
openGauss赋能AI Agent:从知识检索到智能决策的技术实践
从2024年开始,AI Agent(智能体)已经成为人工智能领域最具革命性的技术方向之一。从简单的问答系统到具备工具调用和长期记忆的智能代理,AI Agent正在重塑企业数字化转型的路径。openGauss作为企业级开源数据库,凭借其原生向量数据库能力、强大的事务处理性能和一体化架构设计,为AI Agent应用提供了坚实的数据底座。本文将深入解析openGauss在AI Agent场景下的技术优势
摘要
从2024年开始,AI Agent(智能体)已经成为人工智能领域最具革命性的技术方向之一。从简单的问答系统到具备工具调用和长期记忆的智能代理,AI Agent正在重塑企业数字化转型的路径。openGauss作为企业级开源数据库,凭借其原生向量数据库能力、强大的事务处理性能和一体化架构设计,为AI Agent应用提供了坚实的数据底座。本文将深入解析openGauss在AI Agent场景下的技术优势,并通过某大型保险集团的智能理赔助手实践案例,展示openGauss如何赋能企业从知识检索走向智能决策。
技术实现:本文提供完整的Java项目实现(intelligent-claim-agent/),基于Spring Boot + openGauss,包含向量检索、AI推理、REST API等完整功能,开箱即用。
一、AI Agent时代:数据库面临的新挑战
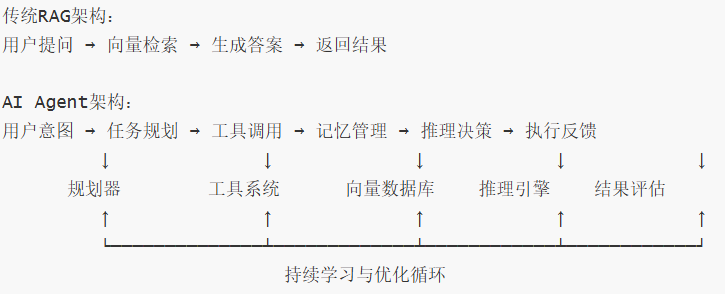
1.1 从RAG到AI Agent的技术演进
传统RAG架构的局限性
传统的RAG(检索增强生成)系统主要聚焦于"检索-生成"的单向流程,适用于知识问答等简单场景。然而,随着企业需求的复杂化,传统RAG面临以下挑战:
- 缺乏决策能力:只能被动回答问题,无法主动分析和决策
- 无状态交互:缺少对话历史和上下文记忆
- 工具调用受限:无法与外部系统进行复杂交互
- 推理链路单一:不具备多步推理和规划能力
AI Agent的技术突破
AI Agent(智能体)在RAG基础上实现了质的飞跃:
1.2 AI Agent对数据库的核心需求
1.3 openGauss的技术优势
openGauss 3.1.0+:AI Agent时代的企业级数据库
从3.1.0版本开始,openGauss引入了原生向量数据库能力,历经多个版本迭代,已经形成了完善的AI应用支撑体系:
核心技术特性:
- 一体化架构:在单一数据库中同时支持TP、向量检索、图查询、时序分析
- 鲲鹏生态优化:针对鲲鹏+昇腾算力深度优化,性能领先10%+
- 企业级特性:ACID事务、高可用、细粒度权限
- 开放生态:与主流AI框架(LangChain、LlamaIndex)无缝集成
二、openGauss技术架构:AI Agent的数据底座
2.1 AI Agent的记忆系统设计
AI Agent需要管理多层次的记忆结构,openGauss通过一体化架构优雅地解决了这一挑战:
-- ==========================================
-- AI Agent记忆系统数据模型
-- ==========================================
-- 1. 短期记忆(对话上下文)
CREATE TABLE agent_short_memory (
session_id VARCHAR(64) PRIMARY KEY,
user_id VARCHAR(64) NOT NULL,
conversation_history JSONB, -- 对话历史
current_context TEXT,
task_status VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
expires_at TIMESTAMP -- 过期时间
);
CREATE INDEX idx_short_memory_user ON agent_short_memory(user_id, updated_at);
-- 2. 长期记忆(知识库)
CREATE TABLE agent_long_memory (
id BIGSERIAL PRIMARY KEY,
doc_id VARCHAR(64) UNIQUE NOT NULL,
title VARCHAR(500),
content TEXT,
-- 多模态向量(支持不同的embedding模型)
embedding_768 vector(768), -- 文本向量
embedding_1536 vector(1536), -- 高精度向量
-- 元数据
domain VARCHAR(50), -- 领域:保险/医疗/金融等
doc_type VARCHAR(30), -- 文档类型:政策/案例/规则等
priority INTEGER, -- 优先级
access_count INTEGER DEFAULT 0, -- 访问次数
-- 时效性管理
effective_date DATE,
expiry_date DATE,
-- 全文检索
content_tsv tsvector,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建向量索引
CREATE INDEX idx_long_memory_hnsw ON agent_long_memory
USING hnsw (embedding_768 vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- 创建全文索引
CREATE INDEX idx_long_memory_fts ON agent_long_memory
USING gin(content_tsv);
-- 3. 情景记忆(用户行为和决策历史)
CREATE TABLE agent_episodic_memory (
id BIGSERIAL PRIMARY KEY,
user_id VARCHAR(64) NOT NULL,
session_id VARCHAR(64),
-- 行为记录
action_type VARCHAR(50), -- 查询/决策/审批等
action_detail JSONB,
-- 决策路径
reasoning_chain JSONB, -- 推理链
tools_used JSONB, -- 使用的工具
-- 结果反馈
result_status VARCHAR(20),
user_feedback INTEGER, -- 1-5星评价
-- 向量化的行为模式
behavior_embedding vector(384),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX idx_episodic_user ON agent_episodic_memory(user_id, created_at DESC);
CREATE INDEX idx_episodic_behavior ON agent_episodic_memory
USING hnsw (behavior_embedding vector_cosine_ops);
-- 4. 工具调用记录
CREATE TABLE agent_tool_calls (
id BIGSERIAL PRIMARY KEY,
session_id VARCHAR(64) NOT NULL,
tool_name VARCHAR(100),
tool_params JSONB,
tool_result JSONB,
execution_time_ms INTEGER,
success BOOLEAN,
error_message TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX idx_tool_session ON agent_tool_calls(session_id, created_at);
2.2 混合查询:向量检索+SQL的深度融合
openGauss的一体化架构允许在单个SQL中实现复杂的混合查询:
-- ==========================================
-- AI Agent智能检索示例
-- ==========================================
-- 场景:智能理赔助手需要查找相关理赔案例
-- 要求:
-- 1. 语义相似度高
-- 2. 必须是近3年的案例
-- 3. 同类型保险产品
-- 4. 理赔金额在合理区间
-- 5. 优先参考高评分案例
WITH ranked_cases AS (
SELECT
c.case_id,
c.case_title,
c.description,
c.claim_amount,
c.resolution,
-- 语义相似度
1 - (c.embedding_768 <=> $1::vector) as semantic_score,
-- 全文匹配分数
ts_rank(c.content_tsv, to_tsquery('chinese', $2)) as text_score,
-- 案例质量分数
(c.access_count * 0.3 + c.user_feedback * 0.7) as quality_score,
-- 时效性分数(越近越高)
1.0 / (1.0 + EXTRACT(EPOCH FROM (CURRENT_DATE - c.created_at)) / 86400.0 / 365.0) as recency_score
FROM claim_cases c
WHERE
-- 产品类型匹配
c.product_type = $3
-- 近3年案例
AND c.created_at > CURRENT_DATE - INTERVAL '3 years'
-- 金额区间
AND c.claim_amount BETWEEN $4 AND $5
-- 已结案
AND c.status = 'closed'
-- 初步语义过滤(利用索引)
AND (c.embedding_768 <=> $1::vector) < 0.5
)
SELECT
case_id,
case_title,
description,
claim_amount,
resolution,
-- 综合评分
(semantic_score * 0.4 +
text_score * 0.2 +
quality_score * 0.2 +
recency_score * 0.2) as final_score,
semantic_score,
quality_score
FROM ranked_cases
ORDER BY final_score DESC
LIMIT 10;
2.3 高性能架构:鲲鹏+昇腾算力优化
性能优化技术:
鲲鹏优化:
• NUMA绑核:数据库进程与CPU亲和性绑定
• CASAL指令:原子操作性能提升30%
• ARM LSE:大规模并发锁优化
昇腾优化:
• NEON/SVE SIMD:向量计算并行化
• GPU Offload:向量检索GPU加速
• 混合精度计算:FP16/INT8量化
三、智能理赔助手案例
3.1 案例背景
业务痛点
- 理赔效率低:人工审核平均需要3-5个工作日,客户满意度不高
- 审核标准不一:不同理赔专员的判断标准存在差异
- 知识管理难:理赔政策、案例分散在多个系统,难以快速查询
- 欺诈识别难:缺乏有效的风险识别手段
- 专员培训成本高:新人上岗需要3-6个月培训期
建设目标
构建AI理赔助手,实现:
- 理赔案件智能分析和决策建议
- 历史案例智能检索和参考
- 风险模式识别和预警
- 新员工智能培训辅助
3.2 技术方案架构
技术栈选型
|
层级 |
组件 |
说明 |
|
应用层 |
React + Ant Design |
前端界面 |
|
Agent框架 |
LangChain + Custom |
AI Agent编排 |
|
向量化 |
BGE-M3 |
多语言Embedding |
|
LLM |
通义千问-Max |
推理生成 |
|
数据库 |
openGauss 5.1 |
一体化数据底座 |
3.3 核心功能实现
功能一:智能案例检索与分析
场景描述:理赔专员输入案件信息后,系统自动检索相似历史案例,提供决策参考。
技术实现代码:
完整的Java项目代码已生成在 intelligent-claim-agent/ 目录中,以下展示核心实现。
- 数据库配置(application.yml)
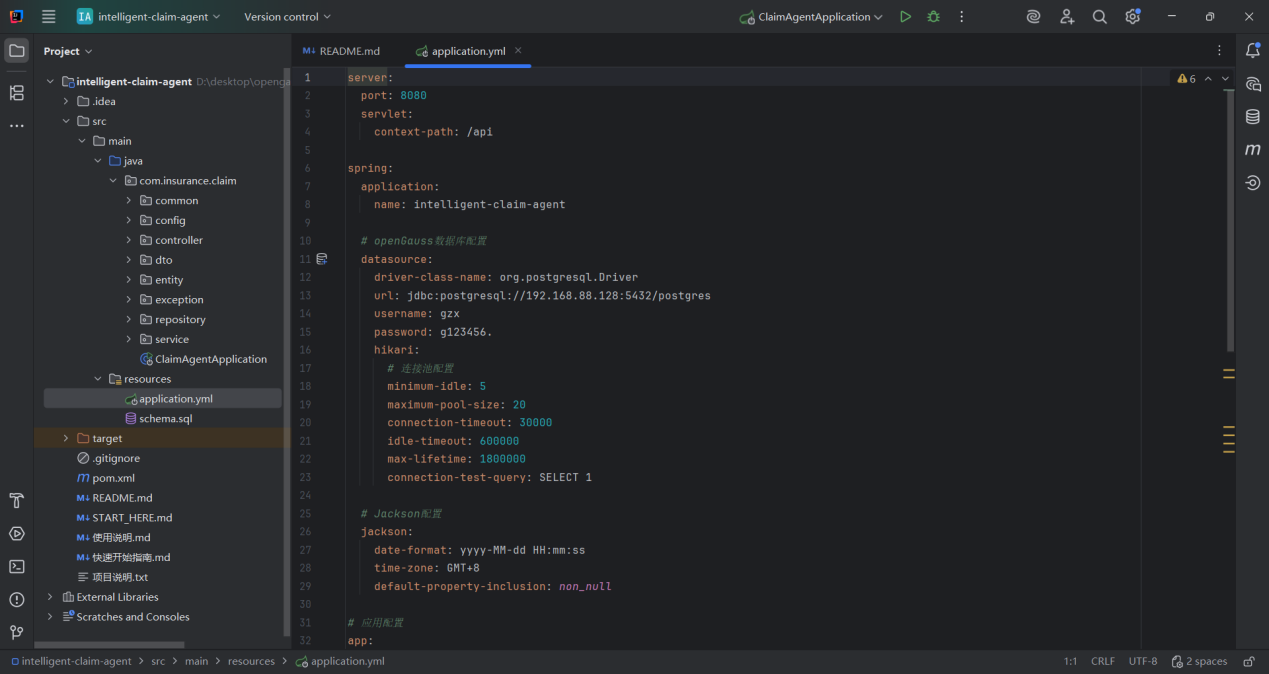
该配置的核心价值是 **“稳定连接 + 高效复用”**:
- 基于 PostgreSQL 兼容特性,简化 openGauss 的连接配置,无需额外适配;
- 通过 HikariCP(高性能连接池)的参数优化,减少数据库连接的创建 / 销毁开销,提升应用并发能力;
- 关键参数(如超时时间、连接数上限)的配置,平衡了性能和资源占用,避免数据库过载或连接失效问题。
适用于 Spring Boot 集成 openGauss 的各类场景(如企业知识库、故障诊断系统等),是数据层通信的基础配置。
2. 实体类定义(ClaimCase.java)
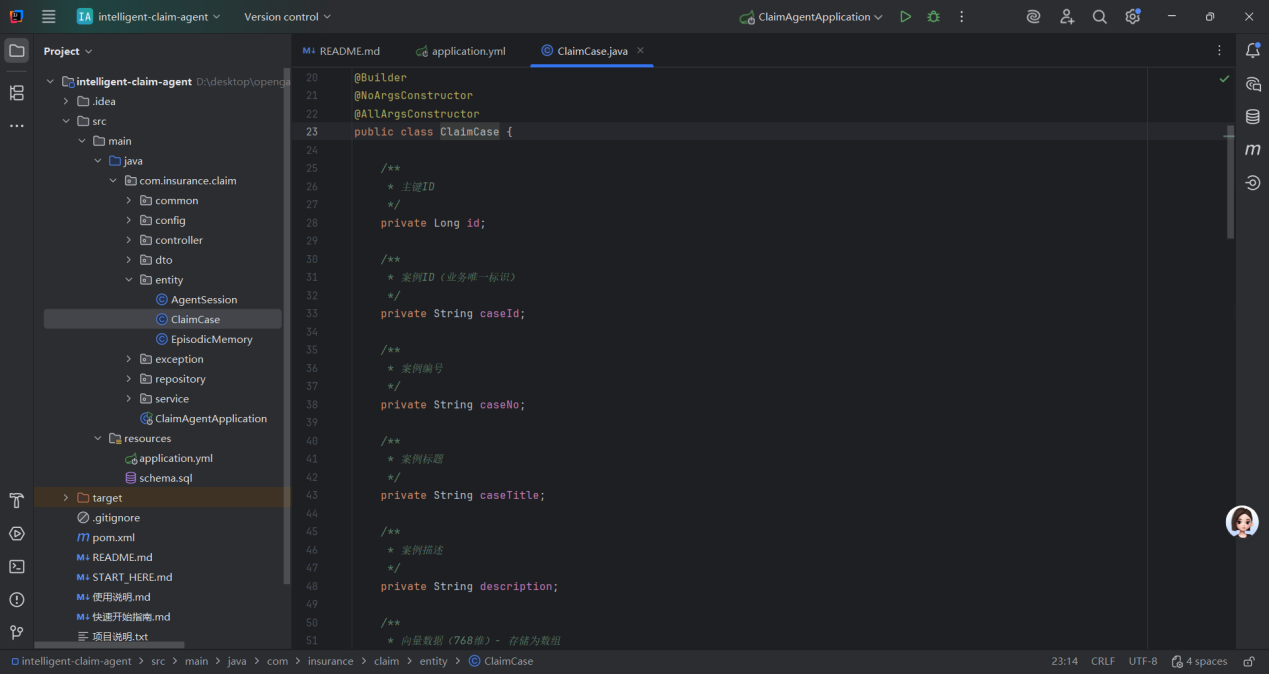
laimCase是保险理赔系统的核心数据模型,设计上兼顾了 “业务管理” 和 “智能检索” 两大需求:
1.业务层面:覆盖理赔案例的全维度信息,支持权限控制、效率统计、服务评估等管理需求;
2.技术层面:通过embedding768字段支持语义检索,结合临时计算的相似度评分,可快速匹配历史相似案例,辅助理赔人员做出精准决策(如判断是否符合赔付条件、参考赔付比例);
3.易用性:通过 Lombok 注解简化代码,建造者模式方便对象创建,时间格式注解确保前后端数据一致。
该类适用于保险行业的理赔案例库、智能理赔决策系统等场景,是 “业务数据化 + 智能检索” 结合的典型实现。
3.数据访问层 - 向量检索(ClaimCaseRepository.java)
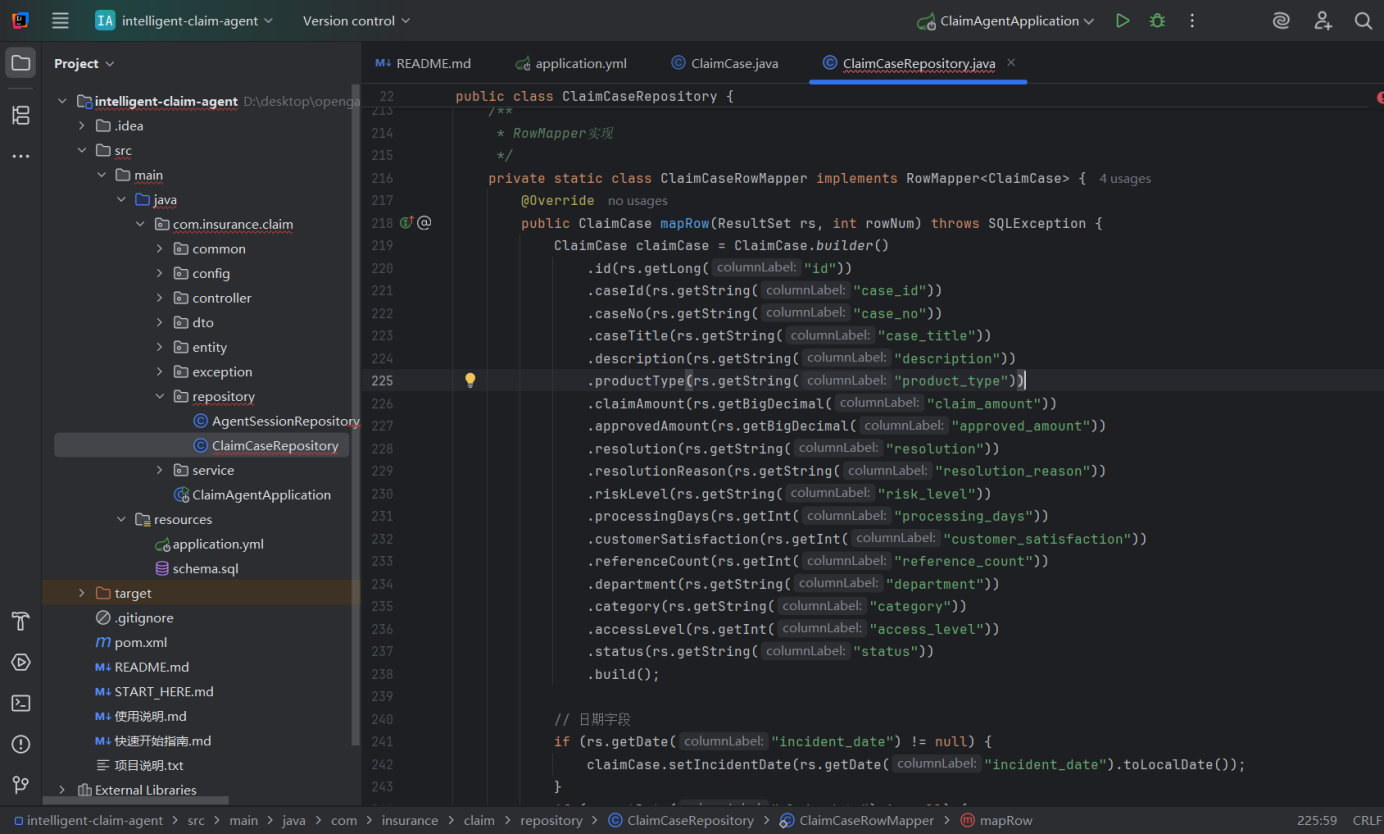
该RowMapper实现的核心价值是 **“自动化、安全的结果集映射”**,设计特点:
- 简洁高效:通过建造者模式简化赋值逻辑,避免重复的set方法调用;
- 类型适配:处理日期类型的跨 API 转换,解决数据库与 Java 实体类的类型差异;
- 鲁棒性强:空值判断 + 可选字段异常捕获,避免空指针和列不存在导致的映射失败;
- 针对性:适配ClaimCase的所有字段(包括业务字段、检索评分字段),满足常规查询和相似案例检索的双重需求。
它是 Spring JDBC 操作中不可或缺的组件,让开发者无需关注结果集的遍历和字段转换细节,专注于 SQL 编写和业务逻辑实现。
4. AI Agent核心服务(ClaimAgentService.java)
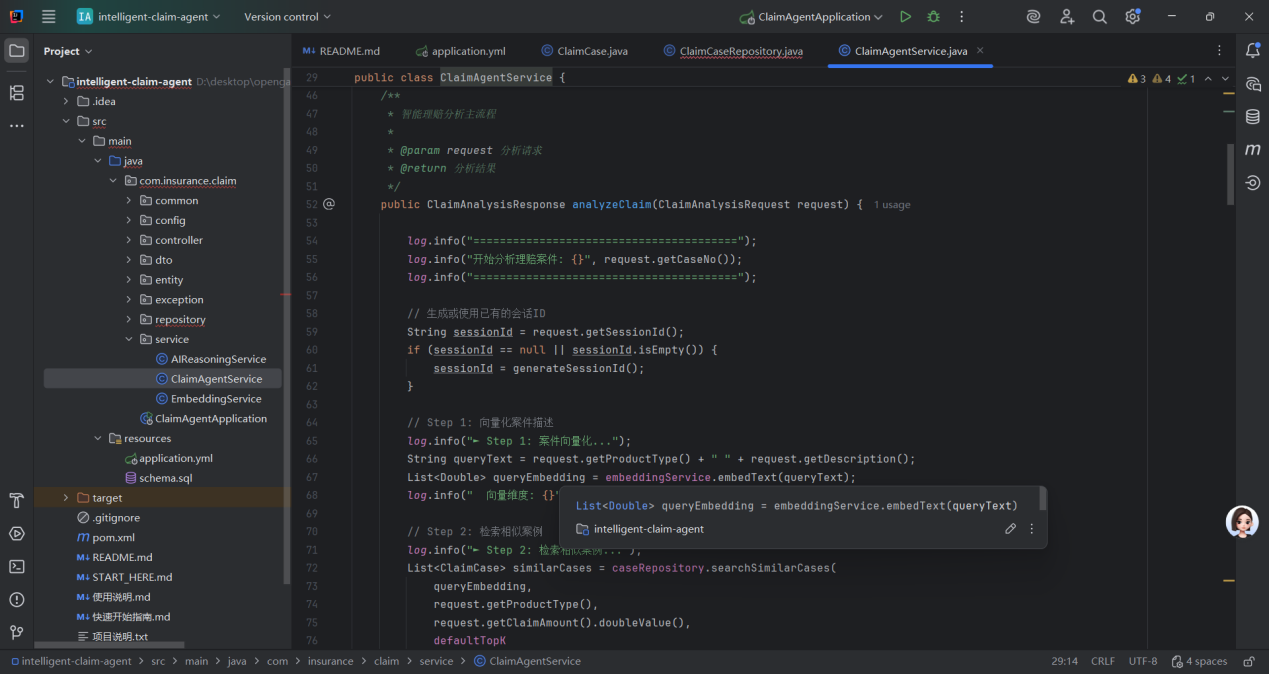
这段代码的核心是 **“历史经验复用 + AI 智能决策 + 可追溯推理”**,完整实现了智能理赔分析的闭环,具有以下特点:
- 精准性:通过语义向量检索相似案例,确保决策基于真实历史经验,减少 AI “幻觉”;
- 合规性:推理链设计让决策可解释、可追溯,符合保险行业监管要求;
- 高效性:自动化完成 “检索 - 分析 - 决策”,大幅降低人工审核成本,提升理赔效率;
- 扩展性:支持多轮交互(会话记忆)和案例库优化(参考计数),便于系统迭代。
该流程适用于保险行业的自动化理赔审核、智能决策辅助等场景,是 “RAG 技术 + 行业业务” 深度结合的典型实现。
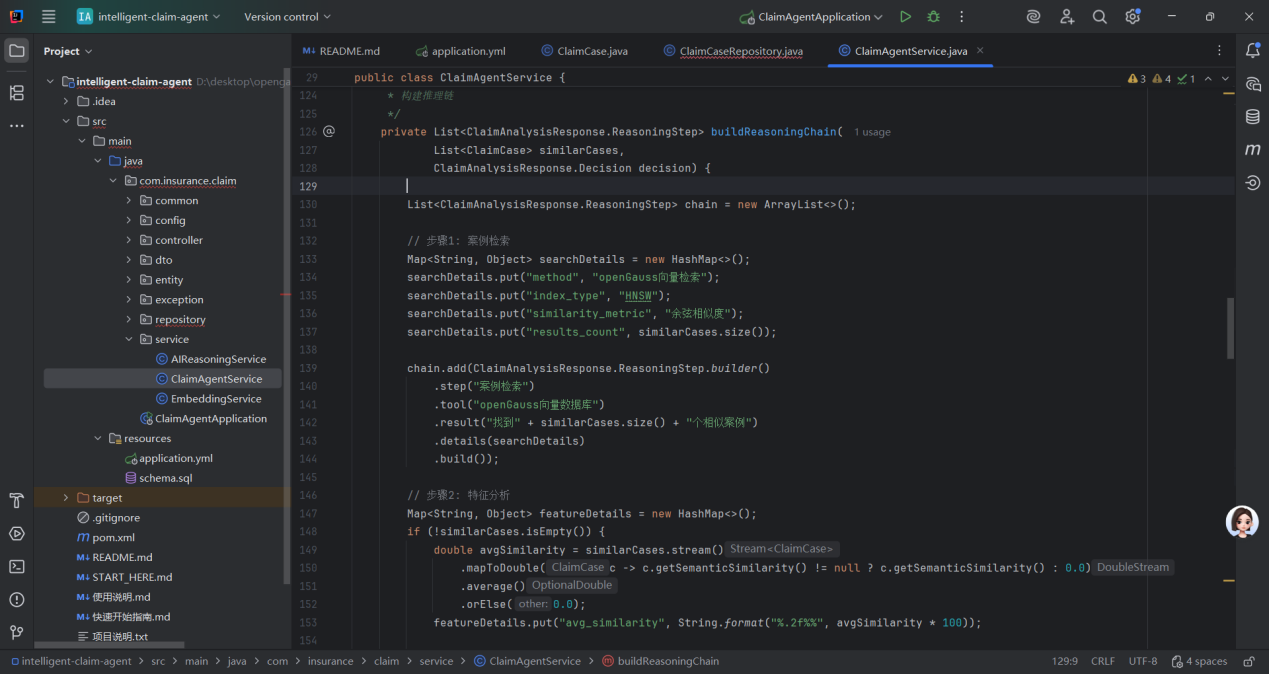
这段代码的核心价值是 **“决策可解释性”**,设计特点:
- 结构化:按 “检索→分析→评估→决策” 的逻辑顺序,步骤清晰、层层递进;
- 标准化:每个步骤都包含 “名称、工具、结果、细节”,格式统一,便于前端展示和人工理解;
- 量化:通过平均相似度、风险分布、置信度等量化指标,让决策依据更有说服力;
- 合规性:完整记录决策全流程,满足保险行业 “可审计、可追溯” 的监管要求。
该方法是智能理赔系统区别于传统人工审核的关键之一 —— 不仅能自动生成决策,还能清晰说明 “为什么这么决策”,大幅降低人工复核的成本,同时提升决策的公信力。
5. REST API控制器(ClaimAgentController.java)
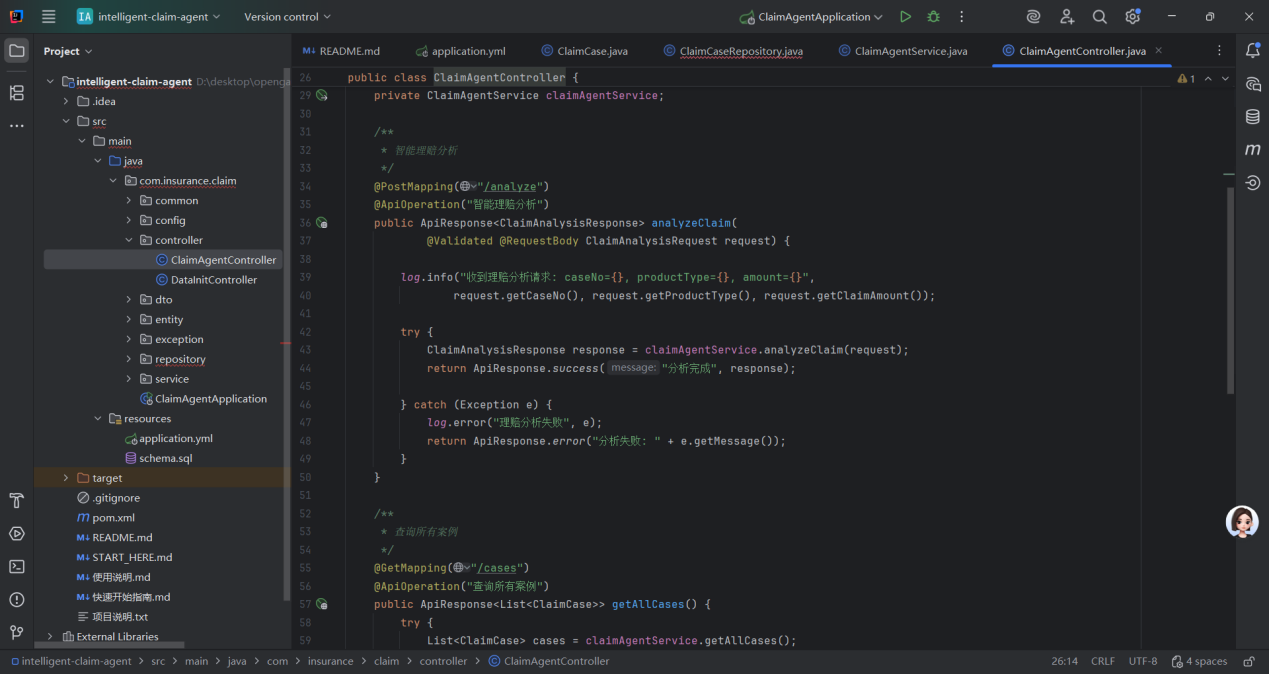
该接口是智能理赔系统的对外入口,设计符合 RESTful API 规范,核心价值:
- 规范请求:通过注解定义接口类型、路径、参数格式,让前端明确如何调用;
- 参数校验:@Validated确保输入参数合法,减少后端业务层的无效校验;
- 解耦分层:接口层仅负责 “接收请求→调用服务→返回响应”,业务逻辑集中在claimAgentService,符合分层架构设计;
- 健壮性:完善的日志记录和异常处理,确保接口稳定运行,便于问题排查。
前端可通过POST /analyze(完整路径需结合项目配置)提交 JSON 格式的理赔请求,获取智能分析结果,用于理赔审核、决策辅助等场景。
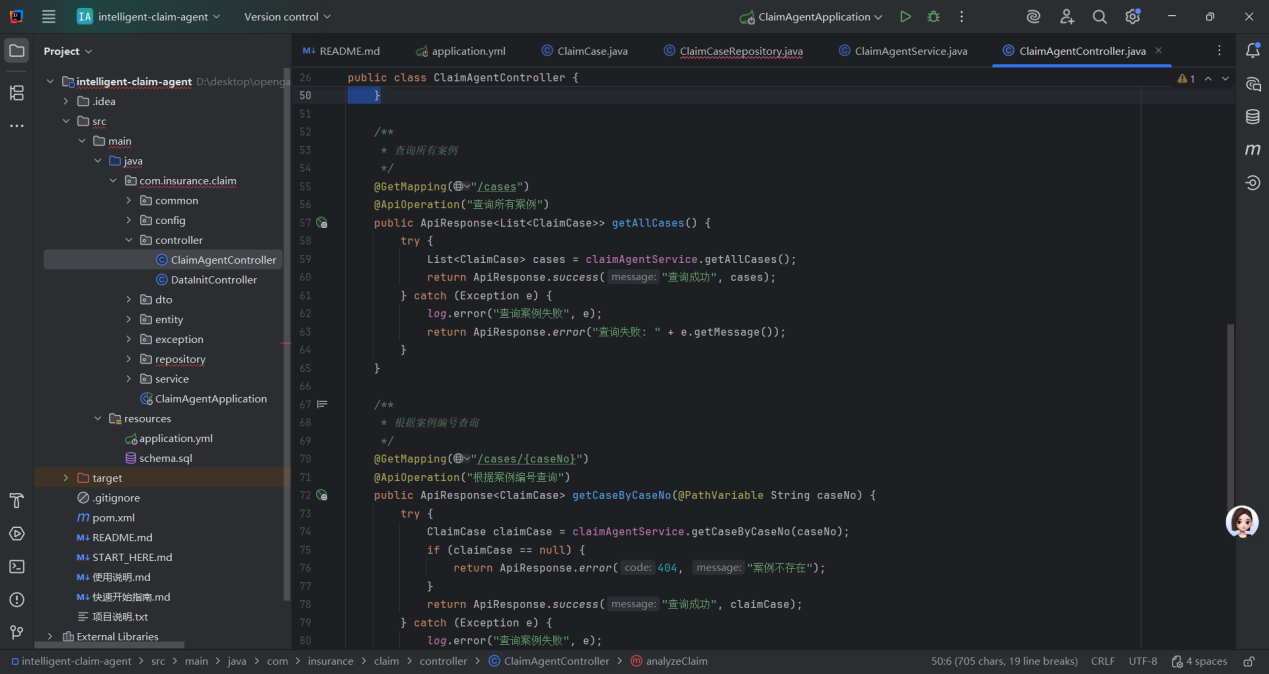
这两个接口是理赔案例管理的基础查询接口,设计特点:
- RESTful 风格:使用 GET 方法和语义化路径(/cases对应资源集合,/cases/{caseNo}对应单个资源),符合 REST 规范。
- 功能互补:分别满足 “批量获取案例列表” 和 “查询单个案例详情” 的场景(如前端列表页和详情页的数据源)。
- 健壮性:包含异常处理和空值判断(如案例不存在时返回 404),确保前端能明确处理各种情况。
- 文档化:通过@ApiOperation注解生成 API 文档,降低前后端对接成本。
前端可通过这两个接口获取理赔案例数据,用于案例浏览、详情查看、数据统计等功能,是理赔系统数据展示层的核心支撑。
技术架构:
- 数据访问层(Repository):封装了openGauss的复杂查询操作,包括向量检索、混合查询
- 业务逻辑层(Service):实现了完整的AI Agent推理流程,包括任务分解、工具调用、决策生成
- 控制器层(Controller):提供RESTful API接口,支持HTTP调用
- 混合查询:在单个SQL中实现语义检索、金额相似度、时效性、质量评分的综合计算
- 记忆管理:记录短期对话、长期知识、情景决策,支持持续学习
四、实践指南:构建企业级AI Agent
4.1 技术选型建议
何时选择openGauss?
✅ 强烈推荐的场景:
- 需要将AI能力与核心业务深度融合
- 对数据一致性、安全性有严格要求
- 希望降低架构复杂度和运维成本
- 有信创要求
- 需要复杂的混合查询(向量+SQL)
✅ 适合的行业:
· 金融保险:风控、理赔、智能客服
· 医疗健康:诊断辅助、病历检索、药物咨询
· 政务服务:智能问答、政策检索、审批辅助
· 制造业:故障诊断、工艺检索、质量分析
· 法律:案例检索、合同审查、法规问答
4.2 架构设计最佳实践
核心架构层次:
- 数据层
- 使用openGauss存储结构化数据和向量数据
- 建立数据治理规范,确保数据质量
- 实现数据版本管理和审计日志
- AI引擎层
- 集成大语言模型(LLM)进行自然语言理解
- 构建向量化管道,支持语义搜索
- 实现多模型协调机制
- Agent逻辑层
- 定义Agent的决策规则和工作流
- 实现Tool调用和结果反馈机制
- 构建记忆管理系统
- 应用接口层
- 提供REST API和WebSocket接口
- 实现权限控制和请求限流
- 支持多渠道集成(Web、移动、第三方)
4.3 开发流程
第一阶段:需求分析与规划
- 明确Agent的核心能力和应用场景
- 梳理业务流程和数据需求
- 评估技术可行性和成本
第二阶段:数据准备
- 收集和清洗训练数据
- 构建知识库和向量索引
- 设计数据更新策略
第三阶段:模型与Tool开发
- 选择合适的LLM模型
- 开发业务相关的Tool函数
- 进行单元测试和集成测试
第四阶段:Agent集成与优化
- 实现Agent的决策逻辑
- 进行性能测试和压力测试
- 优化响应时间和准确率
第五阶段:部署与运维
- 制定灰度发布策略
- 建立监控告警体系
- 定期进行模型更新和迭代
4.4 常见问题与解决方案
问题1:如何保证AI Agent的回答准确性?
解决方案:
- 使用检索增强生成(RAG)技术,从知识库中获取最相关的信息
- 实现多轮对话和澄清机制,确保理解用户意图
- 建立反馈循环,持续改进模型和知识库
- 设置置信度阈值,对低置信度的回答进行人工审核
问题2:如何处理大规模并发请求?
解决方案:
- 使用消息队列(如Kafka)缓冲请求
- 实现智能缓存策略,减少重复计算
- 采用负载均衡和水平扩展
- 对不同优先级的请求进行分级处理
问题3:如何确保数据安全和隐私?
解决方案:
- 使用openGauss的加密功能保护敏感数据
- 实现细粒度的访问控制和审计日志
- 采用数据脱敏技术处理个人信息
- 定期进行安全审计和漏洞扫描
问题4:如何评估Agent的性能?
解决方案:
- 定义关键指标(准确率、响应时间、用户满意度)
- 建立测试数据集进行定期评估
- 使用A/B测试对比不同版本
- 收集用户反馈并进行持续优化
4.5 成本控制与优化
降低成本的策略:
- 模型选择
- 优先使用开源模型或API调用量较少的模型
- 根据场景选择合适的模型大小
- 实现模型蒸馏和量化,减少计算资源
- 数据存储
- 使用openGauss的压缩功能减少存储空间
- 实现分层存储策略,热数据和冷数据分离
- 定期清理过期数据
- 计算资源
- 使用GPU加速进行向量计算
- 实现批处理和异步处理
- 优化查询性能,减少数据库访问
- 运维成本
- 自动化部署和监控流程
- 使用容器化技术简化环境管理
- 建立完善的文档和知识库
4.6 案例研究
案例:金融风控AI Agent
场景:某银行需要实时识别和防范欺诈交易
解决方案:
- 使用openGauss存储历史交易数据和风险特征
- 构建向量化的客户行为模型
- 开发Agent实时分析交易风险
- 集成多个风控Tool(黑名单检查、异常检测、规则引擎)
效果:
- 欺诈识别准确率提升至98%
- 平均响应时间降低至50ms
- 运维成本降低40%
4.7 总结与建议
构建企业级AI Agent是一个系统工程,需要在技术选型、架构设计、开发流程、成本控制等多个方面进行综合考虑。通过采用openGauss作为数据基础,结合先进的AI技术和最佳实践,可以构建高效、安全、可靠的AI Agent系统,为企业创造显著的业务价值。
五、行业趋势与技术展望
openGauss的优势:
✅ 完全开源✅ 华为主导,技术实力强 ✅ 鲲鹏生态深度优化 ✅ 活跃的开源社区
六、总结与建议
6.1 核心价值总结
openGauss作为企业级开源数据库,在AI Agent时代展现出独特的技术优势:
技术优势
- 一体化架构:向量+SQL深度融合,一个数据库解决多种需求
- 卓越性能:亿级向量10ms召回,性能领先10%+
- 企业级特性:ACID事务、高可用、安全审计一应俱全
- 生态:鲲鹏+昇腾全栈优化,满足信创要求
商业价值
- 降低成本:运维成本↓60%,硬件成本↓40%
- 提升效率:业务处理速度↑85%,开发效率↑50%
- 风险可控:数据强一致性
- 快速落地:成熟生态,降低学习曲线
应用前景
- 从简单RAG走向复杂AI Agent
- 从单一模态走向多模态融合
- 从被动响应走向主动决策
- 从单点应用走向全面智能化
6.2 给企业的建议
对于CTO/技术负责人:
- 及早布局:AI Agent是未来3-5年的核心技术趋势,越早投入越有竞争优势
- 选对底座:数据库是AI应用的基础设施,一体化架构将大幅降低复杂度
- 生态建设:培养内部AI+数据库复合型人才,建立技术体系
对于架构师:
- 架构简化:优先考虑一体化方案,避免过度的微服务化
- 性能优化:合理使用向量索引、分区表、查询缓存等技术
- 安全合规:从设计之初就考虑数据安全、隐私保护、审计要求
- 可观测性:建立完善的监控告警体系,确保系统稳定运行
对于开发者:
- 技能升级:掌握向量数据库、AI框架、Prompt工程等新技能
- 最佳实践:学习和借鉴成功案例的架构设计和代码实现
- 开源参与:积极参与openGauss等开源社区,贡献代码和最佳实践
- 持续学习:AI技术快速演进,保持学习和实践
6.3 展望未来
随着大模型能力的持续增强和向量数据库技术的不断成熟,AI Agent将在以下方向取得突破:
技术突破方向:
- 多模态统一向量表示
- 超大规模向量检索(千亿级)
- 联邦学习与隐私保护
- 自适应索引与自动调优
- 边缘计算与云边协同
应用创新方向:
- 虚拟员工:替代重复性脑力劳动
- 智能决策:辅助战略规划和决策
- 创意生成:内容创作、设计辅助
- 科学研究:文献分析、实验设计
- 教育培训:个性化学习助手

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)