
veRL异步异卡方案考古
作者:昇腾实战派
一、异步异卡概念澄清
异卡和共卡
训练和推理两个任务是否在同一张卡上。对应的准确表达是Disaggregated 和 colocated。为啥不把中文一一对应,因为colocated也有是共位还是共卡的歧义。
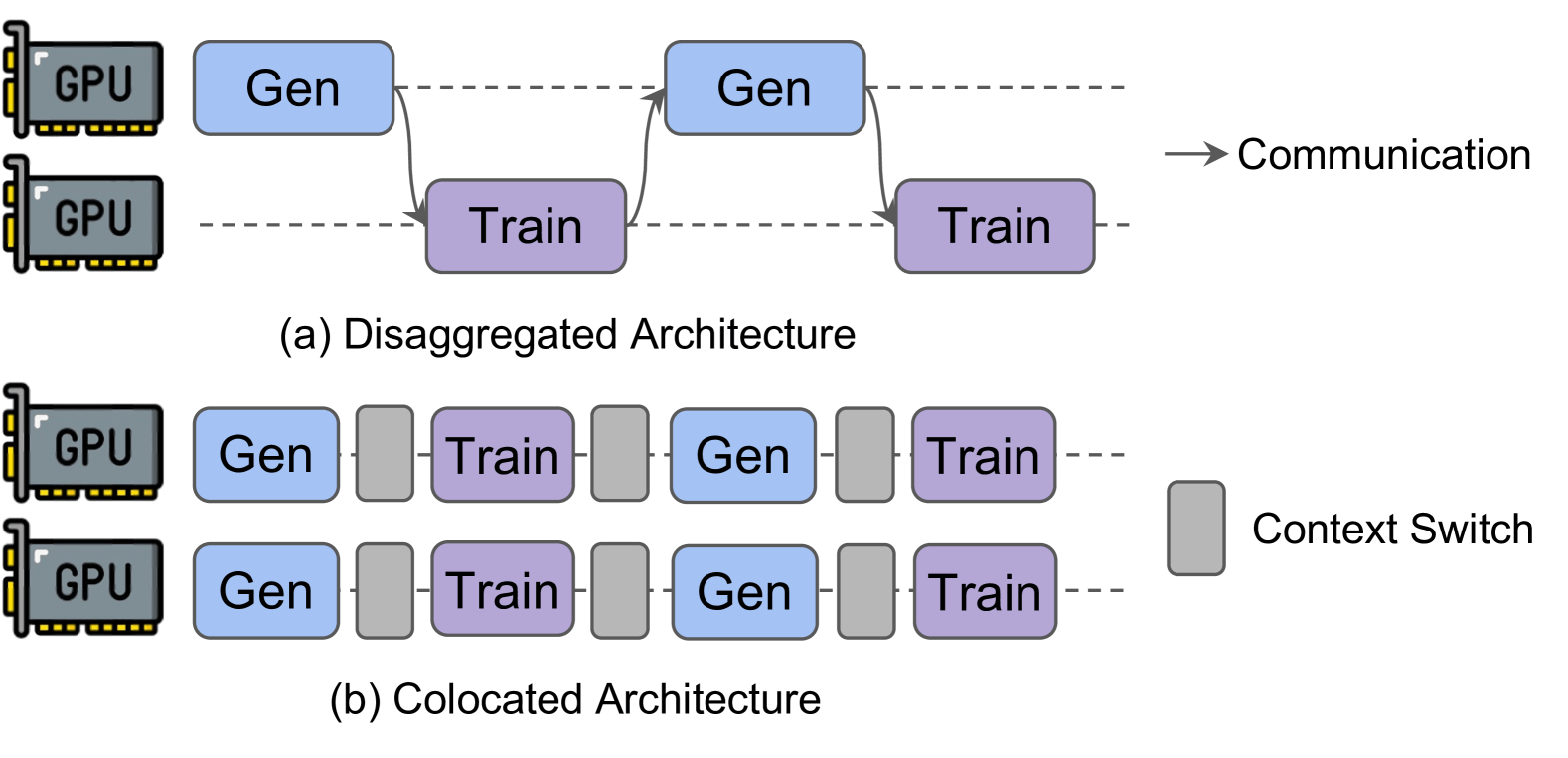
因为共卡这个词,是盘古提出的RL Fusion,认为和colacated的区别在于支持共卡的灵活部署,支持训推有不同的切分策略,但是感觉现在的veRL里应该默认都支持了。所以现在colocated、fusion、共卡、共位好像是同一个词了。后面就只说异卡和共卡了。
异卡的好处在于可以各干各的,为后面的异步提供基本保证,但是需要通信。
共卡的好处就是都在一张卡上干,通信量少,resharding啥的成本不高。坏处就是不可避免要在卡间进行同步等待,全部推理结束才能训练,容易受长尾问题影响(如果有一项技术可以让不同节点分时启动训练,或者共卡下的推理负载均衡,那就也能解决这个坏处)
异步和同步
这里指的也是训推间的关系,是否需要相互等待阻塞。同步方法就是,得先rollout才能进行后续的训练,这也符合RL的流程定义。而异步则是指训推两个流程没有直接的依赖和阻塞关系,训练和推理可以同时触发任务。当然本质上训练仍然需要推理的输入,因此此时需要引入第三方进行数据的管理,训推进程只需要和数据管理交互,而不需要感知对方的工作情况。
回到这四个概念,本质上异步与否是指训推的执行顺序是否相互依赖,属于上层逻辑层面关系,而异卡与否是指他们实际使用资源的位置,是底层资源层面的关系,理论上两者是没有一定的绑定关系。但是目前的方案,基本都是基于异卡的异步,也就是说异卡是异步的前提。
参考文献
https://arxiv.org/html/2504.15930?\_immersive\_translate\_auto\_translate=1
https://gitcode.com/ascend-tribe/ascend-training-system/tree/main/RLOptimization
二、veRL异步异卡方案timeline
veRL异步异卡方案的经历了MultiTurn Rollout、AgentLoop、RecatAgentLoop、AsyncFlow TransferQueue、OnestepOff、Fully Async Policy Trainer等多轮探索创新。
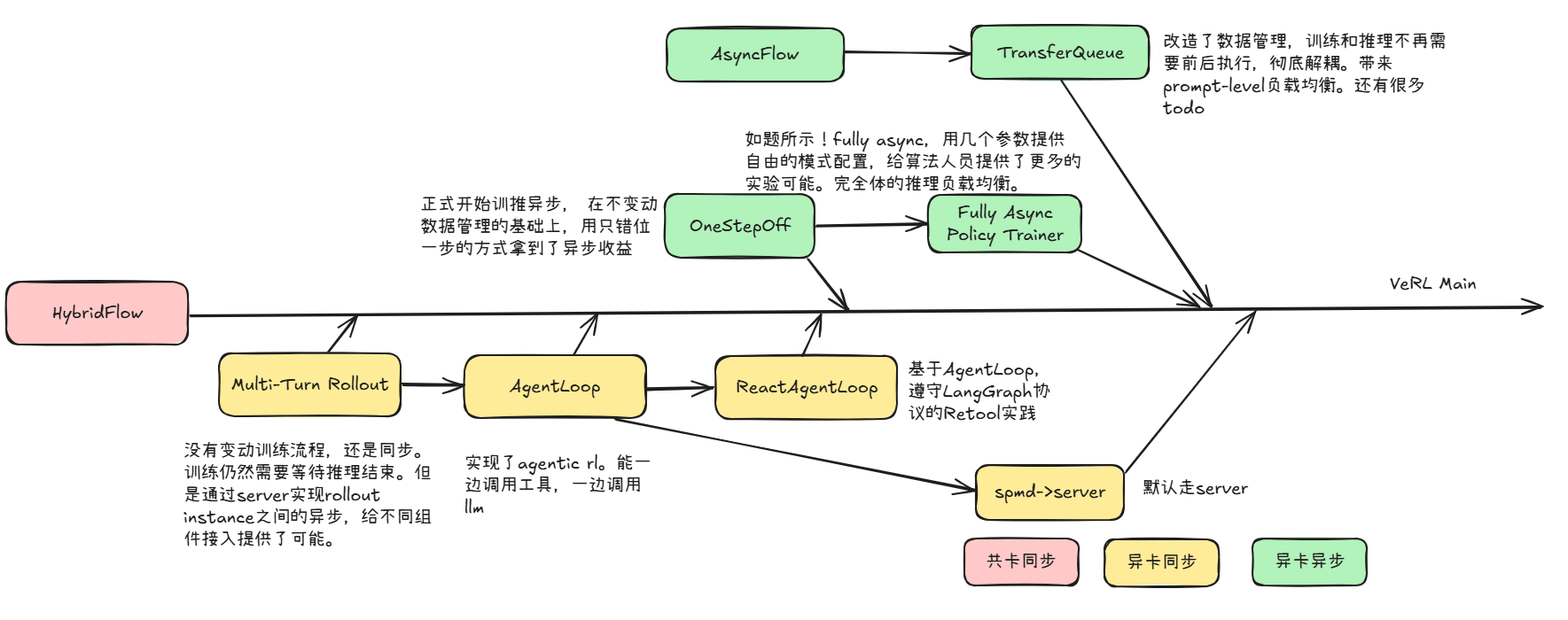
MultiTurn Rollout 4.25
原理
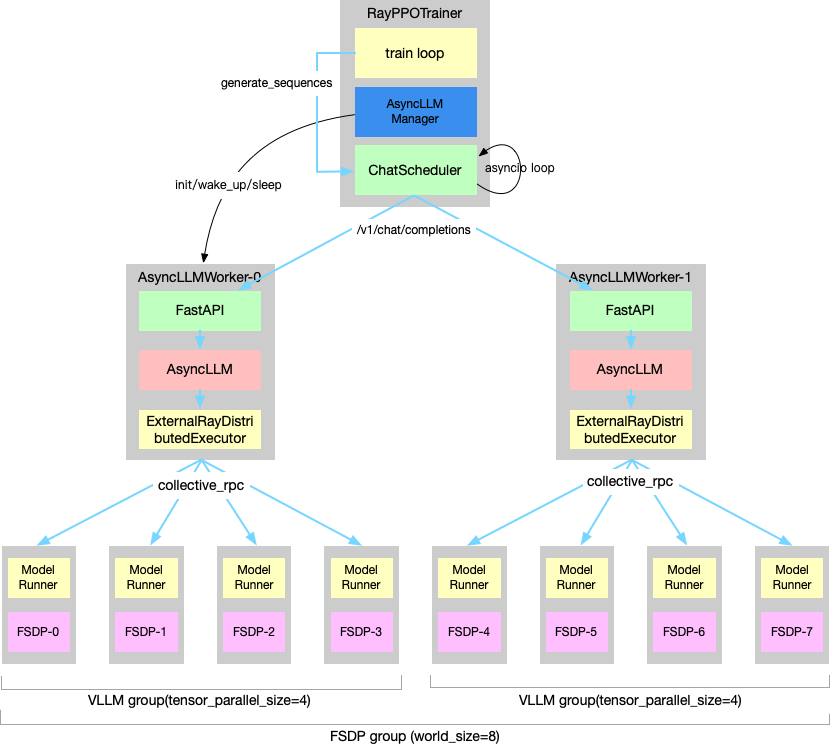
- AsyncLLMWorker: vllm server实例
- AsyncLLMServerManager: 管理实例
- ChatScheduler:跨实例的请求调度
代码使能
config.actor_rollout_ref.rollout.mode = "async"
actor_rollout_ref.rollout.chat_scheduler=examples.ppo_trainer.naive_chat_scheduler.NaiveChatCompletionScheduler意义
没有变动训练流程,还是共卡。训练仍然需要等待推理结束。但是通过server实现异步,给不同组件接入提供了可能。
参考文献
https://github.com/volcengine/verl/pull/1138
AgentLoop 6.19
原理
设计目标
- 可插拔的用户自定义AgentLoop
- 定义不同框架间的标准接口
- 在推理服务间实现requst level的负载均衡
- 不关心工具调用
把原来的AsyncLLMServerMangaer做了进一步的封装,他只关注llm server调度,往上一层AgentLoop,既可以调度llm,又可以调度别的工具
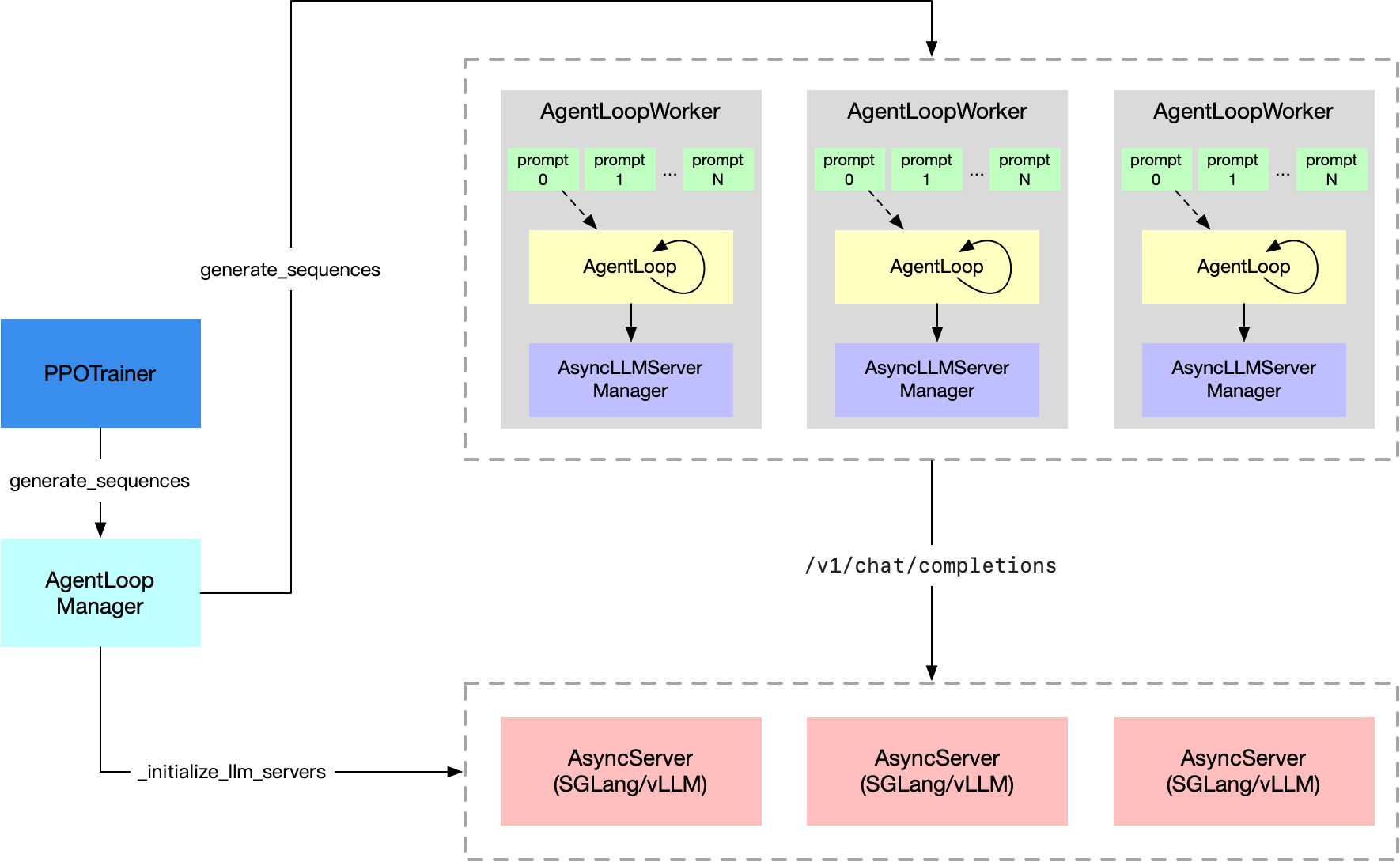
- AgentLoopBase: rollout基类,可以和llm server交互,也可以和其他环境交互,实现了目标2
- AgentLoopWorker: 继承,处理单个prompt,执行loop任务.实现了目标1
- AgentLoopManager: 获取数据,分发给AgentLoopWork,实现了目标3
- AsyncLLMServerManager: 管理多个Server,发送请求调度,和前面的工作内容保持一致
代码使能
config.actor_rollout_ref.rollout.mode = "async"意义
实现了agentic rl。能一边调用工具,一边调用llm
参考文献
6.19 [rollout] feat: add agent loop https://github.com/volcengine/verl/pull/2124
7.17 Agent loop https://github.com/volcengine/verl/blob/main/docs/advance/agent\_loop.rst
RecatAgentLoop 7.11
原理
基于AgentLoop框架,实现了实际例子LangGraph。
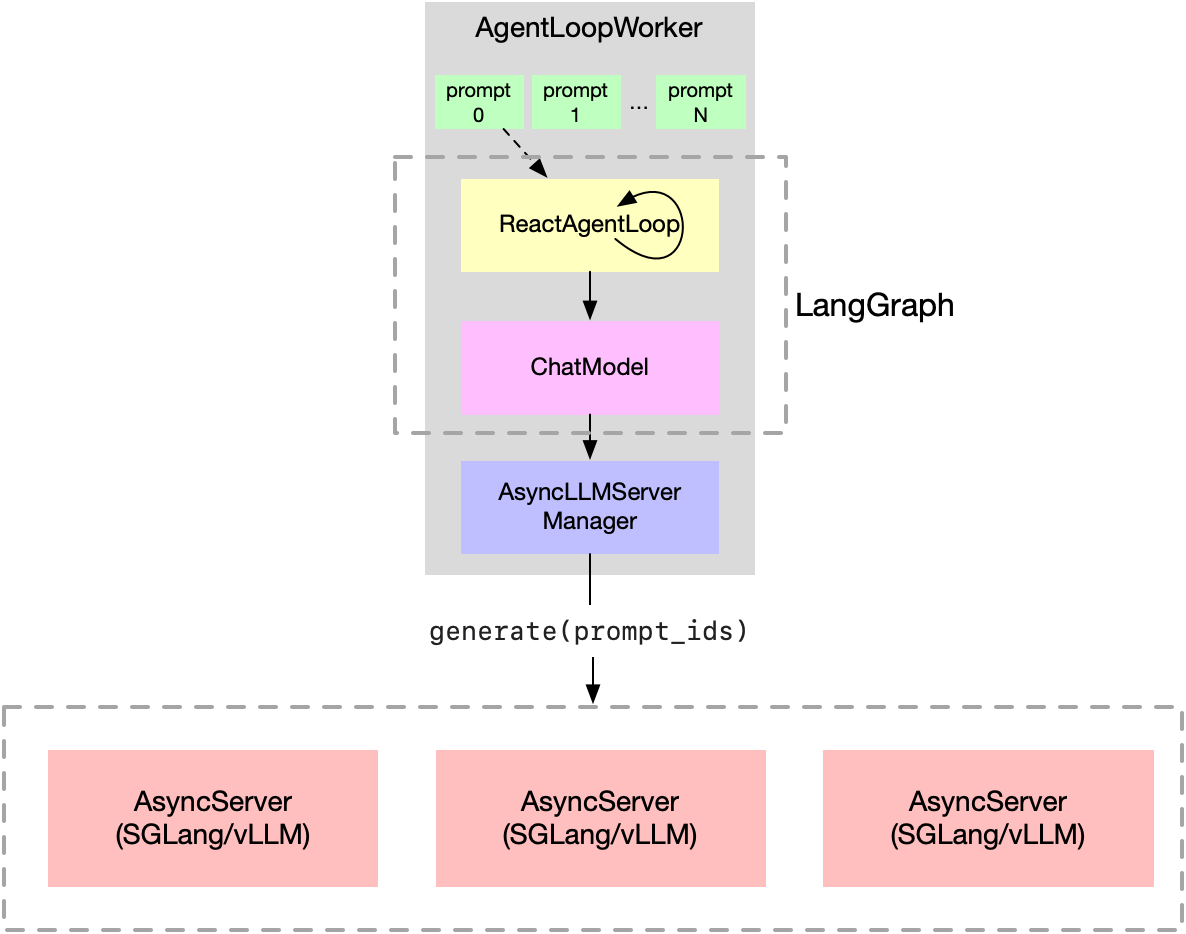
- ChatModel:按照LangGarph的协议定义了模型,能够bindtools以及generate
- ReactAgentLoop:入口,能够调用工具去执行任务
代码使能
定义工具
绑定给ReactAgent
actor_rollout_ref.rollout.mode=async \
actor_rollout_ref.rollout.agent.agent_loop_config_path=$agent_loop_config_path \意义
基于AgentLoop,遵守LangGraph协议的Retool实践
参考文献
7.15 基于Agentloop的应用,gsm8k的agentic rl训练 https://github.com/volcengine/verl/blob/main/docs/start/agentic\_rl.rst
7.11【应用】MathExpression: LangGraph Agent Example https://github.com/volcengine/verl/blob/main/recipe/langgraph\_agent/example/README.md
7.11 【应用】[rollout] feat: add ReactAgentLoop based on LangGraph https://github.com/volcengine/verl/pull/2463
AsyncFlow TransferQueue 10.20
原理
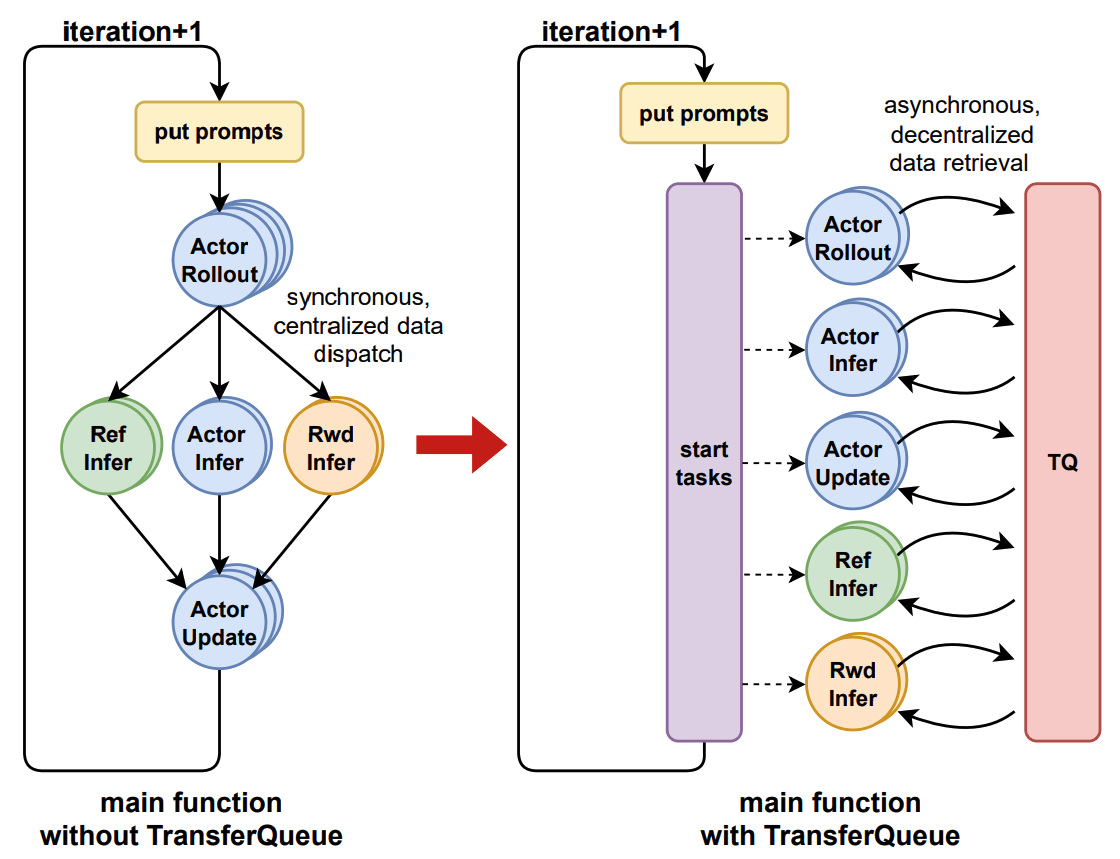
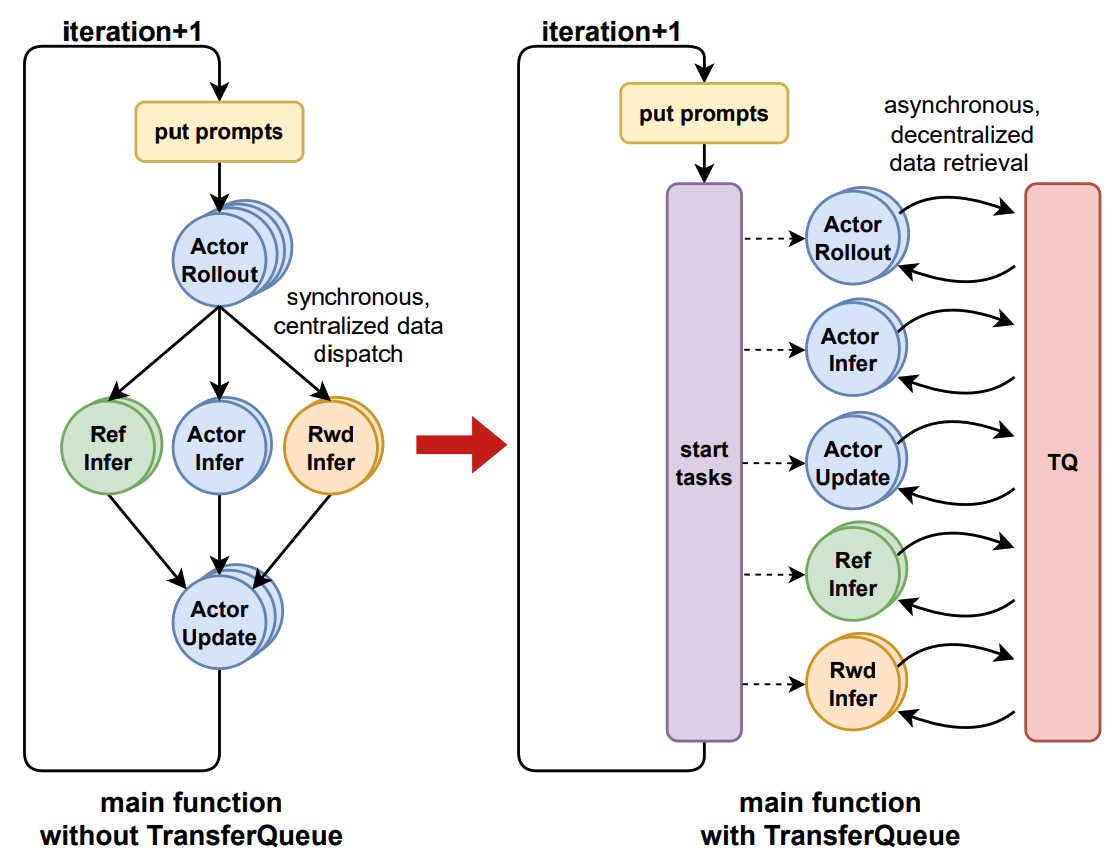
引入流式数据调度+异步强化学习算法,构建数控分离结构,用TransferQueue用于数据存储和调度,分离了数据的生产和消费。

加入TQ前后的流程对比
代码使能
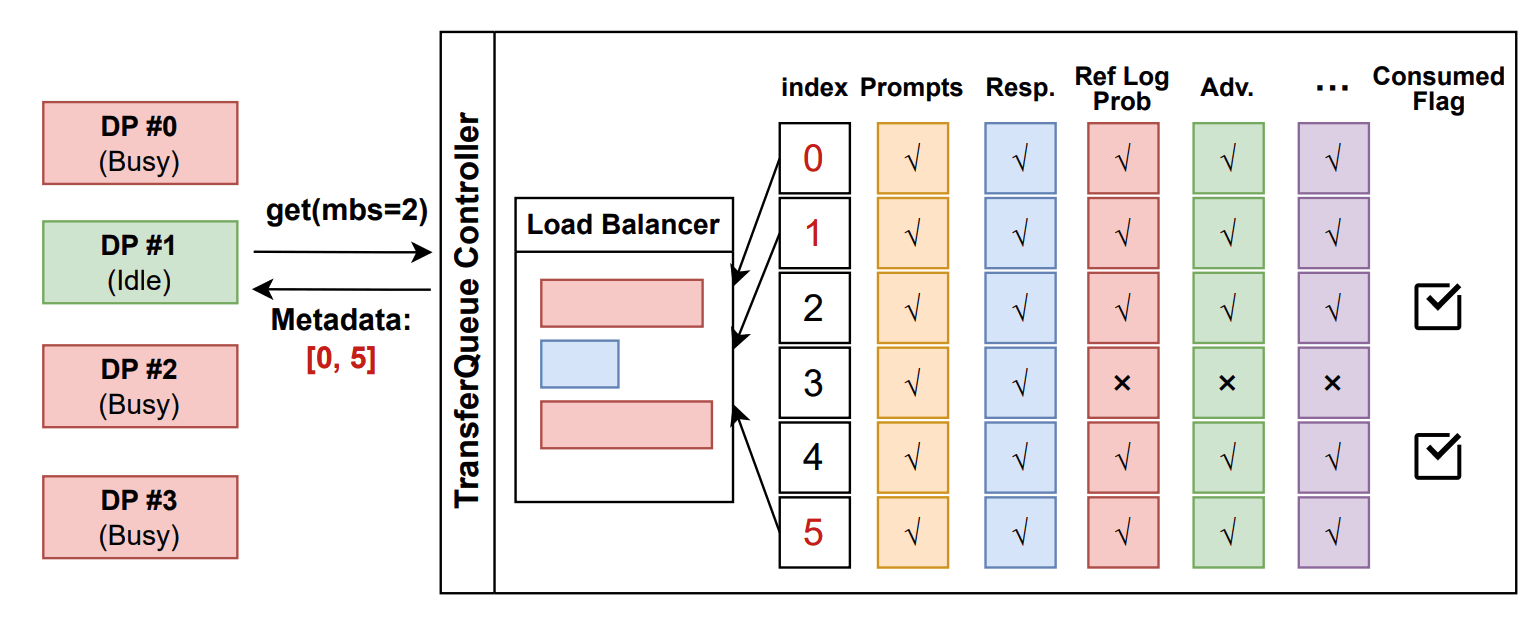
python3 -m recipe.transfer_queue.main_ppoTransferQueueController全局数据管理控制
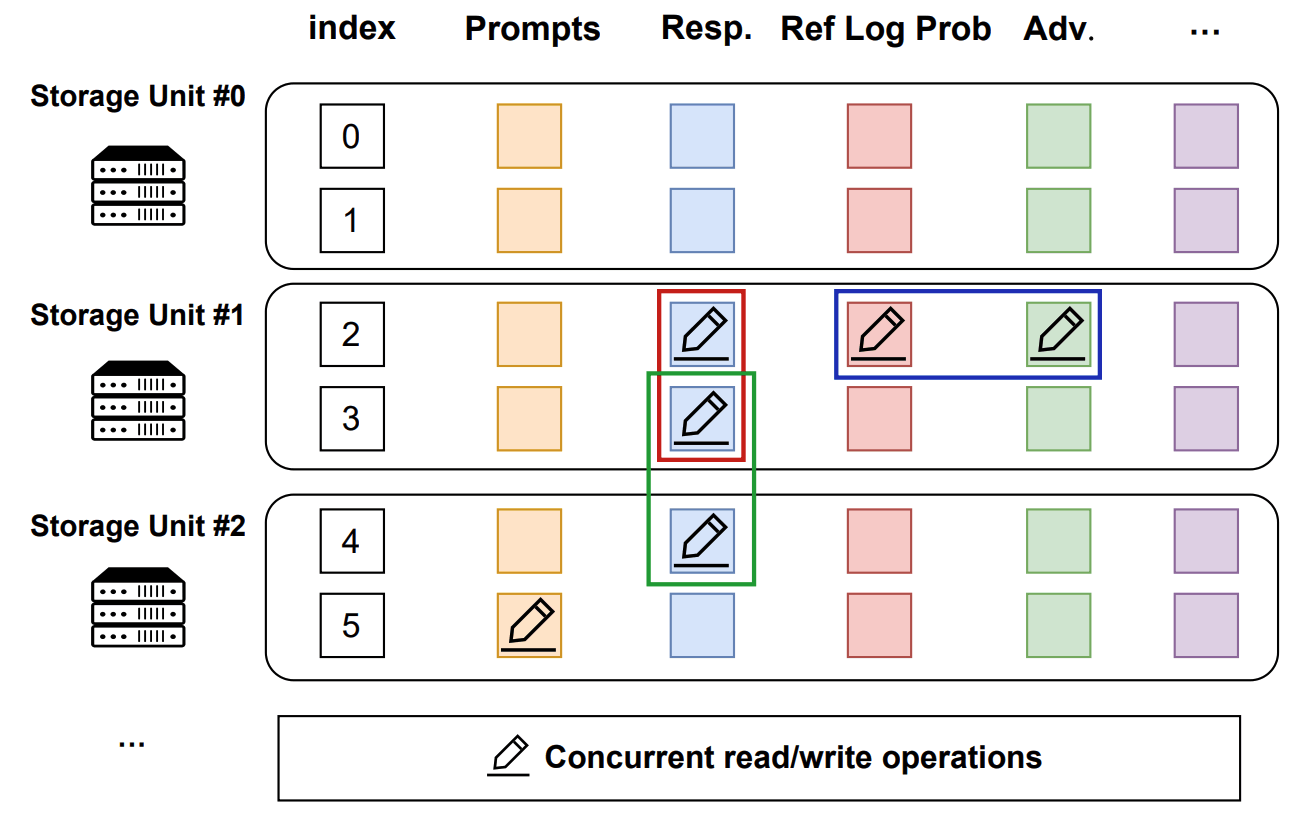
TransferQueueStorageSimpleUnit分部署数据存储
TransferQueueClient 用户界面的封装,包含整个流程
- 像TransferQueueController发送数据请求
- TransferQeueController扫描所有元数据,根据负载均衡策略,动态组合一个micro-batch的数据返回(sapmle-level的负载均衡)
- 处理数据
意义
改造了数据管理,训练和推理不再需要前后执行,彻底解耦。带来prompt-level负载均衡。还有很多todo
参考文献
0702 Asyncflow论文 https://arxiv.org/abs/2507.01663
1020 [data] feat: TransferQueue - An asynchronous streaming data management system https://github.com/volcengine/verl/pull/3649
pr对应的markdown https://github.com/volcengine/verl/blob/main/docs/data/transfer_queue.md
OnestepOff 7.17
原理
基于原来的pipeline,用最小的代价实现了异步。虽然看着变扭,单确实拿到了很多收益。

代码使能
意义
正式开始训推异步, 在不变动数据传输的基础上,用只错位一步的方式拿到了异步收益
参考文献
7.17 [trainer, fsdp, vllm, recipe] feat: one step off async training recipe https://github.com/volcengine/verl/pull/2231/files
Recipe: One Step Off Policy Async Trainer https://github.com/volcengine/verl/blob/main/docs/advance/one\_step\_off.md
Fully Async Policy Trainer 10.17
原理
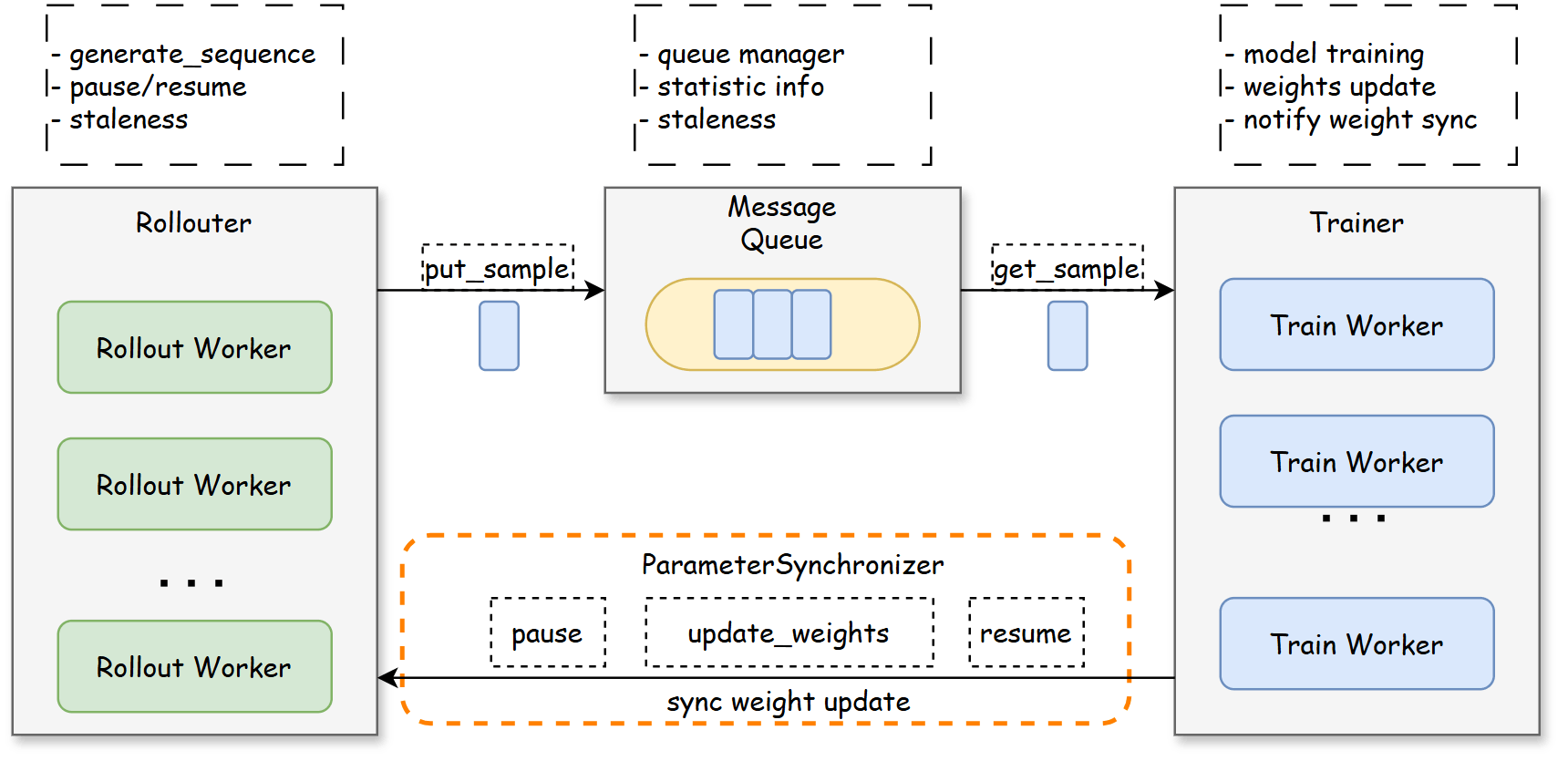
- Rollouter:生产者,逐样本生成,放入MessageQueue,生产速度收新鲜度控制。支持partialRollout,没推完的sleep下一轮接着搞。
- MessageQueue:管理数据,分发数据
- Trainer:数据消费,trigger_parameter_sync_step后进行参数同步
- ParamerSynchronizer:基于nccl实现参数同步
- 设置staleness threshold新鲜度阈值,支持基于旧参数样本进行
- prompt-level的负载均衡
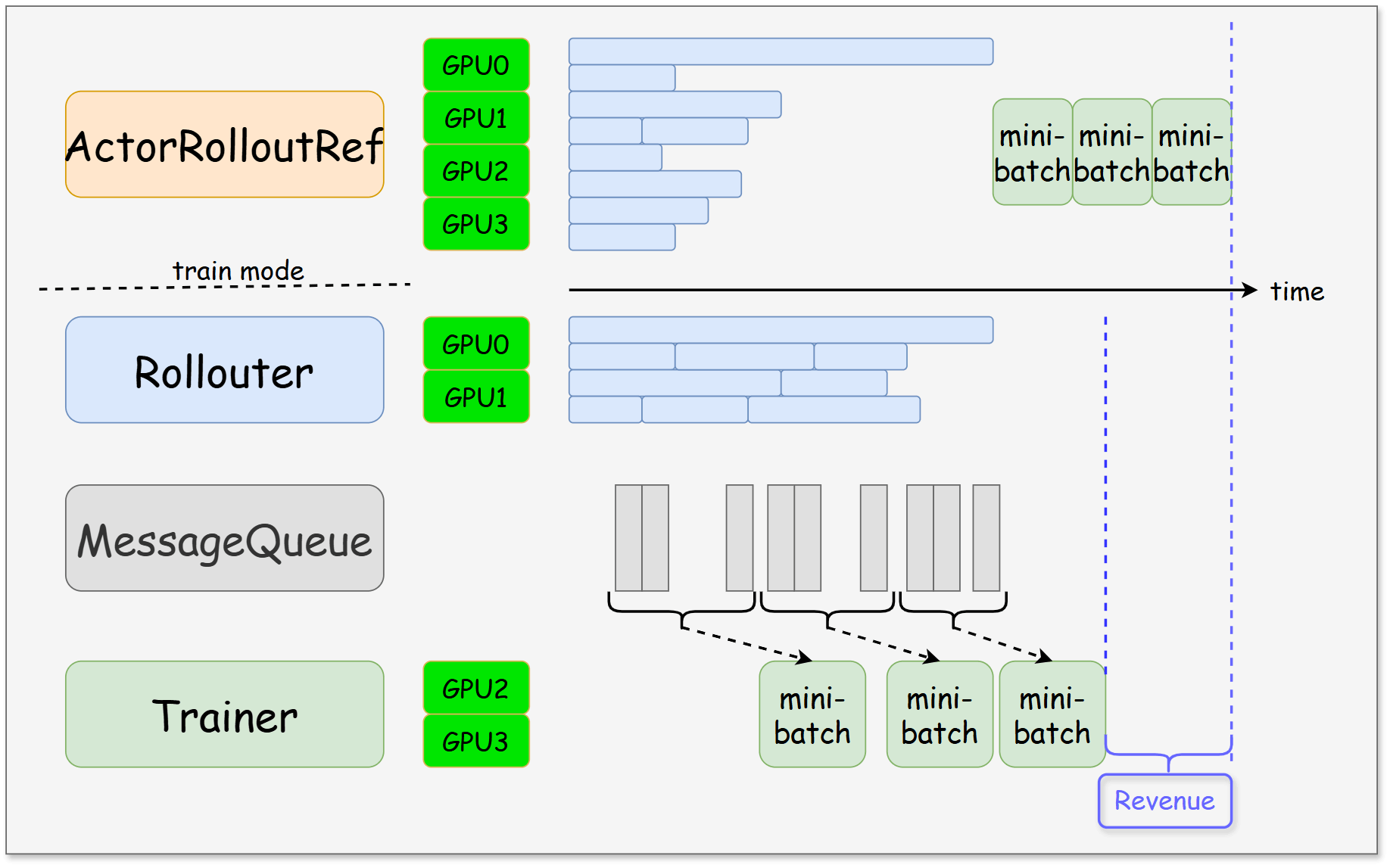
代码使能
- async_training.trigger_parameter_sync_step 设置多少次训练后进行参数同步。
- async_training.staleness_threshold 最大允许使用的staleness样本比例。0是同步,不允许使用不新鲜异步的数据
- async_training.partial_rollout 新鲜度>0的时候,可以使能
(a) step=1, threshold=0 (因为不是共卡,这种等待导致他比原来的共卡同步方案空泡更大)
(b) step>=1, threshod=0 (step=1就是onestep off)
(c) step>=1, threshod>0, partial_rollout=False 数据够了,训练过程推理也不闲着,继续推。没用完的不新鲜数据下一次接着用,areal的方案是直接扔掉
(d) step>=1. threshod>0, partial_rollout=True 没推理完数据,sleep,权重更新后接着推,也是不新鲜数据,但是没那么不新鲜
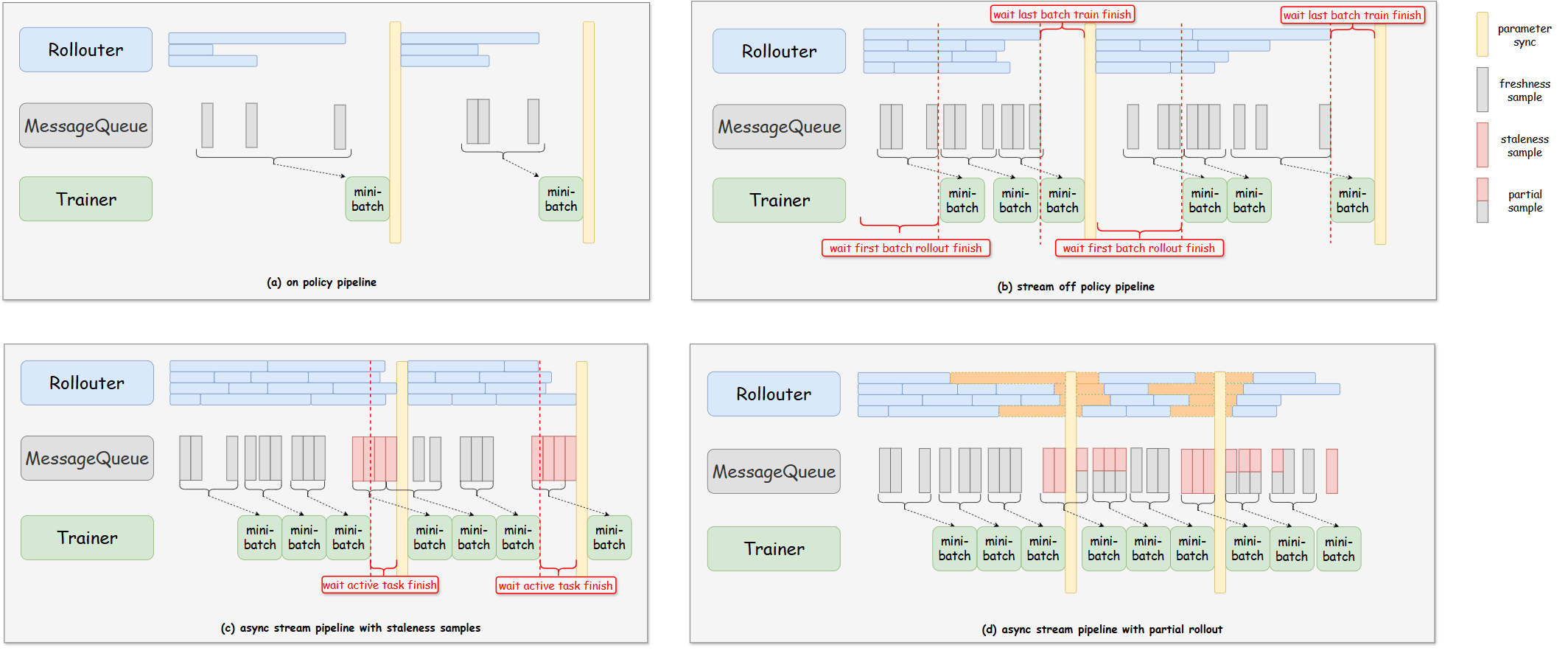
意义
如题所示!fully async,提供几个参数提供自由的模式配置,给算法人员提供了更多的实验可能。完全体的推理负载均衡。
参考文献
https://wiki.huawei.com/domains/4600/wiki/241354/WIKI202510218647683
https://github.com/volcengine/verl/blob/main/docs/advance/fully\_async.md
https://github.com/volcengine/verl/blob/main/recipe/fully\_async\_policy/README\_zh.md
10.17 [trainer, recipe] feat: fully async training recipe https://github.com/volcengine/verl/pull/2981
总结
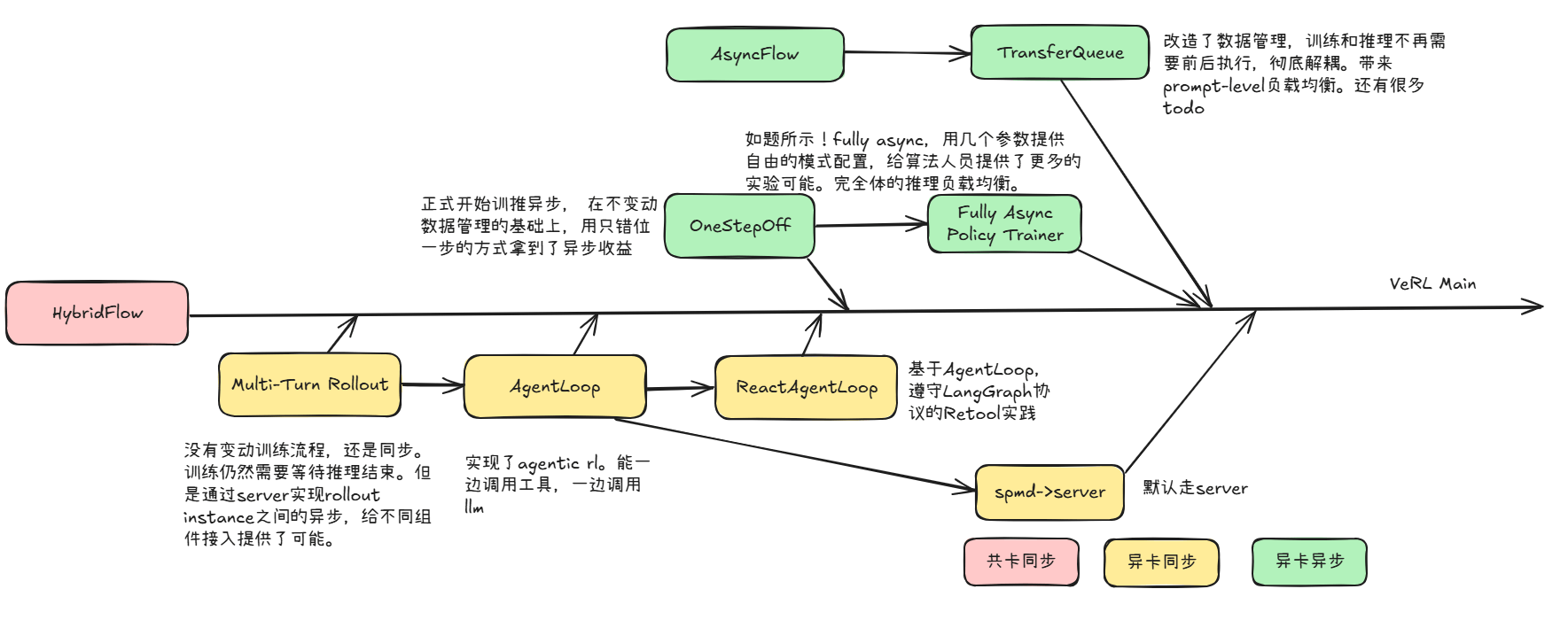
个人意见,仅供参考!
- 目前的方案都是异卡基础上的异步,默认异步pr 正在进行中
- AsyncFlow还有进一步的工作,但是面对FullyAsync,要拿出更多的亮点
- Onestep off这种最小改动拿到异步收益很厉害,FullyAsync感觉是一个非常好的异步实验平台,很全面,有短时间内最优方案的样子
- server模式下对工具提出很大挑战,已经存在异步下profiling不能用的情况了。
- 所有的异步方案都是在卷空泡率、利用率等指标,相关的标准、工具还是空缺着。
- 调优思路需要从离线调优变成服务化调优,除了先保证离线任务的精度性能以外,也要构建服务化下的精度性能调优方法论。
其他参考资料
Magistral https://arxiv.org/abs/2506.10910
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning https://arxiv.org/abs/2505.24298
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation https://arxiv.org/abs/2504.15930

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)