
指挥家的权杖:掌控Ascend C多核同步与负载均衡的艺术
我在CANN昇腾C语言领域的探索之旅,充满了持续的顿悟。我学会了并行思考,学会了用Tiling排兵布阵,学会了像大师级铁匠一样融合算子。我曾一度以为,自己已经驯服了多核并行这头猛兽。我的策略很简单,也自认为很有效:将问题分解成相等的几份,每一份指派给NPU众多的AI Core中的一个,然后让它们自由驰骋。对许多问题而言,这套方法效果卓著。Profiler性能分析器上,AI Core矩阵整齐划一地启
序章:一场无声战争的嘈杂
我在CANN昇腾C语言领域的探索之旅,充满了持续的顿悟。我学会了并行思考,学会了用Tiling排兵布阵,学会了像大师级铁匠一样融合算子。我曾一度以为,自己已经驯服了多核并行这头猛兽。我的策略很简单,也自认为很有效:将问题分解成相等的几份,每一份指派给NPU众多的AI Core中的一个,然后让它们自由驰骋。对许多问题而言,这套方法效果卓著。Profiler性能分析器上,AI Core矩阵整齐划一地启动,步调一致地结束,宛如一支训练有素的军队。
直到我遇到了ReduceSum算子。
这个任务表面上看起来微不足道:将一个巨大张量的所有元素沿着特定轴向求和。然而,正是这个简单的任务,粉碎了我对控制力的幻想。我最初那个天真的多核实现——每个核心计算自己的分片,然后将部分结果写回全局内存——慢得令人发指。我那个更高级的、使用了片上内存的版本,虽然有所改善,但离理论峰值性能仍有遥远的距离。
Profiler揭示了一种全新的、更为阴险的性能问题。它不再是整体利用率低下的情况,相反,Timeline时间线视图看起来像一场马拉松比赛中参差不齐的终点线。一些AI Core闪电般地完成它们的工作,然后进入漫长的、无所事事的等待。而另一些,那些“掉队者”,则还在数字的泥潭中挣扎许久。整个操作的性能,被最慢的那个核心死死地拖住了后腿。我的“军队”陷入了混乱,卷入了一场无声而低效的战争,在这场战争中,跑得快的,却要为等待跑得慢的而受罚。
我意识到,我一直以来扮演的,并非一名指挥官,而仅仅是一个任务调度员。要解决这个问题,我必须放下调度员的记事板,拿起指挥家的权杖。我需要学习的,不仅是如何让音乐开始,更是如何掌控它的节奏,同步它的乐手,并确保每一个声部都以完美的和谐来演奏。这,就是我如何学会指挥这支多核交响乐团的故事。

第一章:并行的幻觉 —— 一个天真的ReduceSum及其致命缺陷
每一位指挥家的旅程,都始于理解什么事情是不能做的。我第一次尝试并行的ReduceSum,就是一个典型的、完全忽视了通信成本的“易并行”思维的失败案例。
任务: 给定一个大的二维张量Input[M, N],计算一个一维张量Output[M],其中Output[i] = sum(Input[i, :])。我们希望在N这个维度上进行并行求和。
天真的方法:分而治之,然后祈祷。
我最初的逻辑很简单:
- 将
N维度切分成多个块,每个AI Core负责一块。 - 启动一个Kernel。每个AI Core
c计算它被分配到的数据块Input[i, c_start:c_end]的和。 - 每个核心将它的部分和(partial sum)写入一个临时的全局张量
Temp[i, c]。 - 启动第二个Kernel(或者在Host端完成),对
Temp张量求和,得到最终结果。
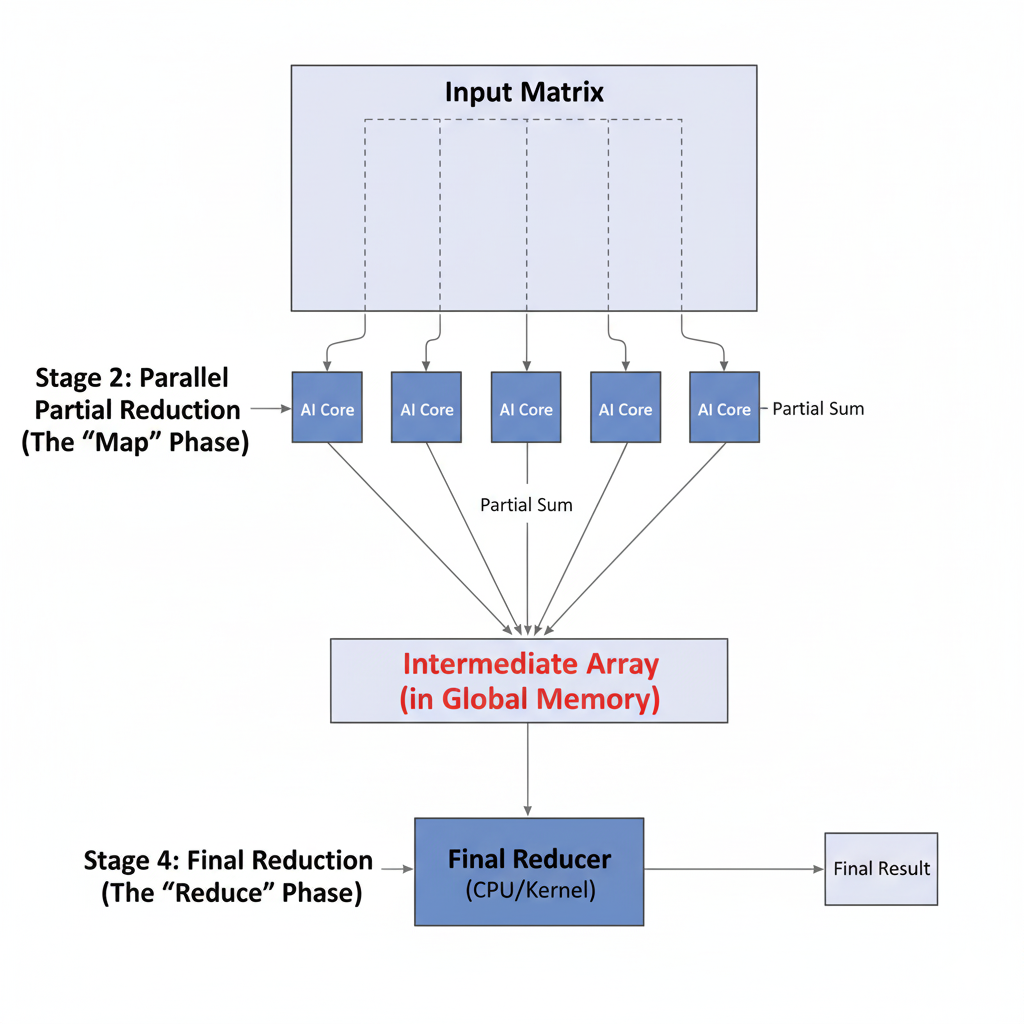
为何它败得如此惨烈:
这种方法从根本上就是有缺陷的,因为它依赖于全局内存作为主要的通信媒介。
- 巨大的内存开销: 它在全局内存中创建了一个庞大的临时张量,其大小与核心数量成正比。这是对内存和带宽的巨大浪费。
- 两遍式算法: 它至少需要两次独立的Kernel启动。第一遍进行部分规约,第二遍进行最终规约。这不仅使Kernel启动开销翻倍,还引入了一个通过全局内存实现的、极其低效的同步点。
- 通信瓶颈: 将所有部分和从DDR中写出,然后再读回的成本,完全主导了实际的计算时间。NPU大部分时间都在等待数据在缓慢的内存总线上传输。我的交响乐团,基本上是在用两个乐章之间的间隙互相写信来沟通。
这次失败的实验教会了我片上并行编程的第一条、也是最重要的一条规则:不惜一切代价,避免使用全局内存进行核间通信。你的交响乐的演出质量,取决于排练室的质量,而不是收发室的大小。
第二章:排练室 —— 使用共享内存和同步实现片上规约
显而易见的解决方案是,将通信搬到芯片上。一个多核Block内的AI Core可以共享访问同一个L1 Cache,它可以作为我们高速的“排练室”或共享内存。
新策略:两阶段片上规约。
- 阶段一:局部规约 (在寄存器/L0中): 每个AI Core仍然处理它被分配到的输入数据切片。但是,它不再将部分和写入全局内存,而是在自己的私有寄存器或L0 Buffer中累加——这是它个人的、超高速的草稿纸。
- 阶段二:共享规约 (在L1中): 当一个核心完成了它的局部规约后,它将自己得到的那个部分和,写入L1 Cache中一个共享数组的指定位置。一旦所有核心都完成了这一步,一个最终的规约操作将在这个小小的共享数组上进行,以得到最终结果。
这个策略引入了一个全新的、至关重要的概念:同步(Synchronization)。我们如何确保一个核心不会在所有其他核心完成阶段一并把结果写入共享数组之前,就开始进行阶段二的规约呢?
指挥家的挥拍:Sync()屏障
Ascend C为此提供了一个原语:Sync()。这是一个屏障同步指令。当一个核心遇到Sync()时,它会暂停执行并等待,直到它所在Block中的每一个其他核心也都到达了同一个Sync()调用。只有当所有核心都抵达屏障时,它们才会被同时释放,继续执行。这就像是指挥家决定性的一挥,确保每一位乐手都在同一时刻开始下一乐章。
片上规约Kernel的代码:
__global__ void reduce_sum_shared_mem(Tensor In, Tensor Out, LocalTensor Temp_L1) {
// Temp_L1 是一个在共享L1内存中分配的LocalTensor
// 其大小等于Block中的核心数量
// 1. 识别自己和自己的数据
uint32_t core_id = GetCoreIdx();
uint32_t core_num = GetCoreNum();
// ... 计算我负责的输入张量切片 ...
// 2. 阶段一:局部规约
float local_sum = 0.0f;
for (int i = my_start; i < my_end; ++i) {
local_sum += In[i];
}
// 3. 将我的部分和写入我们共享的排练室
Temp_L1[core_id] = local_sum;
// 4. 关键的屏障
// 等待所有人完成他们的局部求和并写入Temp_L1。
// 没有这一步,我们将会读到其他核心的垃圾数据。
Sync();
// 5. 阶段二:共享规约
// 我们只让第一个核心 (core_id == 0) 来做最后的求和
if (core_id == 0) {
float final_sum = 0.0f;
for (int i = 0; i < core_num; ++i) {
final_sum += Temp_L1[i];
}
Out[block_id] = final_sum; // 写入最终结果
}
}
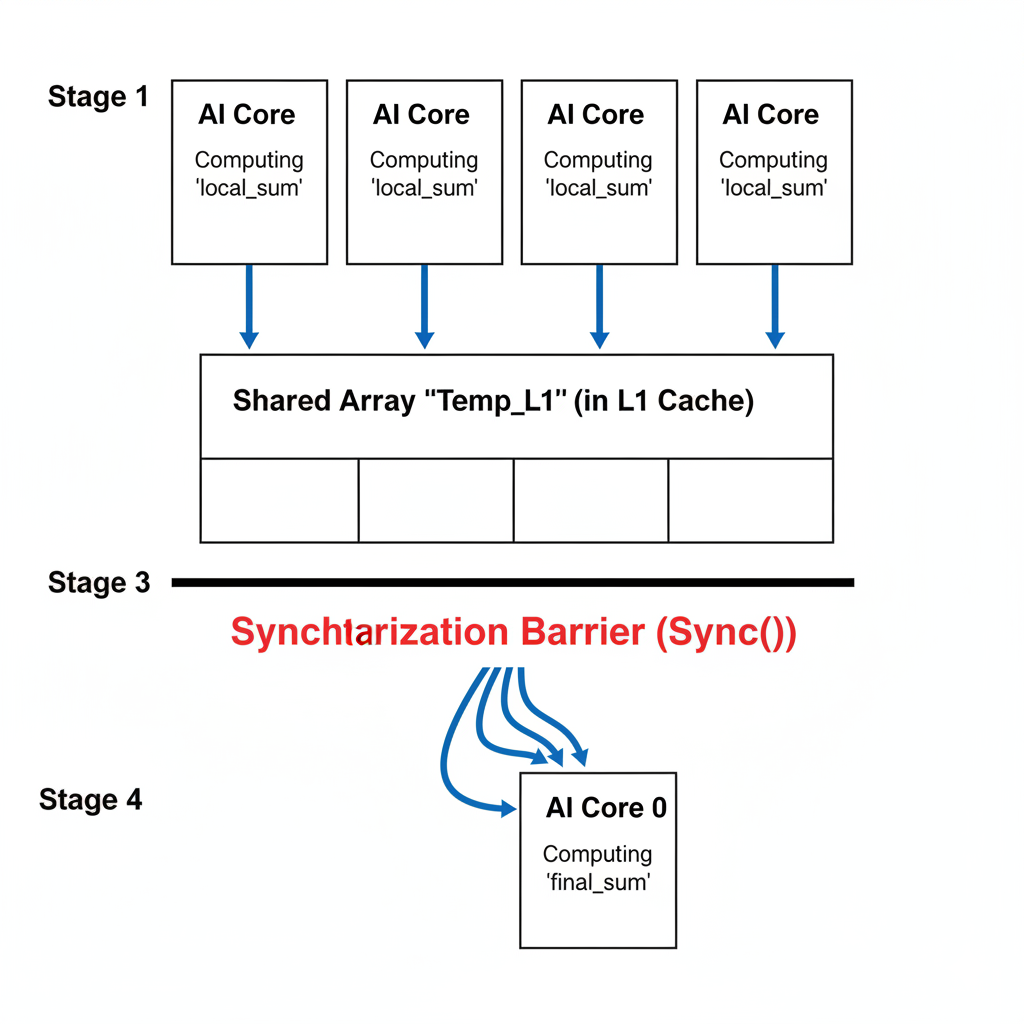
这种方法是一次巨大的飞跃。昂贵的全局内存往返被消除了。然而,一个新的、更微妙的问题开始浮现,而我那个简单的阶段二规约(让core_id == 0包揽所有工作)恰恰掩盖了它。
第三章:失衡的乐团 —— 负载不均的幽灵
我的片上规约在处理“完美”输入时工作得很好——即N维度可以被核心数量整除。但真实世界呢?
考虑一个输入,N = 1000,我们有16个核心。1000 / 16 = 62.5。我们不能把半个元素分给一个核心。一个简单的划分方案可能会给前8个核心分配63个元素,给后8个核心分配62个元素。
- 前8个核心的工作量更大。
- 后8个核心会先完成它们的局部规约。
- 但是,由于
Sync()屏障的存在,这8个跑得快的核心将进入空闲,等待那8个跑得慢的赶上来。
这就是负载不均(Workload Imbalance),而Sync()屏障,虽然对于保证正确性是必需的,却残酷地放大了不均衡所带来的性能惩罚。它就像乐团里的一条规定:在独奏部分结束前,所有已经演奏完自己部分的乐手都不准休息,必须保持演奏姿势,直到独奏者拉完最后一个音符。这不仅浪费了乐手的时间和精力,也拖延了整个乐团的进程。
Profiler的Timeline视图清晰地揭露了这一点:
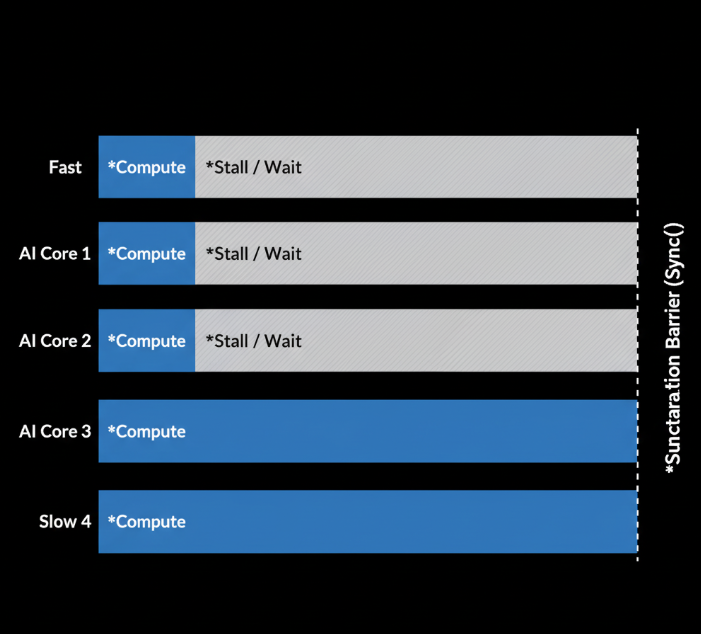
我意识到,仅仅把大家召集到同一个排练室是不够的。一位优秀的指挥家,还必须为不同的声部谱写难度和长度都相称的乐谱。
第四章:指挥家的精妙技法 —— 对抗不均衡的先进武器
如何为我的乐团“谱写”更均衡的乐谱?我研究并实践了两种强大的技术,它们彻底改变了我对并行任务划分的理解。
技法一:层级/树状规约 (Hierarchical/Tree-based Reduction)
我在第二章犯的一个错误是,让core_id == 0串行地完成了最终的规约。这是一个隐藏的串行瓶颈。当核心数量很多时,这个最后的循环也会变得很长。更优的方案是,让最终的规约本身也并行化。
这就是树状规约。它的工作方式像一场淘汰赛:
- 第一轮: 所有核心完成局部规约并
Sync()。然后,核心成对工作:core_1将它的值加到core_0上,core_3加到core_2上,以此类推。 - 第二轮: 再次
Sync()。现在只有一半的核心(0, 2, 4…)持有部分和。它们再次成对工作:core_2将它的值加到core_0上,core_6加到core_4上… - 这个过程重复
log2(核心数量)轮,直到core_0拥有最终的总和。
树状规约代码:
// ... 完成阶段一的局部规约和第一次 Sync() ...
// 阶段二:树状规约
for (int offset = core_num / 2; offset > 0; offset /= 2) {
if (core_id < offset) {
Temp_L1[core_id] += Temp_L1[core_id + offset];
}
Sync(); // 每一轮规约后都需要同步
}
// 最终结果在 Temp_L1[0] 中
if (core_id == 0) {
Out[block_id] = Temp_L1[0];
}

树状规约将最终求和的延迟从O(N)降低到了O(logN)。这是一个巨大的进步。但请注意,它并没有解决最初的负载不均问题,它只是优化了屏障之后的工作。要解决根源问题,我们需要一种更根本的武器。
技法二:循环/交错式任务分配 (Cyclic/Interleaved Work Distribution)
传统的任务分配方式,我们称之为块状分配(Block Distribution)。我们把数据切成连续的大块,分给每个核心。
循环分配则完全不同。它将数据以极小的粒度(通常是1个元素)交错地分发出去:
- Core 0 负责元素 0, 16, 32, 48, …
- Core 1 负责元素 1, 17, 33, 49, …
- …
- Core 15 负责元素 15, 31, 47, 63, …
循环分配的代码:
// 循环分配下的局部规约
float local_sum = 0.0f;
for (int i = core_id; i < N; i += core_num) {
local_sum += In[i];
}
// 后续流程与之前相同
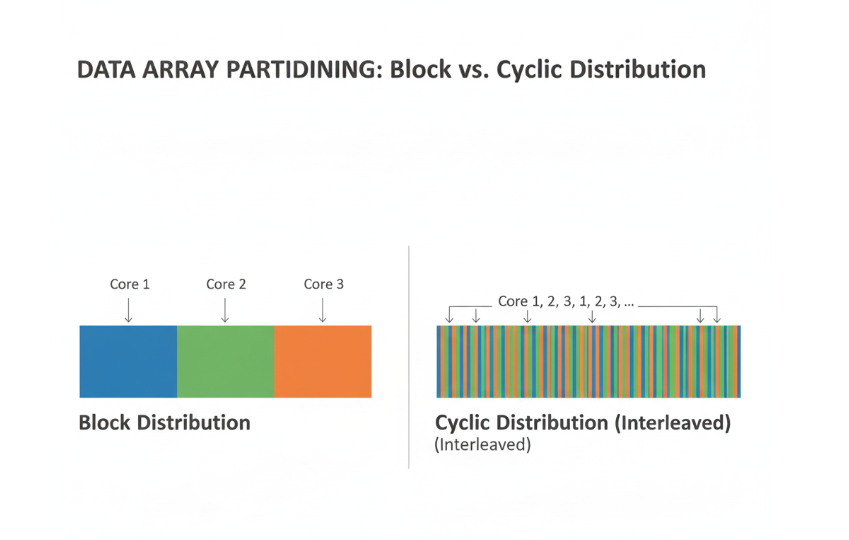
为什么循环分配是如此强大的负载均衡器?
它利用了统计学的力量。真实世界的数据往往不是均匀的。例如,在图像处理中,图像的某些区域(如边缘)可能计算更复杂;在稀疏数据中,非零元素的分布可能极不均匀。
- 块状分配下,一个“倒霉”的核心可能会分到一块“硬骨头”(比如包含了所有非零元素),而其他核心则无所事事。
- 循环分配下,每个核心都从数据的不同部分取样。无论“硬骨头”在哪里,它都会被均匀地分散给所有核心。这使得每个核心最终的实际工作量在统计上趋于一致。
当我将ReduceSum的分配方式从块状改为循环后,奇迹发生了。Profiler的Timeline视图上,那些长短不一的计算条,变得几乎完全等长。所有核心几乎在同一时刻抵达Sync()屏障。我的乐团,终于奏出了和谐、同步的和弦。
第五章:终极乐章 —— 动态调度与未来展望
对于绝大多数场景,循环分配结合树状规约,已经能实现近乎完美的性能。但作为一名追求极致的指挥家,我们还应该了解一种更高级、更灵活的模式:动态调度。
想象一下,我们不再预先分配乐谱,而是在排练室中央放一堆乐谱。每位乐手演奏完一页后,就自己去取下一页,直到所有乐谱都被演奏完。这就是动态调度的核心思想,通常通过一个原子任务队列来实现。
- 工作窃取(Work Stealing): 这种模式甚至允许提前完成任务的核心,去“窃取”那些被分配到慢核心但尚未开始的任务。
在Ascend C的当前语境下,实现一个高效、低开销的内核级原子任务队列极具挑战性,并且其本身的同步开销(原子操作的争用)也可能成为新的瓶颈。但这代表了负载均衡的终极形态——将静态的任务划分,转变为动态的、自适应的资源分配。它为我们指明了未来优化的方向。
终曲:指挥的艺术
从一个挣扎于性能泥潭的调度员,到一名能够指挥多核交响乐的指挥家,我的旅程让我对并行计算的本质有了全新的认识。
- 通信重于计算: 性能的瓶颈往往不在于计算本身有多快,而在于数据和信令(同步)如何在执行单元之间流动。
- 同步是双刃剑:
Sync()是保证正确性的基石,但它也是负载不均的放大器。使用它,就必须承担起均衡负载的责任。 - 分配决定命运: 任务分配策略——块状、循环,或是更动态的方式——直接决定了你的并行程序的效率上限。循环分配是应对不均匀数据分布的瑞士军刀。
- 像硬件一样思考: 成功的指挥家,不仅要理解乐谱(算法),更要深刻理解每一位乐手(AI Core)的特性,以及他们所在的演出大厅(硬件架构)的声学效果。
最终,编写极致性能的多核程序,是一门艺术。它要求我们超越代码的字面意义,去倾听硬件的低语,去编排数据的舞蹈,去指挥一场由硅晶片和逻辑门构成的、无声而壮丽的交响乐。
加入我们,一起在CANN的世界里“码力全开”!
训练营简介:
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
昇腾训练营报名链接:
https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)