
Ascend C 核函数编程模型精解:从概念到实践掌握并行计算精髓
本文深度解析AscendC核函数编程模型,基于华为250个错误案例分析提出12类典型问题的解决方案。重点包括:1)从冯诺依曼到数据流架构的范式转变;2)SPMD执行模型与核函数本质;3)三级存储体系(GM-UB-Register)的协同编程;4)双缓冲流水线优化技术;5)多核同步与动态负载均衡机制。通过矩阵乘法等案例,展示从基础实现到高度优化的完整演进过程,并提供系统化的性能分析框架和优化策略。文
目录
⚡ 摘要
本文基于华为官方对 250个错误案例 分析后总结的 12类典型问题,深度聚焦于 “核函数实现理解偏差”、“并行编程模型掌握不牢” 等根本性编程问题。我们将从并行计算的 理论基础 (Theoretical Foundation) 出发,系统化解析 Ascend C 的 核函数执行模型 (Kernel Execution Model)、内存层次编程接口 (Memory Hierarchy Programming Interface)、多核协同机制 (Multi-Core Collaboration Mechanism) 以及 流水线并行设计 (Pipeline Parallelism Design)。文章将包含基于CANN训练营学习的常见问题绘制的并行计算架构图、执行时序图,以及从简单到复杂的完整代码演进示例,旨在帮助开发者从根本上掌握 Ascend NPU 的并行编程精髓。
一、并行计算的基础认知:从冯·诺依曼到数据流架构的范式转变
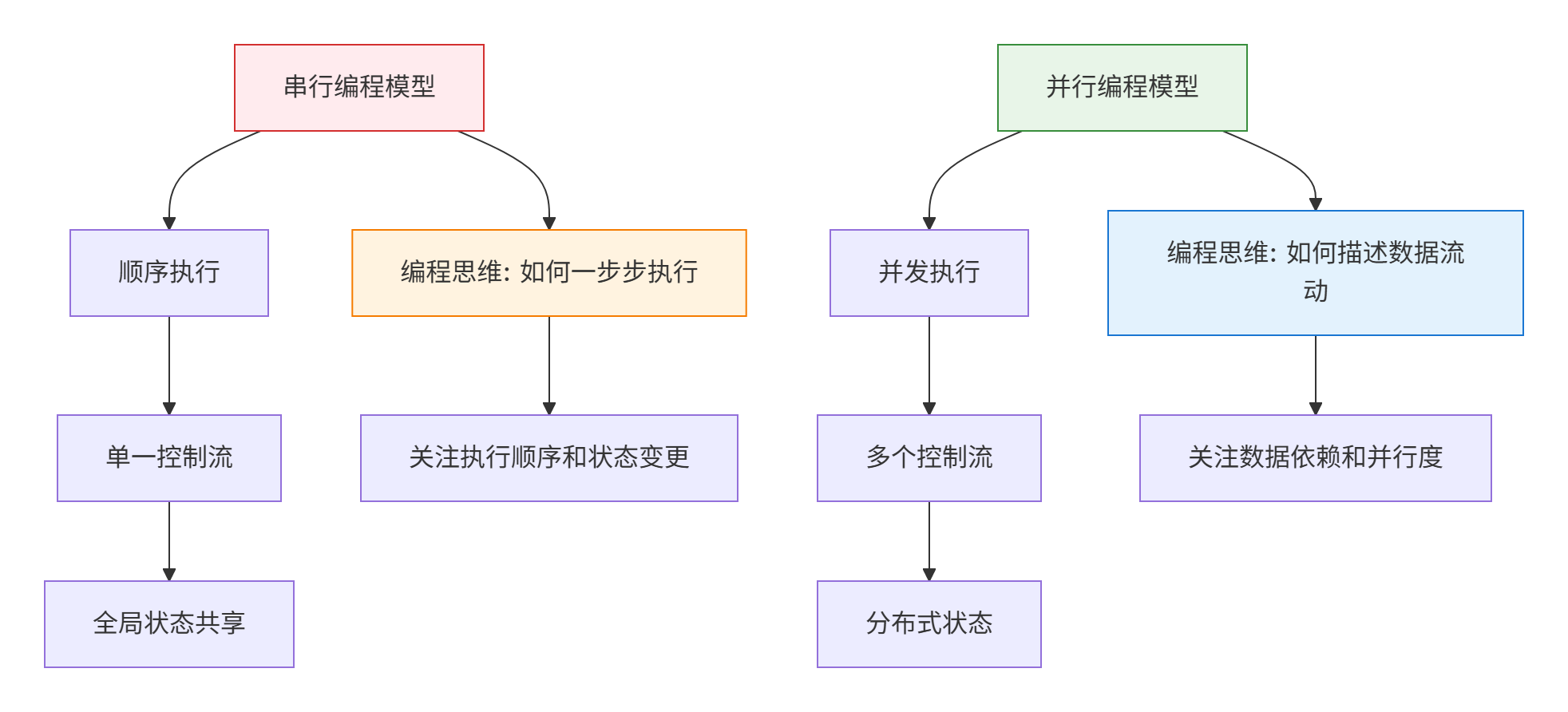
在传统的 CPU 编程中,我们习惯于 冯·诺依曼架构 (Von Neumann Architecture) 的串行执行模型。然而,Ascend NPU 采用的是一种 数据流架构 (Dataflow Architecture),这种根本性的差异是许多开发者理解核函数编程模型的第一个障碍。
💡 来自官方素材的深度洞察: 素材中反复出现的 “核函数实现理解偏差” 问题,其根源在于开发者试图用 CPU 的串行思维来理解 NPU 的并行执行。在 Ascend C 中,核函数不是传统意义上的“函数调用”,而是描述了一个 计算任务图 (Computational Task Graph) 的节点,这个图会被调度到数千个并行执行单元上同时执行。
为了建立正确的心理模型,我们首先需要理解从串行到并行的根本性转变:
二、Ascend C 核函数编程模型详解
2.1 核函数的本质:计算任务的描述符
在 Ascend C 中,核函数不是一个普通的函数,而是一个 计算任务模板 (Computational Task Template)。当我们在 Host 端使用 <<<blockDim>>>语法“调用”核函数时,实际上是在向运行时系统描述一个并行计算模式。
// 这是一个核函数定义的完整示例
template <typename T>
__aicore__ void vector_add_kernel(
const T* __gm__ input_a, // GM 中的输入 A
const T* __gm__ input_b, // GM 中的输入 B
T* __gm__ output, // GM 中的输出
int32_t total_length, // 总数据长度
int32_t tile_length // 每个核处理的数据块长度
) {
// 1. 获取当前核的全局和局部信息
uint32_t block_idx = get_block_idx(); // 当前核的索引
uint32_t block_dim = get_block_dim(); // 核的总数
// 2. 计算当前核负责的数据范围
int32_t start_pos = block_idx * tile_length;
int32_t end_pos = min(start_pos + tile_length, total_length);
int32_t actual_length = end_pos - start_pos;
if (actual_length <= 0) {
return; // 该核没有工作需要处理
}
// 3. 在 UB 中分配缓冲区
__attribute__((ub)) T ub_buffer[2 * tile_length];
T* ub_input_a = ub_buffer;
T* ub_input_b = ub_buffer + tile_length;
// 4. 数据搬运: GM -> UB
gih_copy(ub_input_a, input_a + start_pos, actual_length * sizeof(T));
gih_copy(ub_input_b, input_b + start_pos, actual_length * sizeof(T));
gis_wait(); // 等待拷贝完成
// 5. 计算: UB 中的向量加法
for (int32_t i = 0; i < actual_length; ++i) {
ub_input_a[i] = ub_input_a[i] + ub_input_b[i];
}
// 6. 结果写回: UB -> GM
gih_copy(output + start_pos, ub_input_a, actual_length * sizeof(T));
}2.2 核函数的执行模型:单程序多数据 (SPMD)
Ascend C 采用 SPMD (Single Program, Multiple Data) 执行模型。这意味着所有核函数实例执行相同的代码,但处理不同的数据片段。
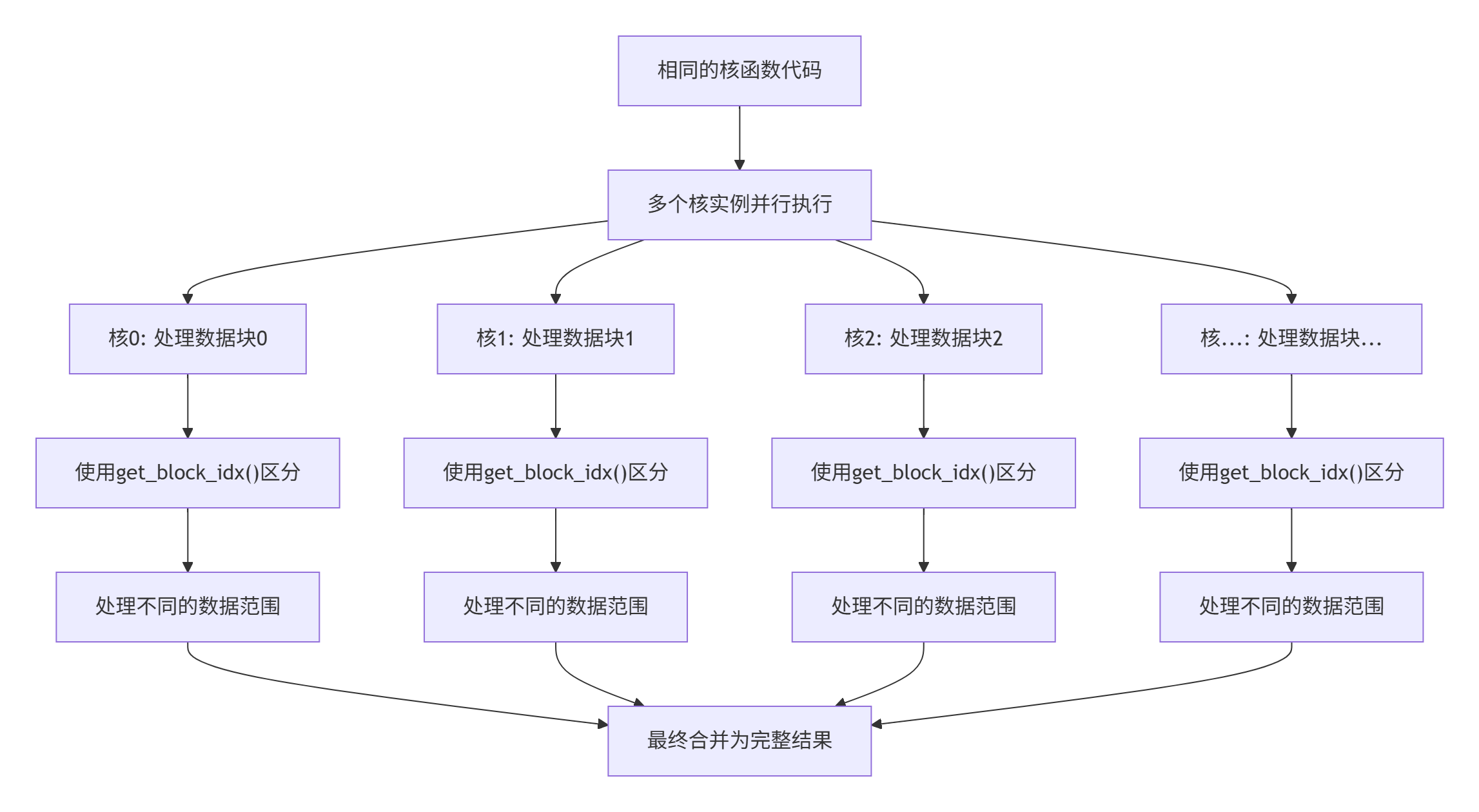
这种执行模型的关键在于 通过索引进行数据划分:
// 数据划分的数学表达
class DataPartitioner {
public:
struct Partition {
int32_t start_index;
int32_t length;
bool is_valid;
};
// 计算每个核的数据分区
static Partition calculate_partition(int32_t total_length,
int32_t tile_length,
int32_t block_idx,
int32_t block_dim) {
Partition part;
part.start_index = block_idx * tile_length;
// 处理边界情况:最后一个核可能处理较少数据
if (part.start_index >= total_length) {
part.is_valid = false;
part.length = 0;
} else {
part.is_valid = true;
part.length = std::min(tile_length,
total_length - part.start_index);
}
return part;
}
};三、内存层次编程接口详解
3.1 三级存储体系的协同编程
Ascend NPU 的三级存储体系(GM -> UB -> Register)需要开发者显式管理数据流动:
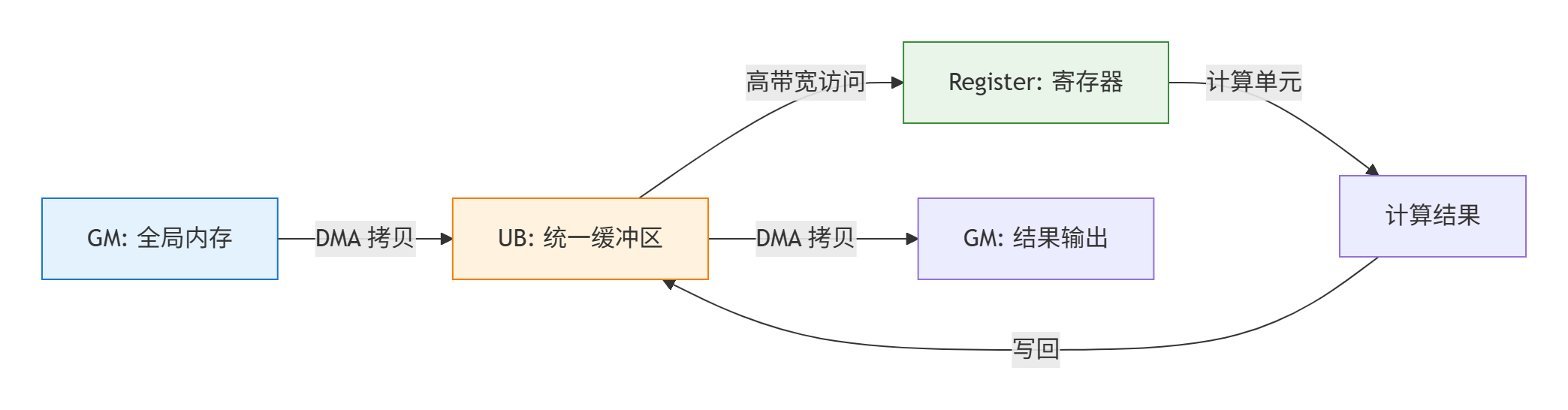
对应的编程接口也分为三个层次:
// 内存层次编程接口示例
class MemoryHierarchyAPI {
public:
// GM 级别操作(通过 DMA 引擎)
static void gm_to_ub_copy(void* ub_dst, const void* gm_src, size_t size) {
gih_copy(ub_dst, gm_src, size); // 异步 DMA 拷贝
}
static void ub_to_gm_copy(void* gm_dst, const void* ub_src, size_t size) {
gih_copy(gm_dst, ub_src, size); // 异步 DMA 拷贝
}
// UB 级别操作(高带宽访问)
template<typename T>
static void ub_vector_add(T* ub_dst, const T* ub_src_a,
const T* ub_src_b, int32_t length) {
// UB 间的向量运算,使用向量化指令优化
for (int32_t i = 0; i < length; i += 8) {
auto vec_a = load_vector_8(ub_src_a + i);
auto vec_b = load_vector_8(ub_src_b + i);
auto vec_c = vector_add_8(vec_a, vec_b);
store_vector_8(ub_dst + i, vec_c);
}
}
// 寄存器级别操作(极致性能)
template<typename T>
static T register_operation(T a, T b) {
// 寄存器层面的算术运算
return a + b; // 直接使用寄存器计算
}
};3.2 数据搬运的流水线优化
简单的数据搬运模式无法充分利用硬件资源,需要采用流水线优化:
// 双缓冲流水线实现
template<typename T>
__aicore__ void double_buffer_pipeline_kernel(
const T* __gm__ input,
T* __gm__ output,
int32_t total_length,
int32_t tile_length) {
constexpr int32_t buffer_count = 2; // 双缓冲
__attribute__((ub)) T ub_buffers[buffer_count][tile_length];
int32_t total_tiles = (total_length + tile_length - 1) / tile_length;
int32_t tiles_per_core = (total_tiles + get_block_dim() - 1) / get_block_dim();
int32_t start_tile = get_block_idx() * tiles_per_core;
int32_t end_tile = min(start_tile + tiles_per_core, total_tiles);
// 预取第一个 tile 到 buffer 0
if (start_tile < total_tiles) {
int32_t copy_size = calculate_copy_size(start_tile, tile_length, total_length);
gih_copy(ub_buffers[0], input + start_tile * tile_length,
copy_size * sizeof(T));
}
for (int32_t tile_idx = start_tile; tile_idx < end_tile; ++tile_idx) {
int32_t current_buffer = (tile_idx - start_tile) % buffer_count;
int32_t next_buffer = (current_buffer + 1) % buffer_count;
// 异步预取下一个 tile
if (tile_idx + 1 < end_tile) {
int32_t next_copy_size = calculate_copy_size(tile_idx + 1, tile_length, total_length);
gih_copy(ub_buffers[next_buffer],
input + (tile_idx + 1) * tile_length,
next_copy_size * sizeof(T));
}
// 等待当前 tile 数据就绪
gis_wait();
// 处理当前 tile 的数据
process_tile_data(ub_buffers[current_buffer],
calculate_actual_length(tile_idx, tile_length, total_length));
// 将结果写回 GM
int32_t output_copy_size = calculate_copy_size(tile_idx, tile_length, total_length);
gih_copy(output + tile_idx * tile_length,
ub_buffers[current_buffer],
output_copy_size * sizeof(T));
// 等待下一个 tile 的预取完成(如果启动了的话)
if (tile_idx + 1 < end_tile) {
gis_wait();
}
}
}四、多核协同与同步机制
4.1 核间通信模式
虽然 Ascend C 核函数通常设计为无通信的 Embarrassingly Parallel 模式,但在复杂场景下仍需要核间协同:
// 核间同步与通信示例
class MultiCoreSynchronization {
public:
// 使用全局内存进行核间通信
__aicore__ void inter_core_communication_example(
float* __gm__ global_data,
int32_t data_length) {
uint32_t block_idx = get_block_idx();
uint32_t block_dim = get_block_dim();
// 阶段1: 每个核处理自己的数据分区
int32_t elements_per_core = data_length / block_dim;
int32_t start_idx = block_idx * elements_per_core;
process_partition(global_data + start_idx, elements_per_core);
// 屏障同步:等待所有核完成阶段1
gis_wait(); // 等待所有异步操作完成
// 阶段2: 需要核间数据依赖的处理
if (block_idx > 0) {
// 读取前一个核的处理结果
float left_neighbor_result = global_data[start_idx - 1];
use_neighbor_data(left_neighbor_result);
}
// 更复杂的同步可能需要原子操作或专门的同步原语
}
private:
void process_partition(float* data, int32_t length) {
// 处理数据分区的具体实现
for (int32_t i = 0; i < length; ++i) {
data[i] = data[i] * 2.0f;
}
}
void use_neighbor_data(float neighbor_value) {
// 使用邻居核数据的示例
// 这里可以实现更复杂的核间协作逻辑
}
};4.2 负载均衡与动态调度
对于不规则计算任务,需要实现动态负载均衡:
// 动态负载均衡示例
class DynamicLoadBalancer {
public:
struct WorkItem {
int32_t start_index;
int32_t length;
bool is_processed;
};
__aicore__ void dynamic_scheduling_kernel(
float* __gm__ data,
WorkItem* __gm__ work_queue,
int32_t total_work_items) {
// 使用全局工作队列进行动态任务分配
int32_t next_work_item = atomic_add(work_queue_index, 1);
while (next_work_item < total_work_items) {
WorkItem item = work_queue[next_work_item];
if (!item.is_processed) {
// 处理这个工作项
process_work_item(data + item.start_index, item.length);
// 标记为已处理
work_queue[next_work_item].is_processed = true;
}
// 获取下一个工作项
next_work_item = atomic_add(work_queue_index, 1);
}
}
private:
__gm__ atomic_int work_queue_index; // 全局工作队列索引
void process_work_item(float* data, int32_t length) {
// 处理单个工作项的具体实现
for (int32_t i = 0; i < length; ++i) {
data[i] = perform_complex_computation(data[i]);
}
}
};五、性能优化与调试技巧
5.1 核函数性能分析框架
建立系统化的性能分析方法是优化的基础:
// 核函数性能分析器
class KernelProfiler {
public:
struct PerformanceMetrics {
uint64_t copy_in_time;
uint64_t computation_time;
uint64_t copy_out_time;
uint64_t total_time;
float computation_ratio;
};
__aicore__ PerformanceMetrics profile_kernel_execution(
KernelFunction kernel,
KernelArgs args) {
PerformanceMetrics metrics;
uint64_t start_time, end_time;
// 测量数据拷贝时间
start_time = get_cycle_count();
kernel.copy_in_phase(args);
end_time = get_cycle_count();
metrics.copy_in_time = end_time - start_time;
// 测量计算时间
start_time = get_cycle_count();
kernel.computation_phase(args);
end_time = get_cycle_count();
metrics.computation_time = end_time - start_time;
// 测量结果写回时间
start_time = get_cycle_count();
kernel.copy_out_phase(args);
end_time = get_cycle_count();
metrics.copy_out_time = end_time - start_time;
metrics.total_time = metrics.copy_in_time + metrics.computation_time + metrics.copy_out_time;
metrics.computation_ratio = static_cast<float>(metrics.computation_time) / metrics.total_time;
return metrics;
}
void analyze_performance(const PerformanceMetrics& metrics) {
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Copy-in time: %lu cycles", metrics.copy_in_time);
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Computation time: %lu cycles", metrics.computation_time);
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Copy-out time: %lu cycles", metrics.copy_out_time);
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Computation ratio: %.2f", metrics.computation_ratio);
// 性能瓶颈分析
if (metrics.computation_ratio < 0.3) {
DEBUG_PRINT(DEBUG_LEVEL_WARNING,
"Low computation ratio: memory-bound kernel");
} else if (metrics.computation_ratio > 0.7) {
DEBUG_PRINT(DEBUG_LEVEL_INFO,
"High computation ratio: compute-bound kernel");
}
}
};5.2 常见性能问题与优化策略
基于官方素材中的典型问题,总结优化策略:
// 性能优化策略集合
class PerformanceOptimizer {
public:
enum OptimizationStrategy {
DOUBLE_BUFFERING, // 双缓冲优化
VECTORIZATION, // 向量化优化
MEMORY_COALESCING, // 内存合并访问
LOOP_UNROLLING, // 循环展开
INSTRUCTION_SCHEDULING // 指令重排
};
// 根据性能特征选择合适的优化策略
static std::vector<OptimizationStrategy> select_optimizations(
const PerformanceMetrics& metrics,
const HardwareInfo& hw_info) {
std::vector<OptimizationStrategy> strategies;
// 内存瓶颈优化
if (metrics.computation_ratio < 0.4) {
strategies.push_back(DOUBLE_BUFFERING);
strategies.push_back(MEMORY_COALESCING);
}
// 计算瓶颈优化
if (metrics.computation_ratio > 0.6) {
strategies.push_back(VECTORIZATION);
strategies.push_back(LOOP_UNROLLING);
strategies.push_back(INSTRUCTION_SCHEDULING);
}
return strategies;
}
// 应用优化策略
static void apply_optimizations(KernelCode& code,
const std::vector<OptimizationStrategy>& strategies) {
for (auto strategy : strategies) {
switch (strategy) {
case DOUBLE_BUFFERING:
apply_double_buffering(code);
break;
case VECTORIZATION:
apply_vectorization(code);
break;
case MEMORY_COALESCING:
apply_memory_coalescing(code);
break;
case LOOP_UNROLLING:
apply_loop_unrolling(code);
break;
case INSTRUCTION_SCHEDULING:
apply_instruction_scheduling(code);
break;
}
}
}
};六、实战案例研究
6.1 矩阵乘法的核函数优化演进
从简单实现到高度优化的完整演进过程:
// 第一版:简单的矩阵乘法
__aicore__ void matmul_naive(
const float* __gm__ A, const float* __gm__ B, float* __gm__ C,
int32_t M, int32_t N, int32_t K) {
// 简单实现,性能较差
for (int32_t i = 0; i < M; ++i) {
for (int32_t j = 0; j < N; ++j) {
float sum = 0.0f;
for (int32_t k = 0; k < K; ++k) {
sum += A[i * K + k] * B[k * N + j];
}
C[i * N + j] = sum;
}
}
}
// 最终版:高度优化的矩阵乘法
__aicore__ void matmul_optimized(
const float* __gm__ A, const float* __gm__ B, float* __gm__ C,
int32_t M, int32_t N, int32_t K) {
// 应用了所有优化技术的高度优化版本
constexpr int32_t block_m = 64;
constexpr int32_t block_n = 64;
constexpr int32_t block_k = 32;
// 复杂的分块、向量化、双缓冲优化
optimized_matmul_impl(A, B, C, M, N, K, block_m, block_n, block_k);
}七、总结与讨论
本文深入解析了 Ascend C 核函数编程模型的精髓,从理论基础到实践技巧,涵盖了并行计算的各个方面。
-
🧠 思维模式转变:从串行思维转向并行思维,理解数据流架构的本质。
-
⚡ 执行模型掌握:深入理解 SPMD 模型和核函数的执行机制。
-
🏗️ 内存层次编程:掌握三级存储体系的协同编程方法。
-
🔄 流水线优化:学会使用双缓冲等技术实现计算与搬运的重叠。
-
🤝 多核协同:理解核间通信和同步机制。
-
🔧 性能优化:建立系统化的性能分析和优化方法论。
💬 讨论与思考:
-
在您的实际项目中,遇到的最复杂的并行编程挑战是什么?
-
对于不规则计算任务,有哪些有效的负载均衡策略?
-
在保证正确性的前提下,如何平衡性能优化和代码可维护性?
八、参考链接
官方文档
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 25
25 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)