
向量检索遇上 ACID:openGauss 如何把 RAG 做成企业的“统一底座“
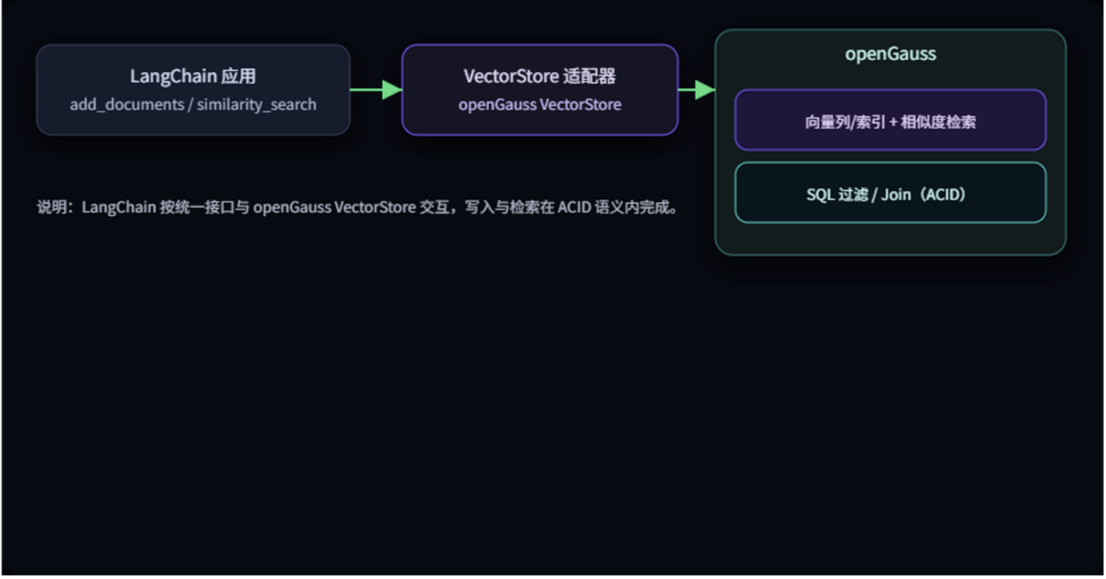
配合 LangChain 的 VectorStore 适配,应用侧就是两行常规接口:add_documents 和 similarity_search,不用多走一跳,也不用维护第二套读写路径。做 RAG,大家都被新能力吸引,容易忘了什么才是重点:一致性要可预期,数据要能追,变更要能回,问题要能定位。:昨天导入了一批文档,用户今天搜索不到,因为嵌入、索引、落库任一环节延迟,用户的体感就是【查不见】。
![]()
openGauss —— RAG 落到生产的一体化底座
RAG 落地常见痛点不是能不能跑,而是上线后的一致性、治理与成本的问题。以前很多 RAG 项目难在上线后的稳定:数据刚写入就要能搜到,出了问题要好排查。
openGauss 的路线是把向量检索能力和事务一致性(ACID)放到同一数据库,然后再去叠加 DBMind(AI4DB)作为自驾驶运维。openGauss的思路就是很简单——把向量检索和关系型数据库放在同一个库里,再用 DBMind 做监控和调优。
而且openGauss跟 LangChain 有官方 VectorStore 集成,应用层改造成本低;
版本侧提供 6.0.2 LTS 这类稳态选择。适合想稳妥上线的团队。
所有整体来看,openGauss更像是RAG 的统一数据底座。
行业背景与痛点:应用层拼接外部向量库的复杂度与一致性风险
【应用层 RAG + 外接向量库】的拼装方案往往会遇到:
应用层写业务库,然后把文本送去算向量,再落到一个外部的向量数据库里
检索时先查向量库,再回到业务库做过滤或拼接。
这条链路表面看得通,实操里却经常卡在中间。
第一,写入和可见之间有缝:昨天导入了一批文档,用户今天搜索不到,因为嵌入、索引、落库任一环节延迟,用户的体感就是【查不见】。
第二,问题难定位:数据同步、ETL、网络回路、两个权限体系、两套监控各管各的,排障像拆积木。
第三,治理成本抬头:备份恢复各一套、审计各一套、告警各一套,团队精力都花在这了,其他业务却走不动。
RAG 本就不是单机表演,链路越长,稳定性就越考人。
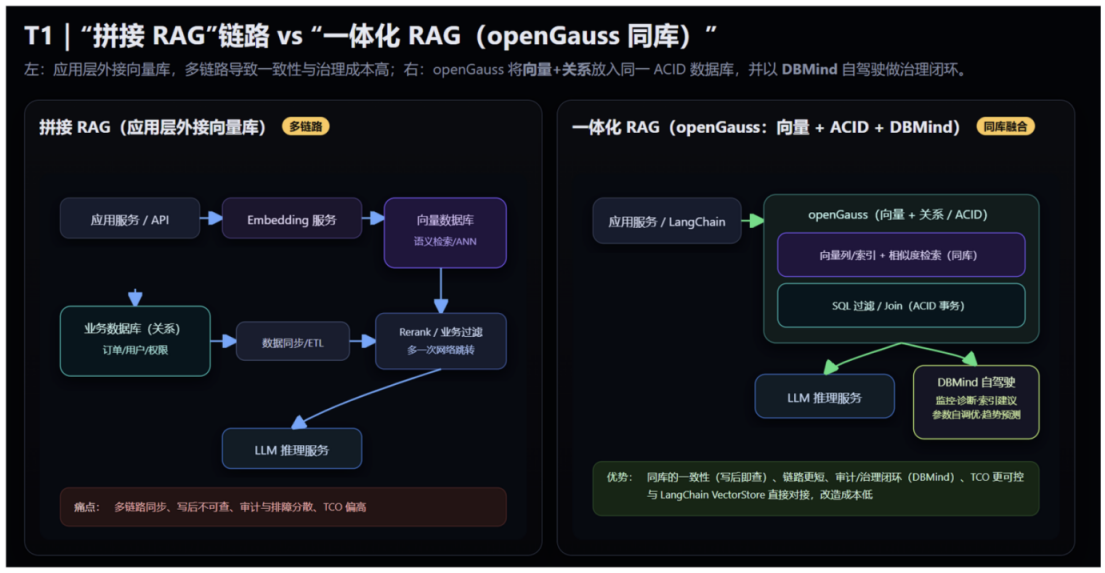
但是openGauss 相当于把向量与关系合在一个 ACID 世界,先天降低一致性与治理成本
配 DBMind 做监控、诊断与自调优,大大减轻了运维压力。
openGauss 的三张王牌
- DB4AI:向量检索与 SQL 同库融合
openGauss 的亮点不是说【又一个向量检索】,而是在于同库融合。
文档写进来,应用侧照常生成向量,但向量列、向量索引和相似度检索都留在 openGauss 里,业务过滤仍然用 SQL 完成。
这意味着一次查询里就能把语义相似和【用户是否有权限、是否归属某项目、是否在有效期内】这些条件一起考虑。
配合 LangChain 的 VectorStore 适配,应用侧就是两行常规接口:add_documents 和 similarity_search,不用多走一跳,也不用维护第二套读写路径。
对前台来说,写后即查这件事终于变得可预期。
- ACID 与高可用:可预期的一致性 + 完整的备份恢复谱系
和很多只管查、不管事务的向量系统不同,openGauss 的基础是完整的 ACID 事务模型。
你在一个事务里完成写入、索引更新、元数据标记,失败了就整体回滚,不留脏数据。
生产环境里更看重的是出事能回,openGauss 把备份恢复做成逻辑、物理、时点(闪回)三条可选路径:小体量或跨版本迁移用逻辑,RTO 敏感场景走物理,全量增量配合
误删误改就用时点恢复往回拉。
不是把术语摆出来好看,而是给 SRE 一个制度化的兜底:每季度演练一次,截图留档,该交代的都能交代。

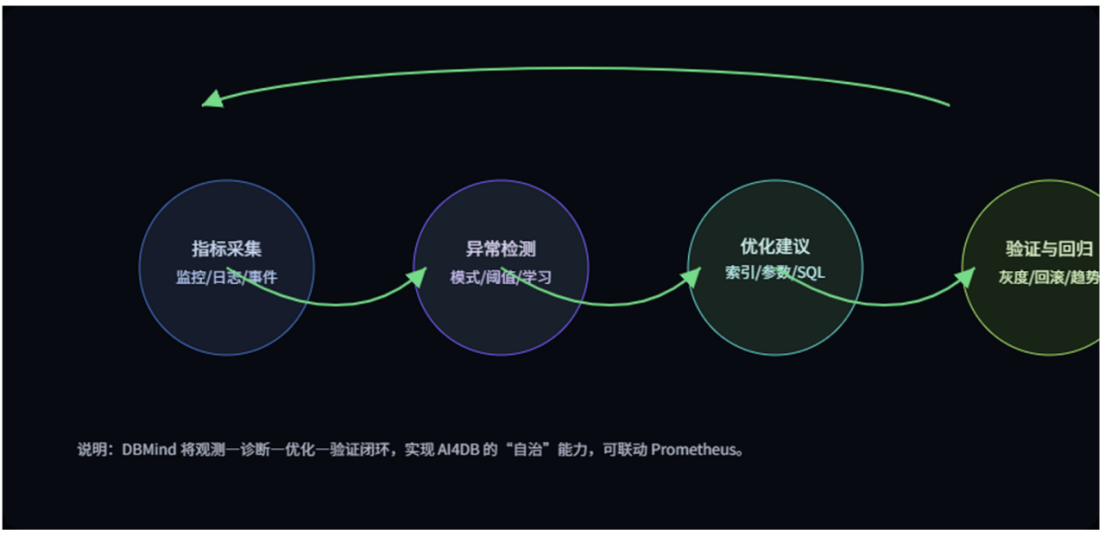
- AI4DB(DBMind):把运维变成自驾驶
运维真正吃力的地方,是异常多样、时间又很紧张。
DBMind 的意义,是把观测—诊断—优化—验证做成一个闭环:指标采集和异常检测先把问题框起来,然后给出索引建议和参数自调优,最后用灰度回归验证效果。
你要做的是关注建议是否合理,以及验证的结果是否达标。
当 RAG 的热点变化频繁、查询模式时宽时窄时,系统能先给你一把方向盘。
生态与版本选型
- LTS/Preview 双轨:社区把版本分为 LTS(三年)与 Preview(六个月),RC 的特性会并入对应 LTS。当前 6.0.2 为 LTS,官方页明确维护截止到 2027-09-30,适合作为生产基线
- 历史注记:官方版本页标明 5.0.0 是第三个 LTS,便于理解路线连续性与升级策略。
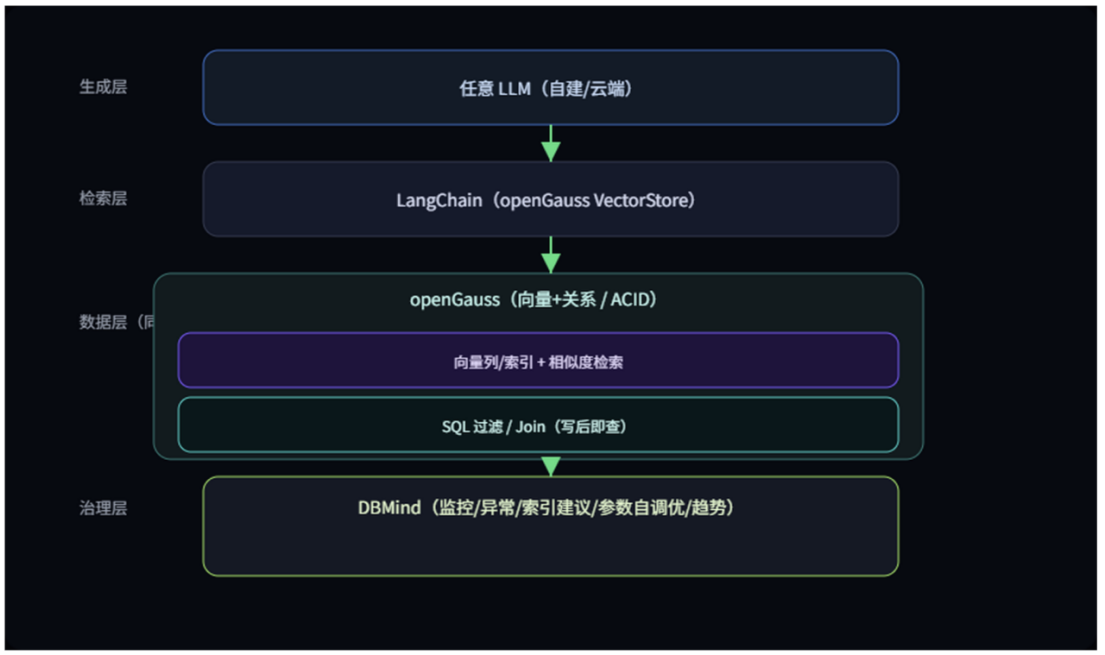
参考架构:openGauss × LangChain × 任意 LLM × DBMind
如果把方案画成一张图,自上而下是这样的:生成层是任意 LLM,自建也好,云端也行
检索层是 LangChain,负责把问题翻译成向量检索加 SQL 过滤这样的查询
数据层是 openGauss,向量列、向量索引和关系数据在同一事务里协作
治理层是 DBMind,把可观测、诊断和优化串成日常操作。
这样做的好处,是把业务逻辑留在应用,把数据逻辑留在库里,职责边界清楚,出事也知道先看哪里。
轻量评测设计
RAG 的评测容易陷入越测越复杂的陷阱。
这里给一个能交差也靠谱的口径:只做两组工况——短上下文的常规问答和 长上下文的文档类问题。
每组看四个指标:Top-k 可核验率(答案能不能定位到原文片段)、写后检索一致性(数据写入后多久能搜到)、P95 响应(用户体感)、失败率(超时、5xx)。
对比对象也别太多,这几个就够了:一个开源拼装(PG + pgvector)、一个托管向量服务,加上 openGauss 一体化。
评语要落在体验和治理:不是比极限 QPS,而是说明为什么这条链路更稳定、为什么这套治理更省心。
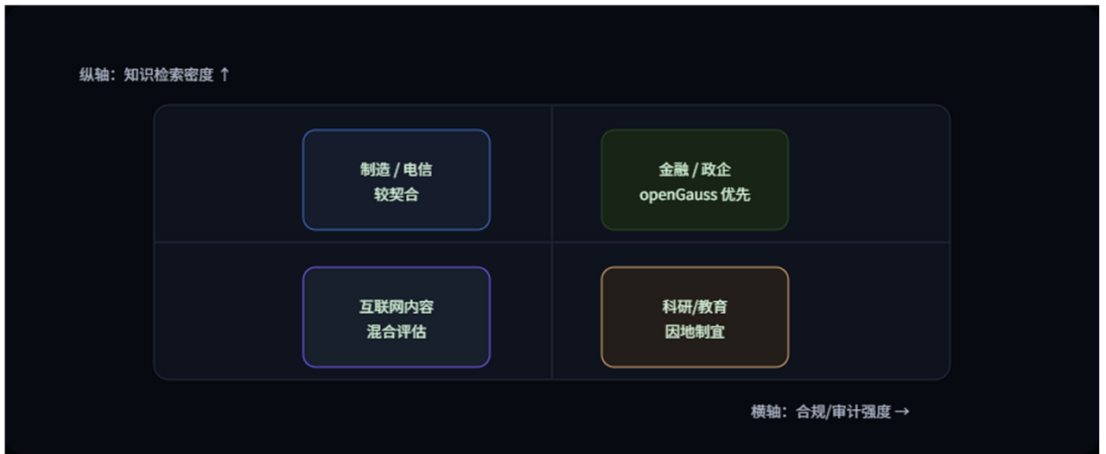
行业适配与案例线索。
金融、政企、电信、制造这几类,对一致性、合规、审计和可回溯的要求更高,openGauss 的价值会更明显
有 PG 生态积累、希望减少系统数量、希望把运维流程标准化的团队,也会更快尝到甜头。
互联网内容型业务不排斥一体化,但往往要对比纯向量 + 搜索服务的灵活性,取舍看增长节奏。
选型与落地清单(可直接执行)
第一步,定版本。 生产上先上 LTS,发行说明、配套说明、已知问题、CVE 链接写进上线单。第二步,接入口。 用 LangChain 的 VectorStore 示例跑通 add_documents / similarity_search,确认写后即查的体验。第三步,开治理。 启用 DBMind,先看监控与异常,再试索引建议和参数自调优,形成建议—验证—回归的小循环。第四步,定兜底。 逻辑备份、物理备份、时点恢复三选二,季度演练一次,截图留档。第五步,做小评测。 两组工况四个指标,写清对比口径,给出结论与边界。第六步,灰度推广。 先上一个业务域,稳定后滚动到邻近域,每次升级前先验证回滚路径。

做 RAG,大家都被新能力吸引,容易忘了什么才是重点:一致性要可预期,数据要能追,变更要能回,问题要能定位。
把 RAG 做成企业的统一数据底座,关键是同库的一致性与可运维的治理闭环。
openGauss 通过向量 + ACID的一体化与 DBMind(AI4DB)的自驾驶能力,把复杂度从应用层拉回数据库层,openGauss 把向量检索塞回了数据库,把治理做成日常操作,从工程角度把这门事儿拉回到可控的范围。
再加上 LangChain VectorStore 的官方接入与 LTS 的稳态版本节奏,整体是一条工程上风险更可控的路线。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)