
MindSpore学习实践——Transformer实现文本机器翻译
MindSpore打卡营:基于MindSpore实现Transformer实现文本机器翻译
MindSpore学习实践——Transformer实现文本机器翻译
前言
-
Transformer由Vaswani等人在2017年的论文“Attention Is All You Need”中提出,可以用于处理及其翻译、语言建模和文本生成等自然语言处理(NLP)任务。笔者目前也正在接触transformer,主要用于对预训练模型的微调,本文章也是借由MIndSpore开源社区提供的学习机会写出,若有不专业或表述不当还请多多指教。
-
Transformer与传统NLP特征提取类模型的区别主要在以下两点:
- Transformer将自注意力机制和多头注意力机制的概念运用到模型中。比如说本次课程所讲的attention_mask,它属于自注意力机制的一部分。它用于在计算注意力分数时屏蔽掉某些位置的值,通常用于处理不同长度的序列或屏蔽掉填充的部分。;
- 由于缺少RNN模型的时序性,Transformer引入了位置编码,在数据上而非模型中添加位置信息;
-
因此transformer带来了更容易并行化、训练更高效;在处理长序列的任务中表现优秀、可以快速捕捉长距离中的关联信息登优点。
相关知识总结:
- 首先我们完成环境的安装:
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
-
注意力机制
注意力机制,顾名思义,就是判断成分在句子中的重要性,主要通过注意力分数实现,而注意力分数主要参考三个因素:
query:任务内容key:索引/标签(主要用于定位)value:答案
计算注意力分数,就是计算
query与key的相似度。这里以scaled dot-product attention方式为例:点积可以用于体现两个向量之间的相似度,因此我们考虑计算
query和key的点积,然后将相似度的区间限制在0到1之间,并令其作用于value之上:
Attention(Q,K,V)=softmax(QKTdmodel)V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{model}}}\right)V Attention(Q,K,V)=softmax(dmodelQKT)V
值得注意的是,在上面计算时,为了避免query和key本身的“大小”影响到相似度的计算,我们需要在点乘后除以
dmodel \sqrt{d_{model}} dmodel
代码实训:
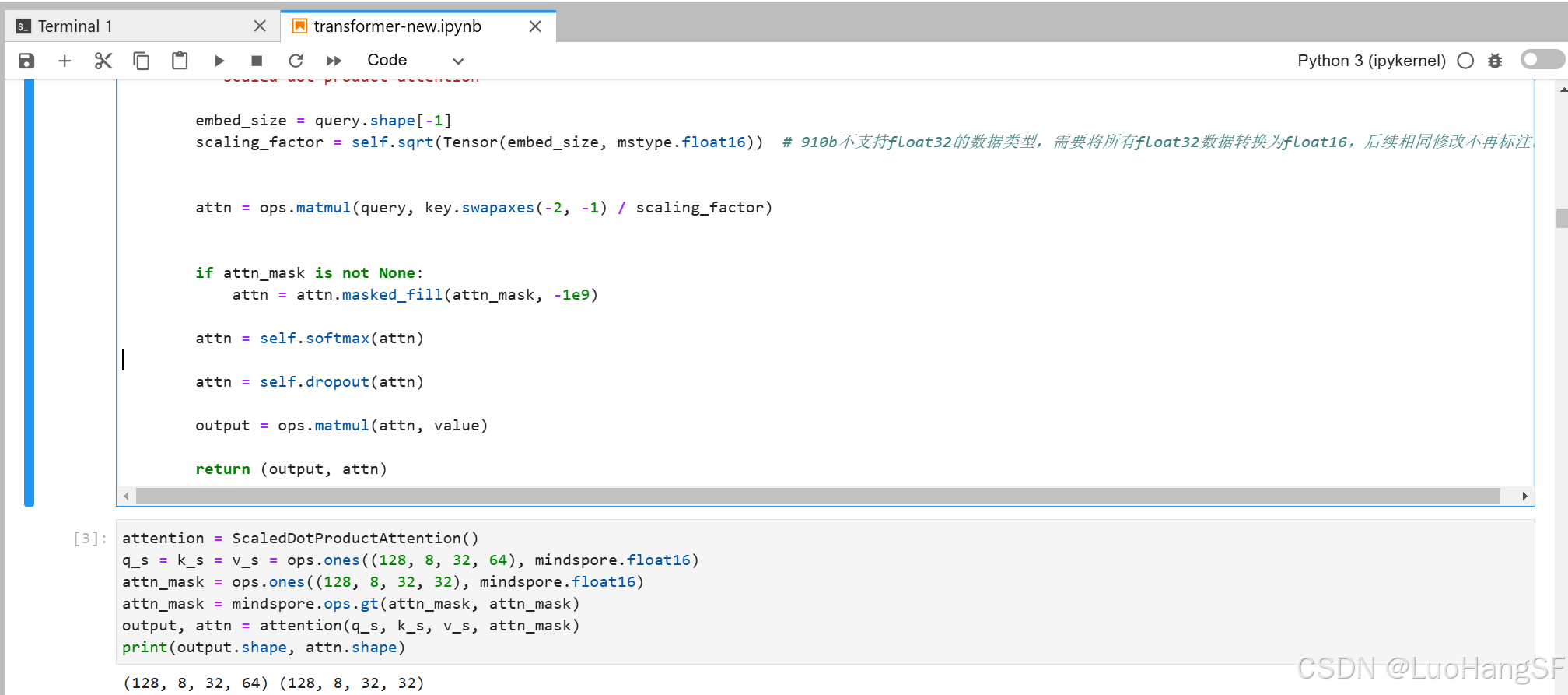
为了保证句子数据长度一致,我们使用了<pad>占位符补齐了一些稍短的文本(<pad>无意义,不计入注意力分数计算当中,为0)
代码实训: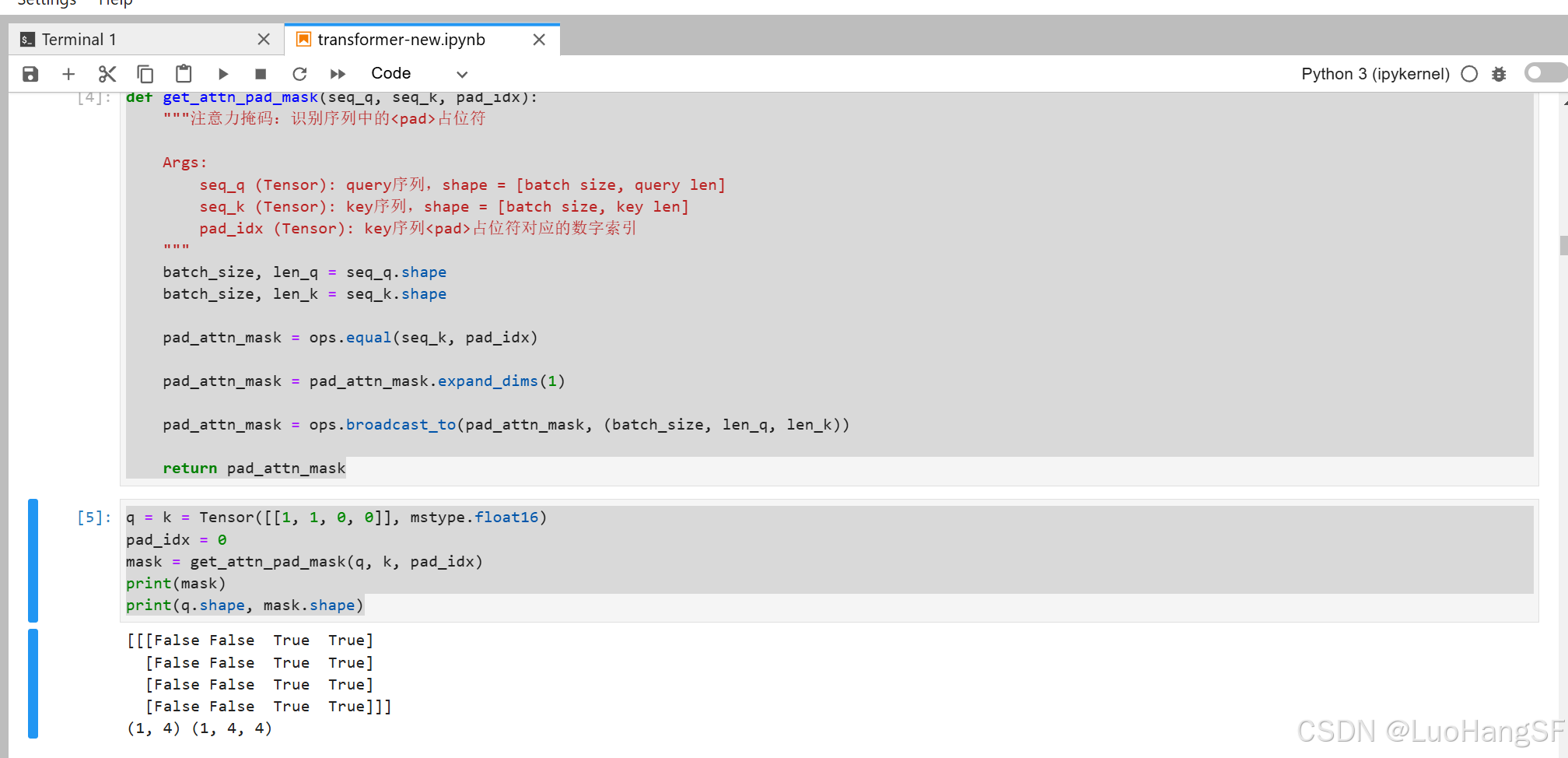
-
自注意力机制
自注意力机制主要用于关注句子本身,查看每一个单词对于周边句子的重要性(主要是逻辑关系)。其计算与注意力机制的计算公式相同,但是
query、key、value变成了句子本身点乘各自的权重。 -
多头注意力机制
其是对自注意力机制的扩展。它将输入分成多个头,每个头独立地执行自注意力计算,然后将这些头的输出拼接起来,并通过一个线性变换得到最终的输出。
多头注意力机制的优点是可以’解读’输入内容的不同方面,从而增强模型的表达能力。
-
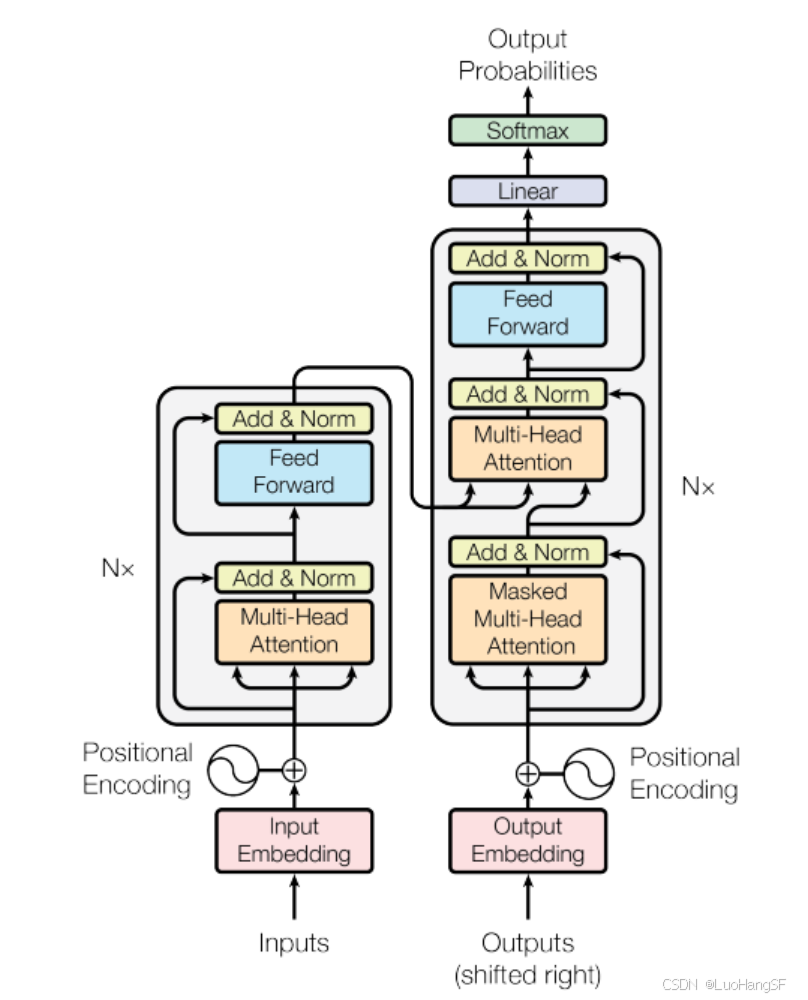
Transformer结构
具体结构如下图:
-
位置编码
transformer由于其不含RNN的特性,模型预测的结果会因为识别顺序的改变而改变,因此引入了位置编码。
实现代码如下:
from mindspore import numpy as mnp class PositionalEncoding(nn.Cell): """位置编码""" def __init__(self, d_model, dropout_p=0.1, max_len=100): super().__init__() self.dropout = nn.Dropout(p = dropout_p) self.pe = ops.Zeros()((max_len, d_model), mstype.float16) pos = mnp.arange(0, max_len, dtype=mstype.float16).view((-1, 1)) angle = ops.pow(10000.0, mnp.arange(0, d_model, 2, dtype=mstype.float16)/d_model) self.pe[:, 0::2] = ops.sin(pos/angle) self.pe[:, 1::2] = ops.cos(pos/angle) def construct(self, x): batch_size = x.shape[0] pe = self.pe.expand_dims(0) pe = ops.broadcast_to(pe, (batch_size, -1, -1)) x = x + pe[:, :x.shape[1], :] return self.dropout(x) x = ops.Zeros()((1, 2, 4), mstype.float16) pe = PositionalEncoding(4) print(pe(x))结果为:
[[[0. 1. 0. 1. ]
[0.8413 0.5405 0.01 1. ]]]
实践:通过Transformer实现文本机器翻译
- 前期的数据准备
from download import download
import re
url = "https://modelscope.cn/api/v1/datasets/SelinaRR/Multi30K/repo?Revision=master&FilePath=Multi30K.zip"
download(url, './', kind='zip', replace=True)
datasets_path = './datasets/'
train_path = datasets_path + 'train/'
valid_path = datasets_path + 'valid/'
test_path = datasets_path + 'test/'
def print_data(data_file_path, print_n=5):
print("=" * 40 + "datasets in {}".format(data_file_path) + "=" * 40)
with open(data_file_path, 'r', encoding='utf-8') as en_file:
en = en_file.readlines()[:print_n]
for index, seq in enumerate(en):
print(index, seq.replace('\n', ''))
print_data(train_path + 'train.de')
print_data(train_path + 'train.en')
import os
class Multi30K():
"""Multi30K数据集加载器
加载Multi30K数据集并处理为一个Python迭代对象。
"""
def __init__(self, path):
self.data = self._load(path)
def _load(self, path):
def tokenize(text):
text = text.rstrip()
return [tok.lower() for tok in re.findall(r'\w+|[^\w\s]', text)]
members = {i.split('.')[-1]: i for i in os.listdir(path)}
de_path = os.path.join(path, members['de'])
en_path = os.path.join(path, members['en'])
with open(de_path, 'r', encoding='utf-8') as de_file:
de = de_file.readlines()[:-1]
de = [tokenize(i) for i in de]
with open(en_path, 'r', encoding='utf-8') as en_file:
en = en_file.readlines()[:-1]
en = [tokenize(i) for i in en]
return list(zip(de, en))
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
train_dataset, valid_dataset, test_dataset = Multi30K(train_path), Multi30K(valid_path), Multi30K(test_path)
for de, en in test_dataset:
print(f'de = {de}')
print(f'en = {en}')
break
class Vocab:
"""通过词频字典,构建词典"""
special_tokens = ['<unk>', '<pad>', '<bos>', '<eos>']
def __init__(self, word_count_dict, min_freq=1):
self.word2idx = {}
for idx, tok in enumerate(self.special_tokens):
self.word2idx[tok] = idx
filted_dict = {
w: c
for w, c in word_count_dict.items() if c >= min_freq
}
for w, _ in filted_dict.items():
self.word2idx[w] = len(self.word2idx)
self.idx2word = {idx: word for word, idx in self.word2idx.items()}
self.bos_idx = self.word2idx['<bos>']
self.eos_idx = self.word2idx['<eos>']
self.pad_idx = self.word2idx['<pad>']
self.unk_idx = self.word2idx['<unk>']
def _word2idx(self, word):
"""单词映射至数字索引"""
if word not in self.word2idx:
return self.unk_idx
return self.word2idx[word]
def _idx2word(self, idx):
"""数字索引映射至单词"""
if idx not in self.idx2word:
raise ValueError('input index is not in vocabulary.')
return self.idx2word[idx]
def encode(self, word_or_list):
"""将单个单词或单词数组映射至单个数字索引或数字索引数组"""
if isinstance(word_or_list, list):
return [self._word2idx(i) for i in word_or_list]
return self._word2idx(word_or_list)
def decode(self, idx_or_list):
"""将单个数字索引或数字索引数组映射至单个单词或单词数组"""
if isinstance(idx_or_list, list):
return [self._idx2word(i) for i in idx_or_list]
return self._idx2word(idx_or_list)
def __len__(self):
return len(self.word2idx)
word_count = {'a':20, 'b':10, 'c':1, 'd':2}
vocab = Vocab(word_count, min_freq=2)
len(vocab)
from collections import Counter, OrderedDict
def build_vocab(dataset):
de_words, en_words = [], []
for de, en in dataset:
de_words.extend(de)
en_words.extend(en)
de_count_dict = OrderedDict(sorted(Counter(de_words).items(), key=lambda t: t[1], reverse=True))
en_count_dict = OrderedDict(sorted(Counter(en_words).items(), key=lambda t: t[1], reverse=True))
return Vocab(de_count_dict, min_freq=2), Vocab(en_count_dict, min_freq=2)
de_vocab, en_vocab = build_vocab(train_dataset)
print('Unique tokens in de vocabulary:', len(de_vocab))
import mindspore
class Iterator():
"""创建数据迭代器"""
def __init__(self, dataset, de_vocab, en_vocab, batch_size, max_len=32, drop_reminder=False):
self.dataset = dataset
self.de_vocab = de_vocab
self.en_vocab = en_vocab
self.batch_size = batch_size
self.max_len = max_len
self.drop_reminder = drop_reminder
length = len(self.dataset) // batch_size
self.len = length if drop_reminder else length + 1 # 批量数量
def __call__(self):
def pad(idx_list, vocab, max_len):
"""统一序列长度,并记录有效长度"""
idx_pad_list, idx_len = [], []
for i in idx_list:
if len(i) > max_len - 2:
idx_pad_list.append(
[vocab.bos_idx] + i[:max_len-2] + [vocab.eos_idx]
)
idx_len.append(max_len)
else:
idx_pad_list.append(
[vocab.bos_idx] + i + [vocab.eos_idx] + [vocab.pad_idx] * (max_len - len(i) - 2)
)
idx_len.append(len(i) + 2)
return idx_pad_list, idx_len
def sort_by_length(src, trg):
"""对德/英语的字段长度进行排序"""
data = zip(src, trg)
data = sorted(data, key=lambda t: len(t[0]), reverse=True)
return zip(*list(data))
def encode_and_pad(batch_data, max_len):
"""将批量中的文本数据转换为数字索引,并统一每个序列的长度"""
src_data, trg_data = zip(*batch_data)
src_idx = [self.de_vocab.encode(i) for i in src_data]
trg_idx = [self.en_vocab.encode(i) for i in trg_data]
src_idx, trg_idx = sort_by_length(src_idx, trg_idx)
src_idx_pad, src_len = pad(src_idx, de_vocab, max_len)
trg_idx_pad, _ = pad(trg_idx, en_vocab, max_len)
return src_idx_pad, src_len, trg_idx_pad
for i in range(self.len):
if i == self.len - 1 and not self.drop_reminder:
batch_data = self.dataset[i * self.batch_size:]
else:
batch_data = self.dataset[i * self.batch_size: (i+1) * self.batch_size]
src_idx, src_len, trg_idx = encode_and_pad(batch_data, self.max_len)
yield mindspore.Tensor(src_idx, mindspore.int32), \
mindspore.Tensor(src_len, mindspore.int32), \
mindspore.Tensor(trg_idx, mindspore.int32)
def __len__(self):
return self.len
train_iterator = Iterator(train_dataset, de_vocab, en_vocab, batch_size=128, max_len=32, drop_reminder=True)
valid_iterator = Iterator(valid_dataset, de_vocab, en_vocab, batch_size=128, max_len=32, drop_reminder=False)
test_iterator = Iterator(test_dataset, de_vocab, en_vocab, batch_size=1, max_len=32, drop_reminder=False)
for src_idx, src_len, trg_idx in train_iterator():
print(f'src_idx.shape:{src_idx.shape}\n{src_idx}\nsrc_len.shape:{src_len.shape}\n{src_len}\ntrg_idx.shape:{trg_idx.shape}\n{trg_idx}')
break
- 模型的构建
src_vocab_size = len(de_vocab)
trg_vocab_size = len(en_vocab)
src_pad_idx = de_vocab.pad_idx
trg_pad_idx = en_vocab.pad_idx
d_model = 512
d_ff = 2048
n_layers = 6
n_heads = 8
encoder = Encoder(src_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1).to_float(mstype.float16)
decoder = Decoder(trg_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1).to_float(mstype.float16)
model = Transformer(encoder, decoder)
- 模型的训练与评估
loss_fn = nn.CrossEntropyLoss(ignore_index=trg_pad_idx)
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.0001)
def forward(enc_inputs, dec_inputs):
"""前向网络
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, trg_len]
"""
logits, _, _, _ = model(enc_inputs, dec_inputs[:, :-1], src_pad_idx, trg_pad_idx)
targets = dec_inputs[:, 1:].view(-1)
loss = loss_fn(logits, targets)
return loss
grad_fn = mindspore.value_and_grad(forward, None, optimizer.parameters)
def train_step(enc_inputs, dec_inputs):
loss, grads = grad_fn(enc_inputs, dec_inputs)
optimizer(grads)
return loss
from tqdm import tqdm
def train(iterator, epoch=0):
model.set_train(True)
num_batches = len(iterator)
total_loss = 0
total_steps = 0
with tqdm(total=num_batches) as t:
t.set_description(f'Epoch: {epoch}')
for src, src_len, trg in iterator():
loss = train_step(src, trg)
total_loss += loss.asnumpy()
total_steps += 1
curr_loss = total_loss / total_steps
t.set_postfix({'loss': f'{curr_loss:.2f}'})
t.update(1)
return total_loss / total_steps
def evaluate(iterator):
model.set_train(False)
num_batches = len(iterator)
total_loss = 0
total_steps = 0
with tqdm(total=num_batches) as t:
for src, _, trg in iterator():
loss = forward(src, trg)
total_loss += loss.asnumpy()
total_steps += 1
curr_loss = total_loss / total_steps
t.set_postfix({'loss': f'{curr_loss:.2f}'})
t.update(1)
return total_loss / total_steps
# 开始训练
from mindspore import save_checkpoint
num_epochs = 10
best_valid_loss = float('inf')
ckpt_file_name = './transformer.ckpt'
for i in range(num_epochs):
train_loss = train(train_iterator, i)
valid_loss = evaluate(valid_iterator)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
save_checkpoint(model, ckpt_file_name)
- 模型推理
from mindspore import load_checkpoint, load_param_into_net
encoder = Encoder(src_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1).to_float(mstype.float16)
decoder = Decoder(trg_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1).to_float(mstype.float16)
new_model = Transformer(encoder, decoder)
param_dict = load_checkpoint(ckpt_file_name)
load_param_into_net(new_model, param_dict)
def inference(sentence, max_len=32):
"""模型推理:输入一个德语句子,输出翻译后的英文句子
enc_inputs: [batch_size(1), src_len]
"""
new_model.set_train(False)
# 对输入句子进行分词
if isinstance(sentence, str):
tokens = [tok.lower() for tok in re.findall(r'\w+|[^\w\s]', sentence.rstrip())]
else:
tokens = [token.lower() for token in sentence]
# 补充起始、终止占位符,统一序列长度
if len(tokens) > max_len - 2:
src_len = max_len
tokens = ['<bos>'] + tokens[:max_len - 2] + ['<eos>']
else:
src_len = len(tokens) + 2
tokens = ['<bos>'] + tokens + ['<eos>'] + ['<pad>'] * (max_len - src_len)
# 将德语单词转换为数字索引,并进一步转换为tensor
# enc_inputs: [1, src_len]
indexes = de_vocab.encode(tokens)
enc_inputs = Tensor(indexes, mstype.float16).expand_dims(0)
# 将输入送入encoder,获取信息
enc_outputs, _ = new_model.encoder(enc_inputs, src_pad_idx)
dec_inputs = Tensor([[en_vocab.bos_idx]], mstype.float16)
# 初始化decoder输入,此时仅有句首占位符<pad>
# dec_inputs: [1, 1]
max_len = enc_inputs.shape[1]
for _ in range(max_len):
dec_outputs, _, _ = new_model.decoder(dec_inputs, enc_inputs, enc_outputs, src_pad_idx, trg_pad_idx)
dec_logits = dec_outputs.view((-1, dec_outputs.shape[-1]))
# 找到下一个词的概率分布,并输出预测
dec_logits = dec_logits[-1, :]
pred = dec_logits.argmax(axis=0).expand_dims(0).expand_dims(0)
pred = pred.astype(mstype.float16)
# 更新dec_inputs
dec_inputs = ops.concat((dec_inputs, pred), axis=1)
# 如果出现<eos>,则终止循环
if int(pred.asnumpy()[0,0]) == en_vocab.eos_idx:
break
# 将数字索引转换为英文单词
trg_indexes = [int(i) for i in dec_inputs.view(-1).asnumpy()]
eos_idx = trg_indexes.index(en_vocab.eos_idx) if en_vocab.eos_idx in trg_indexes else -1
trg_tokens = en_vocab.decode(trg_indexes[1:eos_idx])
return trg_tokens
example_idx = 0
src = test_dataset[example_idx][0]
trg = test_dataset[example_idx][1]
pred_trg = inference(src)
print(f'src = {src}')
print(f'trg = {trg}')
print(f"predicted trg = {pred_trg}")
from nltk.translate.bleu_score import corpus_bleu
def calculate_bleu(dataset, max_len=50):
trgs = []
pred_trgs = []
for data in dataset[:10]:
src = data[0]
trg = data[1]
pred_trg = inference(src, max_len)
pred_trgs.append(pred_trg)
trgs.append([trg])
return corpus_bleu(trgs, pred_trgs)
bleu_score = calculate_bleu(test_dataset)
print(f'BLEU score = {bleu_score*100:.2f}')
-
实训结果:
-
翻译
-
BLEU得分
-
总结
本节课主要学习了transformer的基础知识。课程给的代码很详细,收获颇丰。虽然完成了打卡实训,但个人认为还是学习得很浅,后续将继续学习transformer,把所学用于实际应用中,力求尽快掌握并自主完成一次模型微调。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 52
52 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)