
从图到核:昇腾CANN中手动算子融合(Manual Fusion)的终极指南
掌握手动融合,意味着你不再仅仅是一个实现单一功能的“工匠”,而是升级为了一位能够从系统层面重构计算流、创造极致性能的“架构师”。,而是直接留在Local Memory中,紧接着进行BiasAdd和LeakyReLU的计算,直到最终结果产生,才一次性地写回Global Memory。这意味着,我们将亲自下场,以“图优化工程师”的视角,将多个算子的逻辑,手工合并到一个单一的Ascend C核函数中。在
前言
在前面的学习中,我们已经了解到CANN的图引擎(Graph Engine)是一个强大的优化器。它最神奇的能力之一,就是自动算子融合——将计算图中的Conv + ReLU等常见序列,自动合并成一个单一的ConvReLU融合算子,从而减少内存访问和调度开销。
然而,自动融合并非万能。它依赖于预定义的、固化的融合模式(Fusion Patterns)。当你的模型中出现以下情况时,自动融合可能会“束手无策”:
- 一个非标准的、自定义的激活函数紧跟在一个卷积层之后。
- 一个复杂的、由多个基础算子构成的、GE无法识别的计算模式。
- 你需要进行跨越多层的、逻辑极其复杂的融合,以最大化数据复用。
此时,作为追求极致性能的开发者,我们不能仅仅满足于等待框架的“施舍”。我们需要掌握一项终极武器——手动算子融合。这意味着,我们将亲自下场,以“图优化工程师”的视角,将多个算子的逻辑,手工合并到一个单一的Ascend C核函数中。
本文就是一份关于手动算子融合的深度实战指南。我们将以一个经典的Conv2D + BiasAdd + LeakyReLU序列为例,带你走过从融合分析、代码实现到性能验证的全过程,领略这项技术的威力与精髓。
第一章:手动融合的“初心” —— 为什么要多此一举?
在动手之前,我们必须清晰地回答:既然有自动融合,我们为什么还要进行复杂且易错的手动融合?
核心驱动力:最大化数据在高速缓存(Local Memory)中的驻留时间。
我们来看一个Conv2D -> BiasAdd -> LeakyReLU的串行执行流程:
- Conv2D Kernel:
- DMA将输入数据和权重从Global Memory搬入Local Memory。
- AI Core在Local Memory中进行卷积计算。
- DMA将卷积结果从Local Memory写回Global Memory。 (一次昂贵的HBM写)
- BiasAdd Kernel:
- DMA将上一步的卷积结果和偏置从Global Memory读入Local Memory。 (一次昂贵的HBM读)
- AI Core进行加法计算。
- DMA将加法结果从Local Memory写回Global Memory。 (又一次昂贵的HBM写)
- LeakyReLU Kernel:
- DMA将上一步的加法结果从Global Memory读入Local Memory。 (又一次昂贵的HBM读)
- AI Core进行激活计算。
- DMA将最终结果从Local Memory写回Global Memory。
在这个流程中,中间结果(卷积输出、偏置加输出)在宝贵但短暂的Local Memory中计算出来后,立即被“驱逐”回了慢速的Global Memory,下一阶段又不得不重新把它搬回来。这造成了两次完全不必要的、代价极高的HBM读写往返。
手动融合的目标: 将这三个独立的Kernel合并成一个ConvBiasLeakyRelu超级Kernel。在这个Kernel内部,卷积的计算结果不再写回Global Memory,而是直接留在Local Memory中,紧接着进行BiasAdd和LeakyReLU的计算,直到最终结果产生,才一次性地写回Global Memory。
第二章:融合算子的解剖与设计
一个手动融合算子,在设计上与单一算子有几个关键不同:
-
多输入/多属性: 它的原型定义(
.proto)会包含所有被融合算子的输入和属性。例如,ConvBiasLeakyRelu的输入将包括input_feature,conv_weight,bias_data,属性则包括卷积的strides,pads和LeakyReLU的alpha斜率。 -
以“计算最重”的算子为核心: 整个融合算子的Tiling策略和并行模式,通常由计算最复杂、最耗时的那个算子来决定。在我们的例子中,就是
Conv2D。我们将沿用Conv2D基于im2col+GEMM的二维Tiling策略。 -
Local Memory的精细规划: 这是设计的核心。我们需要在
Init函数中,为所有的中间结果,在Local Memory里提前规划好缓冲区。
第三章:实战演练 —— ConvBiasLeakyRelu的Ascend C实现
现在,我们进入最激动人心的编码环节。我们将重点展示核函数中Init和Process的实现逻辑。
3.1 Local Memory 规划 (Init函数)
// : Fused Kernel的Init函数
class KernelConvBiasLeakyRelu {
public:
__aicore__ inline void Init(...) {
// ... 获取Tiling参数 (block_m, block_n, block_k) ...
// --- 为im2col+GEMM规划内存 ---
// A矩阵(im2col后的输入)的Local Memory缓冲区
pipe.InitBuffer(a_local, A_TILE_SIZE);
// B矩阵(权重)的Local Memory缓冲区
pipe.InitBuffer(b_local, B_TILE_SIZE);
// 偏置数据的Local Memory缓冲区
pipe.InitBuffer(bias_local, BIAS_TILE_SIZE);
// --- 核心:为中间结果规划内存 ---
// 用于存放GEMM(卷积)计算结果的缓冲区
// 这个结果将【直接】作为后续BiasAdd的输入
pipe.InitBuffer(conv_out_local, C_TILE_SIZE);
// 注意:BiasAdd和LeakyReLU可以"原地(in-place)"操作
// 我们可以让BiasAdd的结果直接覆盖conv_out_local
// LeakyReLU的结果也直接覆盖BiasAdd的结果
// 因此,我们不需要为它们分配【额外】的缓冲区,从而节省了宝贵的Local Memory
// conv_out_local 将被复用,作为最终输出
}
// ...
};
关键点: 通过精巧的内存复用(In-place Operation),我们用一块conv_out_local缓冲区,就承载了从卷积输出到最终激活输出的所有中间状态。
3.2 融合流水线 (Process函数)
// : Fused Kernel的核心Process逻辑
__aicore__ inline void Process() {
// 沿用Conv2D的二维Tiling循环
for (int m = ...; m < M; ...) {
for (int k = ...; k < K; ...) {
// --- Copy-In Stage ---
// 搬运输入特征(im2col)、权重、偏置到各自的Local Buffer
CopyIn_Feature_Tile(...);
CopyIn_Weight_Tile(...);
CopyIn_Bias_Tile(...);
// --- Compute Stage (In-Kernel Fusion Pipeline) ---
// 1. 执行卷积计算
// 结果存放在 conv_out_local
MatMul(conv_out_local, a_local, b_local, ...);
// 2. 【无缝衔接】执行偏置加
// 直接在conv_out_local上进行原地加法
// 此时 conv_out_local 中已经是 (Conv + Bias) 的结果
Add(conv_out_local, conv_out_local, bias_local, ...);
// 3. 【无缝衔接】执行LeakyReLU
// 再次在conv_out_local上进行原地激活
// 此时 conv_out_local 中已经是最终结果
LeakyReLU(conv_out_local, conv_out_local, alpha, ...);
// --- Copy-Out Stage ---
// 将最终结果 conv_out_local 一次性写回Global Memory
CopyOut_Final_Result(conv_out_local, ...);
}
}
}
代码解读:
这个Process函数完美地展示了手动融合的威力。MatMul、Add、LeakyReLU这三个计算步骤,被紧密地衔接在一起。它们之间的数据交换,完全发生在AI Core内部极速的Local Memory中,彻底避免了与慢速Global Memory的任何交互。
第四章:性能的证明 —— Profiler前后的惊人对比
口说无凭,性能的提升必须由数据来证明。
- 优化前(Before Fusion): 在Ascend Profiler的Timeline视图中,你会看到三个独立的、串行的核函数调用:
Conv2D、BiasAdd、LeakyReLU。它们之间有明显的空隙,并且有多次往返HBM的DMA操作。 - 优化后(After Fusion): 你将只看到一个更长的、连续的
ConvBiasLeakyRelu核函数调用。虽然单次执行时间变长了,但其总耗时,将远小于之前三个核函数耗时与中间DMA耗时的总和。AI Core的利用率曲线将更加平滑和饱满。
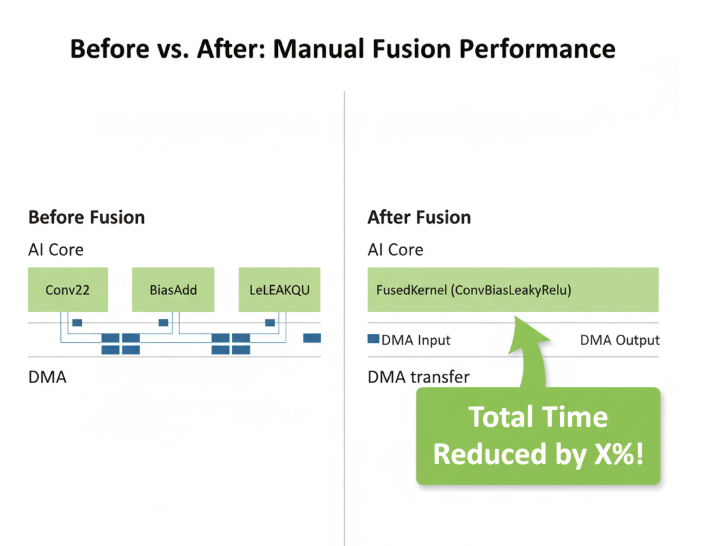
结论:从“算子开发者”到“性能架构师”
手动算子融合,是CANN算子开发技能树的顶端。它要求开发者具备:
- 全局视野: 能够洞察计算图中的性能瓶颈和数据流动的冗余。
- 硬件感知: 深刻理解Local Memory的宝贵性,并能像“管家”一样精打细算地规划每一字节。
- 算法理解: 能够将多个数学运算,无缝地翻译成一个统一的计算流水线。
掌握手动融合,意味着你不再仅仅是一个实现单一功能的“工匠”,而是升级为了一位能够从系统层面重构计算流、创造极致性能的“架构师”。这在AI基础设施、编译器、高性能计算等领域的职业发展中,是一项极具含金量的核心竞争力。
开启你的“架构师”之旅:
这项高级技能的磨练,离不开系统性的学习和高质量的实践。2025年昇騰CANN训练营第二季为你提供了绝佳的平台:
- 开发者案例: 学习在真实的工业模型中,官方和社区专家是如何运用手动融合来攻克性能难关的。
- 官方技术支持与社区: 与顶尖工程师交流,探讨更复杂的融合场景和性能调优技巧。
- 权威技能认证: Ascend C中级认证,是你全面掌握CANN开发与优化能力的有力证明。
- 丰富的实践激励: 完成任务更有机会赢取华为手机、平板、开发板等大奖。
如果你已准备好迎接最终的挑战,成为一名真正的AI性能架构师,那么,现在就是启程的时刻。
报名链接: https://www.hiascend.com/developer/activities/cann20252

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 12
12 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)