=计算时间+搬运时间
理想状态:计算耗时 > 搬运耗时,达到计算瓶颈
这意味着计算单元在持续工作,没有等待数据的空闲时间。
四个优化方向:
- 提升计算算力:充分利用Cube单元
- 减少搬运数据量:通过数据复用
- 提高搬运带宽:优化内存访问模式
- 计算与搬运并行:流水线技术
4.2 负载均衡优化
老师用了一个很形象的例子来说明负载均衡的重要性:
场景1:细粒度分块
- 20个核心参与计算
- 负载均衡很好
- 但搬运数据量多
场景2:粗粒度分块
- 只有6个核心参与计算
- 存在短板效应(有的核很忙,有的核空闲)
- 整体性能受限于最慢的核
优化目标:找到最优的分块大小,实现负载均衡
分块公式:
搬运量=M×BestM切分块数+N×BestN切分块数\text{搬运量} = M \times \text{BestM切分块数} + N \times \text{BestN切分块数}搬运量=M×BestM切分块数+N×BestN切分块数
通过算法选择最优的BestM和BestN!
全载模式:当BestM等于M时触发,可以减少重复搬运
这里我画了一个简单的示意图来理解:
优化前:
核0: [====工作====]
核1: [====工作====]
核2: [==工作==]
核3: [空闲..........]
优化后:
核0: [====工作====]
核1: [====工作====]
核2: [====工作====]
核3: [====工作====]
4.3 内存访问优化
这部分内容特别精彩!老师讲了三个优化技巧:
技巧1:L2缓存优化
问题:传统访问模式按顺序依次访问,导致L2数据频繁刷新和替换
优化方案:
- 区块化分块
- 让更多核心同时访问相同内存块
- 滑动窗口利用数据复用
效果:提升L2缓存命中率,减少访问更慢的HBM
技巧2:大包搬运
老师用了一个很形象的比喻:类似高速公路,大货车一次搬运效率更高!
原理:
- 将小的数据操作合并为大的批处理
- 减少搬运次数
- 提高带宽利用率
应用场景:推理场景下通过数据格式转换实现大包搬运
技巧3:权重预取
策略:让数据先飞一会!提前读取到L2缓存
适用条件:权重为常量的情况
效果:当需要使用时,数据已经在L2缓存中了
4.4 流水线调度优化
这是我觉得最巧妙的优化!
双缓冲优化:
传统流程:
数据搬运 → 计算 → 数据搬出
数据搬运 → 计算 → 数据搬出
计算和搬运串行执行,存在大量空闲时间。
双缓冲优化:
缓冲区A: 数据搬运 | 缓冲区B: 计算
缓冲区A: 计算 | 缓冲区B: 数据搬运
计算和下一块数据的搬运同时进行!
效果:减少计算空洞,让计算单元更连贯地工作
搬出优化:
策略:计算完成一小块数据立即触发搬出,不需要等待所有计算完成
优势:进一步提高流水线效率
五、算子融合:1+1>2的艺术

5.1 Transpose+MatMul融合
老师讲的第一个融合案例让我印象深刻:
问题:传统流程需要两次Transpose数据变换
Input → Transpose → MatMul → Transpose → Output
每次Transpose都要访问内存,开销很大!
解决方案:TransposeBatchMatMul融合算子
技术原理:通过硬件地址跳跃设置,直接获取需要的内存数据
优化效果:消除两个Transpose算子的开销,性能提升显著!
这让我想起编译器优化中的常量折叠,原理是类似的——在更高层次上进行优化。
5.2 Cube+ReduceSum融合
场景:MatMul计算后需要对Batch轴做ReduceSum
传统流程:
MatMul → 写入内存 → 读取内存 → ReduceSum → 写入内存
融合方案:
- 输出到同一块内存
- 硬件自动完成累加操作
优势:
- 避免中间数据的写入和读取
- 减少内存访问次数
- 提升性能
5.3 精度保持优化
老师特别强调了精度问题:
问题:浮点计算存在"大数吃小数"现象
什么意思呢?当一个很大的数和一个很小的数相加时,小数可能会被舍弃。
解决方案:
- 计算过程中将FP16提升到FP32进行累加
- 最后结果再转回FP16
目的:在保证性能的同时满足精度要求
六、"望闻问切"性能分析方法论
6.1 硬件架构基础
唐老师给我们梳理了一遍硬件架构,帮助理解后续的分析方法:
核心组件:AI Core(矩阵计算处理器)
内存层次:
Global Memory (容量大,速度慢)
↓
L2 Cache
↓
Local Memory (L1 Buffer)
↓
L0 Buffer (L0A/L0B/L0C)
↓
Cube计算单元
数据流:GM → L1 → L0A/L0B → Cube → L0C → GM
6.2 MatMul计算阶段分解
老师把MatMul的执行过程分解为四个阶段:
- CopyIn阶段:数据从全局内存搬到局部内存
- Split阶段:数据分块从L1搬到L0
- Cube阶段:核心矩阵乘计算
- CopyOut阶段:结果搬回全局内存
理解这四个阶段,对分析性能瓶颈非常重要!
6.3 性能分析工具
工具1:Profiling工具
功能:提供硬件"体检报告"
关键指标:
- Pipe利用率
- 缓存命中率
- 各计算单元利用率
作用:量化呈现性能瓶颈
工具2:指令流水图
功能:内窥镜式细粒度分析
展示内容:
- 指令下发时间
- 指令执行时间
- 指令完成时间
- 时序关系
优势:快速定位实现代码问题
6.4 "望闻问切"四步法
老师借用中医的"望闻问切"来比喻性能分析过程,我觉得非常形象:
第一步:望(数据采集)
- 通过Profiling工具收集全面性能数据
- 获取详细的性能数据细节
第二步:闻问(数据分析)
- 分析数据,定位关键问题
- 判断是Cube计算慢还是数据搬运慢
第三步:切(深入诊断)
- 查看指令流水情况
- 找到具体的堵塞点或卡点
第四步:优化实施
- 根据诊断结果制定优化方案
- 实现优化代码或调整调度策略
6.5 实战案例分析
老师分享了一个真实的优化案例:
问题现象:
- Profiling数据显示Scaler单元负载过高
- 指令流水图中Wax指令发射存在巨大空隙
根本原因:
- 边缘场景中Scaler单元获得过多任务
- 存在大量基础配置操作
优化方案:
方案1:外提Scaler计算
- 将公共部分的计算外提
- 减少重复配置次数
方案2:Scaler前提
- 与核间同步过程结合
- 错峰执行,避免拥堵
优化效果:
- 特定场景性能提升10%
- 指令流水更加紧凑
虽然10%看起来不多,但在大规模模型中,这个优化可以节省大量时间!
七、互动问答精华
问题1:算子编程使用什么语言?
回答:
- 主要使用类似C++的语言(SNC)
- 有C++基础可以快速上手
- 也提供类似Python的语言
问题2:MatMul和Master乘法有什么区别?
回答:
- MatMul:矩阵块乘法,计算量更大
- Master:向量处理,偏重加法乘法
- 根据具体场景选择使用
问题3:如何判断优化的方向?
回答:
- 核心是寻找当前的瓶颈点
- 当某个组件不再是关键影响因子时,转移优化重点
- 通过"望闻问切"方法迭代优化
这个回答让我想起了木桶理论——总是要优化最短的那块板!
问题4:大矩阵如何处理缓存不足的问题?
回答:
- 通过切块策略利用多级缓存
- L1缓存作为中间缓冲
- L2缓存提供数据复用
问题5:K轴切分适用于什么场景?
回答:
- K维度较大时考虑K轴分块
- 当搬入同步搬运比较高时适用
- 需要权衡搬出开销增加的问题
八、我的学习感悟
8.1 性能优化是系统工程
这次学习让我深刻认识到,性能优化不是某一个技巧就能解决的,而是需要:
- 理解硬件架构
- 分析计算特征
- 选择合适的优化方法
- 迭代验证效果
8.2 数据驱动而非猜测
老师特别强调"望闻问切"方法论,核心思想就是:
- 基于Profiling数据而非猜测
- 用工具定位问题而非凭感觉
- 量化评估效果而非自我感觉
8.3 优化需要权衡
没有银弹!每种优化方案都有适用场景:
- 细粒度分块 vs 粗粒度分块
- 向量化实现 vs 矩阵化实现
- 精度 vs 性能
需要根据实际情况做出权衡。
8.4 开源共建的重要性
老师在最后强调了开源社区共建的重要性,邀请开发者一起参与算子优化。
我觉得这非常有意义:
- 集众人之智慧
- 覆盖更多场景
- 共同推进AI生态发展
九、后续学习计划
听完这次分享,我制定了自己的学习计划:
第一阶段:基础实践
- 自己实现一个简单的MatMul算子
- 使用Profiling工具分析性能
- 尝试应用双缓冲优化
第二阶段:进阶优化
- 学习负载均衡的分块算法
- 实践L2缓存优化技巧
- 尝试算子融合
第三阶段:社区贡献
- 参与OPS-NN仓的开源项目
- 优化现有算子
- 贡献新的算子实现
十、总结
这次CANN算子开源周Meetup的NN算子专场让我受益匪浅。从OPS-NN算子仓的整体架构,到MatMul算子的深度优化,再到"望闻问切"的性能分析方法论,每一部分都让我对昇腾NPU的算子开发有了更深的理解。
核心要点回顾:
- OPS-NN提供完整的神经网络算子覆盖
- MatMul是神经网络的"心脏",优化它至关重要
- 性能优化的四大关键:计算强度、负载均衡、内存访问、流水线调度
- 算子融合可以实现1+1>2的效果
- "望闻问切"方法论:数据驱动、系统分析、迭代优化
对于想要学习昇腾算子开发的同学,我的建议是:
- 深入理解硬件架构
- 从简单算子开始实践
- 学习使用性能分析工具
- 参与开源社区贡献

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 40
40 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)