
昇思25天学习打卡营第2天|快速入门
昨天载入了数据集并对数据进行迭代访问,今天就要对数据进行进行模型构建和分析了。
·
昨天载入了数据集并对数据进行迭代访问,今天就要对数据进行进行模型构建和分析了。
1、网络构建
通过嵌套结构,可以简单地使用面向对象编程的思维,对神经网络结构进行构建和管理。
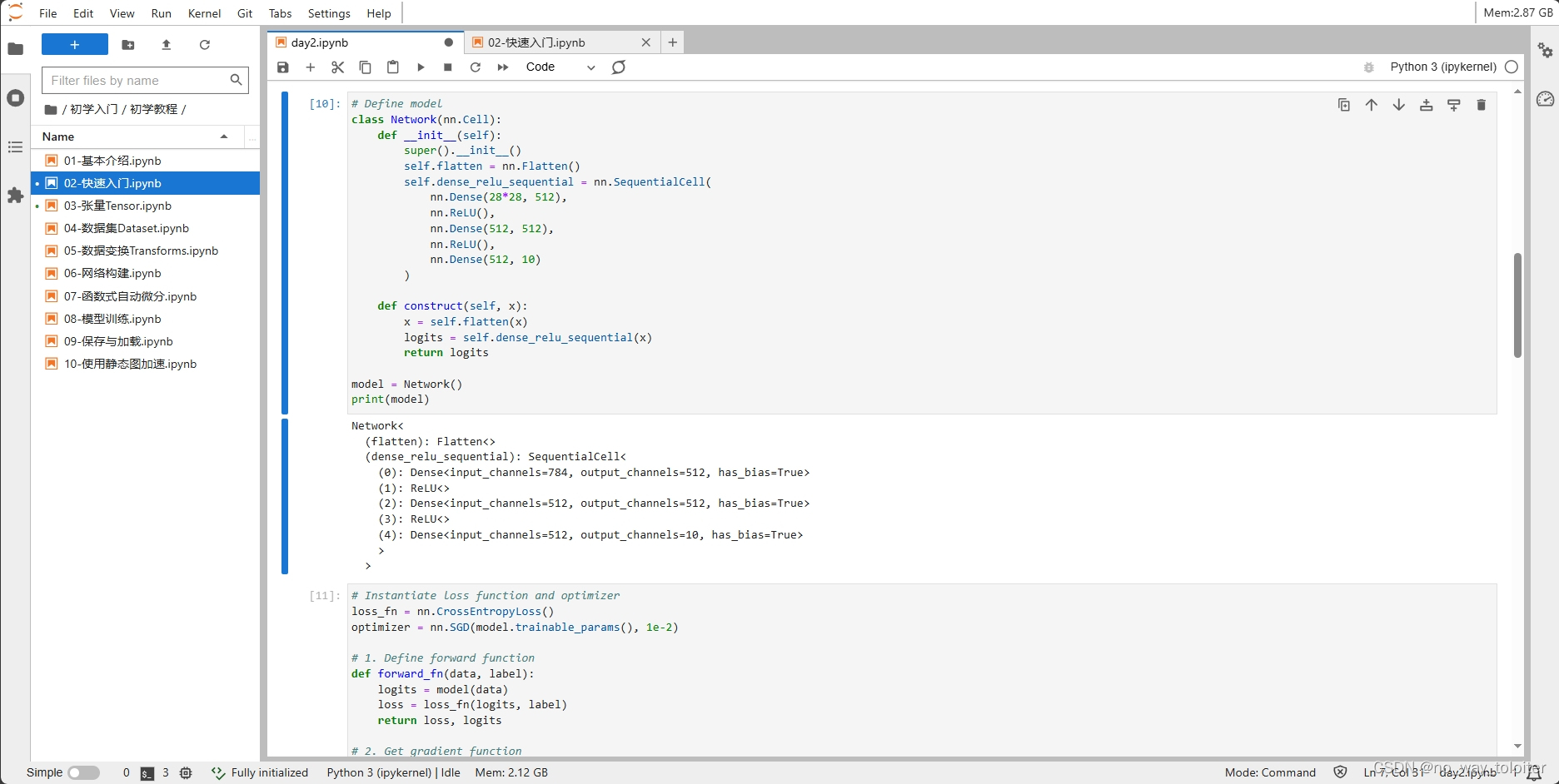
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)Network<
(flatten): Flatten<>
(dense_relu_sequential): SequentialCell<
(0): Dense<input_channels=784, output_channels=512, has_bias=True>
(1): ReLU<>
(2): Dense<input_channels=512, output_channels=512, has_bias=True>
(3): ReLU<>
(4): Dense<input_channels=512, output_channels=10, has_bias=True>
>
>
2、模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
- 定义正向计算函数。
- 使用value_and_grad通过函数变换获得梯度计算函数。
- 定义训练函数,使用set_train设置为训练模式,执行正向计算、反向传播和参数优化。
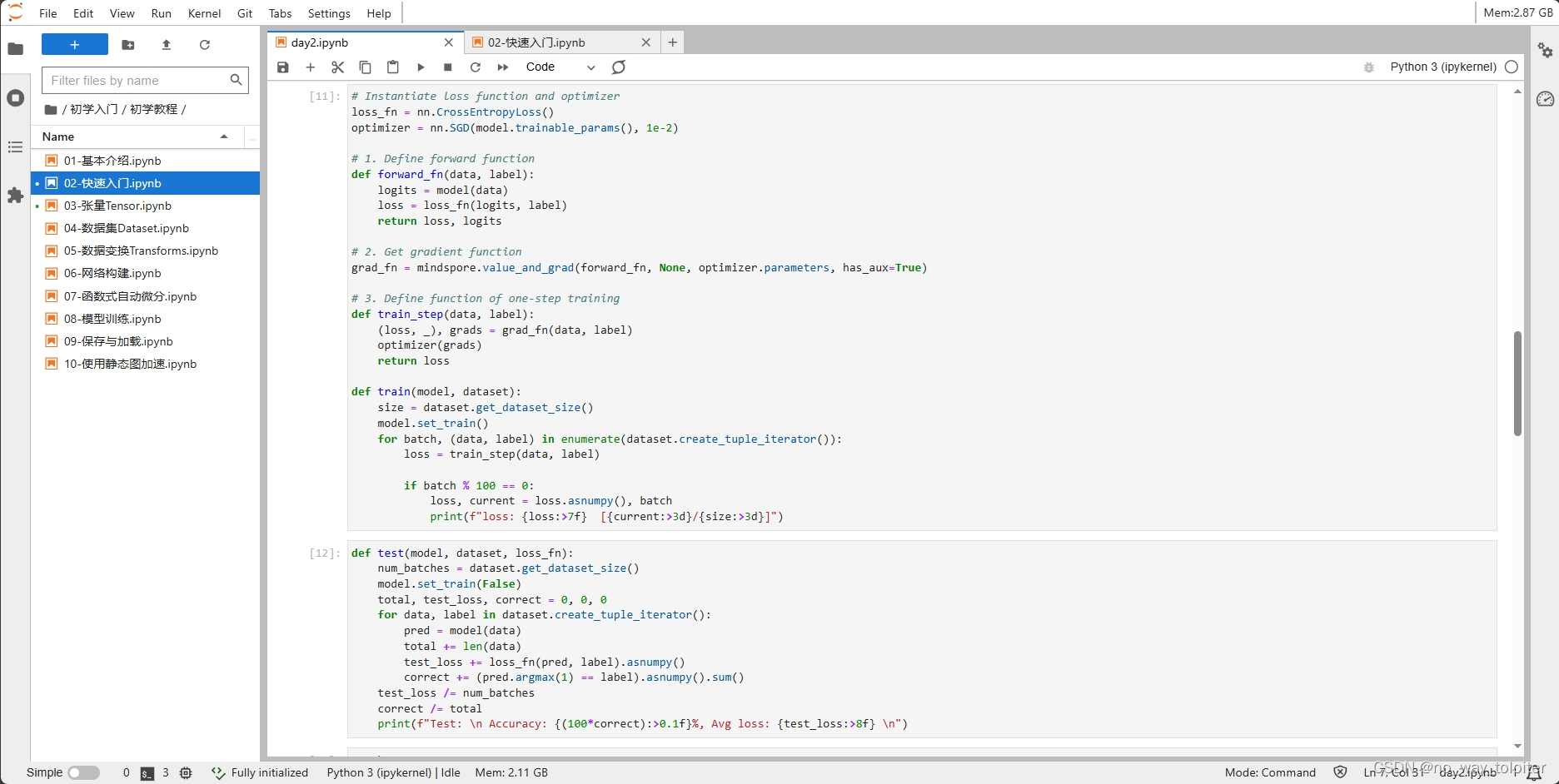
# Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
# 1. Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 2. Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 3. Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")然后我们定义测试函数,用来评估模型的性能。
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
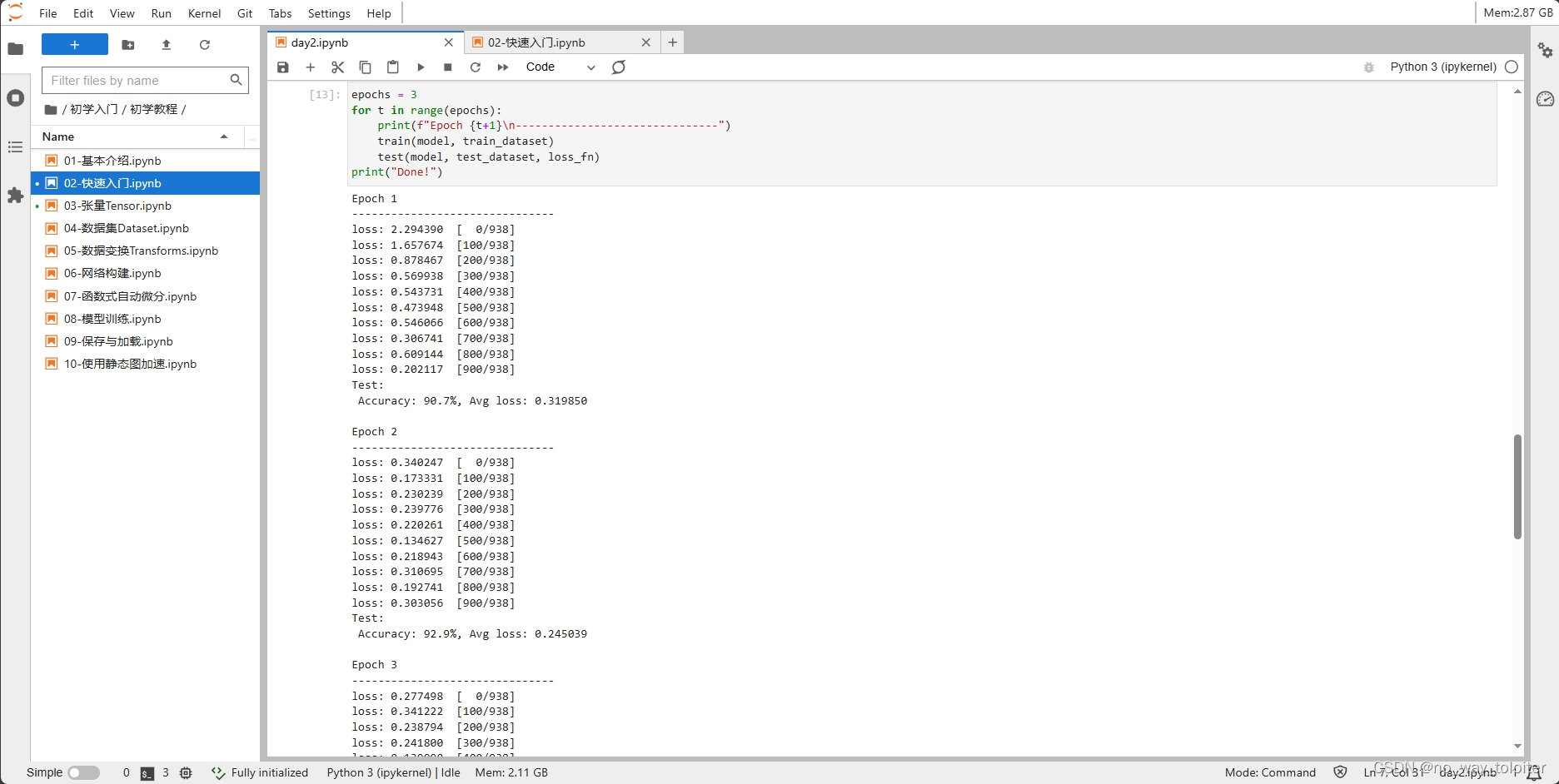
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset)
test(model, test_dataset, loss_fn)
print("Done!")3、保存模型
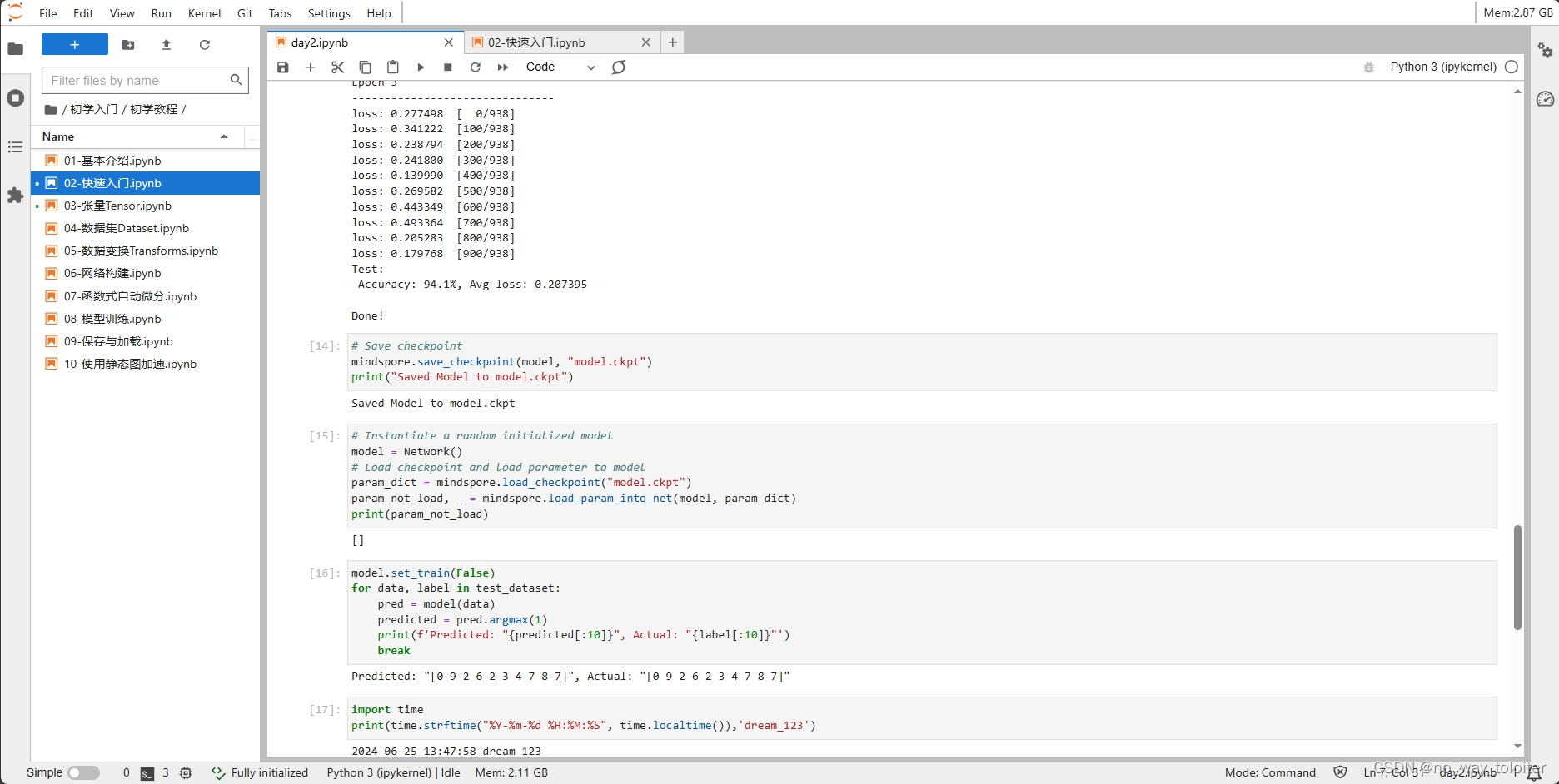
模型训练完成后,需要将其参数进行保存。
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")模型保存命名为"model.ckpt"。
4、加载模型
当我们需要使用保存的模型时,需要加载模型。
加载保存的权重分为两步:
- 重新实例化模型对象,构造模型。
- 加载模型参数,并将其加载至模型上。
# Instantiate a random initialized model
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)输出‘param_not_load’是未被加载的参数列表,为空 [ ] 时代表所有参数均加载成功。
加载后的模型可以直接用于预测推理。
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
breakPredicted: "Tensor(shape=[10], dtype=Int32, value= [3, 9, 6, 1, 6, 7, 4, 5, 2, 2])", Actual: "Tensor(shape=[10], dtype=Int32, value= [3, 9, 6, 1, 6, 7, 4, 5, 2, 2])"
5、我的实践
通过以上内容,我简单了解了数据模型训练及使用的基本步骤和方式。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)