
Llama-2-7b在昇腾NPU上的六大核心场景性能基准报告
随着大语言模型(LLM)技术的飞速发展,其底层算力支撑硬件的重要性日益凸显。传统的GPU方案之外,以华为昇腾(Ascend)为代表的NPU(神经网络处理单元)正成为业界关注的焦点。为了全面评估昇腾NPU在实际LLM应用中的性能表现,我们进行了一项针对性的深度测评。本次测评选用业界广泛应用的开源模型Llama-2-7b,在昇腾NPU平台上进行部署、测试与分析,旨在为开发者和决策者提供一份详实的核心性

引言
随着大语言模型(LLM)技术的飞速发展,其底层算力支撑硬件的重要性日益凸显。传统的GPU方案之外,以华为昇腾(Ascend)为代表的NPU(神经网络处理单元)正成为业界关注的焦点。为了全面、深入地评估昇腾NPU在实际LLM应用中的性能表现,我们进行了一项针对性的深度测评。本次测评选用业界广泛应用的开源模型Llama-2-7b,在 Atlas 800T A2 训练卡 平台上进行部署、测试与分析,旨在为开发者和决策者提供一份详实的核心性能数据、深度的场景性能剖析、以及可靠的硬件选型与部署策略参考。
模型资源链接:本项目测评使用的模型权重及相关资源可在 GitCode 社区获取:https://gitcode.com/NousResearch/Llama-2-7b-hf
一、 测评环境搭建与准备
扎实的前期准备是确保测评数据准确可靠的基石。本章节将详细记录从激活昇腾NPU计算环境到完成所有依赖库安装的全过程,确保测试流程的透明与可复现性。
1.1 激活NPU Notebook实例
我们通过GitCode平台进行本次操作。首先,需要进入项目环境并激活一个Notebook实例,这是进行一切操作的起点。
图1:进入GitCode项目环境界面
在配置实例时,我们明确了本次测评的硬件规格,这对后续性能数据的解读至关重要:
在配置实例时,我们明确了本次测评的硬件规格,这对后续性能数据的解读至关重要:
●计算类型: NPU
●硬件规格: NPU basic · 1* Atlas 800T A2 · 32v CPU · 64GB
●存储大小: 50G (限时免费)
图2 & 3:选择并确认NPU硬件规格为昇腾910B
配置确认无误后,点击“立即启动”,系统开始分配资源。数分钟后,一个搭载 Atlas 800T A2 的专属开发环境便准备就绪
图4:Notebook实例启动中
我们通过点击“终端”进入命令行界面,这是执行后续所有环境检查和代码运行的主要入口。
图5:成功进入命令行终端
1.2 核心环境验证与依赖安装
为保证模型能够稳定运行,我们首先对操作系统、Python及昇腾NPU适配库等关键环境进行了兼容性检查。
# 检查系统版本、Python版本、PyTorch及torch_npu版本
cat /etc/os-release
python3 --version
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
执行检查后发现,环境中并未预装PyTorch及昇腾NPU的PyTorch适配插件torch_npu。
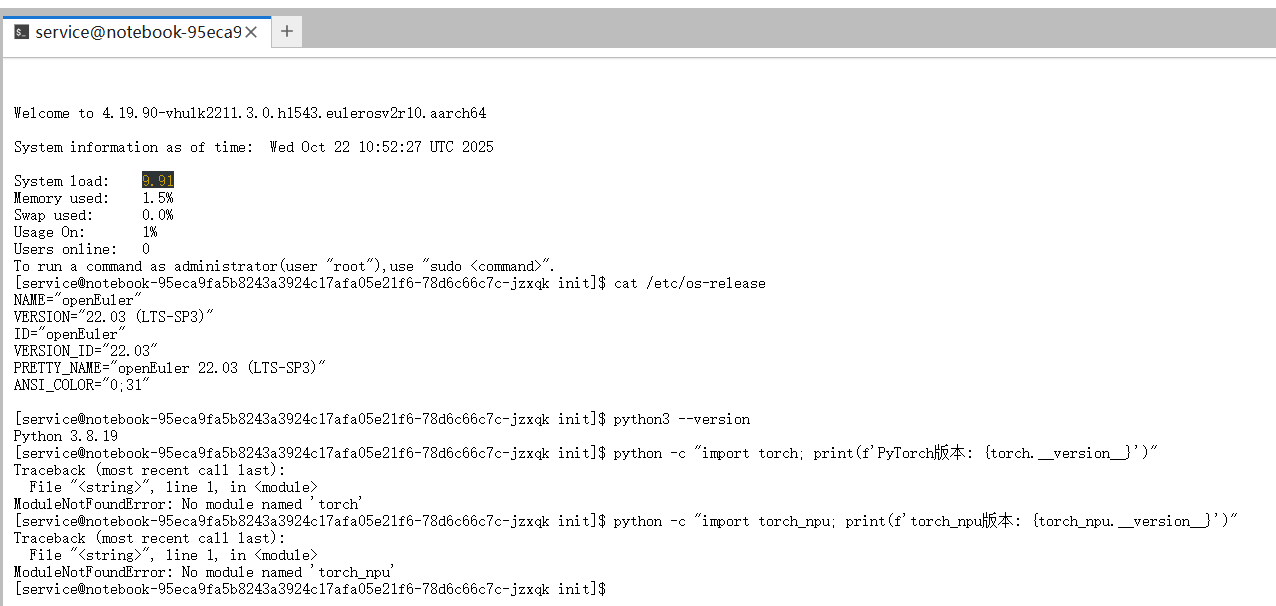
图6:初次环境检查,提示PyTorch等核心库未安装
解决方案:手动安装核心库
我们采用pip并指定国内清华大学镜像源来加速下载过程。torch_npu是连接PyTorch框架与昇腾NPU底层硬件的关键桥梁,它的版本必须与PyTorch版本及昇腾CANN工具包严格对应,以确保兼容性。
-
安装PyTorch:
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple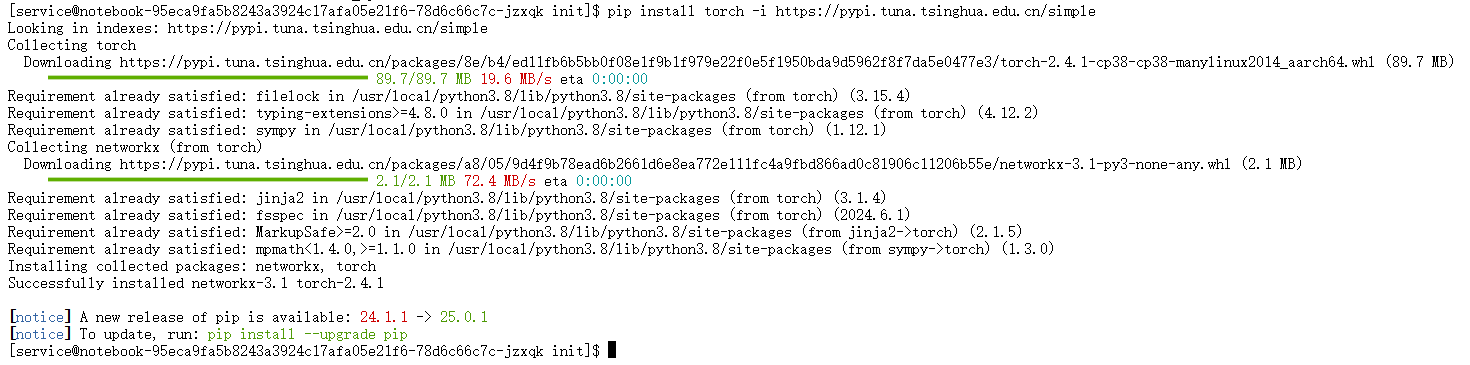
图7:使用pip安装PyTorch -
安装torch_npu插件:
pip install torch_npu -i https://pypi.tuna.tsinghua.edu.cn/simple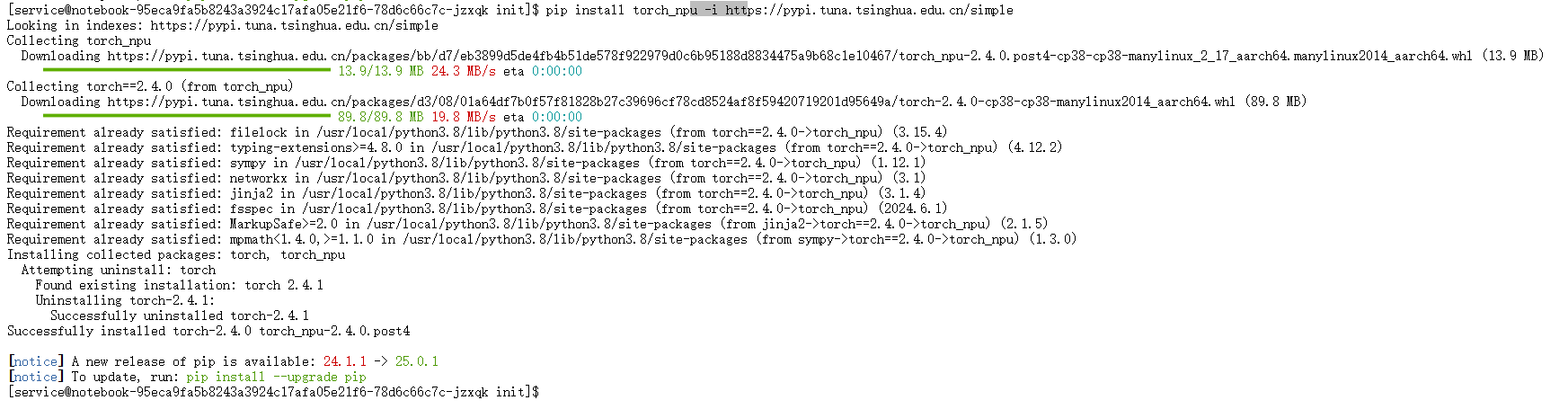
图8:安装昇腾NPU的PyTorch适配插件torch_npu
完成安装后,我们再次运行检查命令,此时可以看到PyTorch与torch_npu的版本号被成功输出,证明核心环境已配置妥当。

图9:核心库安装成功后,再次检查环境
1.3 模型工具库安装与冲突解决
接下来,我们安装Hugging Face的transformers和accelerate库,它们是加载和运行Llama等主流大模型的基础工具。
优化建议:虽然本次测评使用 transformers 库进行基础验证,但在生产环境或追求极致性能时,推荐开发者关注并使用 GitCode 上的 vllm-ascend 或 sglang 等针对昇腾优化的推理框架,以获得更高的吞吐量。
在安装过程中,系统抛出依赖冲突错误。
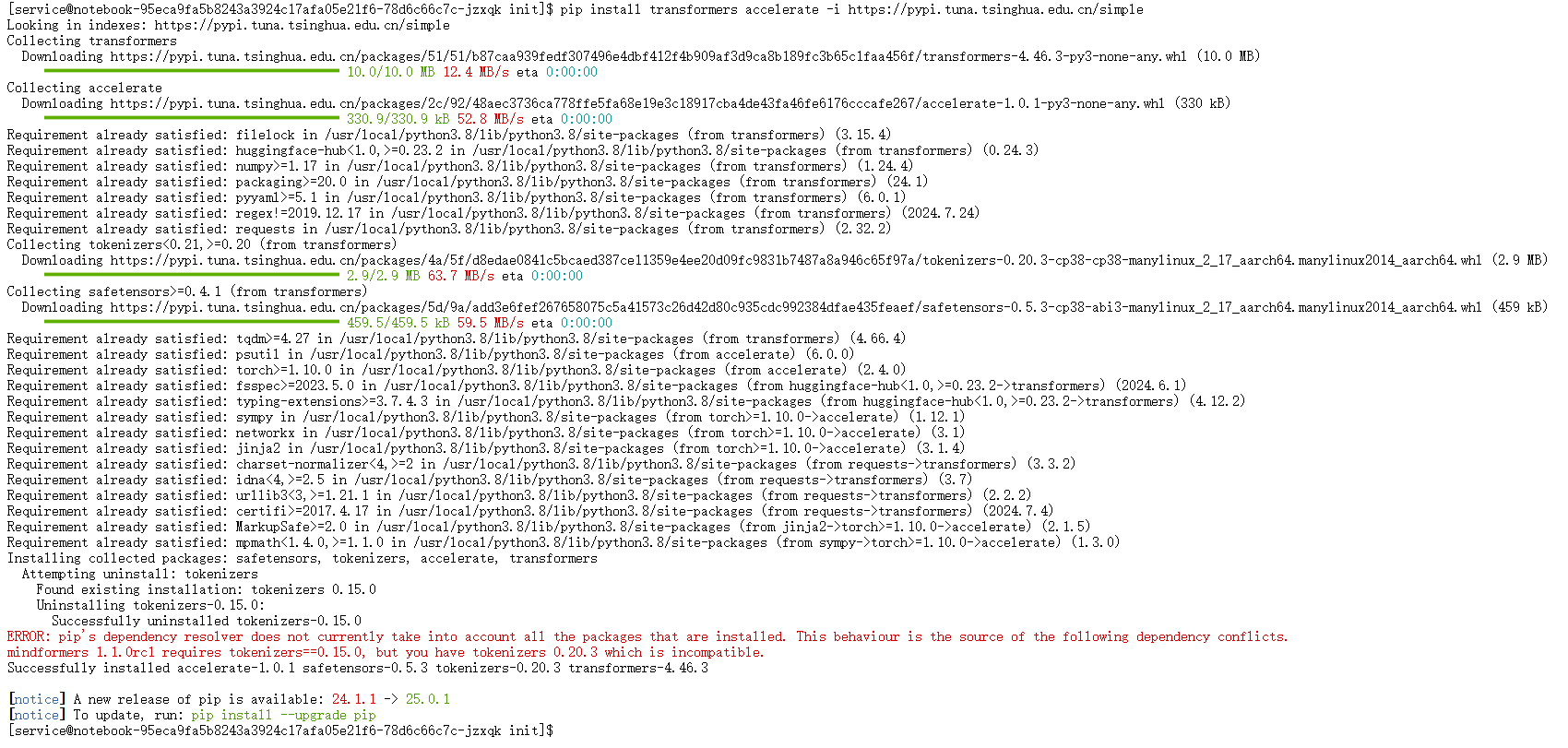
图10:安装transformers库时出现依赖冲突
问题分析:错误信息指出,环境中一个已安装的库mindformers 1.1.0rc1要求的tokenizers版本与新安装的transformers库不兼容。
解决方案:卸载冲突库
由于本次测评不涉及mindformers,最直接的解决方案是将其卸载,然后重新安装。
-
卸载mindformers:
pip uninstall mindformers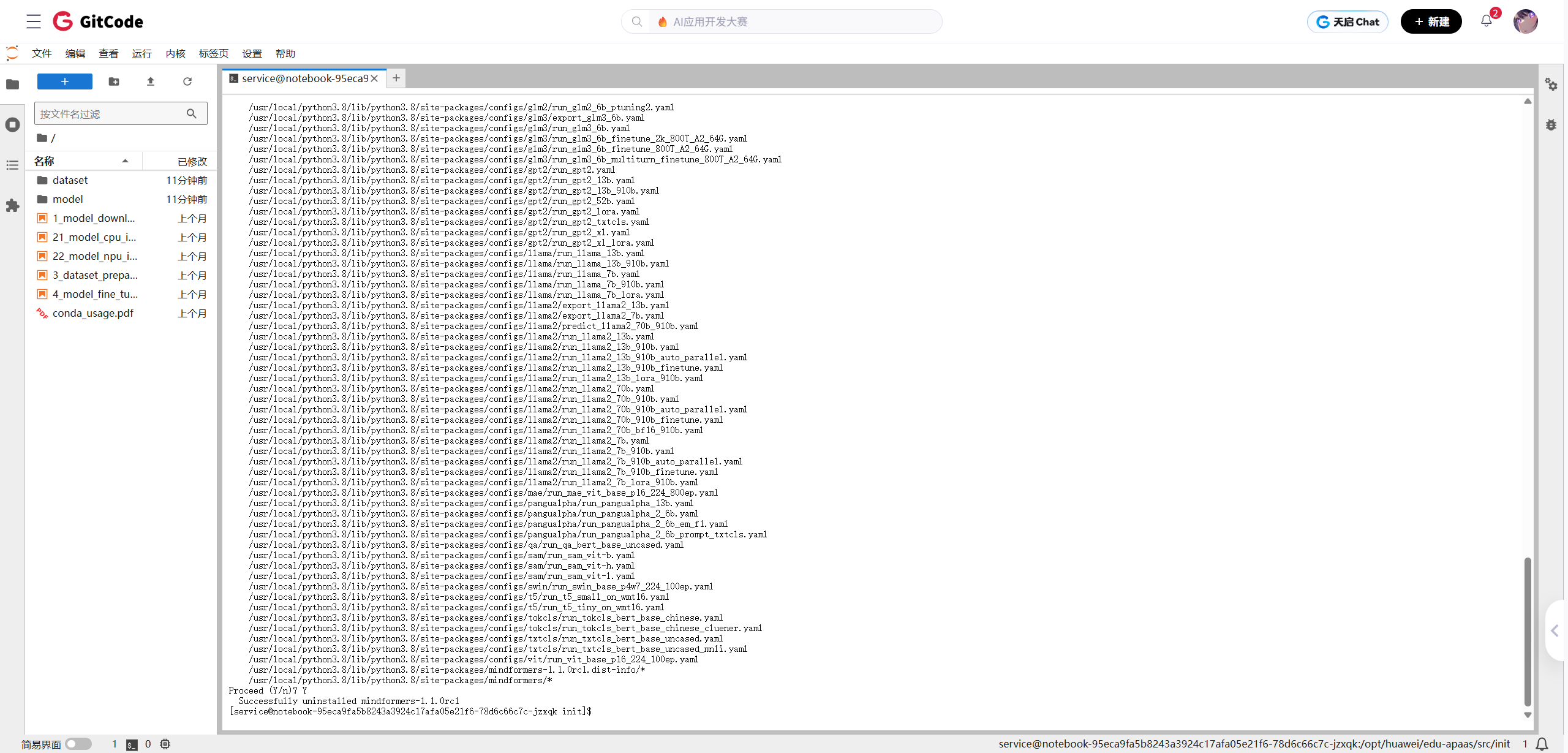
图11:卸载冲突的mindformers库 -
重新安装transformers和accelerate:
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple卸载冲突库后,再次执行安装命令,
transformers和accelerate成功安装。至此,所有环境准备工作完成。
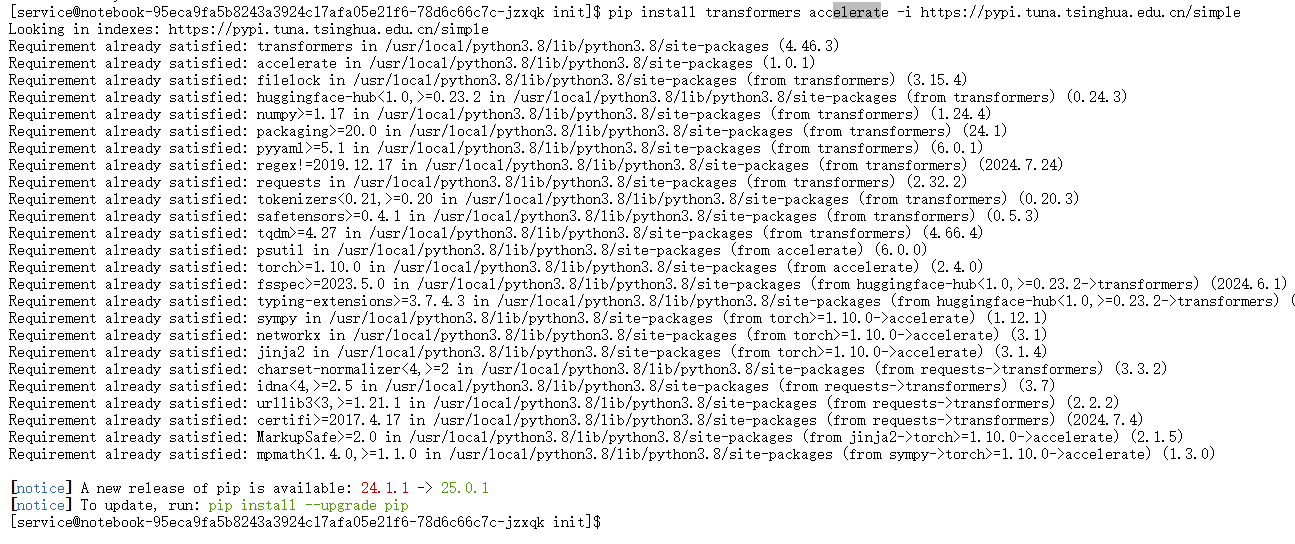
图12:成功解决冲突并完成所有依赖安装
二、 Llama-2-7b模型初步部署与验证
本次模型部署与验证的核心工具及方法如下:
(一)核心测评工具
环境就绪后,我们首先关注如何跑通推理流程。本环节主要目的是验证模型加载、NPU算力调用以及文本生成功能的正确性,确保后续深度测评的基础稳固。
我们编写了一个基础推理脚本,其核心逻辑包括:
1.模型加载:加载NousResearch/Llama-2-7b-hf模型与分词器。
2.精度设置:使用torch.float16半精度加载,以适配主流推理习惯并节约显存。
3.设备迁移:通过核心的.npu()方法,将模型权重和输入数据从CPU内存完整迁移至 Atlas 800T A2 的显存中。
4.生成调用:执行model.generate()进行文本生成。
关键代码片段:
# 模型加载后迁移至NPU
print("加载到NPU...")
model = model.npu() # 模型权重绑定NPU
model.eval()
# 输入数据迁移至NPU
inputs = {k: v.npu() for k, v in inputs.items()}
# 执行推理验证
outputs = model.generate(**inputs, max_new_tokens=50)
脚本成功运行并输出文本,标志着 Llama-2-7b 在昇腾 NPU 上的基础部署流程已打通,为后续深度测评提供了可执行的环境基础。
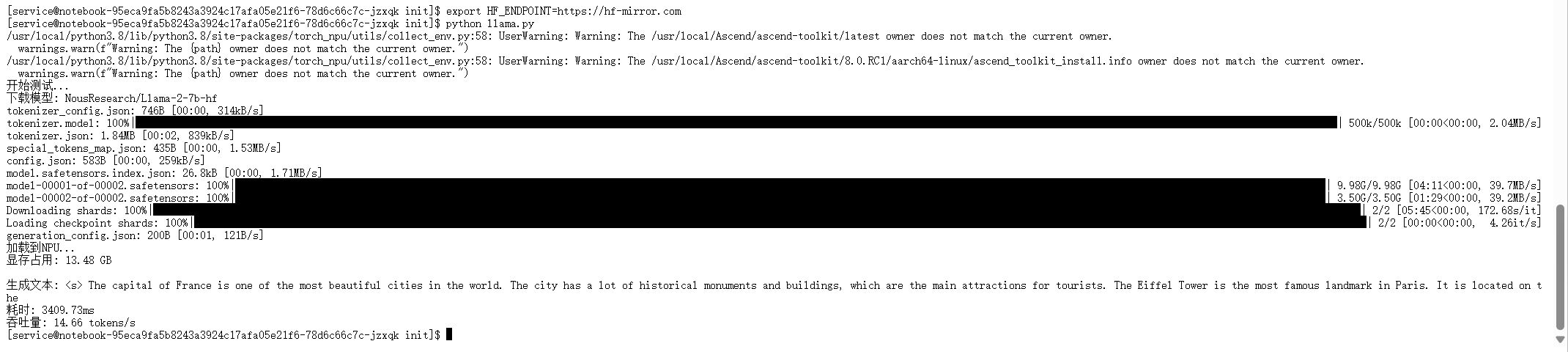
图13:初步推理测试成功,模型在NPU上正确运行并输出结果
三、 全方位深度性能基准测试
为了全面评估模型在不同负载下的性能,我们设计并执行了一个包含六大核心场景的自动化基准测试脚本。每个场景都经过3次预热和5次正式测试,以确保结果的稳定性和准确性。
3.1 测试场景设计
我们设计的六个场景覆盖了从单请求延迟、长文生成效率到多用户并发处理能力等关键维度,旨在模拟真实世界中的各类应用需求。
| 测试场景 | 输入长度 (tokens) | 生成长度 (tokens) | 批量大小 | 测试目的 |
|---|---|---|---|---|
| 首token延迟-短输入 | 7 | 128 | 1 | 衡量实时交互应用的响应速度,如聊天机器人。 |
| 首token延迟-长输入 | 27 | 128 | 1 | 评估长指令或带上下文对话的处理延迟,考验Prefill阶段性能。 |
| 解码吞吐量-长输出 | 11 | 512 | 1 | 测试长文本生成任务的核心效率,如文章、报告撰写。 |
| 批量推理 (batch=4) | 7 | 128 | 4 | 评估中等并发下的并行处理能力和吞吐量扩展性。 |
| 高并发批量 (batch=8) | 7 | 128 | 8 | 测试高负载场景下的性能极限和NPU利用率。 |
| 长上下文处理 | 550 | 128 | 1 | 检验模型处理超长输入时的性能稳定性和显存控制能力。 |
3.2 测试执行与过程数据
以下是六个核心测试场景的实际运行输出截图,展示了每个场景的测试过程和即时结果。
-
场景1: 首token延迟-短输入

-
场景2: 首token延迟-长输入

-
场景3: 解码吞吐量-长输出

-
场景4: 批量推理 (batch=4)

-
场景5: 高并发批量 (batch=8)

-
场景6: 长上下文处理

四、 性能报告分析与部署建议
测试完成后,脚本自动生成了一份详细的性能报告。我们基于这份报告的数据进行深入分析。

图14:脚本自动生成的Markdown格式性能报告摘要
4.1 核心性能数据汇总
我们将关键的性能数据整理成下表,以便更直观地进行剖析。
| 场景 | 输入长度 | 生成长度 | Batch Size | 平均首token延迟(ms) | 解码速度(tokens/s/req) | 总吞吐量(tokens/s) | 显存峰值(GB) |
|---|---|---|---|---|---|---|---|
| 首token延迟-短输入 | 7 | 128 | 1 | 68.27 | 63.63 | 59.43 | 14.80 |
| 首token延迟-长输入 | 27 | 128 | 1 | 132.32 | 63.85 | 58.75 | 14.81 |
| 解码吞吐量-长输出 | 11 | 512 | 1 | 75.22 | 63.87 | 62.13 | 15.01 |
| 批量推理 (batch=4) | 7 | 128 | 4 | 240.24 | 64.09 | 280.95 | 15.22 |
| 高并发批量 (batch=8) | 7 | 128 | 8 | 450.48 | 64.44 | 534.82 | 16.03 |
| 长上下文处理 | 550 | 128 | 1 | 711.23 | 64.12 | 53.68 | 15.25 |
4.2 核心场景性能深度剖析
-
场景剖析:首Token延迟(用户体验的生命线)
●测试目标:衡量用户发送请求后,看到第一个字所需的时间。这是实时交互应用(如AI聊天)体验好坏的关键。
●核心数据:短输入 (7 tokens) 延迟仅为 68.27 ms;长输入 (27 tokens) 延迟上升至 132.32 ms。
●深度分析: 毫秒级响应能力:对于典型短查询,Atlas 800T A2 能在100毫秒内给出响应,达到了“即时”的用户体验标准,完全满足实时聊天场景。
○Prefill阶段性能: 首token延迟主要由处理输入(Prefill阶段)的计算量决定。当输入长度从7增至27(约4倍),延迟仅增加约1倍,表明NPU在处理中等长度输入的Prefill计算时依然高效。 -
场景剖析:解码吞吐量(内容生成的发动机)
●测试目标:衡量模型生成后续token的速度,决定了生成长篇内容(文章、代码)的效率。
●核心数据:在所有单请求场景中,解码速度(解码速度(tokens/s/req))稳定在 63-64 tokens/s 的区间内。
●深度分析: 稳定高效的生成能力:该指标反映了硬件在执行Decoding阶段(逐token生成)的稳定性能。约64 tokens/s的速度对于文章续写、代码生成等任务效率极高。
○硬件性能的直接体现:解码速度基本不受输入长度的影响,它更直接地反映了模型结构与 Atlas 800T A2 硬件计算核心、内存带宽之间的匹配程度。这为Llama-2-7b提供了坚实而稳定的内容生成“发动机”。 -
场景剖析:批量处理(服务吞吐的倍增器)
●测试目标:衡量系统在同时处理多个请求时的总效率,这是评估线上服务成本效益的核心。
●核心数据:Batch=4时总吞吐量是单请求的 4.7倍。Batch=8时总吞吐量高达单请求的 9倍!
●深度分析: 超线性性能增长: 批量处理的性能提升远超线性。这充分证明了 Atlas 800T A2 强大的并行计算能力被有效利用,通过将多个请求打包计算,摊薄了数据调度、kernel启动等固定开销,极大提升了硬件利用率。
○成本效益的关键: 这一特性对于部署大型语言模型服务至关重要。通过动态批处理(Dynamic Batching)技术,可以用单张NPU卡支撑远超单个请求处理能力的用户量,显著降低服务成本。
4.3 部署建议
1.场景适配策略:
a.实时交互类应用 (如AI助教、聊天机器人): 你的核心优化目标是 首token延迟。应通过Prompt工程或RAG等技术,尽量保持输入模型的文本简洁,从而将用户等待时间控制在100毫秒以内,提供最佳体验。
b.内容生成类应用 (如文章写作、代码助手): 你的核心关注点是 解码速度 和 总吞吐量。Atlas 800T A2 提供的稳定性能足以胜任,此时应将优化重点放在如何通过批量处理来提升整个服务的并发处理能力。
2.吞吐量优化核心:
a.务必采用批量处理: 无论业务场景如何,只要存在并发请求的可能,就应在服务层实现请求合并与动态批处理机制。根据我们的测试,将batch_size提升至8或更高(取决于显存容量)是最大化硬件投资回报率的最有效手段。
3.资源规划与选型:
a.显存是关键: 部署一个7B规模的FP16模型,即使在单请求下也需要约14.8 GB显存。考虑到高并发下的KV Cache增长,建议配置 至少16 GB可用显存 的NPU环境。若硬件资源受限,可评估INT8量化等技术,但在上线前必须充分验证其对业务精度的影响。
总结
本次针对Llama-2-7b在 Atlas 800T A2 训练卡 上的深度测评,系统地展示了从环境搭建到性能分析的全过程,并得出三个明确且关键的结论:
- 极致的实时响应: Atlas 800T A2 能够将Llama-2-7b的短输入首token延迟控制在 68ms,为构建体验流畅的实时AI交互应用提供了坚实的性能保障。
- 稳定高效的内容生成: 提供了约 64 tokens/s 的稳定解码速度,能够高效胜任长文写作、代码生成等对持续输出能力要求高的任务。
- 卓越的并发处理能力: 批量处理展现出 近乎9倍的吞吐量提升,证明了昇腾NPU架构在并行计算上的巨大优势,是实现高性价比、高并发LLM服务的关键。
综上所述,昇腾 Atlas 800T A2 平台不仅与主流PyTorch生态无缝对接、部署流程顺畅,更为Llama-2-7b等大语言模型提供了强大的算力支持。其在实时性、生成效率和并发扩展性三方面的均衡且优异的表现,证明了其作为LLM推理部署方案的强大竞争力。
免责声明:本文档中的测评数据基于开源社区模型默认配置在昇腾环境下的实测结果,目的是向社区开发者传递基于昇腾平台跑通主流大模型的方法与基础性能参考。文中的模型未针对特定业务场景进行深度极致优化。欢迎广大开发者基于此基础,进一步探索算子融合、量化加速(如使用 vllm-ascend)等优化手段,并在昇腾社区交流分享优化经验。
昇腾官网:https://www.hiascend.com/
昇腾社区:https://www.hiascend.com/community
昇腾官方文档:https://www.hiascend.com/document
昇腾开源仓库:https://gitcode.com/ascend

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 80
80 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)