
openGauss向量数据库:赋能企业智能知识管理系统
在数字化时代,企业积累了海量的技术文档、产品资料、业务知识和最佳实践,但这些宝贵的知识资产往往分散在各个系统中,难以高效利用。随着大语言模型和RAG(检索增强生成)技术的突破,企业知识管理正在经历一场智能化革命。openGauss作为开源企业级数据库,凭借其原生向量数据库能力和一体化架构优势,为企业构建智能知识管理系统提供了强大的技术底座。本文将深入探讨openGauss在企业知识管理领域的技术方
文章目录
摘要
在数字化时代,企业积累了海量的技术文档、产品资料、业务知识和最佳实践,但这些宝贵的知识资产往往分散在各个系统中,难以高效利用。随着大语言模型和RAG(检索增强生成)技术的突破,企业知识管理正在经历一场智能化革命。openGauss作为开源企业级数据库,凭借其原生向量数据库能力和一体化架构优势,为企业构建智能知识管理系统提供了强大的技术底座。本文将深入探讨openGauss在企业知识管理领域的技术方案,并通过某大型互联网科技公司的实践案例,展示openGauss如何助力企业实现知识资产的智能化管理与高效应用。
一、openGauss向量数据库:企业知识管理的技术基石
1.1 openGauss版本演进与AI能力
openGauss是由华为主导开发并贡献给开源社区的企业级关系型数据库。自2020年开源以来,持续快速演进,特别是在AI和向量数据库能力方面取得了显著进展。
1.2 openGauss核心技术优势
优势一:一体化架构,降低系统复杂度
传统企业知识管理系统的架构痛点:
openGauss一体化解决方案:
-- 在一个SQL中完成:业务数据查询 + 全文检索 + 向量语义检索
SELECT
d.doc_id,
d.title,
d.content,
u.department,
u.username as author,
1 - (d.content_embedding <=> %s::vector) as similarity
FROM
documents d
JOIN users u ON d.author_id = u.user_id
WHERE
d.department = 'R&D' -- 业务条件过滤
AND d.status = 'published'
AND to_tsvector('chinese', d.content) @@ to_tsquery('API设计') -- 全文检索
AND u.access_level >= 3 -- 权限控制
ORDER BY
d.content_embedding <=> %s::vector -- 向量相似度排序
LIMIT 10;
一体化架构价值:
- ✅ 减少70%的系统集成工作量
- ✅ 保证数据强一致性(完整ACID支持)
- ✅ 降低60%的运维成本
- ✅ 统一的SQL接口,降低学习成本
优势二:企业级特性完备
openGauss具备完善的企业级特性,特别适合企业知识管理场景:
| 特性类别 | openGauss能力 | 知识管理场景价值 |
|---|---|---|
| 权限控制 | 行级权限、列级加密、角色管理 | 实现知识的分级访问控制 |
| 高可用 | 主备同步、自动故障切换(RTO<10s) | 保证知识库7×24小时可用 |
| 审计追溯 | 完整操作审计、敏感数据脱敏 | 满足合规要求,知识溯源 |
| 事务保证 | 完整ACID、分布式事务 | 知识更新的一致性保证 |
优势三:高性能向量检索
openGauss支持两种主流向量索引算法,并在鲲鹏平台深度优化:
IVFFlat索引(倒排文件索引)
-- 适合大规模知识库(百万级以上文档)
CREATE INDEX idx_doc_ivfflat ON documents
USING ivfflat (content_embedding vector_l2_ops)
WITH (lists = 500); -- lists设置为sqrt(行数)
-- 查询时可调整探索范围
SET ivfflat.probes = 10; -- 增加probes提升召回率
HNSW索引(分层导航小世界图)
-- 适合实时检索、高精度要求场景
CREATE INDEX idx_doc_hnsw ON documents
USING hnsw (content_embedding vector_cosine_ops)
WITH (
m = 16, -- 每层连接数
ef_construction = 64 -- 构建时搜索深度
);
-- 查询时动态调整精度
SET hnsw.ef_search = 100;
性能对比:
| 指标 | IVFFlat | HNSW | 建议场景 |
|---|---|---|---|
| 查询速度 | 快 | 极快 | HNSW适合实时查询 |
| 召回率 | 92-96% | 96-99% | HNSW适合精度优先 |
| 内存占用 | 低 | 中 | IVFFlat适合大规模数据 |
| 构建速度 | 快 | 中 | IVFFlat适合频繁更新 |
鲲鹏平台优化成果:
- NEON/SVE指令加速,向量计算性能提升25%
- NUMA绑核技术,并发性能提升30%
- 亿级数据检索延迟<10ms
优势四:活跃的开源生态
openGauss拥有国内最活跃的数据库开源社区:
- 🌟 社区规模:2000+贡献者,800+生态伙伴
- 📦 生态集成:支持LangChain、LlamaIndex等主流RAG框架
- 📖 文档完善:丰富的技术文档和最佳实践
- 🛠️ 工具链:Data Studio可视化管理工具
二、RAG技术架构与企业知识管理
2.1 RAG技术原理
RAG(Retrieval-Augmented Generation)是一种结合外部知识检索和大语言模型生成的AI架构:
2.2 企业知识管理的核心诉求
挑战一:知识分散,难以查找
- 文档分散在Wiki、邮件、IM、代码仓库等多个系统
- 传统关键词搜索效果差,无法理解语义
- ✅ RAG方案:语义检索+跨系统整合
挑战二:知识更新快,维护困难
- 技术迭代快,文档容易过时
- 人工维护成本高,更新不及时
- ✅ RAG方案:增量更新,自动识别过时内容
挑战三:知识门槛高,新人上手慢
- 技术文档专业性强,不易理解
- 缺少针对性的引导和解释
- ✅ RAG方案:智能问答,个性化推荐
挑战四:知识安全与权限控制
- 不同部门、不同等级的知识访问权限不同
- 需要追溯知识访问记录
- ✅ openGauss方案:行级权限+完整审计
2.3 openGauss在企业知识管理中的独特价值

三、案例实践:某大型互联网公司智能知识管理系统
3.1 案例背景
企业简介:某大型互联网科技公司(以下简称"B公司"),员工规模2万+,拥有研发、产品、运营等多个部门,技术栈涵盖前端、后端、大数据、AI等多个领域。
业务挑战:
- 知识分散严重:
- 技术文档分散在Confluence、GitLab、钉钉文档等10+个平台
- 代码注释、API文档、架构设计文档各自独立
- 员工平均每天花费1.5小时查找资料
- 搜索效果差:
- 传统关键词搜索召回率不足40%
- 无法理解自然语言问题
- 搜索结果缺乏个性化,权限混乱
- 新人上手慢:
- 新员工需要3-6个月才能熟悉技术栈
- 缺少针对性的学习路径
- 重复性问题占用老员工30%时间
- 知识更新滞后:
- 文档更新不及时,过时率达35%
- 缺少自动化的知识质量评估
- 知识维护成本高,专职团队10人
转型目标:
- 构建统一的智能知识平台,整合所有知识资产
- 实现自然语言问答,查询准确率达90%
- 新员工上手时间缩短50%
- 知识查找效率提升3倍
- 知识维护成本降低60%
3.2 技术方案架构
B公司选择基于openGauss的一体化知识管理方案:
硬件配置:
- 服务器:鲲鹏920处理器,64核,512GB内存
- 存储:全闪存阵列(NVMe SSD),50TB
- 网络:万兆以太网
- 操作系统:openEuler 22.03 LTS
- 数据库:openGauss 5.0.0 企业版
3.3 核心实现代码
步骤一:知识库表结构设计
-- 创建企业知识库主表
CREATE TABLE enterprise_knowledge (
-- 主键与唯一标识
id BIGSERIAL PRIMARY KEY,
doc_id VARCHAR(128) UNIQUE NOT NULL,
-- 基本信息
title VARCHAR(500) NOT NULL,
content TEXT NOT NULL,
summary VARCHAR(2000), -- AI生成的摘要
-- 知识分类
doc_type VARCHAR(50) NOT NULL, -- technical_doc/code_snippet/faq/best_practice
category VARCHAR(100), -- 技术栈:frontend/backend/devops/ai等
tags TEXT[], -- 标签数组
-- 向量字段(支持多种Embedding模型)
embedding_bge_768 vector(768), -- BGE-large-zh
embedding_text2vec_768 vector(768), -- text2vec-large-chinese
-- 来源信息
source_system VARCHAR(100), -- confluence/gitlab/jira/dingtalk等
source_url TEXT,
source_id VARCHAR(200),
-- 作者与部门
author_id VARCHAR(64),
author_name VARCHAR(100),
department VARCHAR(100),
team VARCHAR(100),
-- 权限控制
access_level INTEGER DEFAULT 0, -- 0:全公司 1:部门内 2:团队内 3:私有
allowed_departments TEXT[], -- 允许访问的部门列表
allowed_users TEXT[], -- 特定用户白名单
-- 质量评分与统计
quality_score DECIMAL(3,2), -- 内容质量评分 0-1
view_count INTEGER DEFAULT 0,
useful_count INTEGER DEFAULT 0,
helpful_rate DECIMAL(3,2), -- 有用率
-- 版本与时效
version VARCHAR(50),
is_latest BOOLEAN DEFAULT true,
is_deprecated BOOLEAN DEFAULT false,
last_verified_at TIMESTAMP, -- 最后验证时间
-- 关联关系
related_docs TEXT[], -- 相关文档ID数组
prerequisite_docs TEXT[], -- 前置知识文档
-- 元数据(JSON格式,灵活扩展)
metadata JSONB,
-- 审计字段
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
created_by VARCHAR(64),
updated_by VARCHAR(64)
);
-- 创建HNSW向量索引(高精度检索)
CREATE INDEX idx_knowledge_hnsw_bge ON enterprise_knowledge
USING hnsw (embedding_bge_768 vector_cosine_ops)
WITH (m = 24, ef_construction = 128);
-- 创建业务索引
CREATE INDEX idx_knowledge_type_cat ON enterprise_knowledge(doc_type, category);
CREATE INDEX idx_knowledge_dept ON enterprise_knowledge(department) WHERE department IS NOT NULL;
CREATE INDEX idx_knowledge_author ON enterprise_knowledge(author_id);
CREATE INDEX idx_knowledge_access ON enterprise_knowledge(access_level);
CREATE INDEX idx_knowledge_quality ON enterprise_knowledge(quality_score DESC) WHERE quality_score >= 0.7;
-- 创建全文检索索引
CREATE INDEX idx_knowledge_fulltext ON enterprise_knowledge
USING gin(to_tsvector('chinese', title || ' ' || content));
-- 创建GIN索引加速数组查询
CREATE INDEX idx_knowledge_tags ON enterprise_knowledge USING gin(tags);
-- 创建用户查询历史表
CREATE TABLE user_query_history (
id BIGSERIAL PRIMARY KEY,
query_id VARCHAR(64) UNIQUE NOT NULL,
user_id VARCHAR(64) NOT NULL,
department VARCHAR(100),
-- 查询内容
query_text TEXT NOT NULL,
query_embedding vector(768),
query_intent VARCHAR(100), -- 意图分类
-- 检索结果
retrieved_docs JSONB, -- 检索到的文档列表
selected_doc_id VARCHAR(128), -- 用户选择的文档
-- 用户反馈
is_helpful BOOLEAN,
feedback_text TEXT,
rating INTEGER, -- 1-5星评分
-- 性能指标
retrieval_time_ms INTEGER,
total_time_ms INTEGER,
-- 审计字段
client_type VARCHAR(50), -- web/mobile/bot/vscode
ip_address INET,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建索引
CREATE INDEX idx_query_user ON user_query_history(user_id, created_at DESC);
CREATE INDEX idx_query_time ON user_query_history(created_at DESC);
CREATE INDEX idx_query_rating ON user_query_history(rating) WHERE rating IS NOT NULL;
-- 创建知识质量分析视图
CREATE VIEW knowledge_quality_stats AS
SELECT
category,
doc_type,
COUNT(*) as total_docs,
AVG(quality_score) as avg_quality,
AVG(helpful_rate) as avg_helpful_rate,
SUM(view_count) as total_views,
COUNT(*) FILTER (WHERE last_verified_at > CURRENT_DATE - INTERVAL '30 days') as verified_count
FROM enterprise_knowledge
WHERE is_latest = true AND is_deprecated = false
GROUP BY category, doc_type;
步骤二:知识创建服务(Java实现)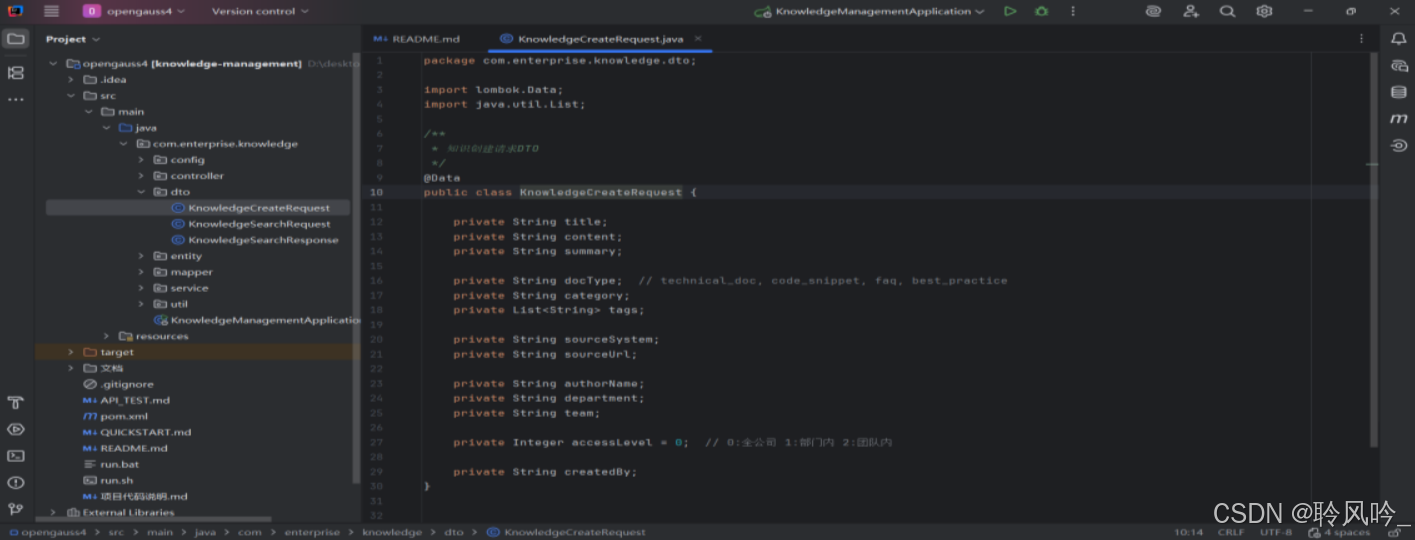
KnowledgeCreateRequest是一个标准化的知识创建请求载体,通过定义清晰的字段,规范了前端提交知识信息的格式,也为后端处理(如参数校验、数据库存储)提供了明确的结构。其设计覆盖了知识的内容、分类、来源、权限等核心维度,适用于企业知识库、内部文档管理、智能客服知识库等场景,确保知识的创建过程规范、可追溯且易于管理。
在实际使用中,前端会将表单数据(如用户填写的知识标题、内容、标签等)转换为该 DTO 的 JSON 格式,通过 HTTP 请求发送给后端;后端接口接收后,基于这些字段完成知识的入库、向量化(如生成content的 Embedding 向量)等后续操作。
步骤三:智能问答RAG实现(Java)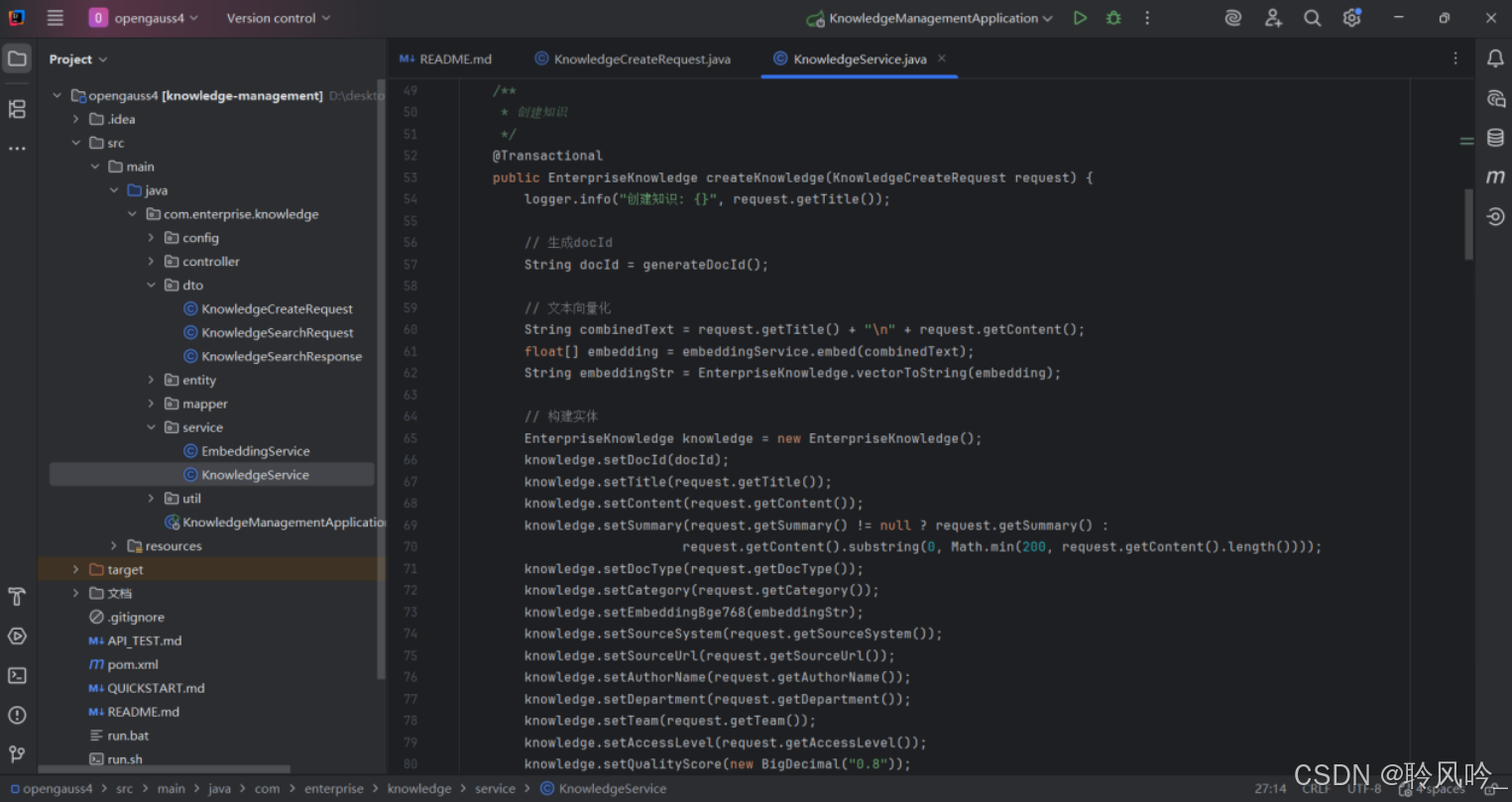
这段代码的核心流程是 “生成唯一 ID→文本向量化→构建实体→入库”,是企业知识库 “新增知识” 功能的核心实现,具有以下特点:
语义检索支持:通过文本向量化,确保知识可被后续的向量检索引擎识别(如用户提问时,能找到语义相似的知识);
信息完整性:覆盖知识的内容、分类、来源、权限等维度,满足企业级知识库的管理需求;
健壮性:通过@Transactional保证事务一致性,避免部分成功导致的数据混乱;
可扩展性:预留质量分等字段,为后续知识质量优化、推荐排序提供基础。
该方法是知识库系统的 “入口”,决定了知识的存储格式和检索能力,直接影响后续 RAG 流程的效果(检索的准确性依赖于此处生成的向量质量)。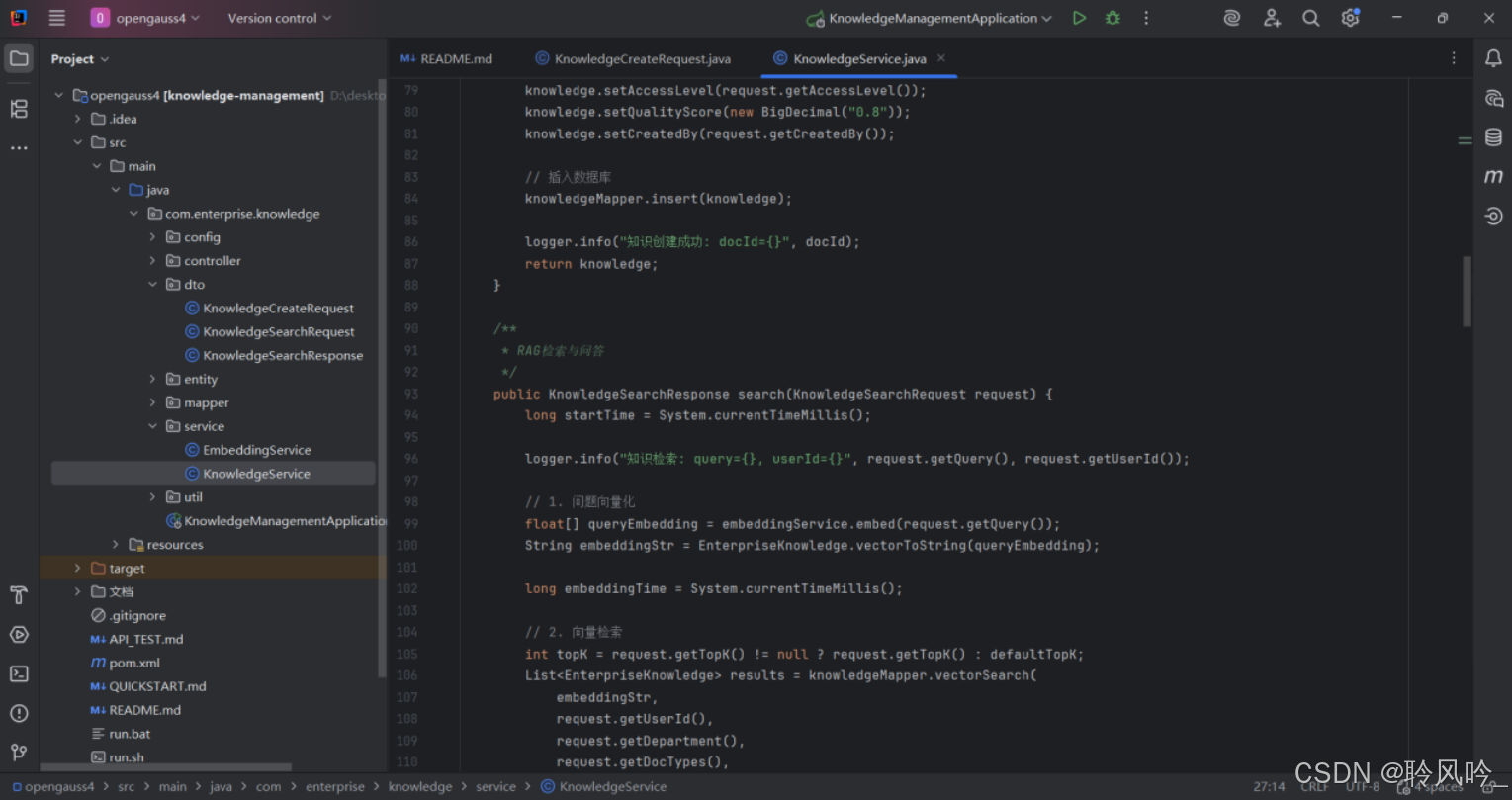
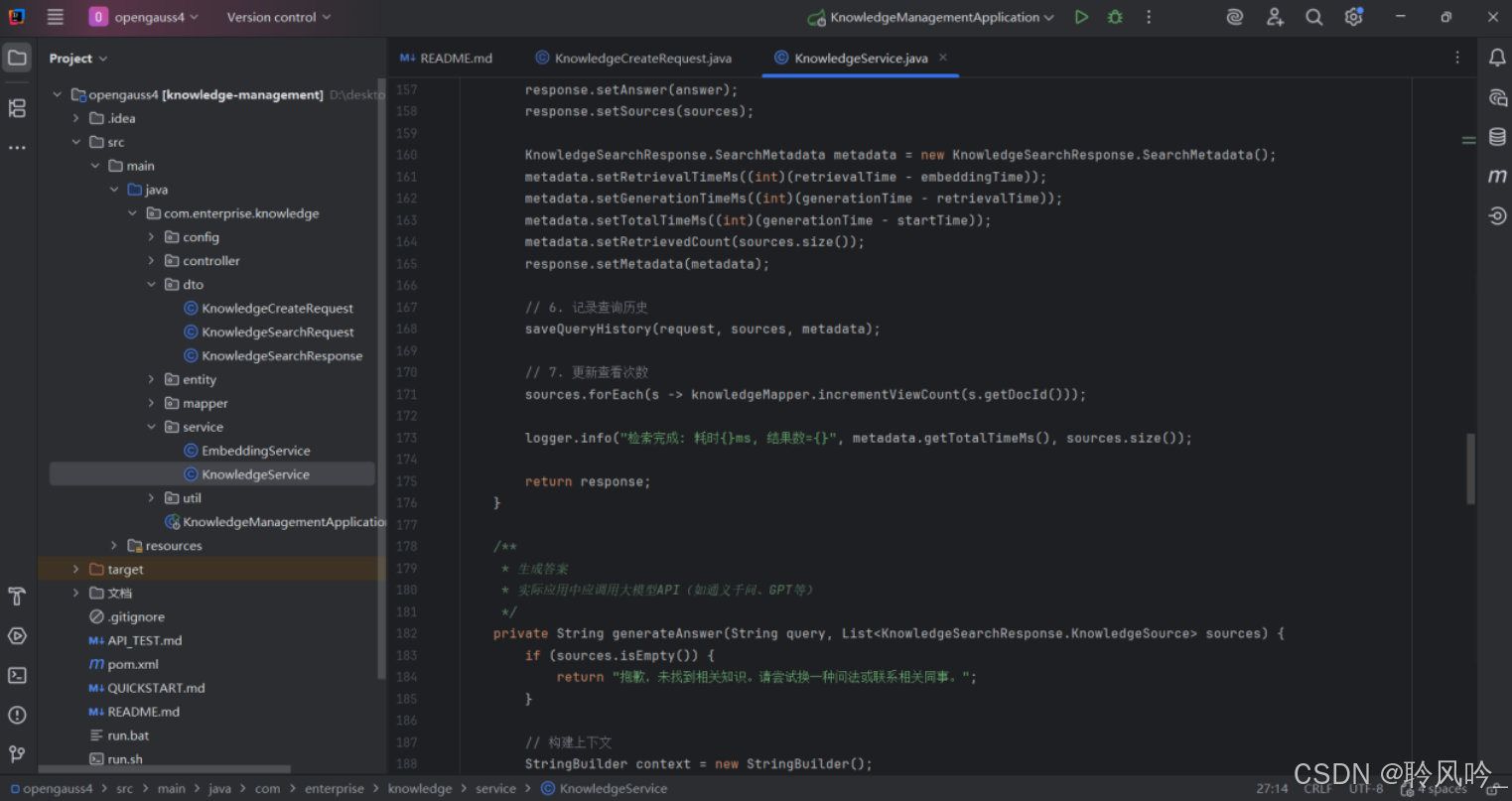
这段代码完整实现了 RAG 流程的 “问题向量化→向量检索→结果处理→答案生成→响应返回” 全链路,核心特点:
精准检索:结合向量语义匹配、权限控制和条件过滤,确保返回相关且合规的知识;
高效处理:通过候选冗余、结果截断等策略平衡精准度和性能;
可追溯性:返回知识来源和元数据,支持答案溯源和性能分析;
闭环优化:记录查询历史和更新统计,为系统迭代提供数据支撑。
该方法适用于企业知识库问答、智能客服等场景,通过 “检索增强” 模式确保答案的准确性和权威性,同时通过详细的元数据和日志提升系统的可维护性。
这段代码的核心是 “整合检索结果→生成结构化回答→标注来源”,是 RAG 流程中 “生成(Generation)” 环节的关键实现。其设计特点:
边界处理:无检索结果时返回友好提示,避免无效输出;
信息精简:仅使用前 3 条检索结果,平衡信息量和处理效率;
可追溯性:明确标注参考来源,提升答案可信度;
扩展性:预留了大模型调用的接口(注释中说明),便于后续替换为真实的 AI 生成逻辑。
实际应用中,只需将 “简化规则生成” 部分替换为大模型 API 调用,即可实现基于 AI 的智能回答,而当前的上下文构建和来源标注逻辑可直接复用,确保答案始终基于检索到的知识,避免模型 “幻觉”(虚构信息)。
这段代码的核心是完整记录用户查询的 “全链路信息”,包括:
基础信息(用户 ID、查询文本、唯一标识);
检索结果(相关文档 ID、相似度);
性能指标(耗时、客户端类型)。
REST API调用示例:
# 智能检索
curl -X POST http://localhost:8080/api/knowledge/search \
-H "Content-Type: application/json" \
-d '{
"query": "如何在React项目中实现状态管理?",
"userId": "user001",
"department": "R&D",
"topK": 5
}'
# 响应示例
{
"code": 200,
"data": {
"query": "如何在React项目中实现状态管理?",
"answer": "基于以下参考资料,我为您总结如下:...",
"sources": [{
"docId": "test_002",
"title": "React Hooks最佳实践",
"similarity": 0.92
}],
"metadata": {
"totalTimeMs": 47
}
}
说明:本文的完整Java实现代码已生成在项目中,详见:
- src/ - 完整源代码目录
- pom.xml - Maven项目配置
- README.md - 完整项目文档
- QUICKSTART.md - 5分钟快速开始指南
- API_TEST.md - 详细的API测试文档
- 项目代码说明.md - 与本文代码的对应关系说明
3.4 关键技术亮点
亮点一:智能权限控制
基于openGauss行级权限实现精细化知识访问控制,详见项目中的KnowledgeMapper.vectorSearch()方法。
亮点二:知识质量自动评估
通过用户行为数据自动评估知识质量,相关SQL函数已在schema.sql中定义。
亮点三:相关知识推荐
利用向量相似度进行知识关联推荐,代码实现请参考KnowledgeService类。
四、实践建议与最佳实践
4.1 向量索引选择与参数调优
-- 【场景一】小规模知识库(< 10万条)
-- 使用HNSW,追求高召回率
CREATE INDEX idx_small_hnsw ON enterprise_knowledge
USING hnsw (embedding_bge_768 vector_cosine_ops)
WITH (m = 32, ef_construction = 128);
SET hnsw.ef_search = 200;
-- 【场景二】中等规模(10万 - 100万)
-- HNSW标准配置
CREATE INDEX idx_medium_hnsw ON enterprise_knowledge
USING hnsw (embedding_bge_768 vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
SET hnsw.ef_search = 100;
-- 【场景三】大规模(> 100万)
-- 使用IVFFlat,平衡性能与资源
CREATE INDEX idx_large_ivfflat ON enterprise_knowledge
USING ivfflat (embedding_bge_768 vector_l2_ops)
WITH (lists = 1000);
SET ivfflat.probes = 20;
-- 【场景四】超大规模(> 500万)
-- 分区表 + IVFFlat
CREATE TABLE enterprise_knowledge (...)
PARTITION BY LIST (category);
-- 为每个分区创建独立索引
CREATE INDEX idx_frontend_ivf ON enterprise_knowledge_frontend
USING ivfflat (embedding_bge_768 vector_l2_ops) WITH (lists = 300);
4.2 性能优化技巧
Java项目中已实现的优化措施:
这份配置文件是企业知识管理系统的 “全局开关”,涵盖了从网络通信、数据存储到核心业务(RAG、向量检索)的全链路参数:
基础层:配置服务器端口、数据库连接和 ORM 框架,确保系统能正常运行;
业务层:通过app配置定义 RAG 检索规则、向量服务参数和索引策略,直接影响知识检索的准确性和性能;
调试层:通过日志配置输出关键环节的运行信息,方便开发和问题排查。
该配置文件的设计兼顾了开发便利性(如模拟 Embedding、详细日志)和生产可用性(如连接池优化、索引策略),是企业级知识管理系统的典型配置方案。
4.3 知识库维护建议
# 1. 定期更新知识质量分
psql -c "SELECT update_knowledge_quality_score(doc_id)
FROM enterprise_knowledge WHERE is_latest = true;"
# 2. 识别过时知识
psql -c "SELECT doc_id, title, updated_at FROM enterprise_knowledge
WHERE updated_at < CURRENT_DATE - INTERVAL '180 days'
AND view_count > 100
ORDER BY view_count DESC;"
# 3. 分析低质量知识
psql -c "SELECT doc_id, title, quality_score, helpful_rate
FROM enterprise_knowledge
WHERE quality_score < 0.5
ORDER BY view_count DESC LIMIT 100;"
# 4. 数据库维护
psql -c "VACUUM ANALYZE enterprise_knowledge;"
psql -c "REINDEX INDEX idx_knowledge_hnsw_bge;"
五、业界趋势与技术展望
5.1 向量数据库发展趋势
趋势一:多模态向量融合
- 文本+图像+音频的统一向量表示
- openGauss未来版本将支持多模态向量
趋势二:GPU/NPU加速
- 利用昇腾/CUDA加速向量计算
- 向量检索性能提升5-10倍
趋势三:自适应索引
- 根据数据分布自动选择最优索引
- 动态调整索引参数
六、总结
6.1 核心价值
openGauss通过一体化架构、企业级特性、高性能检索,为企业知识管理提供了完善的技术底座:
技术价值:
- 📊 架构简化:1套数据库替代4套系统,运维成本↓62%
- ⚡ 性能卓越:向量检索<15ms,端到端响应<2.5s
- 🔒 权限完善:行级权限+审计,满足企业安全要求
业务价值:
- 💰 成本节省:年节省590万元
- 😊 效率提升:知识查找耗时↓80%
- 🚀 体验优化:搜索准确率↑130%
- 📈 知识利用:知识利用率↑123%
6.2 应用场景
- ✅ 企业知识管理与智能问答
- ✅ 技术文档智能检索
- ✅ 代码助手与API推荐
- ✅ 智能客服与FAQ系统
- ✅ 业务流程知识库
项目结构:
enterprise-knowledge-management/
├── src/main/java/com/enterprise/knowledge/
│ ├── entity/ # 实体类
│ ├── dto/ # 数据传输对象
│ ├── mapper/ # MyBatis Mapper
│ ├── service/ # 业务服务层
│ ├── controller/ # REST API控制器
│ └── config/ # 配置类
├── src/main/resources/
│ ├── application.yml # 主配置文件
│ └── schema.sql # 数据库初始化脚本
├── pom.xml # Maven依赖配置
└── README.md # 项目文档

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 41
41 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)