
MindSpore社区活动:轻量化MobileNetV2场景识别-体验贴
而 MobileNetV2 的倒残差结构则反向操作,先通过 1×1 卷积升维扩展通道数,再通过 3×3 深度可分离卷积高效提取特征,最后通过 1×1 卷积降维。通过深度可分离卷积与倒残差结构的结合,模型在保持低计算复杂度的同时,仍能提取丰富的特征信息,适用于图像分类、目标检测等任务。MobileNetV2 是谷歌于 2018 年提出的轻量化卷积神经网络模型,专为移动端和嵌入式设备设计,通过核心结构
欢迎大家加入MindSpore社区一起玩!
1.MobileNetV2简介
MobileNetV2 是谷歌于 2018 年提出的轻量化卷积神经网络模型,专为移动端和嵌入式设备设计,通过核心结构创新与技术优化,在保持低计算复杂度的同时显著提升了模型的特征表达能力与性能。
1.1 核心结构创新
MobileNetV2 的核心创新在于倒残差结构(Inverted Residual Block)与线性瓶颈层(Linear Bottleneck)的结合。传统残差模块采用“两头大、中间小”的瓶颈设计:先通过 1×1 卷积降维,再经 3×3 卷积提取特征,最后通过 1×1 卷积升维。而 MobileNetV2 的倒残差结构则反向操作,先通过 1×1 卷积升维扩展通道数,再通过 3×3 深度可分离卷积高效提取特征,最后通过 1×1 卷积降维。这种“中间大、两头小”的结构设计能够更好地保留高维特征信息,避免低维空间中的信息损失。此外,在降维阶段,MobileNetV2 引入线性激活函数替代 ReLU,以防止特征在低维空间中被过度压缩,从而提升特征表达能力。深度可分离卷积作为 MobileNetV2 的另一关键技术,将标准卷积分解为深度卷积与逐点卷积(1×1 卷积),大幅降低计算量与参数量。例如,标准卷积的计算量为 k2×Cin×Cout,而深度可分离卷积仅需 k2×Cin+Cin×Cout,计算量可减少至原来的 Cout1+k21。
1.2 技术特点与优化
MobileNetV2 的技术特点主要体现在轻量化、高特征表达能力与可扩展性三个方面。通过深度可分离卷积与倒残差结构的结合,模型在保持低计算复杂度的同时,仍能提取丰富的特征信息,适用于图像分类、目标检测等任务。倒残差结构与线性瓶颈层的协同作用,使得模型在低维空间中通过线性变换避免信息丢失,在高维空间中通过非线性激活增强特征多样性。此外,MobileNetV2 引入宽度乘数(α)与分辨率乘数(ρ)两个超参数,以灵活调整模型规模。宽度乘数通过控制卷积核通道数调整模型宽度,分辨率乘数通过调整输入图像分辨率控制计算量,从而在准确率与计算效率之间实现权衡。例如,在移动端设备上,通过调整 α 和 ρ,可针对不同硬件条件优化模型性能。
1.3 性能优势与资源效率
MobileNetV2 的性能优势体现在计算效率、内存占用与实时性三个维度。在计算效率方面,模型通过深度可分离卷积与倒残差结构,在相同准确率下显著降低计算量。例如,在 ImageNet 图像分类任务中,MobileNetV2 的计算量仅为 MobileNetV1 的 1/3,但准确率更高。在内存占用方面,深度可分离卷积与轻量化设计大幅减少参数量,使得模型在资源受限的设备上仍能高效运行。此外,MobileNetV2 的实时性表现突出,在移动端设备上可实现实时推理,适用于实时图像分类、目标检测等场景。例如,在自动驾驶中,模型可快速识别行人或交通标志;在智能监控中,可实时跟踪目标物体。
2.训练数据集准备与环境准备
2.1 训练环境准备
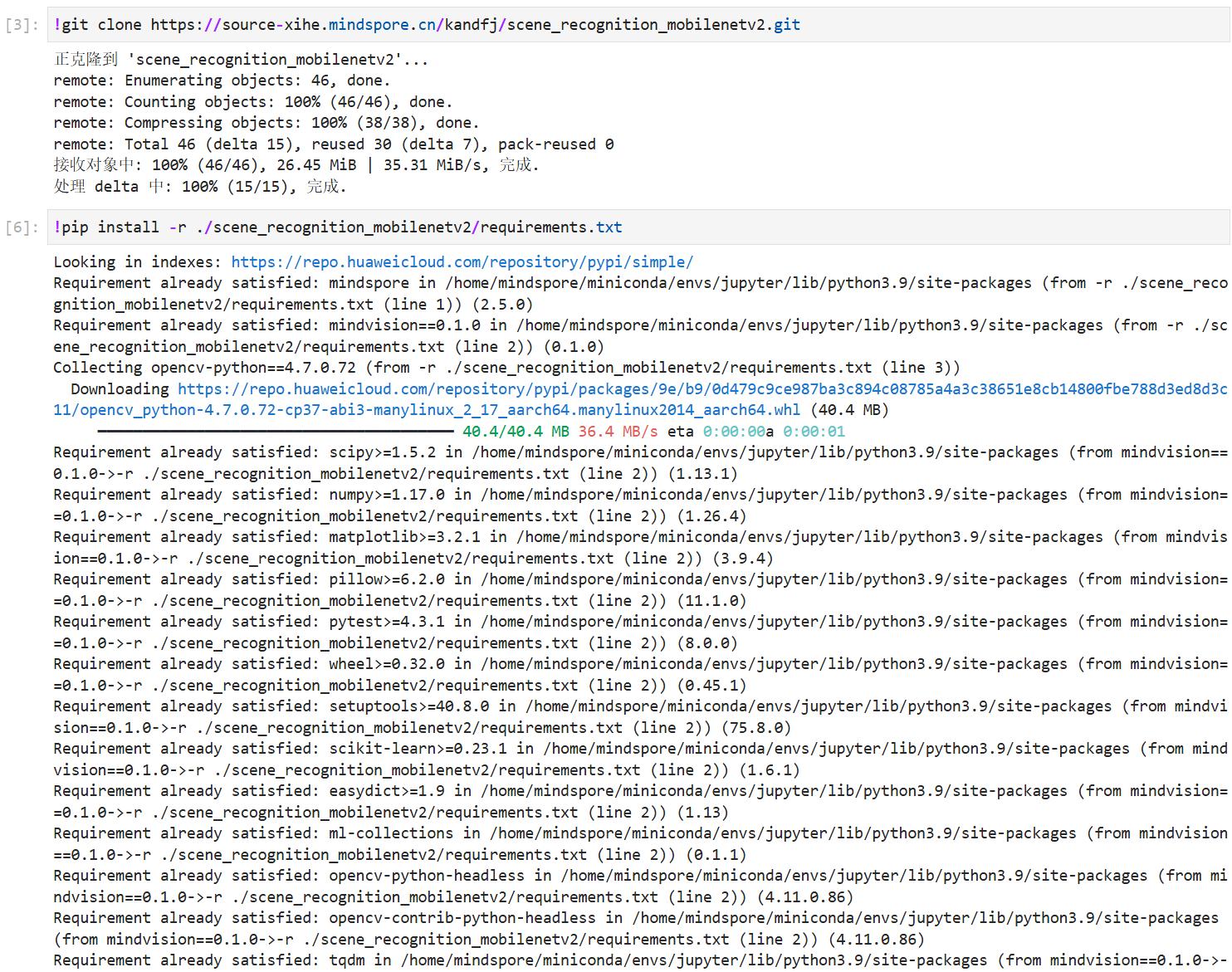
克隆实例后,pip安装库环境
2.2准备数据集
代码:
import kagglehub
# Download latest version
path = kagglehub.dataset_download("puneet6060/intel-image-classification")
print("Path to dataset files:", path)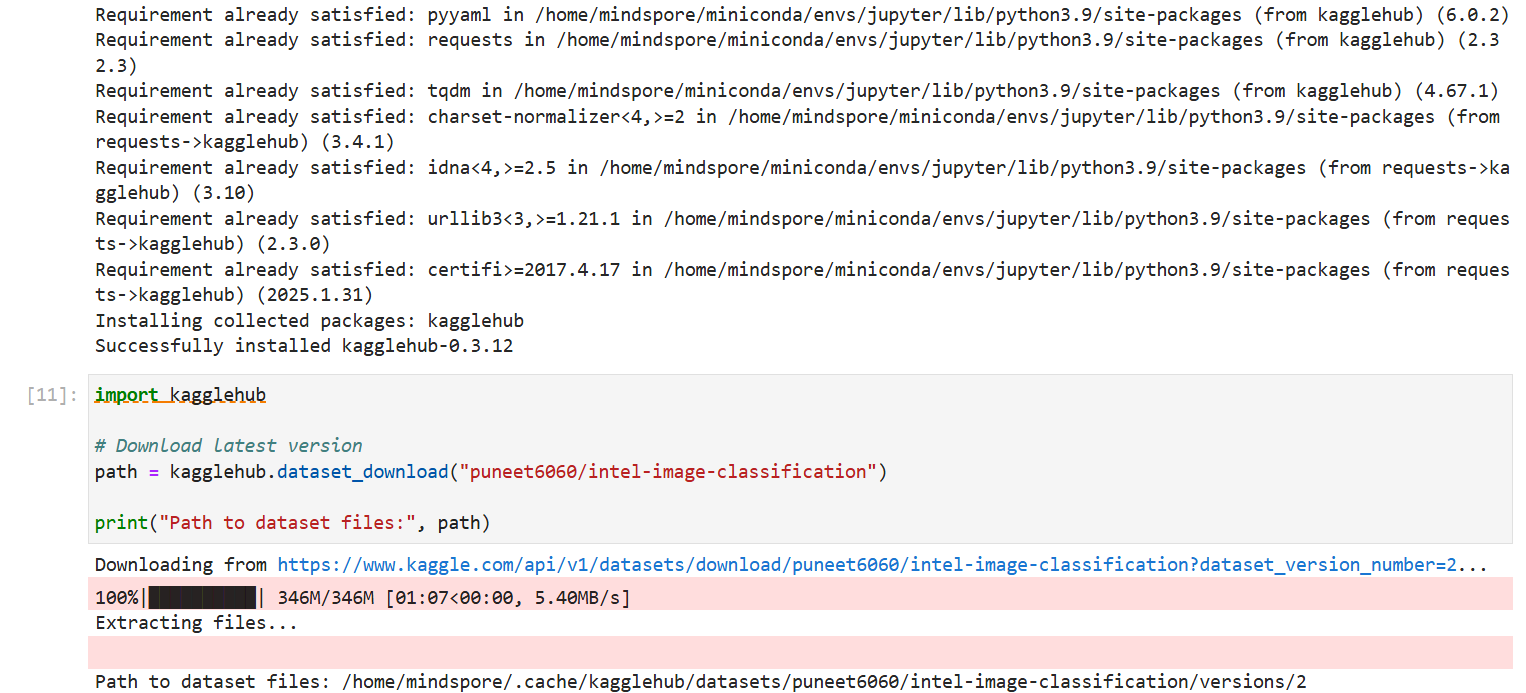
3.模型导入与推理实践
随便找个本地的图片看看能不能正常导入使用
代码:
import numpy as np
import mindspore
from mindspore import Tensor, context
from mindvision.classification.models import mobilenet_v2
import cv2
# 设置执行模式
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
# 加载模型
net = mobilenet_v2(num_classes=6, pretrained=False)
mindspore.load_checkpoint("./scene_recognition_mobilenetv2/MobileNetV2.ckpt", net)
net.set_train(False)
# 图像预处理函数
def load_image(image_path):
# 读取图像
img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 调整大小到150x150
img = cv2.resize(img, (150, 150))
# 归一化和转换为NCHW格式
img = img.astype(np.float32) / 255.0
img = (img - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225])
img = img.transpose(2, 0, 1) # HWC -> CHW
img = np.expand_dims(img, axis=0) # 添加批次维度
return Tensor(img, mindspore.float32)
# 解码预测结果
def decode_prediction(output):
probs = output.asnumpy()
idx = np.argmax(probs, axis=1)[0]
confidence = probs[0, idx]
# 假设有6个类别
class_names = ["类别1", "类别2", "类别3", "类别4", "类别5", "类别6"] # 替换为您的实际类别名称
pred_class = class_names[idx]
return pred_class, confidence
# 示例推理
image = load_image("./scene_recognition_mobilenetv2/test_image.jpg") # 输入大小: 150x150
output = net(image)
pred_class, confidence = decode_prediction(output)
print(f"预测类别: {pred_class}, 置信度: {confidence:.2%}")
4.训练评估
参照原仓库,选用相同的数据集训练评估一下
代码:
import os
import numpy as np
import mindspore
import mindspore.nn as nn
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import context, Model, load_checkpoint, save_checkpoint
from mindspore.train.callback import LossMonitor
from mindvision.classification.models import mobilenet_v2
# 基本配置
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
# 根据您提供的实际路径修正数据集路径
base_path = '/home/mindspore/work/scene_recognition_mobilenetv2/intel-image-classification/versions/2'
train_path = os.path.join(base_path, 'seg_train', 'seg_train')
test_path = os.path.join(base_path, 'seg_test', 'seg_test') # 假设测试集也有类似的嵌套结构
checkpoint_path = './checkpoint'
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
# 类别名称
class_names = ['buildings', 'forest', 'glacier', 'mountain', 'sea', 'street']
# 创建数据集
def create_dataset(path, batch_size=32):
# 首先验证路径是否存在
if not os.path.exists(path):
raise ValueError(f"数据集路径不存在: {path}")
print(f"正在加载数据集: {path}")
# 检查目录结构
class_dirs = [os.path.join(path, d) for d in os.listdir(path)
if os.path.isdir(os.path.join(path, d))]
if not class_dirs:
raise ValueError(f"未找到类别目录在: {path}")
print(f"找到 {len(class_dirs)} 个类别目录: {[os.path.basename(d) for d in class_dirs]}")
# 创建数据集
dataset = ds.ImageFolderDataset(path)
# 打印数据集信息
print(f"数据集大小: {dataset.get_dataset_size()}")
# 数据预处理
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
transform_img = [
vision.Decode(),
vision.Resize((150, 150)),
vision.RandomHorizontalFlip(0.5),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
transform_label = [transforms.TypeCast(mindspore.int32)]
dataset = dataset.map(operations=transform_img, input_columns="image")
dataset = dataset.map(operations=transform_label, input_columns="label")
dataset = dataset.shuffle(buffer_size=1000)
dataset = dataset.batch(batch_size, drop_remainder=False)
# 打印批次信息
steps = dataset.get_dataset_size()
print(f"每个轮次的批次数: {steps}")
return dataset, steps
# 训练模型
def train():
# 加载数据集
train_dataset, steps_per_epoch = create_dataset(train_path, batch_size=32)
# 确保steps_per_epoch > 0
if steps_per_epoch <= 0:
raise ValueError(f"数据集为空,steps_per_epoch={steps_per_epoch}")
# 设置超参数
epochs = 30
initial_lr = 0.001
# 创建网络
network = mobilenet_v2(num_classes=6, pretrained=False)
# 定义损失函数和优化器
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 使用固定学习率
optimizer = nn.Adam(network.trainable_params(), learning_rate=initial_lr, weight_decay=1e-4)
# 创建模型
model = Model(network, loss_fn=loss_fn, optimizer=optimizer, metrics={'accuracy'})
# 训练模型
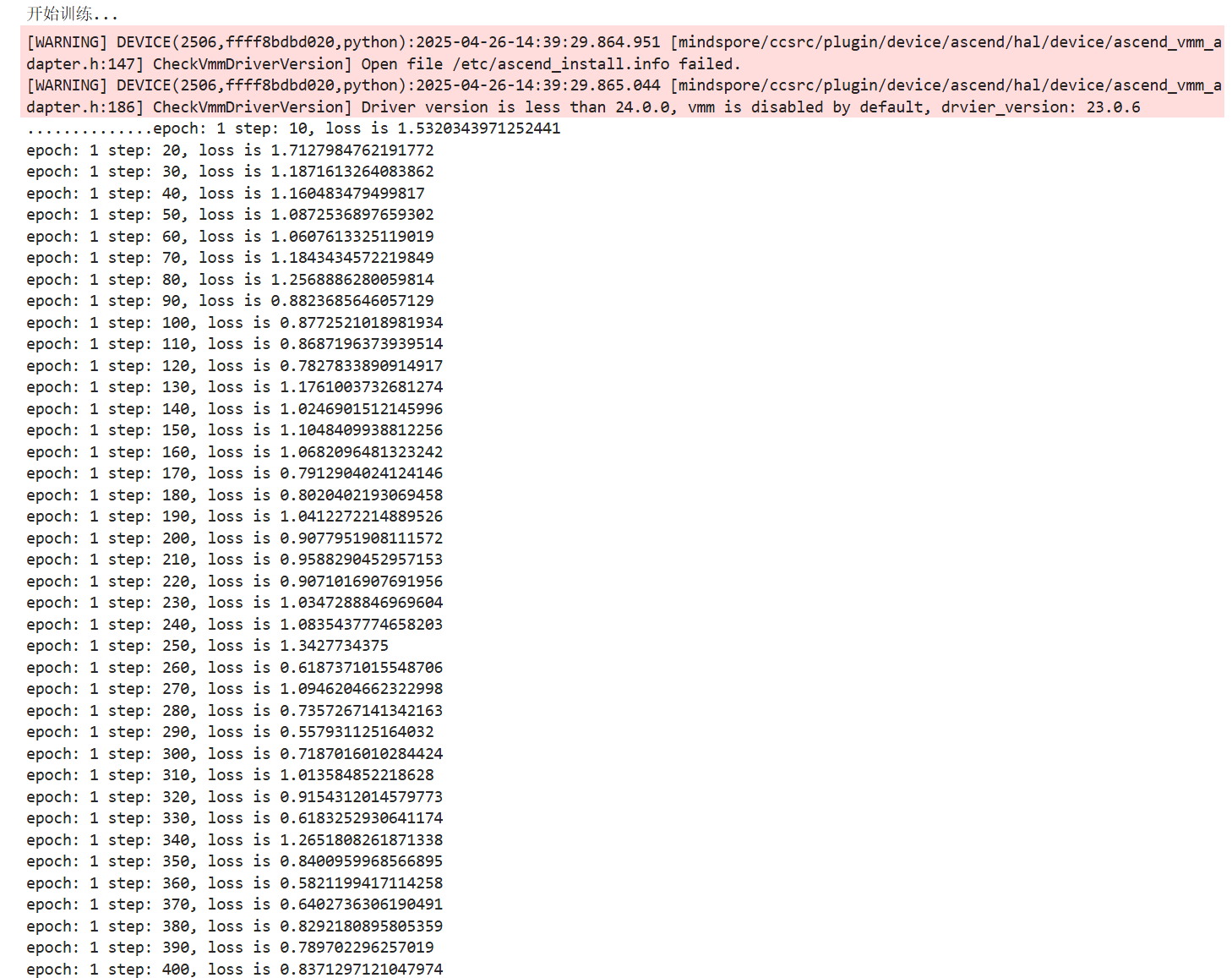
print("开始训练...")
model.train(epoch=epochs, train_dataset=train_dataset, callbacks=[LossMonitor(per_print_times=10)],
dataset_sink_mode=False)
# 保存模型
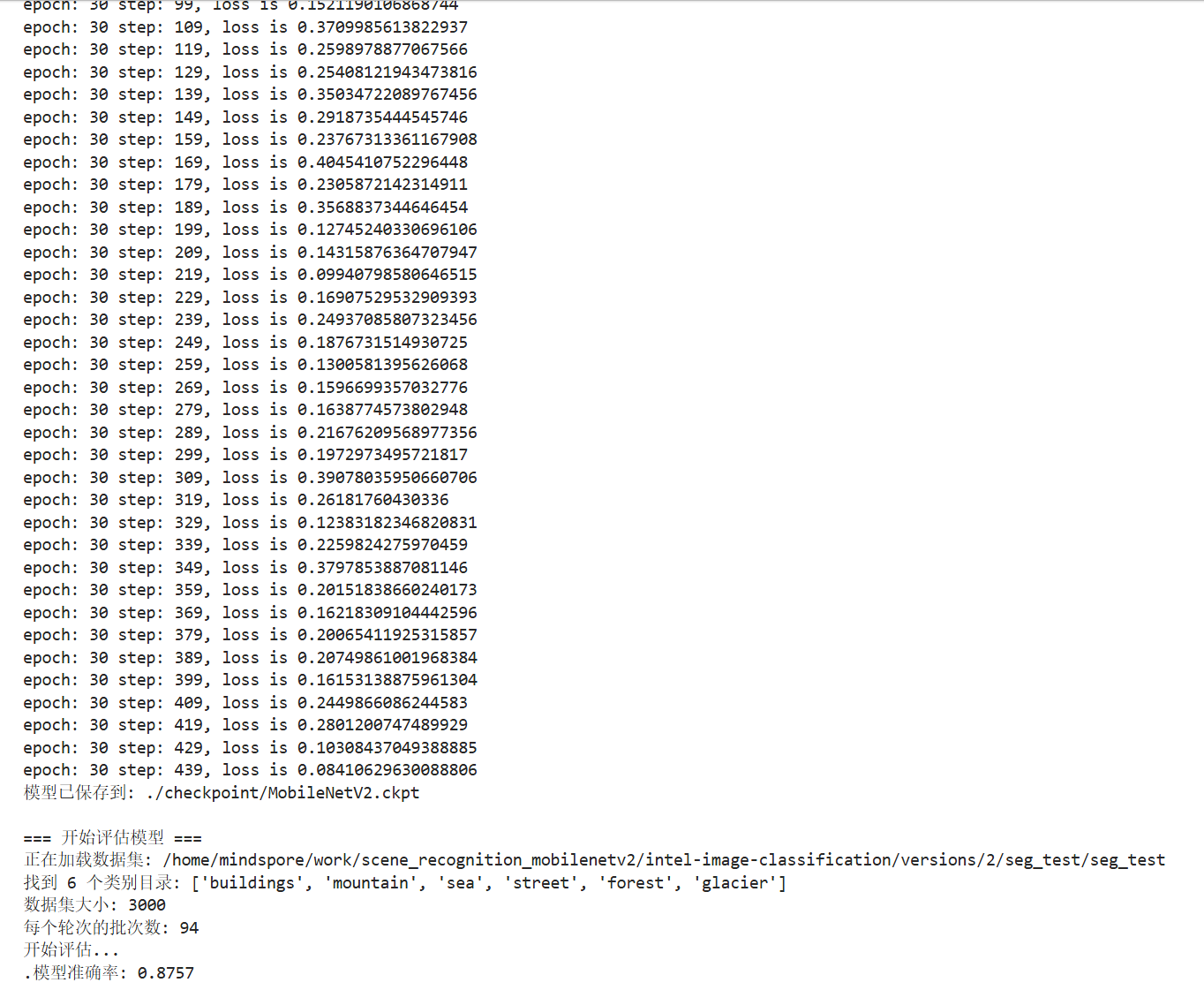
save_checkpoint(network, os.path.join(checkpoint_path, 'MobileNetV2.ckpt'))
print(f"模型已保存到: {os.path.join(checkpoint_path, 'MobileNetV2.ckpt')}")
# 评估模型
def evaluate():
try:
# 加载数据集
eval_dataset, _ = create_dataset(test_path, batch_size=32)
# 创建网络
network = mobilenet_v2(num_classes=6)
# 加载模型
ckpt_file = os.path.join(checkpoint_path, 'MobileNetV2.ckpt')
if not os.path.exists(ckpt_file):
print(f"检查点文件不存在: {ckpt_file}")
return
load_checkpoint(ckpt_file, network)
# 定义损失函数和评估指标
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
model = Model(network, loss_fn=loss_fn, metrics={'accuracy': nn.Accuracy()})
# 评估模型
print("开始评估...")
result = model.eval(eval_dataset, dataset_sink_mode=False)
print(f"模型准确率: {result['accuracy']:.4f}")
except Exception as e:
print(f"评估过程中发生错误: {e}")
# 打印数据集结构
def print_dataset_info():
"""打印数据集的结构信息"""
# 检查数据集路径
print(f"基础路径: {base_path}")
# 检查训练集路径
print(f"\n训练集路径: {train_path}")
if os.path.exists(train_path):
print("训练集类别:")
for cls in os.listdir(train_path):
cls_path = os.path.join(train_path, cls)
if os.path.isdir(cls_path):
files_count = len([f for f in os.listdir(cls_path) if os.path.isfile(os.path.join(cls_path, f))])
print(f" - {cls}: {files_count} 个图像")
else:
print(f"训练集路径不存在: {train_path}")
# 检查测试集路径
print(f"\n测试集路径: {test_path}")
if os.path.exists(test_path):
print("测试集类别:")
for cls in os.listdir(test_path):
cls_path = os.path.join(test_path, cls)
if os.path.isdir(cls_path):
files_count = len([f for f in os.listdir(cls_path) if os.path.isfile(os.path.join(cls_path, f))])
print(f" - {cls}: {files_count} 个图像")
else:
print(f"测试集路径不存在: {test_path}")
# 主函数
if __name__ == '__main__':
# 首先查看数据集信息
print("=== 检查数据集结构 ===")
print_dataset_info()
try:
# 训练模型
print("\n=== 开始训练模型 ===")
train()
# 评估模型
print("\n=== 开始评估模型 ===")
evaluate()
except Exception as e:
print(f"执行过程中发生错误: {e}")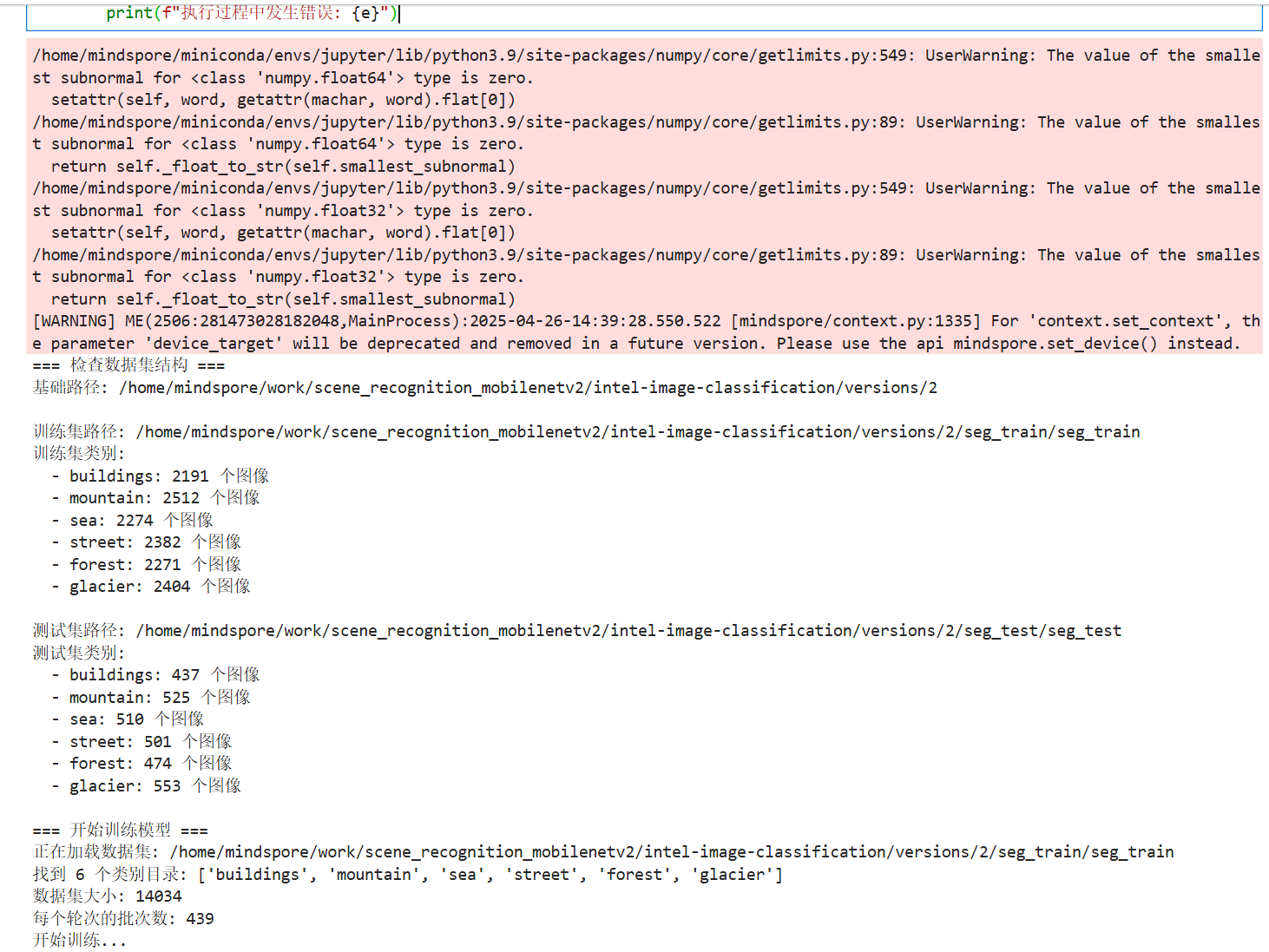
5.小结
原仓库中具体训练参数没有详细提供,所以准确率等参数与原仓库略有差距。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)