
国产化大模型适配~华为鲲鹏服务器~300I-pro
今天收到一个大模型进行国产化适配的任务,服务器是华为鲲鹏服务器(300I-pro),由于之前没有接触过该服务器,为了进行适配,就开始了摸索之路。
今天收到一个大模型进行国产化适配的任务,服务器是华为鲲鹏服务器(300I-pro),由于之前没有接触过该服务器,为了进行适配,就开始了摸索之路。
一、环境搭建框架
通过调研发现,进行适配环境的搭建,总共有两种方法,一种就是物理机搭建,另一种是通过docker镜像部署。这两者需要安装的环境是有些差别的。下面用图进行展示它们之间存在的差别:
1、物理机部署
物理机部署的环境如下图所示:
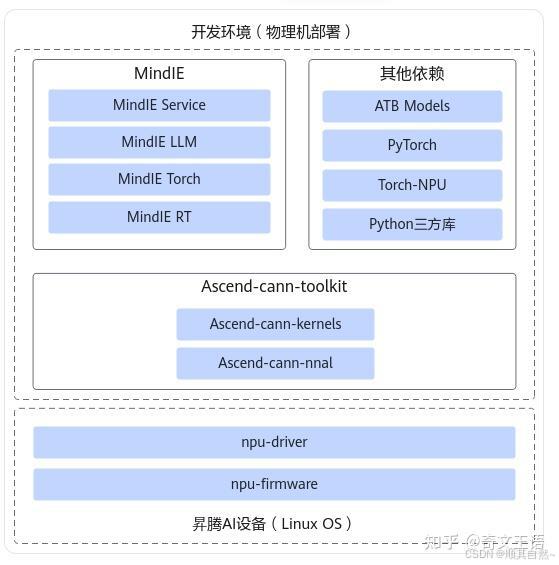
物理机依赖架构
2、容器部署
容器部署的环境如下图所示:
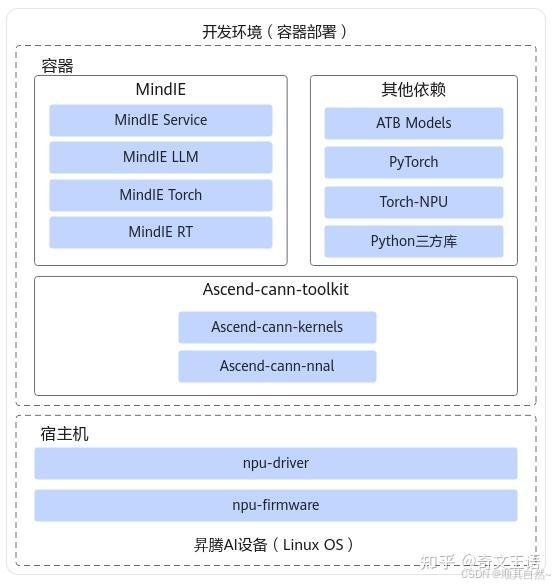
容器依赖结构
二、环境准备
为了操作的灵活性,因此我开始选择了物理机进行环境搭建,这种方式比基于docker容器搭建费劲一些,因为好多底层环境需要自己一步一步进行搭建。
1、安转驱动与固件
# 下载驱动与固件
Ascend-hdk-310p-npu-driver_23.0.1_linux-aarch64.run
Ascend-hdk-310p-npu-firmware_7.1.0.4.220.run
# 增加可执行权限
chmod +x Ascend-hdk-310p-npu-driver_23.0.1_linux-aarch64.run
chmod +x Ascend-hdk-310p-npu-firmware_7.1.0.4.220.run
# 校验run安装包的一致性和完整性
./Ascend-hdk-310p-npu-driver_23.0.1_linux-aarch64.run --check
./Ascend-hdk-310p-npu-firmware_7.1.0.4.220.run --check
# 安装驱动
./Ascend-hdk-310p-npu-driver_23.0.1_linux-aarch64.run --full
./Ascend-hdk-310p-npu-firmware_7.1.0.4.220.run --full
# 重启服务器(生效)
reboot
# 卸载驱动与固件
./Ascend-hdk-310p-npu-driver_23.0.1_linux-aarch64.run --uninstall
./Ascend-hdk-310p-npu-firmware_7.1.0.4.220.run --uninstall2、安转CANN软件包
# 下载CANN包
Ascend-cann-toolkit_8.0.RC2_linux-aarch64.run
# 增加可执行权限
chmod +x Ascend-cann-toolkit_8.0.RC2_linux-aarch64.run
# 校验run安装包的一致性和完整性
./Ascend-cann-toolkit_8.0.RC2_linux-aarch64.run --check
# 安装软件包
./Ascend-cann-toolkit_8.0.RC2_linux-aarch64.run --check --install
# 配置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 安装后检查
cd /usr/local/Ascend/ascend-toolkit/latest/aarch64-linux
cat ascend_toolkit_install.info
check
install successfully

version info
3、安转Kernels算子包
Kernels算子包能够节省算子编译时间,在如下场景中需要安装:
(1)大模型推理、训练场景
(2)运行包含动态shape网络或单算子API相关业务场景在安装Kernels算子包之前,需要安装配套版本的Toolkit并配置环境变量。
# 下载Kernels算子包
Ascend-cann-kernels-310p_8.0.RC2_linux.run
# 增加可执行权限
chmod +x Ascend-cann-kernels-310p_8.0.RC2_linux.run
# 校验run安装包的一致和完整性
./Ascend-cann-kernels-310p_8.0.RC2_linux.run --check
# 安装软件包
./Ascend-cann-kernels-310p_8.0.RC2_linux.run --install
# 安装后检查
cd /usr/local/Ascend/ascend-toolkit/latest/opp_kernel
cat version.info
check

install success
version info
4、安装NNAL加速库
NNAL加速库软件包中提供了面向大模型领域的ATB(Ascend Transformer Boost)加速库,实现了基于Transformers结构的神经网络推理加速引擎库,提供昇腾亲和的融合算子、通信算子、内存优化等,作为算子的公共底座提升了大模型训练和推理性能。
在安装NNAL加速库之前,需要安装配套版本的Toolkit并配置环境变量。
# 下载NNAL加速库
Ascend-cann-nnal_8.0.RC2_linux-aarch64.run
# 增加可执行权限
chmod +x Ascend-cann-nnal_8.0.RC2_linux-aarch64.run
# 校验run安装包的一致性和完整性
./Ascend-cann-nnal_8.0.RC2_linux-aarch64.run --check
# 安装软件包
./Ascend-cann-nnal_8.0.RC2_linux-aarch64.run --install
# 配置环境变量(当前进程)
source /usr/local/Ascend/nnal/atb/set_env.sh
# 配置环境变量(所有进程)
vim ~/.bashrc
source /usr/local/Ascend/nnal/atb/set_env.sh
source ~/.bashrc
# 安装后检查
cd /usr/local/Ascend/nnal/atb/latest
cat version.info
check

install success

version info
5、安装PyTorch库
安装了配套版本的NPU驱动固件、CANN软件(Toolkit、Kernels、NNAL)并配置环境变量。
# 下载安装包
# 下载PyTorch安装包
wget https://download.pytorch.org/whl/cpu/torch-2.2.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 下载torch_npu插件包
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc2-pytorch2.2.0/torch_npu-2.2.0.post2-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 执行命令安装
pip3 install torchvision==0.17.0
pip3 install torch-2.2.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip3 install torch_npu-2.2.0.post2-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 验证安装是否成功
python3 -c "import torch;import torch_npu; a = torch.randn(3, 4).npu(); print(a + a);"
# 卸载软件
pip3 uninstall torch torch_npu6、安装ATB Models库
拉取Mindie镜像
MindIe 镜像
根据拉取的镜像,创建一个容器,比如 创建的容器名字叫:llm-demo
# 创建容器
docker run -it -d --net=host --ipc=host \
--shm-size=15g \
--name llm-demo \
--privileged=true \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-w /home \
--device=/dev/davinci0 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /home:/home \
-v /tmp:/tmp \
-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.RC2-300I--Duo-arm64 /bin/bash
# 进入容器
docker exec -it llm-demo /bin/bash
# 安装atb-llm的python包
pip3 install atb_llm-0.0.1-py3-none-any.whl
# 配置环境变量(当前进程)
source /usr/local/atb_models/set_env.sh7、安装MindIE库
MindIE(Mind Inference Engine,昇腾推理引擎)是华为昇腾针对AI全场景业务的推理加速套件,具有强大的性能,健全的生态,帮助用户快速开展业务迁移、业务定制。
# 准备mindie安装库
Ascend-mindie_1.0.RC2_linux-aarch64.run
# 增加可执行权限
chmod +x Ascend-mindie_1.0.RC2_linux-aarch64.run
# 校验run安装包的一致和完整性
./Ascend-mindie_1.0.RC2_linux-aarch64.run --check
# 安装软件包
./Ascend-mindie_1.0.RC2_linux-aarch64.run --install --quiet
配置环境变量(当前进程)
source /usr/local/Ascend/mindie/set_env.sh
配置MindIE Server
# 进入mindie安装目录
cd /usr/local/Ascend/mindie
chmod 750 mindie-service
chmod -R 550 mindie-service/bin
chmod -R 500 mindie-service/bin/mindieservice_backend_connector
chmod -R 550 mindie-service/lib
chmod -R 550 mindie-service/include/
chmod -R 550 mindie-service/scripts/
chmod 750 mindie-service/logs
chmod 750 mindie-service/conf
chmod 640 mindie-service/conf/config.json
chmod 700 mindie-service/security/
chmod -R 700 mindie-service/security/*
根据用户需要设置配置参数
进入config目录,打开config.json文件
cd mindie-service/conf
vim config.json
配置参数介绍(主要)
资源参数:ResourceParam
cacheBlockSize:kvcache block的size大小,建议取值128,其他值建议取为2的n次幂。
preAllocBlocks:预分配策略,给请求分配好block数量
日志参数:LogParam
logLevel:日志级别
logPath:日志保存路径
模型部署参数:ModelDeployParam
modelName:模型名字
maxSeqLen:最大序列长度,输入的长度+输出的长度<=maxSeqLen
npuMemSize:NPU中可以用来申请kv cache的size上限。单位:GB,建议值:8。快速计算公式:npuMemSize=(总空闲-权重/NPU卡数-后处理占用)*系数,其中系数取0.8。
cpuMemSize:上述就是在物理机上进行搭建大模型运行的环境的完整步骤

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 0
0 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)