
昇思25天学习打卡营第2天 | 数据变换、网络构建
首先我们构造一个shape为(3, 28, 28)的随机数据(3个28x28的图像),依次通过每一个神经网络层来观察其效果。当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。construct意为神经网络(计算图)构建,用于定义要执行的计算逻辑,所有子类都必须重写此方法。方法不可直接调用。相关内
以下为官方活动的学习笔记兼打卡记录,大部分内容来自活动资料,稍有删改,内含跳转至MindSpore文档的超链接,可作为字典查询。
一、数据变换 Transforms(与第一天打卡的文章关系紧密)
在MindSpore的数据处理Pipeline中,数据变换(Transforms)可以对不同种类的数据进行预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。下面分别对其进行介绍。
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
1、Vision Transforms
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。以下以Rescale、Normalize和HWC2CHW变换为例,进行简单介绍。
Rescale
该变换用于调整图像像素值的大小,即对张量元素进行缩放,包括两个参数:
rescale:缩放因子。shift:平移因子。
图像的每个像素将根据这两个参数进行调整,输出的像素值为 o u t p u t i = i n p u t i ∗ r e s c a l e + s h i f t output_{i} = input_{i} * rescale + shift outputi=inputi∗rescale+shift。
Normalize
Normalize变换用于对输入图像的归一化,包括三个参数:
- mean:图像每个通道的均值,为一个列表或元组。
- std:图像每个通道的标准差,为一个列表或元组。
- is_hwc:bool值,输入图像的格式。True为(height, width, channel),False为(channel, height, width)。
图像的每个通道将根据mean和std进行调整,计算公式为 o u t p u t c = i n p u t c − m e a n c s t d c output_{c} = \frac{input_{c} - mean_{c}}{std_{c}} outputc=stdcinputc−meanc,其中 c c c代表通道索引。
HWC2CHW
HWC2CHW变换用于转换图像格式。MindSpore设置HWC为默认图像格式,在有CHW格式需求时,可使用该变换进行处理。
Vision Transforms详见mindspore.dataset.vision。
2、Text Transforms
mindspore.dataset.text模块提供一系列针对文本数据的Transforms。文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。这里简单介绍其使用方法。
首先我们定义三段文本,作为待处理的数据,并使用GeneratorDataset进行加载。
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')
PythonTokenizer
分词(Tokenize)操作是文本数据的基础处理方法,MindSpore提供多种不同的Tokenizer。这里我们选择基础的PythonTokenizer举例,此Tokenizer允许用户使用自定义的分词器,对输入字符串进行分词。随后我们利用map操作将此分词器应用到输入的文本中,对其进行分词。
def my_tokenizer(content):
return content.split()
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))
> [Tensor(shape=[3], dtype=String, value= [‘Welcome’, ‘to’, ‘Beijing’])]
以上代码中,PythonTokenizer需要传入一个可调用对象(该对象要求接收一个string参数作为输入,返回一个包含多个string的列表),这里传入我们的自定义分词函数。
map将分词这一操作应用于test_dataset,并返回包含变换后元素的新数据集。随后创建迭代器,输出分词后的数据集。
Lookup
Lookup为词表映射变换,用来将Token转换为Index。在使用Lookup前,需要构造词表,一般可以加载已有的词表,或使用Vocab生成词表。这里我们选择使用Vocab.from_dataset方法从数据集中生成词表。
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())
> {‘to’: 2, ‘Welcome’: 1, ‘Beijing’: 0}
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))
> [Tensor(shape=[3], dtype=Int32, value= [1, 2, 0])]
更多Text Transforms详见mindspore.dataset.text。
Lambda Transforms
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以通过map将自定义的Lambda函数加载至数据集中,提供足够的灵活度。
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))
> [[Tensor(shape=[], dtype=Int64, value= 2)], [Tensor(shape=[], dtype=Int64, value= 4)], [Tensor(shape=[], dtype=Int64, value= 6)]]
二、网络构建
神经网络模型是由神经网络层和Tensor操作构成的,mindspore.nn提供了常见神经网络层的实现,在MindSpore中,Cell类是构建所有网络的基类,也是网络的基本单元。一个神经网络模型表示为一个Cell,它由不同的子Cell构成。使用这样的嵌套结构,可以简单地使用面向对象编程的思维,对神经网络结构进行构建和管理。
下面我们将构建一个用于Mnist数据集分类的神经网络模型。
import mindspore
from mindspore import nn, ops
1、模型层介绍
首先我们构造一个shape为(3, 28, 28)的随机数据(3个28x28的图像),依次通过每一个神经网络层来观察其效果。
input_image = ops.ones((3, 28, 28), mindspore.float32)
nn.Flatten
实例化nn.Flatten层,将28x28的2D张量转换为784大小的连续数组。
参数:
- start_dim (int, 可选) - 要展平的第一个维度。默认值: 1 。
- end_dim (int, 可选) - 要展平的最后一个维度。默认值: -1 。
flatten = nn.Flatten(start_dim = 1, end_dim = -1)
flat_image = flatten(input_image)
print(flat_image.shape)
> (3, 784)
nn.Dense
nn.Dense为全连接层,其使用权重和偏差对输入进行线性变换。
layer1 = nn.Dense(in_channels=28*28, out_channels=20)
hidden1 = layer1(flat_image)
print(hidden1.shape)
> (3, 20)
nn.ReLU
nn.ReLU层给网络中加入非线性的激活函数,帮助神经网络学习各种复杂的特征。
hidden1 = nn.ReLU()(hidden1)
以上一行代码为函数式API写法
nn.SequentialCell
nn.SequentialCell是一个有序的Cell容器。输入Tensor将按照定义的顺序通过所有Cell。我们可以使用SequentialCell来快速组合构造一个神经网络模型。
seq_modules = nn.SequentialCell(
flatten, # (3, 784)
layer1, # Dense,(3, 20)
nn.ReLU(),
nn.Dense(20, 10)
)
logits = seq_modules(input_image)
print(logits.shape)
> (3, 10)
2、定义模型类
当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。
construct意为神经网络(计算图)构建,用于定义要执行的计算逻辑,所有子类都必须重写此方法。model.construct()方法不可直接调用。相关内容详见使用静态图加速。
以下使用上述提到的模型层构建一个简单的神经网络,获得一个10维的Tensor输出,包含每个类别的原始预测值。
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512, weight_init="normal", bias_init="zeros"),
nn.ReLU(),
nn.Dense(512, 512, weight_init="normal", bias_init="zeros"),
nn.ReLU(),
nn.Dense(512, 10, weight_init="normal", bias_init="zeros")
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
X = ops.ones((1, 28, 28), mindspore.float32)
logits = model(X)
# print logits
logits
> Tensor(shape=[1, 10], dtype=Float32, value=
[[-5.08734025e-04, 3.39190010e-04, 4.62840870e-03 … -1.20305456e-03, -5.05689112e-03, 3.99264274e-03]])
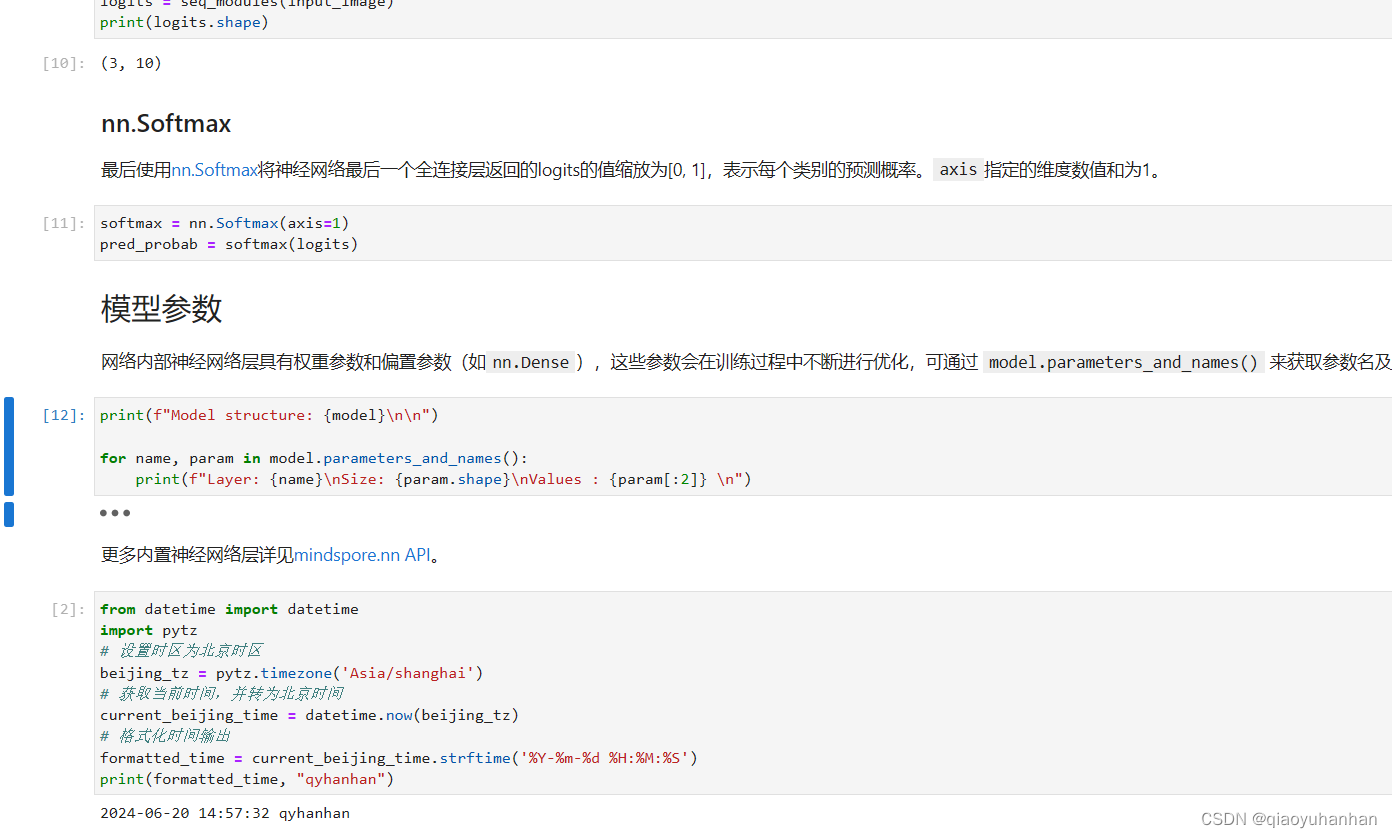
模型参数
网络内部神经网络层具有权重参数和偏置参数(如nn.Dense),这些参数会在训练过程中不断进行优化,可通过 model.parameters_and_names() 来获取参数名及对应的参数详情。
更多内置神经网络层详见mindspore.nn API。
学习记录
1、数据变换Transforms 打卡

2、网络构建 打卡

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 28
28 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)