
《昇思25天学习打卡营第22天|LSTM+CRF序列标注》
序列标注(Sequence Labeling)在自然语言处理(NLP)领域中是一项关键技术,序列标注通过为序列中的每个元素分配一个标签,帮助计算机理解和处理自然语言中的各种信息,为进一步的语言处理和理解打下基础。序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Ta
1.序列标注的作用是什么
序列标注(Sequence Labeling)在自然语言处理(NLP)领域中是一项关键技术,序列标注通过为序列中的每个元素分配一个标签,帮助计算机理解和处理自然语言中的各种信息,为进一步的语言处理和理解打下基础。
序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。以命名实体识别为例:
| 输入序列 | 清 | 华 | 大 | 学 | 座 | 落 | 于 | 首 | 都 | 北 | 京 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输出标注 | B | I | I | I | O | O | O | O | O | B | I |
如上表所示,清华大学 和 北京是地名,需要将其识别,我们对每个输入的单词预测其标签,最后根据标签来识别实体。
这里使用了一种常见的命名实体识别的标注方法——“BIOE”标注,将一个实体(Entity)的开头标注为B,其他部分标注为I,非实体标注为O。
主要作用包括:
-
命名实体识别(NER):识别文本中具有特定意义的实体,如人名、地名、机构名等。例如,在句子“John lives in New York”中,John是一个人名,New York是一个地名。
-
词性标注(POS Tagging):对每个单词进行词性标注,如名词、动词、形容词等。这对于句子解析和语法分析非常重要。
-
语义角色标注(SRL):识别句子中单词或短语的语义角色,如主语、宾语、谓语等。例如,在句子“Mary sold the car to John”中,Mary是卖家,the car是商品,John是买家。
-
分词(Word Segmentation):特别是在中文等语言中,分词是将连续的字符序列切分成独立的单词。这是进行进一步处理的基础。
-
意图识别和槽填充(Intent Recognition and Slot Filling):在对话系统中,识别用户的意图并提取相关信息。例如,用户说“预订明天晚上8点的餐厅”,系统需要识别出意图是预订餐厅,并提取出时间和其他相关信息。
2.序列标注主要使用哪些方法
序列标注的主要方法可以分为传统方法和深度学习方法两大类:
传统方法
-
隐马尔可夫模型(HMM, Hidden Markov Model):基于统计的序列标注方法,通过最大化观测序列的概率来找到最优的状态序列,适用于词性标注和分词等任务。
-
条件随机场(CRF, Conditional Random Field):一种判别式模型,可以直接建模条件概率,适用于命名实体识别等需要考虑标签之间依赖关系的任务。
-
最大熵马尔可夫模型(MEMM, Maximum Entropy Markov Model):结合了最大熵模型和马尔可夫模型,能够考虑更多的特征信息。
深度学习方法
-
循环神经网络(RNN, Recurrent Neural Network):适用于处理序列数据,能够捕捉序列中的长短期依赖关系。常用变种包括LSTM(长短期记忆网络)和GRU(门控循环单元)。
-
双向LSTM(BiLSTM, Bidirectional Long Short-Term Memory):结合前向和后向的LSTM,可以同时捕捉过去和未来的信息,提升标注效果。
-
序列到序列模型(Seq2Seq, Sequence to Sequence Model):特别适用于机器翻译等任务,通过编码器-解码器结构实现序列映射。
-
注意力机制(Attention Mechanism):允许模型在处理当前元素时关注到序列中的其他重要元素,提升了对长距离依赖的捕捉能力。
-
Transformer:完全基于注意力机制的模型,能够并行处理序列中的所有元素,极大提升了效率和效果,被广泛应用于各种NLP任务。
-
BERT(Bidirectional Encoder Representations from Transformers):基于Transformer的预训练模型,通过大规模无监督预训练和任务特定的微调,极大提升了序列标注任务的表现。
3.典型序列标注任务的流程
- 数据预处理:准备和处理训练数据,包括分词、词向量嵌入等。
- 模型构建:定义BiLSTM+CRF模型,包括嵌入层、BiLSTM层和CRF层。
- 训练模型:通过Score计算、Normalizer计算和CRF层的优化,训练模型参数。
- 模型预测:使用训练好的模型,通过Viterbi算法进行序列标注预测。
- 评估和调优:评估模型性能,进行必要的参数调优和模型改进。
4.LSTM+CRF序列标注的大概步骤
- Score计算:计算标签序列的总得分。
- Normalizer计算:计算归一化分母,使得输出为概率分布。
- Viterbi算法:找到最可能的标签序列。
- CRF层:在训练阶段通过最大化对数似然估计进行参数优化,在预测阶段通过Viterbi算法进行解码。
1. Score计算
Score计算步骤的主要目的是为每个可能的标签序列分配一个得分(或置信度)。在CRF模型中,得分由以下两个部分组成:
- 发射分数(Emission Score):BiLSTM输出的每个时间步的得分,表示在特定时间步给定某个标签的概率。
- 转移分数(Transition Score):表示从一个标签转移到下一个标签的概率,考虑了标签之间的依赖关系。
综合这两个分数,可以计算整个标签序列的总得分。
2. Normalizer计算
为了将得分转化为概率分布,需要进行归一化处理。Normalizer计算的目的是计算所有可能的标签序列的总得分,这相当于归一化分母。
这个步骤确保模型输出的是合法的概率分布,便于进行概率推断和训练。
3. Viterbi算法
Viterbi算法是一种动态规划算法,用于在给定观测序列的情况下找到最可能的标签序列。其主要步骤包括:
- 初始化:设置起始状态的初始分数。
- 递归计算:逐步计算每个时间步的最优得分和路径。
- 终止和回溯:在最后一个时间步找到得分最高的标签,并通过回溯找到最优路径。
通过Viterbi算法,模型能够在解码阶段找到最可能的标签序列,从而进行预测。
4. CRF层
CRF层是BiLSTM+CRF模型的关键部分,它通过结合BiLSTM的输出和标签之间的依赖关系进行全局优化。CRF层的作用包括:
- 训练阶段:通过最大化条件对数似然估计(Conditional Log-Likelihood)来调整模型参数,使得真实标签序列的得分最大化。
- 预测阶段:使用Viterbi算法找到最优标签序列,进行预测。
5. BiLSTM+CRF模型
在实现CRF后,设计一个双向LSTM+CRF的模型来进行命名实体识别任务的训练。模型结构如下:
nn.Embedding -> nn.LSTM -> nn.Dense -> CRF
其中LSTM提取序列特征,经过Dense层变换获得发射概率矩阵,最后送入CRF层。具体实现如下:
class BiLSTM_CRF(nn.Cell):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_tags, padding_idx=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=padding_idx)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, bidirectional=True, batch_first=True)
self.hidden2tag = nn.Dense(hidden_dim, num_tags, 'he_uniform')
self.crf = CRF(num_tags, batch_first=True)
def construct(self, inputs, seq_length, tags=None):
embeds = self.embedding(inputs)
outputs, _ = self.lstm(embeds, seq_length=seq_length)
feats = self.hidden2tag(outputs)
crf_outs = self.crf(feats, tags, seq_length)
return crf_outsembedding_dim = 16
hidden_dim = 32
training_data = [(
"清 华 大 学 坐 落 于 首 都 北 京".split(),
"B I I I O O O O O B I".split()
), (
"重 庆 是 一 个 魔 幻 城 市".split(),
"B I O O O O O O O".split()
)]
word_to_idx = {}
word_to_idx['<pad>'] = 0
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_idx:
word_to_idx[word] = len(word_to_idx)
tag_to_idx = {"B": 0, "I": 1, "O": 2}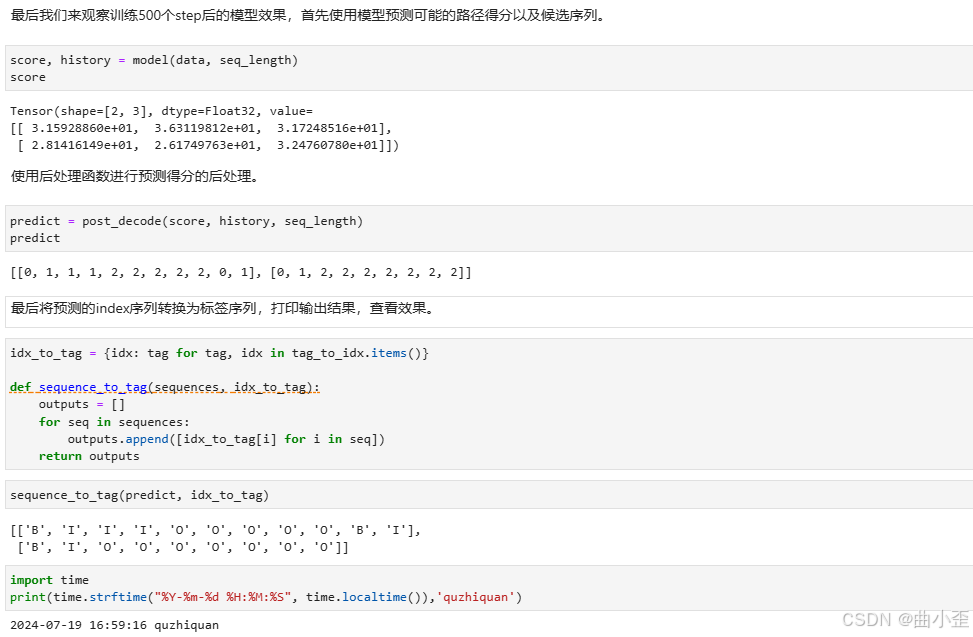

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 36
36 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)