
Qwen3系列模型在Vllm scend下的系统可视化设计和性能优化
我们在2025年9月,基于vllm ascend框架,部署Qwen3-235B模型,对某企业的推理场景进行了性能调优(Attn:DP4TP4),性能达到0.94~1.87倍H800(Attn:TP16)。在这之后,基于Qwen3-235B模型上的调优经验,在Qwen3-30B上进行了类似配置下的测试,但vllm ascend(Attn:DP4)性能仅在0.6~0.7倍H800(Attn:TP4)。
1 背景
Qwen系列开源模型在业界影响力较大,大部分互联网企业都基于Qwen3模型基座进行微调或后训练。我们在2025年9月,基于vllm ascend框架,部署Qwen3-235B模型,对某企业的推理场景进行了性能调优(Attn:DP4TP4),性能达到0.94~1.87倍H800(Attn:TP16)。在这之后,基于Qwen3-235B模型上的调优经验,在Qwen3-30B上进行了类似配置下的测试,但vllm ascend(Attn:DP4)性能仅在0.6~0.7倍H800(Attn:TP4)。于是我们在Vllm上新增了维测打点,通过对推理过程的详细分析,去探究不同场景下性能的一些关键规律。
2 场景分析
2.1 推理场景负载和配置
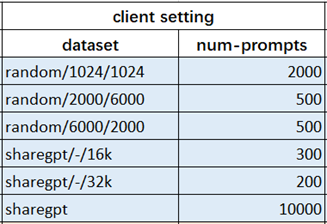
某企业提炼了主流的几类推理场景如下表所示:
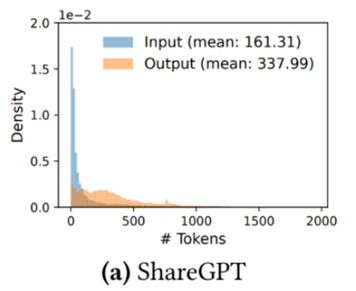
Sharegpt数据集的输入输出长度分布如下图所示,主流的典型长度都小于500(tokens)。
Vllm ascend默认配置chunk prefill打开,chunk size配置2048;235B性能优化时我们按照单板KV池子大小配置batch数,确保不触发重计算;为了充分利用HBM容量,配置A3单机切分方式为Attention DP4TP4,MoE TP16。而客户在H800上的配置没有打开chunked refill,decoder batch size统一配置为1024(长序列下容易触发重计算),TP8切分。因此我们围绕DP/TP切分、重计算和chunked prefill这三个特性,设计和开发了性能维测,以分析清楚不同场景下的性能差异。
2.2 DP/TP切分
Qwen3-30B开启DP后性能与Qwen3-235B相比收益较小。以2k输入、6k输出场景为例,按照预留的kv cache计算可配置的最大bs,性能如下表所示:

可以发现Qwen3-235B 开启DP4后,端到端吞吐相比纯TP切分提升了161%,但是在Qwen3 30B上,开启DP的收益很小。
对比KV Cache容量,在Qwen3-235B上开启DP后的KV Cache容量是TP切分的3.5倍,因此支持的最大bs能到256,但是TP只能到72,这是因为,Qwen3的num kv heads是4,当使用TP16切分的时候,KV的头会冗余4倍,而在DP4TP4的切分下,每张卡刚好一个头,因此显存的收益较大。 30B由于推理仅用双卡四die,在A3 上attention DP4和TP4,实际上KV Cache容量没有太大差异,能支持的最大bs基本相当。
为了看清楚DP4和TP4在VLLM上的性能差异,我们将推理分为三种状态,分开统计耗时:纯prefill、chunked prefill、纯decoder,通过对forward耗时维测打点后我们统计了下性能数据(单位ms):

可以看到(TP4下应该有1次纯prefill的耗时未抓到):
1、DP4下,prefill推理耗时比TP有明显下降。由于本次测试chunked size配置为2048,DP4场景下相当于2048*4=8192,而TP域仅为2048,导致了DP和TP切分下prefill生产能力的较大差异。
2、decode性能,DP4相对TP4增益不大,提升了2%左右。
3、当前场景是短输入长输出,decoder性能占了主导,最终增益端到端约6%。
为了看清decoder的性能差异,我们进一步分析了不同DP域的调度行为,发现存在少量时刻DP域之间状态的不同步。下图左半为DPrank0的性能指标,右半为DPrank2的,标黄时刻有的DP域在做decode,有的DP域在做prefill,而做decode的DP域会等待做prefill的DP域,影响了端到端的性能增益。
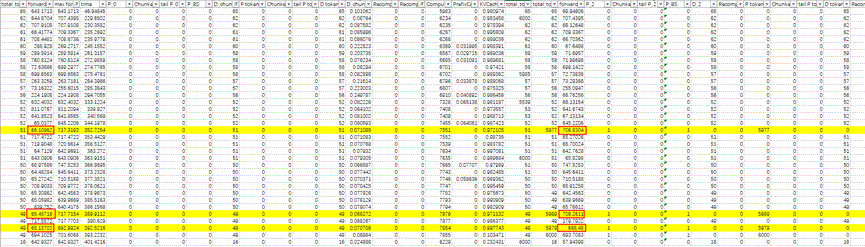
该维测能有效帮我们看出服务化下DP负载不均衡的现象,并进一步定位到是不同DP域调度类别差异导致,需要尽量保证各DP域调度负载相当,在吞吐优先的场景下新业务请求到达时可以适当攒一攒。
2.3 重计算
本章节我们重点分析重计算在不同场景下的性能增益差异。
2.3.1 长序列下避免重计算并不是最优性能
我们发现在输入2k输出6k这个场景,根据历史经验为了提升端到端吞吐去限制bs从而避免重计算的性能反而没有不限制并发的性能好。如下表,不限制bs的端到端性能比限制了bs的性能提升了15%。

我们推测,在输出长序列下,由于decode占主导性能,可以适当地增加decode 的batch size去提高decode 吞吐,只要重计算的损耗小于这部分性能提升就能达到端到端性能提升的目标。为了证明这个猜想,我们在之前基础P和D性能维测的基础上,增加了每次forward重计算token的数量,以及Kv Cache利用率的变化(用来判断当前Kv Cache的容量,更好地找到重计算开始的位置)。
为了看清楚不同并发下,重计算对端到端性能的影响我们挑选了几个bs进行了测试,结果如下:

可以发现随着并发的增加,端到端的时延在逐步变好,通过维测指标我们画出了decode batch size随时间变化的图:
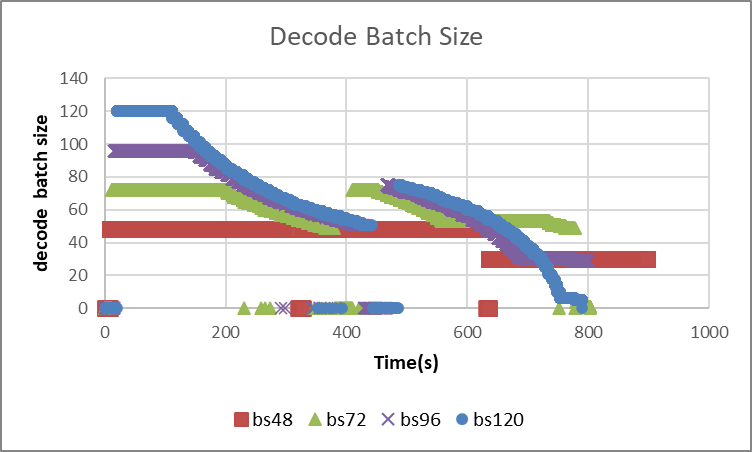
如图,由于总请求数为500条,最大并发48*4(DP)=192时,在推理的最后就会多一个bs 100+的拖尾阶段,导致整体的吞吐有所下降 。而在不限制bs的时候,推理开始阶段能够打更高的decode batch size,然后kv cache利用率满之后,会一点一点丢掉请求,直到能推完完整的请求。接着,会进入重计算阶段,再重新打到一个比较高的bs,然后逐步完成所有请求。整个过程,和猜想的一样,相当于用重计算的时间去换取更高的decode吞吐,只要decode的高吞吐收益能够掩盖重计算的损失,就能得到更好的端到端时延。
然后此时,我们看到从bs 48*4~128*4,性能都在一直提升,我们怀疑当重计算达到一定量级时,性能会出现下滑,因此随着batch 提升一定是有一个拐点的,由于之前数据总量限制,这次我们将测试的总prompt数增加到800条,测试了DP4下,每个DP域bs 48、120、200几组作为对比。

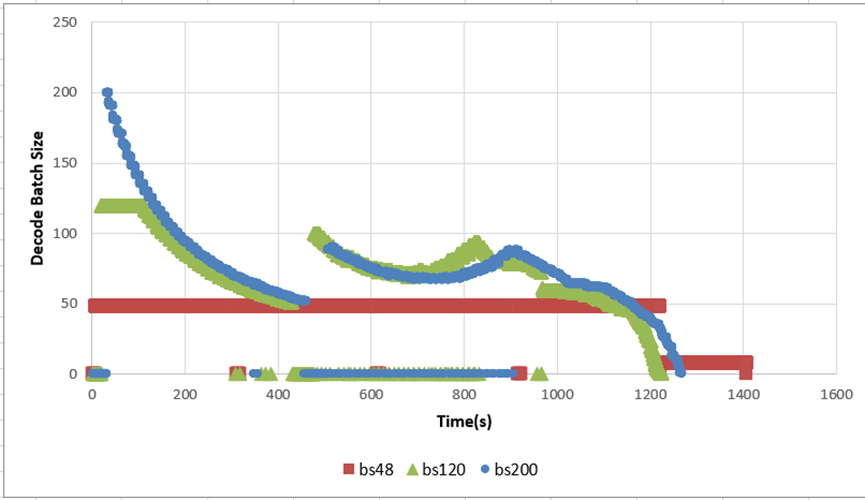
如图当bs打到bs200时,和预期一致,端到端性能劣化了。可以看到,当batch size打到200之后,在开始阶段,更多的请求进入第一轮推理,但实际上这些请求最后都会被丢弃掉并在后段进入重计算,更多的重计算耗时抵消了高bs的收益。
因此该场景下,考虑到重计算和高bs的平衡,不能将bs无限制的往上打,最好的性能在bs125左右。
总结:在短输出长输出下,由于decode 性能占主导,平衡好重计算和打高batch size带来的吞吐收益,可以帮助优化模型端到端性能,建议并发设置在根据KV Cache容量计算得到的最大bs数的2~3倍。
2.3.2 短输出的场景下,避免重计算性能较好
根据上一章节的经验,放开重传约束打高decoder bs会带来性能优化,所以我们在测试输入1k输出1k的场景时,如下图进行了最大bs 200*4、300*4、400*4、500*4 4组对比测试。但是测试发现,在该场景下,打高bs反而带来了性能劣化。

实际根据测试我们发现不仅时1k/1k场景,也在6k/2k、sharegpt数据集(平均输入输出200)的场景下发现了同样的现象,只要涉及到了重计算,端到端就会劣化,与之前长序列下的结论完全相反。我们推测,由于不限制bs当KV Cache满时会丢掉之前做的P和一部分D,会导致之前做的prefill计算要重新计算一次,prefill的耗时在端到端耗时占比越大,重计算带来的负面开销会在当前场景下更凸显。
我们可以通过这套维测指标进行统计,可以发现在这几个场景中prefill耗时在端到端占比从16~32%不等,长序列输出场景的占比为1.7%-8.03%。

然后我们去拆解了1k、1k场景下,bs200和bs300的性能差异,当bs300时,可以看到虽然decode的总耗时减少了,但是重计算带来27s的额外开销,占到了端到端性能的11%以上了,这也证明了在该场景下,确实应该尽量避免重计算。

综上,建议在短输入长输出场景,Prefill耗时占比低于10%的场景,放开最大bs约束,通过重计算可获得整体的性能提升。
2.3.3 DP与重计算配合异常
基于2.3.1的经验,我们判断长输出场景放开重计算有一定性能增益,于是我们测试了输入sharegpt输出16k场景,但意外的是在不限制bs时,性能劣化严重,与之前在输入2k输出6k下得到的不限制bs性能会提升的结论相反。

于是,我们使用这套维测打点,进行详细分析。我们发现在KV Cache利用率快满的时候,有的decode的时延达到了9000+ms。正常情况下,即使由于DP域不均衡,其他DP域decode的性能也应该在800ms上下,属于chunk后的2k prefill的正常时延范围。
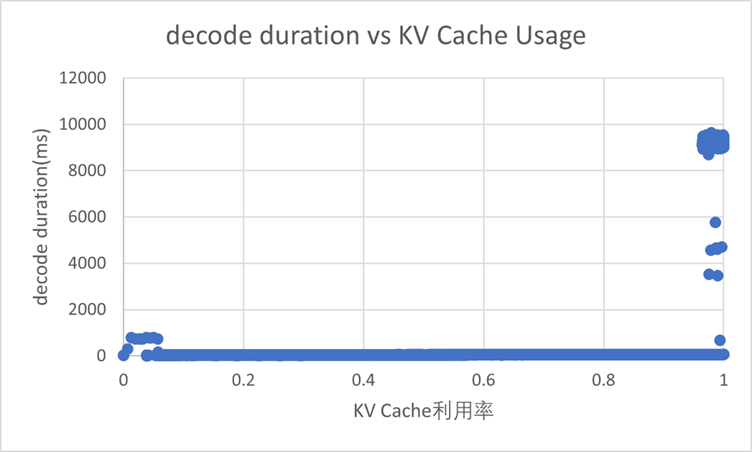
通过细致的对表格进行对比我们发现,这些异常值都是出现在有DP域重计算的时候,kv基本打满。
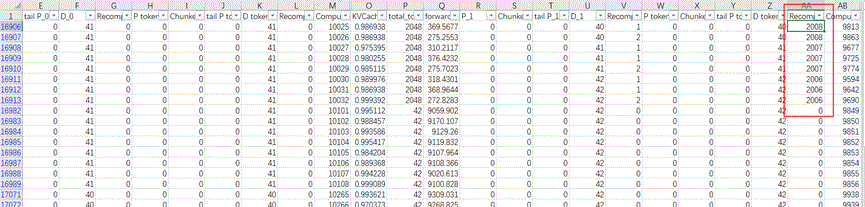
这些性能异常的原因暂时还没定位到,当前版本建议在DP场景下尽量避免重计算来规避这个问题。
2.4 Chunked Prefill
在输出64k的场景,模型warmup时如果不开启chunked prefill,会按照64k的最大序列长度去warmup,这会导致gmm部分的激活值非常大,从而降低了KV Cache的容量。通过服务化日志打屏的kv cache block num指标发现,在开启chunked prefill后,KV Cache的空间多了29%。

接着,根据实际的测算,开启Chunked Prefill后,端到端时间确实提升了11%左右。

3 系统打点维测
以下为该维测打点在Vllm代码里的添加位置和相关解析代码,以及维测指标输出的变量含义解释。
3.1 性能DFX设计
当需要深入分析不同场景下的性能时,需要区分当前调度的状态为prefill还是decoder,每个状态需要统计推理耗时、bs、tokens:
1、需要考虑跟DP的配合,因此维测按每个DP域打点;
2、需要考虑跟chunked prefill的配合,将prefill状态区分为:完整的prefill(P)、截断未结束的prefill(chunked P)、截断的最后一个prefill(tail P);
3、需要考虑跟重计算的配合,打印重计算的bs和tokens;
4、需要考虑kv的状态,打印本次调度本DP域的kv left和本次decoder调度的历史kv seq len;
5、需要考虑跟prefix cache的配合,打印prefix cache的命中率;
最终每个DP域每次调度时的维测统计指标输出excel如下表格式所示,获取了详细数据后可以按照我们希望的维度进行透视分析。
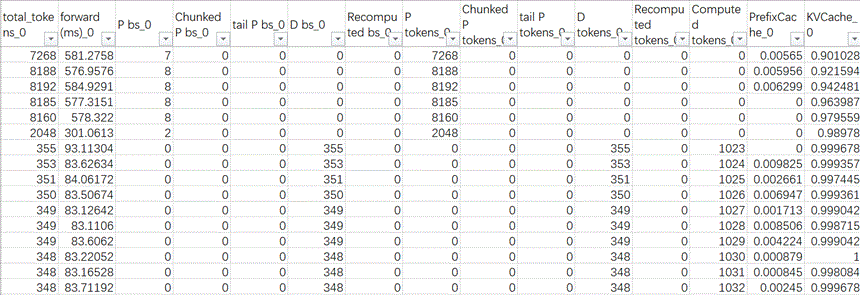
3.2 输出变量含义解释
|
参数 |
参数含义 |
|
total_tokens_0 |
本次推理的总token数 |
|
forward (ms)_0 |
本次推理的forward耗时 |
|
P_BS_0 |
本次推理的prefill batch size |
|
Chunked P_BS_0 |
本次推理的prefill中,被chunk的请求batch size |
|
tail P_BS_0 |
本次推理的prefill中,之前被chunk的请求,剩余的tail batch size |
|
D_BS_0 |
本次推理的decode batch size |
|
Recomputed_bs_0 |
本次推理中重计算的batch size |
|
P tokens_0 |
本次推理中未被chunk的prefill token数 |
|
Chunked P tokens_0 |
本次推理中被chunk的prefill token数 |
|
tail P tokens_0 |
被chunk后的tail prefill token数 |
|
D tokens_0 |
decode生成的token数 |
|
Recomputed tokens_0 |
重计算的token数(包含此请求参与重计算的prefill和decode token总和) |
|
Computed tokens_0 |
参与本次推理的请求,本次推理完成后,已经推理的kv长度 |
|
PrefixCache_0 |
PrefixCache命中率 |
|
KVCache_0 |
kv cache利用率 |
|
注:后缀的0代表0卡,qwen3-30b使用4卡进行推理,采集会有4张卡 |
|
3.3 维测代码添加
下文涉及的代码链接:
https://github.com/yifeililn/vllm/pull/1/files
https://github.com/yifeililn/vllm-ascend/pull/1/files
3.3.1 修改点1
修改文件:/vllm-workspace/vllm-ascend/vllm_ascend/worker/model_runner_v1.py
修改内容(对应函数添加===add monitor===扩起来的代码):打印每次forward时 P、D、chunkP、重计算的bs和token数
with ProfileExecuteDuration().capture_async("prepare input"):
self._update_states(scheduler_output)
=========================================add monitor=============================
logger.info(f"====================rank: {torch.distributed.get_rank()} "
f"scheduler_output.num_scheduled_tokens: {sum(scheduler_output.num_scheduled_tokens.values())}")
P = []
chunked_P = []
tail_P = []
D = []
Recomputed = []
Computed = []
for req_id_ in scheduler_output.num_scheduled_tokens.keys():
if req_id_ in scheduler_output.scheduled_cached_reqs.req_ids and scheduler_output.scheduled_cached_reqs.resumed_from_preemption[scheduler_output.scheduled_cached_reqs.req_ids.index(req_id_)]:
Recomputed.append(scheduler_output.num_scheduled_tokens[req_id_])
elif self.requests[req_id_].num_computed_tokens == 0 and scheduler_output.num_scheduled_tokens[req_id_] == self.requests[req_id_].num_prompt_tokens:
P.append(scheduler_output.num_scheduled_tokens[req_id_])
elif self.requests[req_id_].num_computed_tokens + scheduler_output.num_scheduled_tokens[req_id_] < self.requests[req_id_].num_prompt_tokens:
chunked_P.append(scheduler_output.num_scheduled_tokens[req_id_])
elif self.requests[req_id_].num_computed_tokens + scheduler_output.num_scheduled_tokens[req_id_] == self.requests[req_id_].num_prompt_tokens:
tail_P.append(scheduler_output.num_scheduled_tokens[req_id_])
elif scheduler_output.num_scheduled_tokens[req_id_] > 1:
Recomputed.append(scheduler_output.num_scheduled_tokens[req_id_])
else:
D.append(scheduler_output.num_scheduled_tokens[req_id_])
if self.requests[req_id_].num_computed_tokens > 0:
Computed.append(self.requests[req_id_].num_computed_tokens)
if len(Computed) > 0:
average_computed = sum(Computed) // len(Computed)
else:
average_computed = 0
logger.info(f"====================rank: {torch.distributed.get_rank()} "
f"P: [{len(P)}, {sum(P)}]; "
f"Chunked P: [{len(chunked_P)}, {sum(chunked_P)}]; "
f"tail P: [{len(tail_P)}, {sum(tail_P)}]; "
f"D: [{len(D)}, {sum(D)}]; "
f"Recomputed: [{len(Recomputed)}, {sum(Recomputed)}]; "
f"Computed: [{len(Computed)}, {average_computed}]; "
)
=========================================add monitor=============================3.3.2 修改点2
修改文件:/vllm-workspace/vllm/vllm/v1/core/sched/scheduler.py
修改内容(对应函数添加===add monitor===扩起来的代码):打印Kv Cache利用率
def make_stats(
self,
spec_decoding_stats: Optional[SpecDecodingStats] = None,
) -> Optional[SchedulerStats]:
if not self.log_stats:
return None
prefix_cache_stats = self.kv_cache_manager.make_prefix_cache_stats()
assert prefix_cache_stats is not None
=========================================add monitor============================= logger.info(f"====KVCacheUsage: {self.kv_cache_manager.usage}; PrefixCache: {0 if prefix_cache_stats.queries == 0 or prefix_cache_stats.requests == 0 else prefix_cache_stats.hits/prefix_cache_stats.queries}")
return SchedulerStats(
num_running_reqs=len(self.running),
num_waiting_reqs=len(self.waiting),
kv_cache_usage=self.kv_cache_manager.usage,
prefix_cache_stats=prefix_cache_stats,
spec_decoding_stats=spec_decoding_stats,
num_corrupted_reqs=sum(req.is_output_corrupted
for req in self.running),
)
=========================================add monitor=============================3.3.3 修改点3
修改文件:/vllm-workspace/vllm-ascend/vllm_ascend/models/qwen3_moe.py
修改内容:在模型forward前后用cuda events进行性能打点统计
import torch_npu
event1 = torch_npu.npu.Event(enable_timing=True)
event2 = torch_npu.npu.Event(enable_timing=True)
event1.record()
hidden_states = self.model(input_ids, positions, intermediate_tensors,
inputs_embeds, _metadata_for_padding)
event2.record()
torch.npu.synchronize()
duration = event1.elapsed_time(event2)
from vllm.logger import logger
logger.info(f"==========================rank: {torch.distributed.get_rank()} forward time: {duration} ms") 3.3.4 维测数据解析
在vllm推理完成后,使用解析脚本对之前服务化打印的维测信息日志进行解析,并生成csv文件。其中input_path为vllm日志路径,output_path为生成的csv文件路径
parse.py文件内容:
import re
import pandas as pd
world_size = 4
input_path = "log_dp4_6k2k_152.log"
output_path = "chunked_close_6k_2k_bs48.csv"
match_ = {0: r"scheduler_output.num_scheduled_tokens: (\d+)",
1: r"P: \[(\d+), (\d+)\];\s+"
r"Chunked P: \[(\d+), (\d+)\];\s+"
r"tail P: \[(\d+), (\d+)\];\s+"
r"D: \[(\d+), (\d+)\];\s+"
r"Recomputed: \[(\d+), (\d+)\];\s+"
r"Computed: \[(\d+), (\d+)\];\s+",
2: r"forward time: (\d+\.\d+) ms",
3: r"KVCacheUsage: (\d+\.\d+|\d+); PrefixCache: (\d+\.\d+|\d+)"}
dfs = []
with open(input_path, "r") as f:
lines = f.readlines()
for rank in range(4):
save_ = {
"total_tokens":[],
"forward (ms)":[],
"P_BS":[],
"Chunked P_BS":[],
"tail P_BS":[],
"D_BS":[],
"Recomputed_bs":[],
"P tokens":[],
"Chunked P tokens":[],
"tail P tokens":[],
"D tokens":[],
"Recomputed tokens":[],
"Computed tokens":[],
"PrefixCache":[],
"KVCache":[]
}
lines_ = [line for line in lines if f"=====rank: {rank}" in line or f"====KVCacheUsage" in line]
count = 0
for line in lines_:
matched = re.search(match_[count], line)
if matched:
if count == 0:
save_["total_tokens"].append(matched[1])
count+=1
elif count == 1:
save_["P_BS"].append(matched[1])
save_["P tokens"].append(matched[2])
save_["Chunked P_BS"].append(matched[3])
save_["Chunked P tokens"].append(matched[4])
save_["tail P_BS"].append(matched[5])
save_["tail P tokens"].append(matched[6])
save_["D_BS"].append(matched[7])
save_["D tokens"].append(matched[8])
save_["Recomputed_bs"].append(matched[9])
save_["Recomputed tokens"].append(matched[10])
save_["Computed tokens"].append(matched[12])
count+=1
elif count == 2:
save_["forward (ms)"].append(matched[1])
count+=1
elif count == 3:
save_["KVCache"].append(matched[1])
save_["PrefixCache"].append(matched[2])
count =0
max_len = len(save_['total_tokens'])
for k, v in save_.items():
max_len = min(max_len, len(v))
save_ = {k:v[:max_len] for k, v in save_.items()}
df = pd.DataFrame(save_)
df = df.add_suffix(f"_{rank}")
dfs.append(df)
df_total = pd.concat(dfs, axis=1)
df_total.to_csv(output_path, index=False)4 总结
基于vllm ascend推理引擎,我们设计了一套性能运维指标,根据不同场景的维测数据结果分析,提炼出一套qwen3 30B模型的典型性能配置,相比基线默认配置吞吐增益达到10%以上:
1、短输入长输出场景,TP4,max bs约束配置为约2倍+kv容量,开启chunked prefill;
2、其他场景,DP4,max bs约束配置为1倍kv容量,关闭chunked prefill。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 36
36 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)