
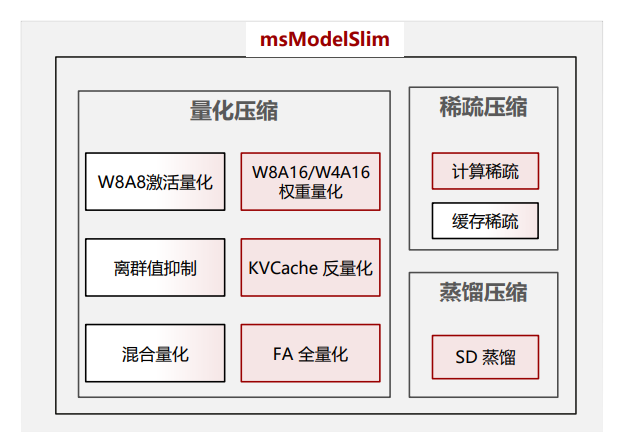
ModelSlim模型压缩工具
困难挑战:模型部署成本高,为追求50ms以内的极致性能,量化逐渐成为LLM模型的刚需工具能力:提供低成本、高精度量化的最佳实践;支持w8a8/w816/w4a16/ KVcache int8 的系统性、自动化量化压缩,精度损失<1%
·
具体内容
- ModelSlim工具概述
- ONNX-PTQ量化
- 大模型量化压缩
- 大模型稀疏权重压缩
量化的基本原理
- 向量/矩阵量化:通过缩放S和平移Z,把浮点范围的数值映射到量化的定点范围,范围和量化bit数N有关
- 向量/矩阵反量化:把量化的数值反向缩放和平移,恢复浮点范围
- 量化误差来源:量化过程中截断和取整操作后的数值无法完全还原至原来的浮点数值。浮点数值分布范围越广,量化分辨率越低,精度也越低
ModelSlim工具概述
- 困难挑战:模型部署成本高,为追求50ms以内的极致性能,量化逐渐成为LLM模型的刚需
- 工具能力:提供低成本、高精度量化的最佳实践;支持w8a8/w816/w4a16/ KVcache int8 的系统性、自动化量化压缩,精度损失<1%
ONNX-PTQ量化
- 适用场景:对于常规模型,训练后量化(Post-Training Quantization, PTQ)是一种在不重新训练模型的情况下减少模型大小并提升推理性能的技术。
- 工具能力:通过减少模型中参数和运算的精度来减小模型大小和加速模型推理。在深度学习领域,通过量化,可以将模型的权重和激活从FP16降低到更低精度,如8位整数(INT8)。保持精度前提下,可以实现CV典型模型性能平均提升 40%+
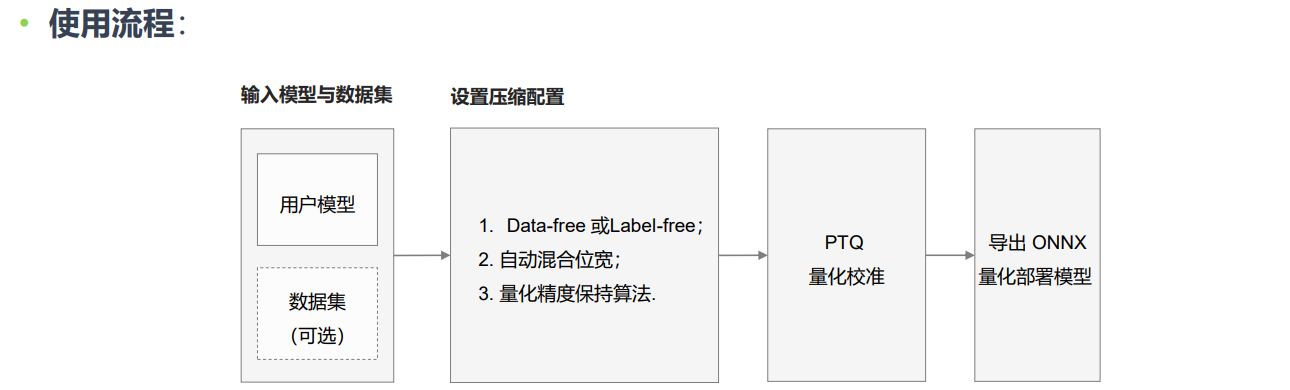
ONNX-PTQ量化使用
- 量化模式:ONNX模型的量化可以采用Label-Free或Data-Free模式。在Label-Free模式下,量化过程需要少量的数据集来矫正量化因子;Data-Free模式则不需要数据集来进行量化矫正。
大模型量化压缩
- 适用场景:大模型压缩是指将大语言模型(LLM)减小体积、减少计算资源消耗和加快推理速度的技术,压缩技术有助于在资源有限的设备上部署模型。
- 工具能力:量化工具将高位浮点数转换为低位定点数,从而直接减少模型权重的体积,并针对大模型的特点提供离群值抑制、精度保持、仅权重量化、稀疏量化等可配置特性。
离群值抑制
- 困难挑战:当模型参数规模大于6.7B时,大模型激活值上开始出现离群值,离群值对常规PTQ量化算法挑战增大,随着模型规模增大,W8A8量化精度骤降。
- 特性优势:使用离群值抑制功能对LLM模型进行离群值抑制,大大减小其对精度的影响。
仅权重量化
- 困难挑战:大模型推理的主要瓶颈在于权重的数据搬运,仅权重量化虽然没有减少计算量,但是降低了数据搬运的访存开销,所以可以提升性能
- 特性优势:仅权重量化不涉及激活部分的改动,避免了激活离群值问题,精度更高,可做到更低比特压缩。
稀疏量化
- 困难挑战:稀疏化通过识别并移除那些对模型性能影响不大的参数来减少深度神经网络中的参数数量,从而降低模型的复杂性和计算需求。
- 特性优势:模型稀疏工具通过算法判断模型权重中每个元素对精度结果的重要性,并将模型权
重中对最终精度影响小的权重值置零。可以先对模型进行稀疏化,然后再结合量化进一步进行权重压缩,稀疏后的权重存在更多零值,对量化更加友好。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)