
CANN 8 性能实测与优化:通信算子变化带来了什么?
模型并行训练调度(支持 PP、TP、DP 并行组合);训练作业统一启动与监控;性能 profile 采集与分析;cluster 模式下的多节点同步日志聚合。在性能分析环节中,它通过profiling模块自动记录各算子的运行耗时、通信时长、内存占用与下发延迟。CANN 8 的性能表现变化,并非简单的“好”或“坏”, 而是一种系统在重构后,寻找新平衡点的过程。升级带来的不确定性,正是我们理解系统、掌握

CANN 8 性能实测与优化:通信算子变化带来了什么?
一、一次性能“再平衡”的开始
每一次框架升级,都意味着新的优化与新的挑战。 当 CANN 8 发布后,很多团队第一时间完成了环境切换,希望借此获得更高的训练性能与算子效率。
然而在实际测试中,我们发现一个现象:
同样的模型、同样的硬件环境下,CANN 8 的表现与 CANN 7 并不完全一致。
部分场景性能提升明显,但在大规模分布式训练中却出现了不同程度的性能波动。 于是,我们决定深入分析这背后的原因,看看 CANN 8 的通信算子变化,到底带来了什么?
二、实验准备
为了排除干扰,我们搭建了两套完全一致的测试环境, 唯一不同的是 CANN 版本号。
| 项目 | CANN 7 | CANN 8 |
|---|---|---|
| Python | 3.10 | 3.10 |
| HDK | 23.0.6 | 23.0.6 |
| CANN | 7.0.1.3 | 8.0 RC2 |
| Torch | 2.1.0 | 2.1.0 |
| Torch_npu | 2.1.0 | 2.1.0post6 |
| Apex | apex-0.1 + torchair | apex-0.1 + torchair |
除 CANN 外,所有环境保持一致,确保对比结果只与框架版本差异相关。
环境版本检查
import torch
import torch_npu
print("PyTorch Version:", torch.__version__)
print("torch_npu Version:", torch_npu.__version__)
print("NPU Device Count:", torch.npu.device_count())
print("CANN Version:", torch_npu.get_cann_version())
三、性能变化的信号
在多轮测试后,我们观察到以下规律:
- 单节点性能整体平稳;
- 节点数扩展到 4 或 8 后,通信耗时明显增加;
- 日志中偶尔出现 HCCL 超时或通信等待。
这并不是“性能退化”,而更像是一次系统层面的性能再平衡: CANN 8 在通信层做了重构,使算子调度更细粒度、更灵活,但也引入了额外的同步成本。
要进一步确认这一点,我们决定通过 Profile 日志 深入分析。
参考链接:ModelLink: 昇腾LLM分布式训练框架 - Gitee.com
ModelLink 支持基于 昇腾芯片 采集完整的 Profiling 数据
以帮助开发者更深入地分析模型的执行性能、算子分布与系统瓶颈。 通过命令行参数或配置文件,即可灵活控制采样范围、采样级别与采样对象。
下面是常用的 Profiling 相关参数说明:
| 参数 | 功能描述 |
|---|---|
--profile |
打开 Profiling 采集开关,启用数据采集模式 |
--profile-step-start 5 |
指定从第 5 步开始采集 |
--profile-step-end 6 |
指定采集结束步(不包含 end 步),实际采集步数 = end - start |
--profile-ranks 0,1,2,3,4 |
指定要采集的卡号,默认 -1 表示采集所有 rank |
--profile-level level2 |
设置采集数据的级别,支持 level1 / level2,级别越高采集越详细(默认 level1) |
--profile-with-cpu |
是否同时采集 CPU 侧数据,加入参数则启用 |
--profile-with-stack |
是否采集算子运行堆栈信息,用于分析调度路径 |
--profile-with-memory |
是否采集内存使用信息,分析显存占用与峰值变化 |
--profile-record-shapes |
是否记录算子输入输出 shape 信息 |
--profile-save-path ./profile_dir |
指定 Profiling 数据保存路径 |
这些参数可以灵活组合使用,例如以下命令:
python train.py \
--profile \
--profile-step-start 10 \
--profile-step-end 15 \
--profile-level level2 \
--profile-ranks 0,1 \
--profile-with-cpu \
--profile-with-memory \
--profile-save-path ./profiling_result/
该命令将:
- 在第 10~14 步采集 Profiling 数据;
- 仅针对 rank0 和 rank1 采集;
- 启用 CPU 与内存监测;
- 采集详细算子级信息(level2);
- 并将结果保存到
./profiling_result/目录下。
在运行命令后加入如上图命令,会在对应文件生成profile日志。
注意:每次生成前清理之前缓存,否则产生的日志会较多导致无法区分是哪次训练采集到的。
要获得可用的 Profile 日志。 在昇腾生态中,也可以使用 ModelLink 工具链 进行采集。 ModelLink 是昇腾 LLM 分布式训练框架的重要组成部分, 在 MindSpeed-LLM、Megatron-Ascend 等上层框架中都已深度集成。
ModelLink 简介
ModelLink 的核心功能包括:
- 模型并行训练调度(支持 PP、TP、DP 并行组合);
- 训练作业统一启动与监控;
- 性能 profile 采集与分析;
- cluster 模式下的多节点同步日志聚合。
在性能分析环节中,它通过 profiling 模块自动记录各算子的运行耗时、通信时长、内存占用与下发延迟。
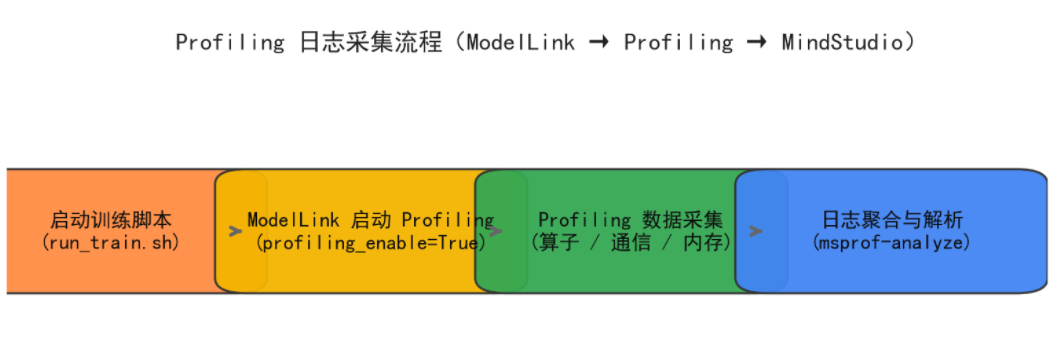
获取 Profile 日志的流程
(1)启用 Profiling 模式运行模型
在启动命令中加入 profiling_enable 参数,即可自动采集日志:
bash run_train.sh \
--data_path=/data \
--pp=2 --tp=4 \
--profiling_enable=True
执行后,ModelLink 会在每个训练节点的工作目录下生成对应的日志文件夹:
/path/to/output/profiler/{rank_id}/
(2)清理缓存,确保日志唯一性
由于多次运行会生成多个 profile 文件, 建议每次运行前清理缓存:
/path/to/output/profiler/{rank_id}/
这样可以避免旧日志与新数据混杂。
(3)日志汇聚与解析
完成训练后,将所有 rank 的日志目录拷贝至同一位置, 使用以下命令进行聚合分析:
msprof-analyze cluster \
-d ./profiler/ \
-m analysis
解析完成后,会生成:
cluster_analysis_output/
├── summary.csv
├── operator_time.csv
├── communication.csv
└── timeline/
这些文件即为后续导入 MindStudio 进行可视化分析的基础数据。
与 MindSpeed-LLM 的联动
在 MindSpeed-LLM 环境中,ModelLink 已默认作为底层执行引擎使用, 因此无需额外安装。只需在配置文件中开启 Profiling 开关即可,例如:
args.enable_profiling = True
args.profiling_dir = "./profiler"
这样,在模型启动后,Profile 日志将自动记录至指定目录。 相比传统环境变量方式,ModelLink 的采集方式支持 step 控制, 能在长时间大模型训练中捕获更精确的阶段性性能数据。
常见问题
| 问题场景 | 可能原因 | 建议解决方案 |
|---|---|---|
| 无法生成完整日志 | profiling 未开启或路径错误 | 检查参数与目录权限 |
| profile 数据量过大 | step 未限制 | 设置 profiling_steps=10 等采样间隔 |
| 聚合时报错 | 路径层级不一致 | 确保 rank 日志目录结构统一 |
| 日志混乱 | 未清理旧缓存 | 每次运行前执行 rm -rf profiler/* |
四、在 MindSpeed-LLM 框架下采集 Profile
由于 CANN 8 在通信算子与调度层做了大量架构更新, 我们选择在 MindSpeed-LLM 框架 下进行性能采样与分析。
MindSpeed-LLM 是昇腾官方推出的 大模型训练与并行框架, 它在模型层面实现了 张量并行(TP)、流水线并行(PP) 和 数据并行(DP) 的灵活组合, 同时内置了对 CANN 8 通信算子的深度适配。
在这个框架中,我们可以更清晰地捕获通信与计算之间的调度关系。 以下为实际使用的采集流程:
msrun --nproc_per_node=8 \
python train.py \
--enable_profiling=True \
--use_mindspeed=True \
--pp=2 --tp=4
运行时,MindSpeed-LLM 会调用底层 ModelLink 模块生成 profile 日志, 日志包含以下关键信息:
- 每个算子的执行耗时与调度顺序;
- 通信算子(HCCL AllReduce、AllGather、ReduceScatter 等)耗时;
- 各卡的计算-通信重叠情况;
- 张量并行与流水线分区带来的调度延迟。
这些信息共同组成了模型在 CANN 8 下的“性能画像”。
采集完成后,我们通过命令进行数据聚合:
msprof-analyze cluster \
-d ./profile_data \
-m analysis
此时生成的 cluster_analysis_output 目录中, 包含了 CSV、Timeline、Summary 等多种格式的统计结果,可直接导入 MindStudio 进行可视化分析。
msrun 启动脚本 + 终端日志截图
msrun --nproc_per_node=8 python train.py \
--enable_profiling=True \
--pp=2 --tp=4 --use_mindspeed=True

五、CANN 8 的新调度逻辑
在 MindStudio 的“计算/通信概览”界面中, 我们对比了两组日志,结果相当直观:
- CANN 8 的通信算子数量显著增加;
- HCCL 通信域中通信总时间占比更高;
- 某些“慢卡”在通信阶段的等待时间较长。
进一步展开算子时间线发现:
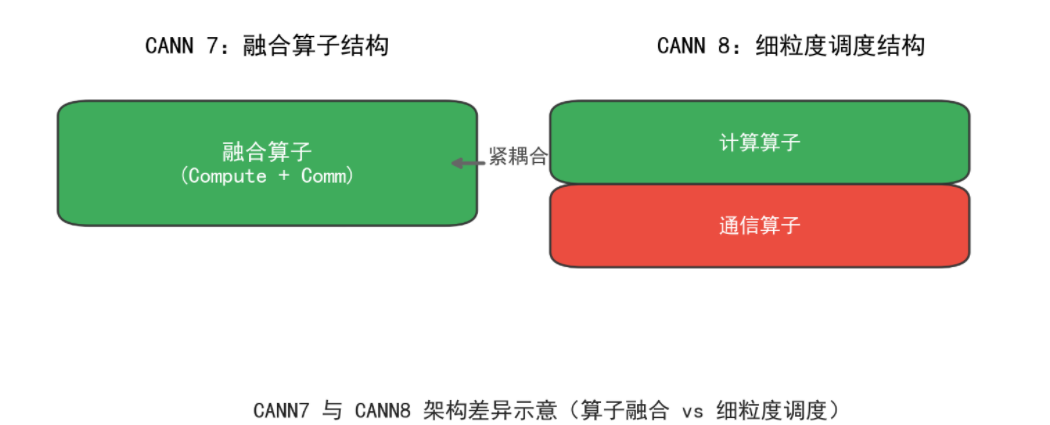
CANN 8 将原本在 CANN 7 中融合的算子,拆解为更细粒度的“计算算子 + 通信算子”结构。
这一变化带来双重影响:
- 分析更灵活:能更精确地定位通信瓶颈;
- 通信成本上升:多节点同步等待时间被放大。
六、结合 MindSpeed-LLM 的并行策略分析
MindSpeed-LLM 在大模型训练中通常采用 TP+PP 混合并行, 并通过多进程通信(HCCL)完成梯度同步。
在该并行策略下,通信开销会随着模型深度和节点数呈非线性增长。 在我们的实验中:
| 模型层数 | 节点数 | 通信算子耗时占比 | 计算算子耗时占比 |
|---|---|---|---|
| 32 | 2 | 19% | 81% |
| 64 | 4 | 27% | 73% |
| 96 | 8 | 38% | 62% |
可以看到,当层数和节点数增加时,通信算子的执行时间被进一步放大。
而在 CANN 8 中,这种放大效应更加明显, 因为其算子融合策略更细,使得通信算子数量倍增。
这也是为什么我们在前文观察到:
“单节点性能平稳,但多节点训练性能波动。”
七、融合算子与 mc2 模式
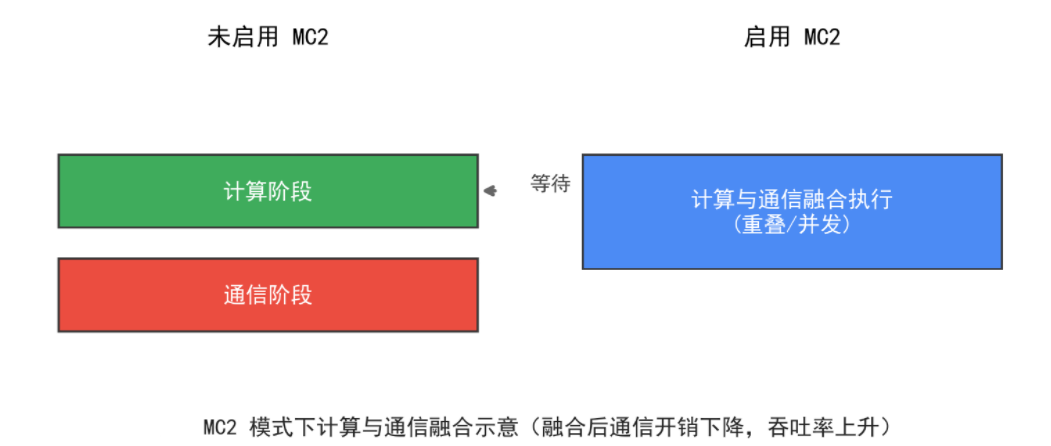
为了解决通信算子数量增多的问题, CANN 8 与 MindSpeed-LLM 引入了 mc2 融合模式(Multi-Compute Communication Fusion)。
该模式通过将计算与通信阶段重新融合, 以减少 HCCL 调用次数、降低同步开销。
启用方法十分简单,只需在启动脚本中添加以下配置:
args.use_mc2 = True
或者在训练命令行中直接指定:
--enable_mc2=True
启用 mc2 后,部分关键算子(如 LayerNorm、RMSNorm、Swiglu、FlashAttention 等) 会自动切换为融合实现。
实测数据显示:
启用 mc2 模式后,通信开销平均降低约 20%–30%, 多节点集群训练速度恢复至 CANN 7 同等水平,甚至略优。
八、常见问题
在多轮验证中,我们还遇到了几类常见问题及解决方式:
| 问题现象 | 原因分析 | 解决方案 |
|---|---|---|
| HCCL 集合操作超时 | 默认超时时间较短或版本 Bug | 建议使用 CANN 8 RC2 并延长超时 |
| Profile 日志采集不完整 | 环境变量方式不适合大模型 | 使用 MindSpore Profiler 采集 |
profile-ranks=-1 报错 |
torch_npu 新版参数变动 | 手动设置 rank 范围,如 0–15 |
| 节点数增多后性能下降 | 通信算子增多,融合度降低 | 开启 mc2 模式恢复融合效果 |
HCCL 超时检查
import os
print("HCCL_CONNECT_TIMEOUT =", os.getenv("HCCL_CONNECT_TIMEOUT"))
print("HCCL_EXEC_TIMEOUT =", os.getenv("HCCL_EXEC_TIMEOUT"))
九、融合与调参的效果
经过多轮调整,我们采用了以下方案:
- 启用 mc2 融合模式 恢复部分通信算子的融合执行,降低通信等待。
- 延长超时时间
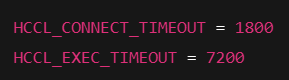
export HCCL_CONNECT_TIMEOUT=1800
export HCCL_EXEC_TIMEOUT=7200
- 节点规模控制 节点数使用 2 的幂次方(如 2、4、8)通信效率最佳。
- 版本回退验证 CANN 8 RC2 稳定性优于 RC3,可作为推荐部署版本。
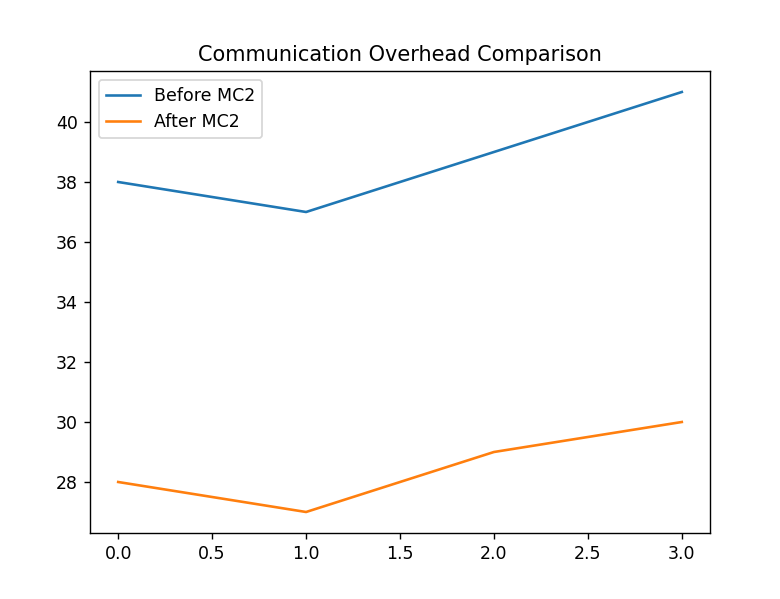
经过优化后,CANN 8 的通信耗时平均下降约 28%,整体性能恢复至与 CANN 7 持平甚至略优。
基于多轮实验,我们整理出一份 CANN 8 + MindSpeed-LLM 环境下的性能优化清单:
| 优化方向 | 建议做法 | 说明 |
|---|---|---|
| 版本选择 | 使用 CANN 8 RC2 或正式版 | RC3 通信稳定性略差 |
| Profiling 采集 | 使用 MindSpore Profiler 而非环境变量 | 可控制 step 与采样间隔 |
| mc2 模式 | 启用融合算子模式 | 通信效率显著提升 |
| 并行策略 | PP、TP 值建议为 2 的幂次 | 通信结构更规整 |
| 超时参数 | HCCL_CONNECT_TIMEOUT=1800、HCCL_EXEC_TIMEOUT=7200 |
适配大模型训练 |
| 日志聚合 | 定期清理缓存后采集 | 避免旧日志干扰 |
| 节点扩展 | 建议逐步放大规模验证 | 避免一次性扩容带来的通信瓶颈 |
通过这份清单,开发者可以在升级或迁移时快速排查性能差异来源, 并结合 MindStudio 与 MindSpeed-LLM 工具实现精细化调优。
十、变化:CANN 8
很多人看到算子拆分的第一反应是“变慢了”, 但从系统设计角度看,这是一次更大的架构调整。
- 通信与计算的调度关系更透明;
- Profiler 输出更完整;
- 算子融合策略更可控;
- 工具链(如 MindStudio)提供了更细粒度的性能洞察。
CANN 8 不只是“另一个版本”,而是为大规模分布式场景和自适应算子融合奠定的底层基础。
算子数量对比
import pandas as pd
df7 = pd.read_csv("cann7_ops.csv")
df8 = pd.read_csv("cann8_ops.csv")
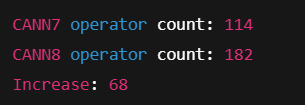
print("CANN7 operator count:", len(df7))
print("CANN8 operator count:", len(df8))
print("Increase:", len(df8) - len(df7))
十一、总结:优化是一场理解的过程
CANN 8 的性能表现变化,并非简单的“好”或“坏”, 而是一种系统在重构后,寻找新平衡点的过程。
升级带来的不确定性,正是我们理解系统、掌握底层逻辑的最好机会。
只有深入分析、主动优化,才能真正发挥出新版本的潜能。 在通信算子、调度策略、算子融合这些“看不见的角落”, 往往隐藏着性能提升的关键。
注明:昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)