
释放硬件极致性能:Ascend C 算子性能优化的系统化工程实践
本文深度解析Ascend NPU性能优化方法论,基于250个案例分析提炼出两项核心瓶颈:算子耗时超标和计算资源利用率低。通过剖析AscendNPU硬件架构,提出系统化解决方案:1)采用双缓冲技术实现计算与搬运重叠;2)运用任务切分与向量化指令提升并行度;3)通过内存填充规避BankConflict。文章提供详细流程图、代码示例和优化闭环方法论,帮助开发者最大化释放昇腾芯片算力,包含流水线并行、数据
目录
2. 深入虎穴:Ascend NPU 性能模型与瓶颈的精确制导分析
3.1 优化基石:双缓冲 (Double Buffering) 实现计算与搬运重叠
3.3 优化高阶:消除资源争用 - 深入规避 Bank Conflict
4. 性能调优的科学闭环:从普罗文件(Profile)到优化(Optimize)
⚡ 摘要
本文基于CANN训练营对 250个错误案例分析后总结的 12类典型问题,深度聚焦于 “算子耗时超过基线”、“计算资源利用率低”两大核心性能瓶颈。我们将从 Ascend NPU 的 硬件架构原理 (Hardware Architecture Principle)出发,系统化阐述导致性能瓶颈的根因,并提供从 流水线并行 (Pipeline Parallelism)、数据复用 (Data Reuse)、多核协同 (Multi-Core Collaboration)到 指令级优化 (Instruction-Level Optimization)的全套解决方案。文章将包含大量基于官方素材绘制的专业流程图、性能分析图谱,以及可直接复用的优化代码示例,旨在帮助开发者建立完整的性能优化方法论,彻底释放昇腾处理器的澎湃算力。
1. 性能挑战的严峻性:从250个案例中洞察效率瓶颈的根源
在算子功能正确性得以保障之后,性能便成为衡量算子质量的黄金标准,直接关系到AI模型训练的周期和推理服务的实时性。您提供的官方素材清晰地指出,在经过对 250个错误案例的深入分析后,“算子实现及内存使用问题”是最高频的错误来源,而这其中,性能问题占据了相当大的比重。
💡 来自CANN训练营教材的深度洞察: 素材中明确将 “计算流程实现未充分发挥硬件计算效率”与 “多核并行度不够”、“UB(Unified Buffer)使用不合理”并列为导致性能不达标的三大核心症结。这并非孤立的编码问题,而是反映了开发者对 Ascend NPU 这一大规模并行计算架构 (Massively Parallel Computing Architecture)的理解深度不足。许多开发者习惯于CPU的编程思维,未能将计算任务有效地映射到NPU的数据流驱动 (Dataflow-Driven)和存储层次化 (Memory Hierarchy)的执行模型上,最终导致强大的AICore计算单元因“饥饿”而闲置,或陷入低效的等待状态。
为了建立一个全局视野,我们首先基于素材绘制出性能问题的完整分类与优化策略地图:
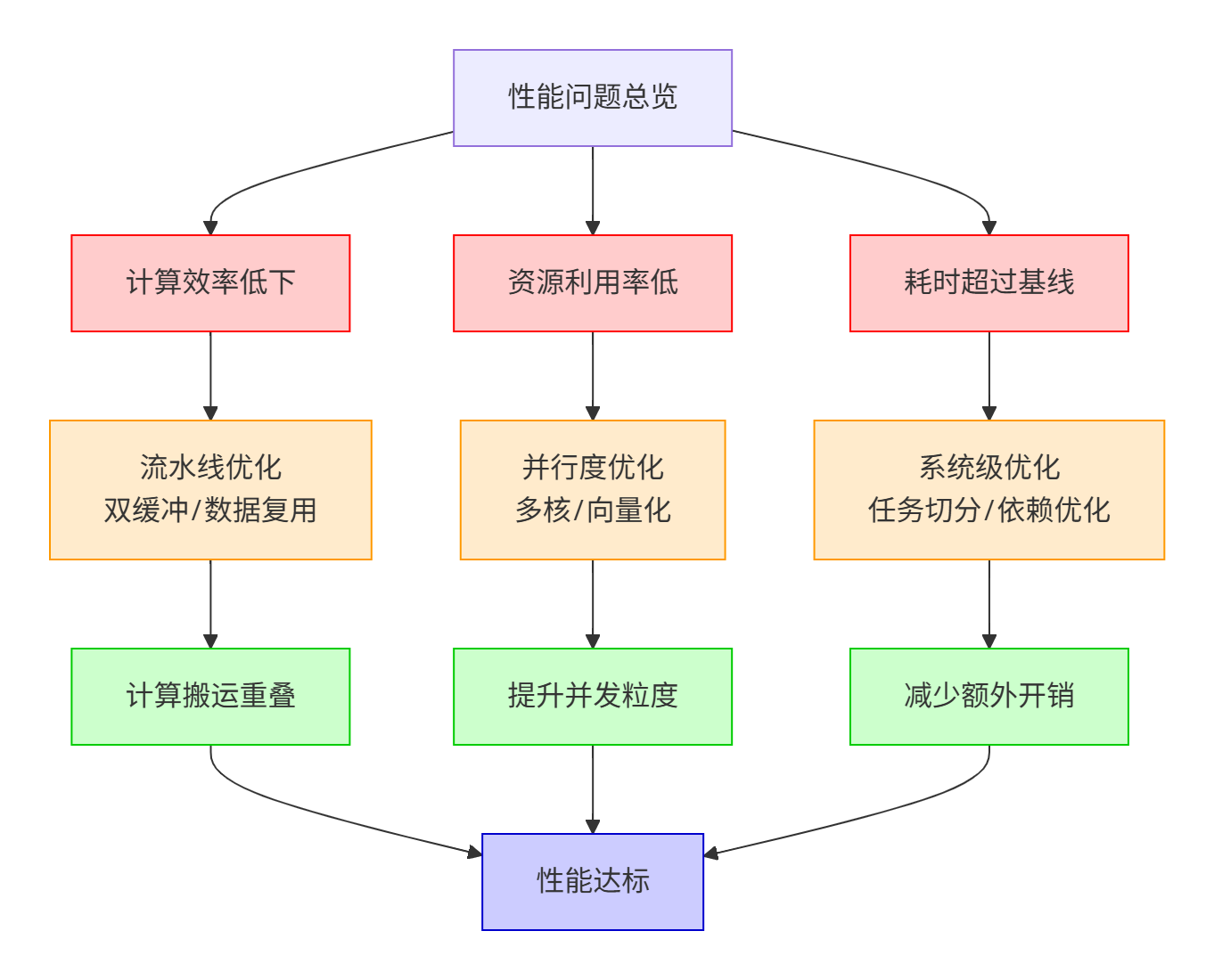
2. 深入虎穴:Ascend NPU 性能模型与瓶颈的精确制导分析
性能优化绝非盲目尝试,必须建立在对硬件工作方式的精确理解之上。一个低效的算子在NPU上的执行,可以类比为一个组织混乱的工业生产流水线。
2.1 理想 vs. 现实:计算流水线的天壤之别
一个未经优化的朴素算子,其执行流程是顺序和阻塞的,可用以下时序图刻画其低效的本质:

(图:顺序阻塞模型下,计算与搬运单元存在大量空闲时间,硬件利用率极低)
而一个经过充分优化的算子,其目标是达到如下图所示的全流水线并行执行状态,这也是我们追求的终极目标:
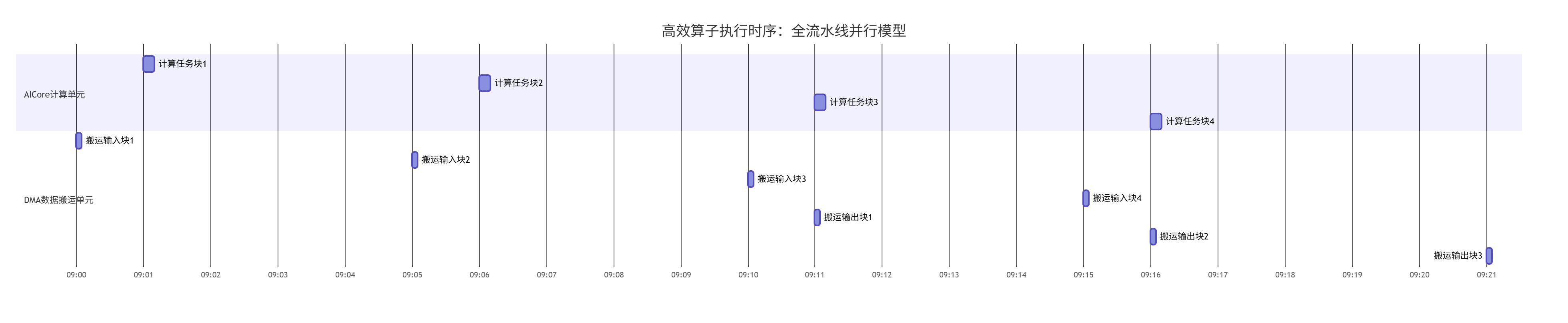
(图:理想的全流水线并行,计算与搬运完全重叠,硬件资源被持续喂饱,利用率接近100%)
2.2 性能瓶颈的精细化归因分析
根据官方素材的指引,我们可以将性能瓶颈进行更精细的拆解:
-
🕸️ 数据搬运瓶颈 (Data Movement Bottleneck): 这是最普遍的瓶颈。GM(全局内存)的带宽和延迟远逊于UB(片上缓存)和计算单元。若数据搬运策略是“用一点,搬一点”,那么计算单元绝大部分时间都在等待数据,形成“饥饿”。素材中“UB使用不合理”往往指未能有效利用UB进行数据缓存和复用,导致对GM的频繁访问。
-
🌀 并行度不足 (Insufficient Parallelism): 包括两个层面:
-
任务级并行 (Task-Level Parallelism): 素材中“多核并行度不够”即指此。未能将计算任务合理地切分(Tiling)并调度到足够多的AICore上执行,导致大部分计算核心处于闲置状态。
-
数据级并行 (Data-Level Parallelism): 未能充分利用AICore的SIMD(单指令多数据)向量指令。例如,使用标量指令逐个处理
half数据,而非使用__half8指令一次处理8个数据,计算吞吐量直接下降为1/8。
-
-
⚔️ 资源争用 (Resource Contention): 当多个执行单元争抢同一资源时发生。最典型的是 UB Bank Conflict。UB由多个Bank(存储体)组成。理想情况下,一次访问的数据应分布在不同的Bank上以实现并行存取。若多个数据项映射到同一Bank,则访问会串行化,大幅增加延迟。
-
⛓️ 指令与数据依赖 (Instruction & Data Dependency): 计算指令间的真数据依赖(Read-after-Write, RAW)会强制流水线停顿。此外,复杂的控制流(如大量
if-else分支)会导致指令预取失效,也会影响性能。
3. 核心优化技术实战:从理论到高效代码的蜕变
接下来,我们将深入每一个优化技术,并提供详尽的代码实现。
3.1 优化基石:双缓冲 (Double Buffering) 实现计算与搬运重叠
双缓冲是解决数据搬运瓶颈、实现流水线并行的核心技术。其核心思想是在UB中为数据开辟两块缓冲区(例如BufferA和BufferB)。当计算单元在处理BufferA中的数据时,DMA控制器可并行地将下一块数据从GM搬运到BufferB,从而实现计算与搬运的重叠。
其数据流和状态切换的精细控制过程,可由以下状态机清晰展示:

(图:双缓冲技术的精细状态机,展示了计算、搬运、同步和缓冲区角色切换的完整周期)
✅ Ascend C 双缓冲优化实战代码示例:
以下代码展示了如何为一个简单的向量加法算子实现双缓冲优化,其中包含了详细的注释,说明了每一步的意图和最佳实践。
// 使用双缓冲技术优化的向量加法核函数
// 假设: TILE_LENGTH 是每个数据块的大小,UB_SIZE 是UB总容量
template <typename T>
__aicore__ void vector_add_double_buffer_kernel(
const T* __gm__ gm_input_a, // GM中的输入A
const T* __gm__ gm_input_b, // GM中的输入B
T* __gm__ gm_output, // GM中的输出
int32_t total_data_length // 总数据长度
) {
// 1. UB内存规划:在UB中为两块缓冲区分配空间
// 计算每块缓冲区所需容量(包括可能的对齐填充)
const int32_t tile_elements = TILE_LENGTH;
const int32_t buffer_size_bytes = tile_elements * sizeof(T);
// 获取UB基地址指针(通常通过参数传入或使用__attribute__((ub)))
extern __attribute__((ub)) uint8_t ub_buffer[];
// 将UB划分为两个缓冲区(Buf0 和 Buf1)
T* ubuf_a0 = (T*)(ub_buffer); // Buf0: 输入A
T* ubuf_b0 = ubuf_a0 + tile_elements; // Buf0: 输入B
T* ubuf_c0 = ubuf_b0 + tile_elements; // Buf0: 输出C
T* ubuf_a1 = ubuf_c0 + tile_elements; // Buf1: 输入A
T* ubuf_b1 = ubuf_a1 + tile_elements; // Buf1: 输入B
T* ubuf_c1 = ubuf_b1 + tile_elements; // Buf1: 输出C
// 安全检查:确保UB容量足够
if ((ubuf_c1 + tile_elements - (T*)ub_buffer) * sizeof(T) > UB_SIZE) {
// 处理错误,UB不足
return;
}
// 2. 计算任务分块(Tiling)
int32_t total_tiles = (total_data_length + tile_elements - 1) / tile_elements;
int32_t tiles_per_core = ...; // 根据blockDim等参数计算每个核需要处理的块数
int32_t start_tile_index = get_block_idx() * tiles_per_core;
// 3. 初始化:预取第一个数据块到Buf0
int32_t current_tile = start_tile_index;
if (current_tile < total_tiles) {
int32_t copy_offset = current_tile * tile_elements;
int32_t copy_size = (copy_offset + tile_elements <= total_data_length) ?
tile_elements : (total_data_length - copy_offset);
// 使用DMA进行异步数据搬运 (gih_copy)
gih_copy(ubuf_a0, gm_input_a + copy_offset, copy_size * sizeof(T));
gih_copy(ubuf_b0, gm_input_b + copy_offset, copy_size * sizeof(T));
}
// 4. 主循环:双缓冲流水线
for (int32_t i = 0; i < tiles_per_core; ++i) {
current_tile = start_tile_index + i;
int32_t next_tile = current_tile + 1;
// 4a. 异步预取下一个数据块到Buf1(如果存在)
if (next_tile < total_tiles) {
int32_t next_copy_offset = next_tile * tile_elements;
int32_t next_copy_size = (next_copy_offset + tile_elements <= total_data_length) ?
tile_elements : (total_data_length - next_copy_offset);
gih_copy(ubuf_a1, gm_input_a + next_copy_offset, next_copy_size * sizeof(T));
gih_copy(ubuf_b1, gm_input_b + next_copy_offset, next_copy_size * sizeof(T));
}
// 4b. 等待当前块(Buf0)的数据搬运完成
gis_wait(); // 同步点,确保Buf0的数据已就绪
// 4c. 计算核心:处理当前在Buf0中的数据
// 使用向量化指令进行优化
for (int32_t j = 0; j < tile_elements; j += 8) { // 假设8路向量化
// 使用内置函数进行向量加载和加法
__h8 vec_a = __get_h8(ubuf_a0, j); // 从ubuf_a0加载8个half数据
__h8 vec_b = __get_h8(ubuf_b0, j);
__h8 vec_c = __add_h8(vec_a, vec_b); // 向量加法
__set_h8(ubuf_c0, j, vec_c); // 将结果存回ubuf_c0
}
// 4d. 将当前块的计算结果(Buf0)异步写回GM
if (current_tile < total_tiles) {
int32_t out_offset = current_tile * tile_elements;
int32_t out_size = (out_offset + tile_elements <= total_data_length) ?
tile_elements : (total_data_length - out_offset);
gih_copy(gm_output + out_offset, ubuf_c0, out_size * sizeof(T));
}
// 4e. 交换缓冲区角色:Buf1 <-> Buf0
// 通过交换指针,下一轮循环将处理刚预取到Buf1的数据
{ // 交换指针块,避免临时变量污染
T* temp_a = ubuf_a0; T* temp_b = ubuf_b0; T* temp_c = ubuf_c0;
ubuf_a0 = ubuf_a1; ubuf_b0 = ubuf_b1; ubuf_c0 = ubuf_c1;
ubuf_a1 = temp_a; ubuf_b1 = temp_b; ubuf_c1 = temp_c;
}
// 4f. 等待下一个块的预取完成(如果启动了的话)
if (next_tile < total_tiles) {
gis_wait();
}
} // 结束 for 循环
// 5. 最终同步,确保所有CopyOut操作完成
gis_wait();
}3.2 优化支柱:提升并行度 - 榨干硬件并发能力
-
任务级并行 (Task-Level Parallelism):核数 (blockDim) 与任务切分 (Tiling) 的艺术
素材中“多核并行度不够”是致命伤。在Host侧启动核函数时,必须合理设置
blockDim(启动的核数)。这需要根据总数据量、算子计算复杂度、以及UB容量来综合决定。最佳实践公式:
blockDim = (total_data_length + tile_length - 1) / tile_length,其中tile_length是每个核一次处理的数据量,受UB容量限制。// Host侧代码:合理设置并行度 int total_length = 1024 * 1024; // 1M 个数据 int tile_length = 1024; // 每个核处理1K数据,假设UB可容纳 // 计算需要启动的核数,向上取整 int block_dim = (total_length + tile_length - 1) / tile_length; // 确保block_dim不超过硬件支持的最大核数 block_dim = std::min(block_dim, MAX_AICORE_NUM); // 使用<<<>>>语法异步启动核函数 vector_add_kernel<<<block_dim>>>(gm_a, gm_b, gm_out, total_length); // 使用rtStreamSynchronize等待所有核执行完毕 aclrtSynchronizeStream(stream); -
数据级并行 (Data-Level Parallelism):向量化 (Vectorization) 指令的极致运用
Ascend C提供了丰富的内置函数(Intrinsics)用于向量化操作。未能使用这些指令是导致“计算资源利用率低”的直接原因。以下对比了标量与向量化实现的差异:
// ❌ 低效的标量计算 for (int i = 0; i < count; ++i) { ub_c[i] = ub_a[i] + ub_b[i]; // 编译器可能无法自动向量化 } // ✅ 高效的手动向量化计算(假设数据类型为half) for (int i = 0; i < count; i += 8) { // 每次迭代处理8个数据 // 一次性从UB加载8个half数据到向量寄存器 __h8 vec_a = __get_h8(ub_a, i); __h8 vec_b = __get_h8(ub_b, i); // 单条向量加法指令完成8次加法运算 __h8 vec_c = __add_h8(vec_a, vec_b); // 将结果一次性存回UB __set_h8(ub_c, i, vec_c); }向量化将计算吞吐量提升了近8倍,极大地提升了计算单元的利用率。
3.3 优化高阶:消除资源争用 - 深入规避 Bank Conflict
UB被划分为多个Bank。当单次内存访问请求所涉及的数据项都位于不同的Bank时,访问可以并行进行,达到最高带宽。反之,如果多个数据项映射到同一个Bank,则访问必须串行化,造成延迟。
Bank Conflict 示例与解决方案:
假设UB有16个Bank,每个Bank宽4字节。连续访问float数据(4字节)时,地址0, 4, 8, 12...分别映射到Bank0, Bank1, Bank2, Bank3...,无冲突。但如果以2个float为步长进行访问(访问0, 8, 16...),则所有地址都落在Bank0和Bank4,冲突严重。
解决方案:内存填充 (Memory Padding)
// 原始访问,可能存在Bank Conflict
float data[32][32]; // 一个32x32的矩阵
// 优化后:通过添加填充列来改变Bank映射
float data_padded[32][33]; // 每行多一个元素(填充)
// 现在按列访问时,相邻行的同一列元素会映射到不同的Bank4. 性能调优的科学闭环:从普罗文件(Profile)到优化(Optimize)
性能优化是一个持续迭代的过程,其科学工作流如下:
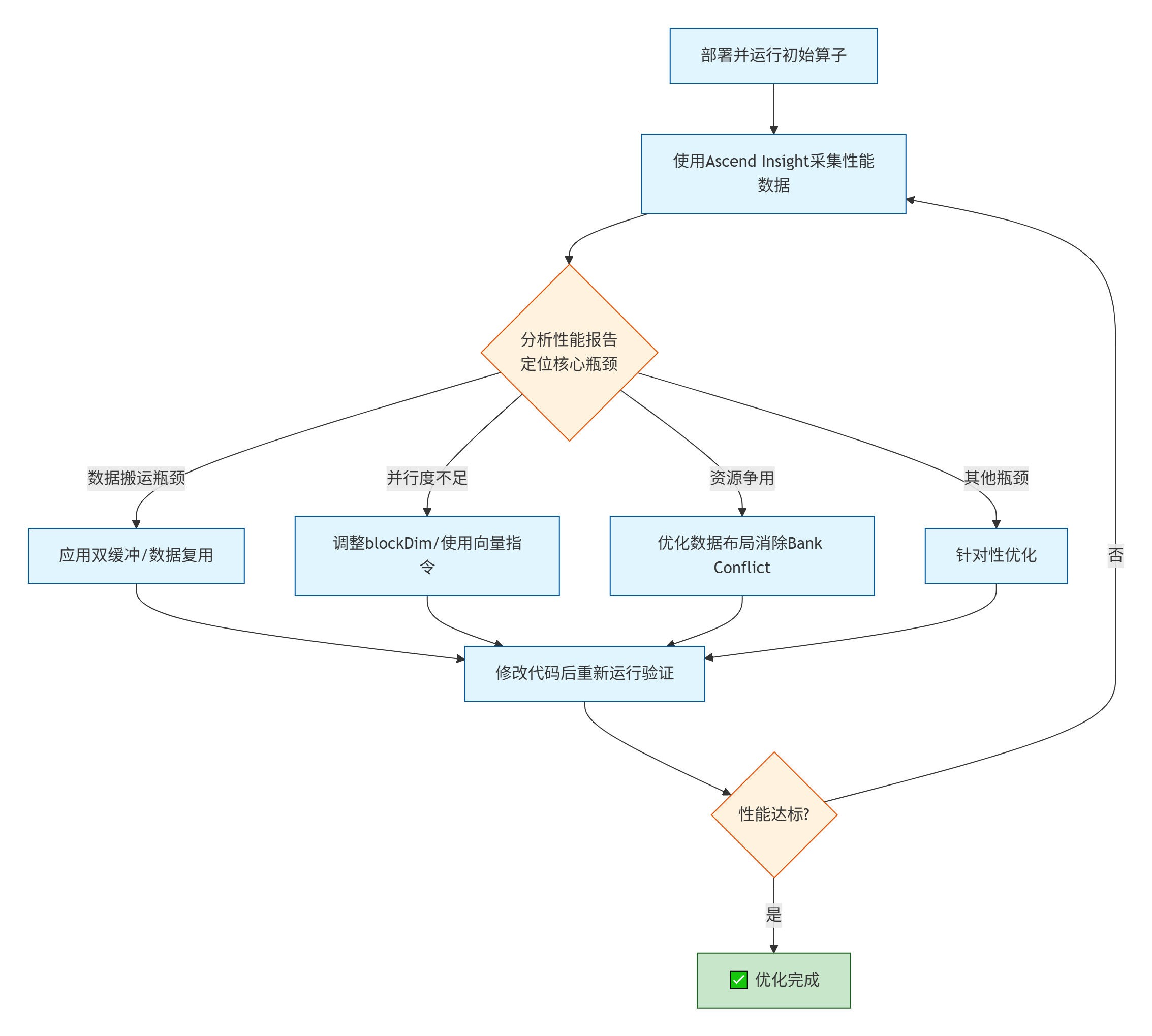
关键分析点:
-
AICore利用率: 若利用率曲线存在大量“峡谷”,说明计算单元经常空闲,大概率是数据供给不足。
-
时间线视图: 观察CopyIn、Compute、CopyOut的时间线是否紧密衔接。如果存在明显间隙,说明同步或依赖处理不当。
-
内存带宽: 查看GM和UB的带宽使用率是否接近硬件峰值。若远低于峰值,可能存在访问模式问题或Bank Conflict。
5. 总结与讨论
本文基于官方的一手问题素材,构建了一套完整的Ascend C算子性能优化体系。我们从250个案例的宏观分析切入,深入到流水线、并行度、资源争用等微观细节,最终落地为可执行的代码和科学的工作流。
-
🔄 流水线是灵魂:双缓冲技术是克服内存墙、实现计算搬运重叠的核心手段,是将硬件利用率从低谷推向高峰的关键。
-
💥 并行度是引擎:合理的任务切分 (Tiling)与核数配置 (blockDim)决定了任务级并发的潜力,而极致的向量化编程则榨干了单个计算核心的数据级并发能力。
-
⚔️ 资源管理是保障:理解并优化数据布局,避免 UB Bank Conflict,是确保内存子系统能够稳定高效地为计算单元输送数据的基础。
-
🔬 科学循证是准则:依赖 Ascend Insight等性能分析工具,建立“Profile-Hypothesize-Validate”的闭环,是避免盲目优化、高效解决问题的唯一路径。
💬 讨论与思考:
-
在您优化的最复杂的算子中,最大的性能瓶颈是什么?是通过本文提到的哪种技术解决的?
-
当双缓冲和向量化等技术都应用后,性能依然未达预期,您认为还有哪些更深入的优化方向可以考虑?(例如,尝试三缓冲、使用AI CPU协同计算等)
-
在多人协作的大型项目中,如何建立有效的性能回归测试机制,防止代码变更引入性能回退?
6. 参考链接
-
论文:A Performance Analysis Framework for AI Accelerators- 可参考相关学术论文对AI加速器性能模型的分析方法。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!


鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 35
35 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)