
无板也能写算子?解锁Ascend C CPU孪生调试黑科技
2025年昇腾CANN训练营第二季推出系列课程助力开发者提升算子开发技能,通过认证可获得证书及大奖。针对NPU算子调试难题,AscendC提供CPU孪生调试方案,通过C++模拟AICore行为实现脱离硬件的逻辑验证。调试时可直接使用printf打印变量值,并支持GDB单步调试,大幅提升开发效率。虽然CPU模拟无法反映真实性能,但能快速解决逻辑问题。建议先用CPU调试确保正确性,再上NPU优化性能。
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
算子开发者最怕什么? 不是算法难,而是 Debug 难。
在 NPU 硬件上调试算子,往往像是在“开盲盒”:
-
报错信息晦涩(Error Code: 10000x)。
-
无法单步跟踪,不知道程序挂在哪一行。
-
想要
printf看个变量值,结果 Log 被底层屏蔽或者乱序。
更惨的是,如果你手头暂时没有 NPU 硬件,难道就不能开发了吗? Ascend C CPU 孪生调试 完美解决了这个问题。它在 Host 侧(CPU)构建了一个 AI Core 的功能模拟器,让你脱离硬件也能验证算子逻辑。
一、 核心原理:给 AI Core 照镜子
CPU 调试模式的核心思想是:用 C++ 代码模拟 AI Core 的硬件行为。 Ascend C 提供了一套可以在 CPU 上编译运行的头文件库。当你开启 CPU 调试宏时,原本指向底层汇编的 Intrinsics(如 DataCopy, Add)会被替换为 C++ 实现的模拟函数。
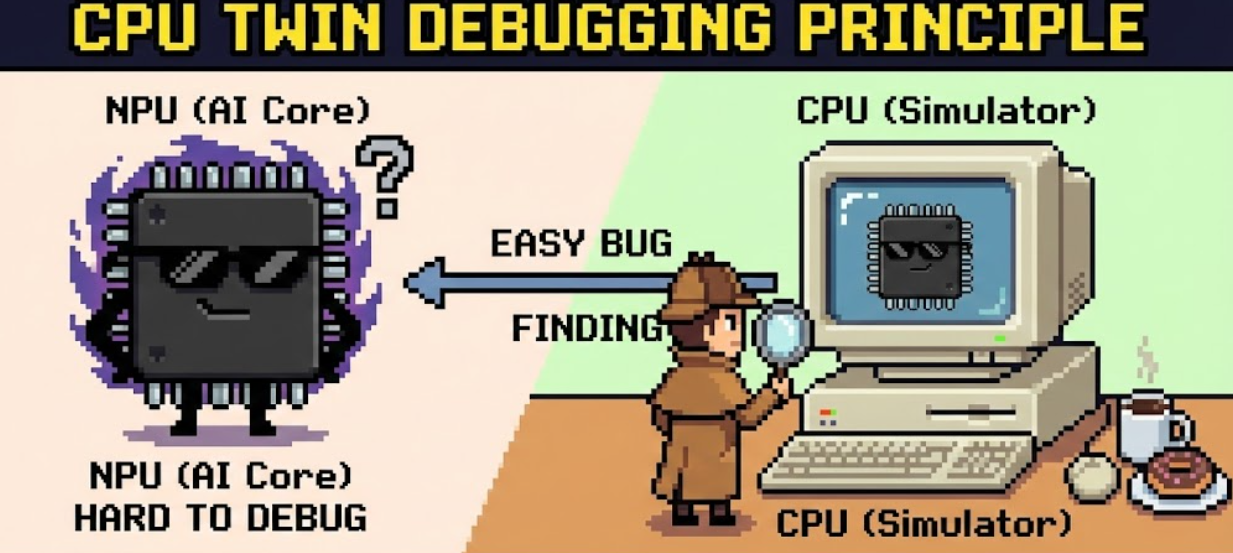
二、 实战:开启“上帝视角”的 printf
在 CPU 模式下,最爽的莫过于可以直接在 Kernel 代码里使用 printf。这在 NPU 模式下是绝对禁止的(或者极其麻烦)。
2.1 修改 CMakeLists.txt
首先,我们需要告诉构建系统:这次我要编译给 CPU 跑。
# 增加 CPU 调试编译选项
add_compile_options(-D__CCE_KT_TEST__ -g -O0) # -g 用于 GDB 调试
2.2 编写调试代码
在你的算子实现文件 add_custom.cpp 中,利用宏 __CCE_KT_TEST__ 来隔离调试代码。
__aicore__ inline void Compute(int32_t i) {
// ... DeQue ...
#ifdef __CCE_KT_TEST__
// 这里的代码只会在 CPU 调试模式下运行!
// 我们可以直接把 Tensor 的值取出来打印
// GetValue() 是 CPU 模式特有的 Helper 函数
half val0 = xLocal.GetValue(0);
half val1 = yLocal.GetValue(0);
printf(">> [Debug] Tile %d: x[0]=%f, y[0]=%f\n", i, (float)val0, (float)val1);
if (i == 0) {
printf(">> [Debug] TileLength = %d\n", tileLength);
}
#endif
Add(zLocal, xLocal, yLocal, tileLength);
// ...
}
2.3 编写 CPU 启动脚本 (Main.cpp)
我们需要一个 Host 侧的 C++ main 函数来直接调用 Kernel 函数,而不是通过 ACL。Ascend C 提供了 ICPU_RUN_KF 宏来简化这个过程。
#include "add_custom.h" // 引入算子类定义
int main() {
// 1. 准备 Host 数据 (malloc)
size_t dataSize = 1024 * sizeof(half);
uint8_t* x = (uint8_t*)malloc(dataSize);
uint8_t* y = (uint8_t*)malloc(dataSize);
uint8_t* z = (uint8_t*)malloc(dataSize);
// ... 初始化 x, y 数据 ...
// 2. 模拟 Tiling 参数
AddCustomTilingData tiling;
tiling.totalLength = 1024;
tiling.tileLength = 256;
// ...
// 3. 启动 CPU 仿真运行
// 宏参数:(Kernel类名, blockDim, 参数1, 参数2, ...)
ICPU_RUN_KF(AddCustom, 1, x, y, z, tiling);
// 4. 校验结果 z
// ...
printf("CPU Debug Finished!\n");
return 0;
}
三、 显微镜手术:GDB 单步调试
既然生成的是标准的可执行文件,我们就可以祭出 Linux 神器 —— GDB。
# 1. 编译
g++ -o cpu_debug main.cpp add_custom.cpp -D__CCE_KT_TEST__ -g -O0 -I...
# 2. 启动调试
gdb ./cpu_debug
# 3. 打断点
(gdb) break add_custom.cpp:Compute
# 4. 运行
(gdb) run
# 5. 单步执行 & 查看变量
(gdb) next
(gdb) print tileLength
$1 = 256
(gdb) print xLocal
通过 GDB,你可以一步步看着数据从 inQueue 流向 outQueue,检查 Tiling 计算是否溢出,地址偏移是否对齐。这种“显微镜”级别的观察能力,能帮你解决 99% 的逻辑 Bug。
四、 局限性:它不是万能的
虽然 CPU 调试很爽,但必须认清它只是功能模拟,不是硬件仿真。
-
性能无关:CPU 跑得慢不代表 NPU 跑得慢,CPU 跑得快也不代表 NPU 快。做性能分析(Profiling)必须上板。
-
并发差异:CPU 模拟通常是串行化的(或者线程模拟),可能掩盖真实的流水线竞争(Race Condition)或死锁问题。
-
指令差异:极少数特殊的硬件指令在 CPU 上可能没有完全等价的行为。
最佳实践: 先在 CPU 模式下把逻辑跑通(保证算得对),再上 NPU 调优性能(保证算得快)。
五、 总结
Ascend C 的 CPU 孪生调试技术,极大地降低了算子开发的门槛。 它让每一台笔记本都变成了潜在的 Ascend 开发机。
-
没有板子? 用 CPU 调试。
-
逻辑报错? 用 printf/GDB。
-
Tiling 算不清? 在 Host 侧打印出来看看。
掌握了这一招,你的算子开发效率至少能提升一倍。
下期预告 到目前为止,我们所有的算子都是基于 C++ 编写的。但在大模型推理场景中,PyTorch 原生算子有时性能不够,写 C++ 又太慢。有没有一种既有 Python 的灵活性,又有 C++ 高性能的方法? 下一期,我们将探索 Ascend C 与 Python 的深度融合,看看如何在 Python 中直接生成 Ascend C 代码!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)