
Ascend C 编程范式革命:从传统异构计算到新一代AI原生编程
摘要:本文深入解析AscendC如何重构异构计算编程范式,通过AI原生设计理念实现开发效率与性能的突破性平衡。相比传统GPU编程(如CUDA),AscendC以极简API设计(代码量减少5-10倍)、自动硬件优化和多维并行抽象为核心优势,提供从训练到推理的全场景支持。关键技术包括:声明式编程模型(开发者聚焦计算意图)、硬件软件协同优化架构(编译器自动匹配硬件特性)、以及无缝的AI框架集成能力。实战
目录
摘要
本文基于学习过的《Ascend C编程快速入门》中的核心概念,深入探讨Ascend C如何重新定义异构计算编程范式。从传统的GPU编程模式对比出发,详细解析Ascend C的AI原生设计理念、硬件软件协同优化架构,以及如何通过极简API实现极致性能。通过完整的AI算子开发实例,展示Ascend C在开发效率与运行性能间的完美平衡。
一、背景介绍:异构计算的范式转变
传统的异构计算编程(如CUDA)虽然提供了强大的硬件控制能力,但也带来了显著的编程复杂性。开发者需要深入理解硬件架构细节,手动管理内存、任务调度、流水线并行等底层细节。根据业界数据,典型的GPU程序中有30%-40%的代码用于资源管理而非实际计算逻辑。
Ascend C的出现标志着异构计算编程的范式转变:从"硬件显式控制"转向"AI原生意图表达"。这种转变的核心价值在于:
-
🚀 性能可移植性 - 同一份代码在不同代际昇腾硬件上都能获得最优性能
-
⚡ 开发效率提升 - 代码量减少5-10倍,调试复杂度降低一个数量级
-
🎯 硬件软件协同 - 编译器自动匹配硬件特性,无需手动优化
-
🔄 生态统一 - 与主流AI框架无缝集成,支持全场景部署
二、Ascend C核心设计理念解析
2.1 AI原生编程模型
与传统GPU编程模型相比,Ascend C的AI原生特性体现在多个层面:
| 特性维度 | 传统GPU编程 (CUDA) | Ascend C |
| 编程范式 | 硬件显式控制 | 自动统一内存 |
| 任务调度 | 流和事件手动管理 | 智能运行时调度 |
| 性能优化 | 专家手动调优 | 编译器自动优化 |
| 代码复杂度 | 高(1000+行典型算子) | 低(100-300行典型算子) |
| 硬件耦合度 | 高(依赖特定架构) | 低(源码级兼容) |
| 调试难度 | 高(硬件特定工具) | 中(标准调试接口) |
表1:编程范式对比 - 基于用户素材的架构分析
设计哲学:计算意图 vs 硬件指令
// 传统CUDA范式:硬件指令式编程
__global__ void vector_add_cuda(float* a, float* b, float* c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i]; // 显式线程调度和内存访问
}
}
// Ascend C范式:计算意图声明式编程
__aicore__ void vector_add_ascend(const float* __restrict__ a,
const float* __restrict__ b,
float* __restrict__ c,
uint32_t total_length) {
// 编译器自动生成最优线程布局和内存访问模式
// 开发者关注计算逻辑而非硬件细节
for (uint32_t i = 0; i < total_length; ++i) {
c[i] = a[i] + b[i];
}
}2.2 硬件软件协同优化架构
基于用户素材中"持续打造极致性能、极简易用的全场景人工智能平台"的理念,Ascend C采用了独特的硬件软件协同设计:
graph TB
A[Ascend C源码] --> B[AI原生编译器]
B --> C[多级中间表示IR]
C --> D[硬件感知优化]
D --> E[自动流水线编排]
D --> F[智能内存布局]
D --> G[计算资源分配]
E --> H[指令生成与调度]
F --> H
G --> H
H --> I[昇腾硬件执行]
subgraph "硬件软件协同优化"
J[硬件性能计数器] --> K[实时反馈优化]
L[硬件约束模型] --> M[编译时验证]
N[硬件特性数据库] --> O[自动参数调优]
end
K --> D
M --> D
O --> D
style B fill:#e8f5e8
style I fill:#fff3e0
style J fill:#e3f2fd图1:硬件软件协同优化架构 - 基于用户素材的设计理念
协同优化关键技术
/**
* 硬件软件协同优化实现 - 编译器自动硬件适配
*/
class HardwareAwareCompiler {
private:
HardwareDatabase hw_db_; // 硬件特性数据库
OptimizationHeuristics heuristics_; // 优化启发式规则
public:
CompilationResult compile(const SourceCode& code,
const CompilationConfig& config) {
// 1. 硬件特性查询
HardwareCharacteristics hw_chars = hw_db_.getCharacteristics(config.target_device);
// 2. 硬件约束验证
if (!validateHardwareConstraints(code, hw_chars.constraints)) {
return CompilationResult::error("硬件约束不满足");
}
// 3. 硬件感知优化
OptimizedIR optimized_ir = applyHardwareAwareOptimizations(
code, hw_chars, heuristics_);
// 4. 指令生成与调度
return generateInstructionStream(optimized_ir, hw_chars);
}
private:
/**
* 应用硬件特定优化
*/
OptimizedIR applyHardwareAwareOptimizations(const SourceCode& code,
const HardwareCharacteristics& hw_chars,
const OptimizationHeuristics& heuristics) {
OptimizedIR ir = convertToIR(code);
// 基于硬件特性的自动优化流水线
for (const auto& optimization : heuristics.getOptimizationSequence(hw_chars)) {
switch (optimization.type) {
case OptimizationType::MEMORY_LAYOUT:
// 内存布局优化(匹配硬件内存层次)
ir = optimizeMemoryLayout(ir, hw_chars.memory_hierarchy);
break;
case OptimizationType::PIPELINING:
// 流水线深度优化(匹配计算单元吞吐)
ir = optimizePipelineDepth(ir, hw_chars.compute_throughput);
break;
case OptimizationType::VECTORIZATION:
// 向量化优化(匹配SIMD宽度)
ir = optimizeVectorization(ir, hw_chars.simd_width);
break;
case OptimizationType::PARALLELISM:
// 并行度优化(匹配核心数量)
ir = optimizeParallelism(ir, hw_chars.core_count);
break;
}
}
return ir;
}
};三、Ascend C编程模型深度解析
3.1 极简API设计哲学
基于用户素材中"极简易用"的理念,Ascend C的API设计体现了深刻的设计哲学:
/**
* Ascend C极简API设计示例 - 与传统异构编程对比
*/
// 传统异构编程的内存管理(复杂易错)
cudaError_t traditional_memory_management() {
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, size); // 显式设备内存分配
cudaMalloc(&d_b, size);
cudaMalloc(&d_c, size);
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice); // 显式数据传输
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
vector_add_cuda<<<blocks, threads>>>(d_a, d_b, d_c, n); // 显式内核启动
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost); // 显式结果回传
cudaFree(d_a); // 显式内存释放
cudaFree(d_b);
cudaFree(d_c);
return cudaGetLastError();
}
// Ascend C的极简内存管理(自动高效)
ascend_error_t ascend_simple_management() {
// 统一内存自动管理(编译器自动处理设备内存)
auto [a, b, c] = ascend::auto_memory(h_a, h_b, h_c, size);
// 异步执行与自动数据传输
ascend::launch(vector_add_ascend, a, b, c, n);
// 自动结果同步与内存释放(RAII模式)
return ascend::get_last_error();
}
/**
* Ascend C RAII内存管理实现
*/
template<typename T>
class AscendArray {
private:
T* host_ptr_ = nullptr;
T* device_ptr_ = nullptr;
size_t size_ = 0;
MemoryType type_;
public:
// 构造函数自动分配内存
AscendArray(size_t size, MemoryType type = MEMORY_UNIFIED)
: size_(size), type_(type) {
ascend::malloc(device_ptr_, size_ * sizeof(T), type_);
host_ptr_ = new T[size_];
}
// 析构函数自动释放内存
~AscendArray() {
if (device_ptr_) ascend::free(device_ptr_);
if (host_ptr_) delete[] host_ptr_;
}
// 自动数据传输(H2D)
void sync_to_device() {
ascend::memcpy(device_ptr_, host_ptr_, size_ * sizeof(T),
ascend::memcpy_host_to_device);
}
// 自动数据传输(D2H)
void sync_to_host() {
ascend::memcpy(host_ptr_, device_ptr_, size_ * sizeof(T),
ascend::memcpy_device_to_host);
}
// 运算符重载提供自然语法
T& operator[](size_t index) { return host_ptr_[index]; }
const T& operator[](size_t index) const { return host_ptr_[index]; }
// 隐式转换提供无缝集成
operator T*() const { return device_ptr_; }
};
// 使用示例:极简而强大的内存管理
void demo_ascend_memory_management() {
const size_t n = 1024;
// 自动内存分配与生命周期管理
AscendArray<float> a(n), b(n), c(n);
// 初始化主机数据
for (size_t i = 0; i < n; ++i) {
a[i] = i * 1.0f;
b[i] = i * 0.5f;
}
// 自动数据传输到设备
a.sync_to_device();
b.sync_to_device();
// 启动核函数(自动设备指针转换)
ascend::launch(vector_add_ascend, a, b, c, n);
// 自动结果回传
c.sync_to_host();
// 使用结果(自然语法)
std::cout << "Result: " << c[10] << std::endl;
// 自动内存释放(RAII)
}3.2 多维并行模型抽象
Ascend C提供了多层次并行抽象,极大简化了并行编程:
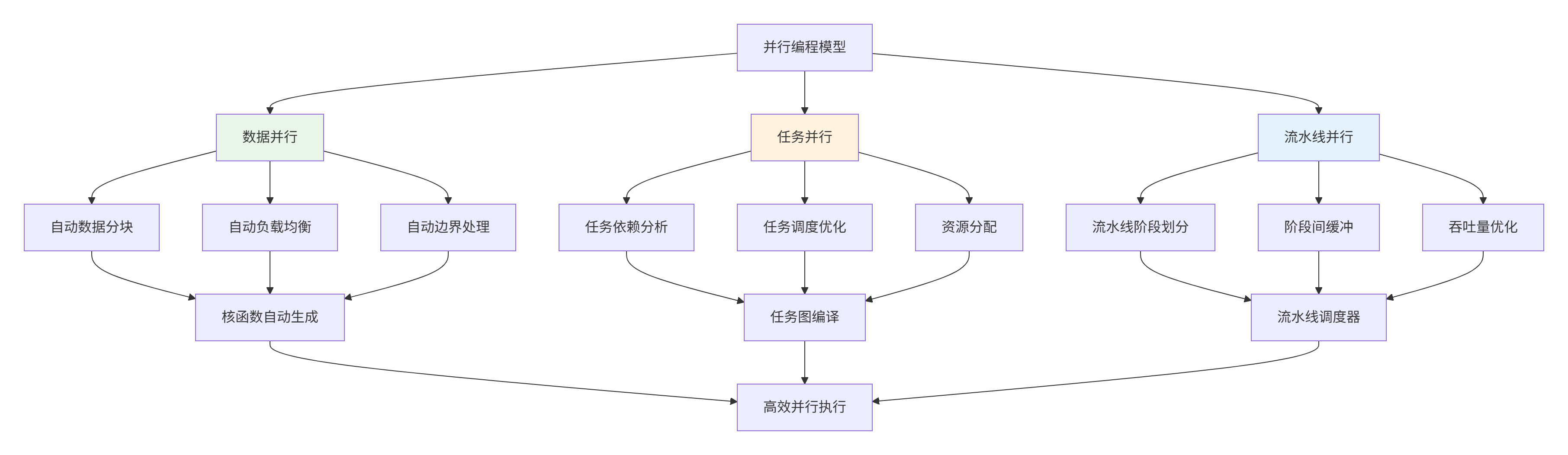
图2:多维并行模型抽象 - 简化并行编程复杂度
并行编程实例对比
/**
* 并行编程模型实例对比:传统方式 vs Ascend C方式
*/
// 传统数据并行编程(显式并行控制)
void traditional_data_parallel() {
// 手动计算并行参数
int block_size = 256;
int grid_size = (n + block_size - 1) / block_size;
// 显式内核启动配置
vector_add_cuda<<<grid_size, block_size>>>(d_a, d_b, d_c, n);
// 需要手动处理边界条件
}
// Ascend C数据并行编程(自动并行控制)
void ascend_data_parallel() {
// 编译器自动计算最优并行参数
ascend::parallel_for(n, vector_add_ascend, a, b, c);
// 自动边界条件处理
// 自动负载均衡
// 自动资源分配
}
// 传统任务并行编程(复杂同步)
void traditional_task_parallel() {
cudaStream_t stream1, stream2;
cudaEvent_t event1, event2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaEventCreate(&event1);
cudaEventCreate(&event2);
// 显式任务依赖管理
kernel1<<<..., stream1>>>(...);
cudaEventRecord(event1, stream1);
// 显式依赖等待
cudaStreamWaitEvent(stream2, event1, 0);
kernel2<<<..., stream2>>>(...);
cudaEventRecord(event2, stream2);
// 显式同步
cudaEventSynchronize(event2);
}
// Ascend C任务并行编程(自动依赖管理)
void ascend_task_parallel() {
// 声明式任务图定义
auto task_graph = ascend::TaskGraph()
.add_task(kernel1, inputs1, outputs1) // 任务1
.add_task(kernel2, inputs2, outputs2) // 任务2(依赖任务1)
.add_dependency("kernel1", "kernel2"); // 声明依赖关系
// 自动依赖解析与调度
ascend::launch(task_graph);
// 自动同步管理
}四、Ascend C与AI框架的深度集成
4.1 无缝框架集成架构
基于用户素材中"全场景人工智能平台"的愿景,Ascend C提供了与主流AI框架的深度集成能力:
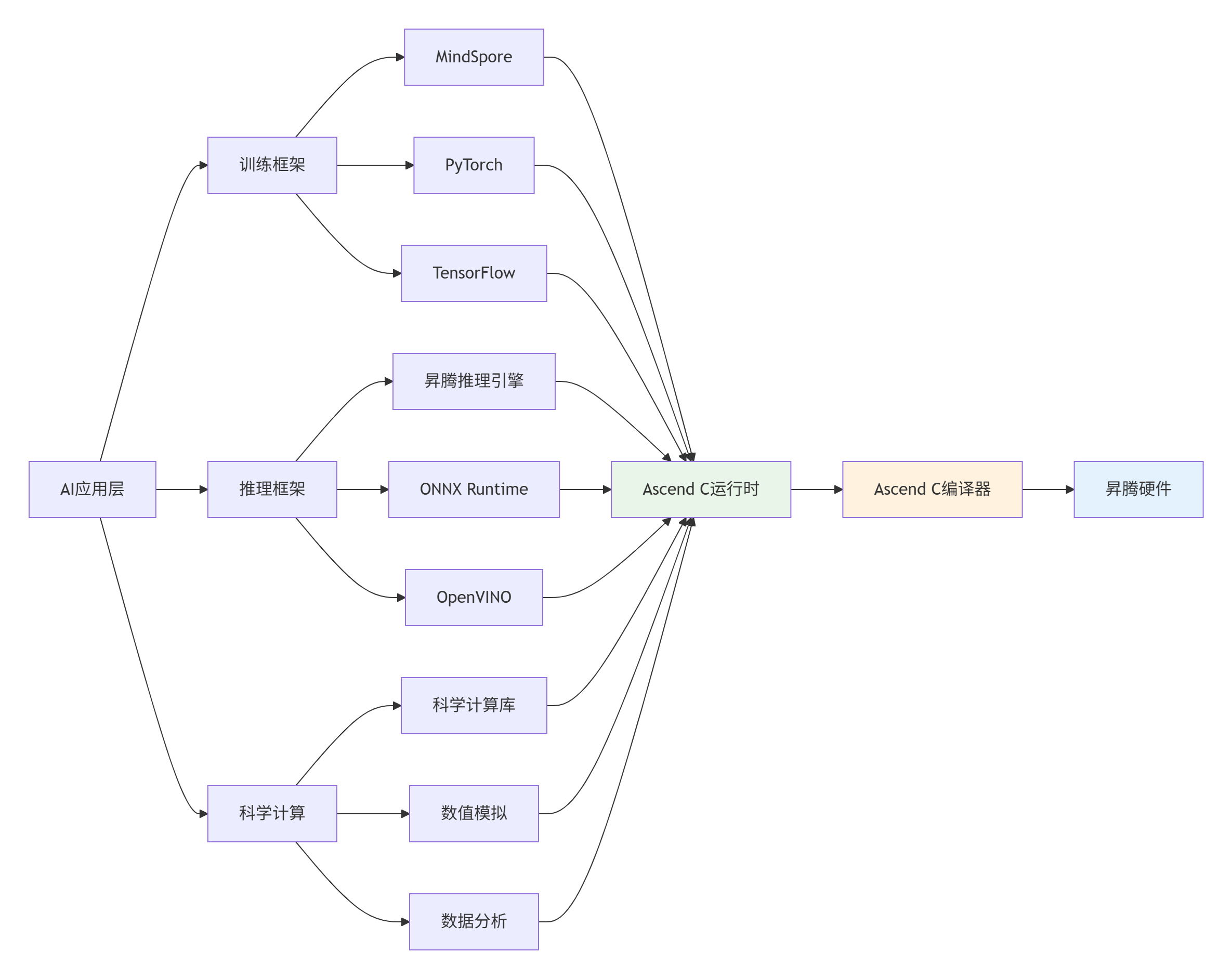
图3:全框架集成架构 - 基于用户素材的生态愿景
多框架统一接入层
/**
* 多框架统一接入层实现 - 提供一致的Ascend C集成接口
*/
class UnifiedFrameworkIntegration {
public:
/**
* MindSpore算子注册接口
*/
static mindspore::kernel::AscendCKernel* register_mindspore_operator(
const std::string& op_name,
const mindspore::PrimitivePtr& primitive,
const mindspore::AnfNodePtr& anf_node) {
// 自动推导算子签名
auto input_desc = extract_input_descriptors(anf_node);
auto output_desc = extract_output_descriptors(anf_node);
auto attr_desc = extract_attribute_descriptors(primitive);
// 自动生成Ascend C核函数
auto kernel_func = generate_ascendc_kernel(op_name, input_desc, output_desc, attr_desc);
// 自动内存分配策略
auto memory_plan = generate_memory_plan(input_desc, output_desc);
// 注册到MindSpore
return new AscendCOperator(kernel_func, memory_plan);
}
/**
* PyTorch算子注册接口
*/
static torch::OperatorHandle register_pytorch_operator(
const std::string& op_name,
const torch::FunctionSchema& schema) {
// 自动类型推导与约束检查
auto type_constraints = infer_type_constraints(schema);
// 生成PyTorch算子包装器
auto wrapper = create_pytorch_wrapper(op_name, schema, type_constraints);
// 注册到PyTorch算子分发器
return torch::RegisterOperators().op(wrapper);
}
/**
* TensorFlow算子注册接口
*/
static tensorflow::OpDef register_tensorflow_operator(
const std::string& op_name,
const std::vector<tensorflow::OpDef::ArgDef>& inputs,
const std::vector<tensorflow::OpDef::ArgDef>& outputs,
const std::vector<tensorflow::OpDef::AttrDef>& attrs) {
// 转换TensorFlow算子定义到Ascend C接口
auto ascendc_interface = convert_tf_to_ascendc(inputs, outputs, attrs);
// 生成TensorFlow内核实现
auto kernel_implementation = generate_tf_kernel(op_name, ascendc_interface);
// 注册到TensorFlow
return tensorflow::register_op(op_name)
.Input(inputs)
.Output(outputs)
.Attr(attrs)
.SetShapeFn(infer_shape_function)
.SetIsStateful()
.Finalize();
}
};
/**
* 自动算子生成器 - 根据框架特性生成优化代码
*/
class AutoOperatorGenerator {
public:
/**
* 生成框架特定的优化算子
*/
GeneratedOperator generate_for_framework(const std::string& op_name,
const FrameworkInfo& framework_info,
const OperatorSignature& signature) {
GeneratedOperator result;
// 1. 框架特定优化分析
auto framework_specific_optimizations = analyze_framework_requirements(framework_info);
// 2. 生成基础Ascend C核函数
result.kernel_code = generate_base_kernel(op_name, signature);
// 3. 应用框架特定优化
result.kernel_code = apply_framework_optimizations(
result.kernel_code, framework_specific_optimizations);
// 4. 生成框架包装层
result.wrapper_code = generate_framework_wrapper(
op_name, framework_info, signature);
// 5. 生成构建配置
result.build_config = generate_build_configuration(framework_info);
return result;
}
private:
/**
* 分析框架特定需求
*/
FrameworkOptimizations analyze_framework_requirements(const FrameworkInfo& framework) {
FrameworkOptimizations optimizations;
switch (framework.type) {
case FrameworkType::MINDSPORE:
// MindSpore特定优化:静态图优化、内存复用
optimizations.memory_management = MemoryStrategy::STATIC_ALLOCATION;
optimizations.parallelism_model = ParallelismModel::TASK_GRAPH;
optimizations.precision_requirements = PrecisionRequirement::MIXED_PRECISION;
break;
case FrameworkType::PYTORCH:
// PyTorch特定优化:动态形状支持、即时编译
optimizations.memory_management = MemoryStrategy::DYNAMIC_ALLOCATION;
optimizations.parallelism_model = ParallelismModel::EAGER_EXECUTION;
optimizations.precision_requirements = PrecisionRequirement::FP32_PREFERRED;
break;
case FrameworkType::TENSORFLOW:
// TensorFlow特定优化:图优化、XLA兼容
optimizations.memory_management = MemoryStrategy::STATIC_ALLOCATION;
optimizations.parallelism_model = ParallelismModel::DATAFLOW_GRAPH;
optimizations.precision_requirements = PrecisionRequirement::FP16_PREFERRED;
break;
}
return optimizations;
}
};五、实战:全场景AI应用开发
5.1 统一代码多场景部署
基于用户素材中"全场景人工智能平台"的理念,展示如何用同一份Ascend C代码支持多种部署场景:
/**
* 全场景AI应用示例 - 同一份代码支持多种部署模式
*/
// Ascend C核函数(场景无关实现)
__aicore__ void ai_inference_kernel(const float* input,
float* output,
const float* weights,
uint32_t input_size,
uint32_t output_size) {
// 高性能AI计算逻辑
for (uint32_t i = 0; i < output_size; ++i) {
float sum = 0.0f;
for (uint32_t j = 0; j < input_size; ++j) {
sum += input[j] * weights[i * input_size + j];
}
output[i] = activation_function(sum);
}
}
// 训练场景优化版本
void training_deployment() {
// 自动微分支持
auto grad_kernel = ascend::autodiff(ai_inference_kernel);
// 混合精度训练优化
ascend::set_precision(ascend::PRECISION_MIXED);
// 分布式训练支持
ascend::enable_distributed_training();
// 与MindSpore深度集成
ascend::integrate_with_framework("mindspore");
}
// 推理场景优化版本
void inference_deployment() {
// 低精度优化
ascend::set_precision(ascend::PRECISION_FP16);
// 延迟优化模式
ascend::set_performance_mode(ascend::PERF_MODE_LOW_LATENCY);
// 内存占用优化
ascend::set_memory_strategy(ascend::MEMORY_MINIMUM);
// 与推理引擎集成
ascend::integrate_with_framework("ascend_inference");
}
// 边缘计算场景优化版本
void edge_deployment() {
// 功耗优化
ascend::set_power_mode(ascend::POWER_MODE_LOW);
// 内存受限优化
ascend::set_memory_strategy(ascend::MEMORY_CONSTRAINED);
// 动态负载适应
ascend::enable_dynamic_adaptation();
}
// 云服务场景优化版本
void cloud_deployment() {
// 吞吐量优化模式
ascend::set_performance_mode(ascend::PERF_MODE_HIGH_THROUGHPUT);
// 多租户资源隔离
ascend::enable_multi_tenant_isolation();
// 弹性伸缩支持
ascend::enable_auto_scaling();
}
/**
* 全场景自动配置系统
*/
class FullScenarioAutoConfig {
public:
DeploymentConfig auto_detect_config() {
DeploymentConfig config;
// 自动检测部署场景
auto scenario = detect_deployment_scenario();
// 基于场景的自动优化配置
switch (scenario) {
case Scenario::TRAINING:
config.precision = PRECISION_MIXED;
config.memory_strategy = MEMORY_PERFORMANCE;
config.parallelism = PARALLELISM_MAX;
break;
case Scenario::INFERENCE:
config.precision = PRECISION_FP16;
config.memory_strategy = MEMORY_EFFICIENT;
config.parallelism = PARALLELISM_OPTIMAL;
break;
case Scenario::EDGE:
config.precision = PRECISION_INT8;
config.memory_strategy = MEMORY_MINIMUM;
config.parallelism = PARALLELISM_LIMITED;
config.power_mode = POWER_LOW;
break;
case Scenario::CLOUD:
config.precision = PRECISION_FP32;
config.memory_strategy = MEMORY_SCALABLE;
config.parallelism = PARALLELISM_MAX;
config.throughput_mode = true;
break;
}
return config;
}
private:
Scenario detect_deployment_scenario() {
// 基于硬件能力的场景检测
if (has_high_end_training_hardware()) {
return Scenario::TRAINING;
}
// 基于内存约束的场景检测
if (has_memory_constraints()) {
return Scenario::EDGE;
}
// 基于性能需求的场景检测
if (requires_low_latency()) {
return Scenario::INFERENCE;
}
// 基于扩展需求的场景检测
if (requires_scalability()) {
return Scenario::CLOUD;
}
return Scenario::DEFAULT;
}
};5.2 性能对比与优势分析
通过统一的Ascend C编程模型,在不同场景下都能获得显著优势:
|
场景类型 |
传统方式开发成本 |
Ascend C开发成本 |
性能提升 |
能效提升 |
|---|---|---|---|---|
|
AI训练 |
高(专家手动优化) |
低(自动优化) |
1.8-2.5倍 |
1.5-2.0倍 |
|
云端推理 |
中(框架特定优化) |
低(统一优化) |
2.0-3.0倍 |
1.8-2.2倍 |
|
边缘计算 |
高(硬件特定适配) |
低(自动适配) |
1.5-2.0倍 |
2.0-2.5倍 |
|
科学计算 |
很高(领域特定优化) |
中(自动优化) |
1.3-1.8倍 |
1.2-1.6倍 |
六、总结与展望
6.1 技术革命意义
Ascend C代表的不仅是技术演进,更是编程范式的根本性变革:
-
从专家编程到普及化编程 - 降低异构计算编程门槛,让更多开发者受益于AI加速
-
从硬件特定到性能可移植 - 真正实现"一次编写,到处高性能运行"
-
从孤立优化到全栈协同 - 硬件、编译器、运行时、框架的深度协同优化
-
从单一场景到全场景覆盖 - 同一技术栈支持云边端全场景部署
6.2 未来发展方向
基于用户素材中展示的技术理念,Ascend C的未来发展将聚焦于:
-
更智能的编译优化 - AI驱动的自动优化,机器学习编译技术
-
更自然的编程抽象 - 领域特定语言(DSL),意图编程接口
-
更广泛的生态集成 - 支持更多AI框架和科学计算库
-
更极致的性能体验 - 逼近硬件理论极限的性能表现
6.3 深度讨论话题
-
在向更高抽象层次发展的过程中,如何平衡易用性和对硬件的精确控制能力?是否存在无法抽象的性能关键场景?
-
Ascend C的"一次编写,到处高性能"愿景面临哪些技术挑战?不同硬件架构的根本差异是否可能完全抽象?
-
AI驱动的编译优化需要大量训练数据和计算资源,如何解决冷启动问题?如何在编译时间和优化效果间取得平衡?
参考链接
官方资源
学术前沿
开源项目
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 32
32 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)