
昇腾运行大语言模型结果解析
执行下列脚本运行结果如下。
执行下列脚本
bash run.sh pa_fp16 performance [[256,256]] 1 qwen /data/drx/DeepSeek-R1-Distill-Qwen-32B 1
运行结果如下

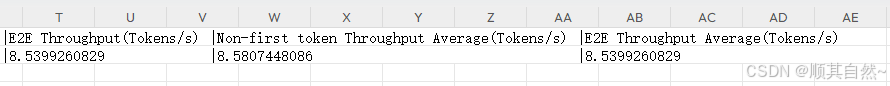
指标说明
以下是表格中各项指标的详细解释,结合大语言模型推理和昇腾CPU硬件特性进行说明:
1. Model
含义:运行的大语言模型名称或架构(如BERT、GPT、LLaMA等)。
作用:标识具体模型,不同模型的参数量、结构会影响性能指标。
2. Batchsize
含义:单次推理的批次大小(即并行处理的样本数)。
作用:增大Batchsize可提升硬件利用率,但受内存限制。昇腾NPU通过多核并行优化,适合较大Batchsize。
3. In_seq / Out_seq
In_seq:输入序列的Token长度(如提示词的Token数)。
Out_seq:输出序列的Token长度(模型生成的Token数)。
作用:序列长度直接影响计算量。昇腾NPU的长程注意力优化对长序列处理效率提升显著。
4. Total time(s)
含义:生成整个批次(Batchsize个样本)的总耗时(秒)。
计算:包括模型初始化、输入处理、计算、输出生成全流程时间。
5. First token time(ms)
含义:生成每个样本第一个Token的平均耗时(毫秒)。
特点:首Token需初始化上下文计算(如Transformer的KV缓存),耗时通常高于后续Token。
6. Non-first token time(ms)
含义:生成每个样本非首Token的平均耗时(毫秒)。
特点:利用自回归模型的缓存机制(如KV复用),速度通常快于首Token。
7. Non-first token Throughput(Tokens/s)
含义:仅统计非首Token的吞吐量(每秒处理的Token数)。
计算:(总Token数 - Batchsize) / (总时间 - First token time总和)
8. E2E Throughput(Tokens/s)
含义:端到端总吞吐量(包含所有Token的生成效率)。
计算:总Token数 / 总时间
9. 后两列(Average)
含义:多次实验或非首/端到端吞吐量的平均值。
作用:反映模型在不同批次或序列长度下的综合性能稳定性。
关键分析
性能瓶颈:若First token time占比过高,需优化模型初始化或硬件缓存机制。
效率对比:Non-first token Throughput通常显著高于E2E Throughput,体现自回归生成的特点。
硬件特性:昇腾CPU通过多核并行和内存优化,在长序列和大Batchsize场景下表现更优。
示例计算
假设:
Batchsize=4,In_seq=64,Out_seq=32
Total time=2.4s,First token time=200ms
总Token数=4*32=128
计算步骤:
1、Non-first token时间总和:2.4s - (4*0.2s) = 2.4s - 0.8s = 1.6s
2、Non-first Throughput:(128-4) / 1.6 = 124/1.6 ≈ 77.5 Tokens/s
3、E2E Throughput:128 / 2.4 ≈ 53.3 Tokens/s
优化方向
硬件:利用昇腾NPU的向量计算单元加速矩阵运算。
模型:优化首Token生成逻辑(如预加载部分计算)。
调度:增大Batchsize以提升硬件利用率,但需平衡内存使用。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 14
14 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)