
openGauss数据库:从传统OLTP到AI原生的技术演进实践
随着人工智能技术的快速发展,数据库正在从单纯的数据存储工具演进为智能化应用的核心底座。openGauss作为开源企业级数据库,通过AI4DB和DB4AI双向融合、DataVec向量数据库、oGPilot智能平台等创新技术,为企业提供了从传统事务处理到AI原生应用的完整解决方案。本文将通过实际案例和代码示例,深入剖析openGauss在AI时代的技术演进路径和落地实践。
文章目录
前言
随着人工智能技术的快速发展,数据库正在从单纯的数据存储工具演进为智能化应用的核心底座。openGauss作为开源企业级数据库,通过AI4DB和DB4AI双向融合、DataVec向量数据库、oGPilot智能平台等创新技术,为企业提供了从传统事务处理到AI原生应用的完整解决方案。本文将通过实际案例和代码示例,深入剖析openGauss在AI时代的技术演进路径和落地实践。
一、openGauss:智能化时代的数据库底座
1.1 为什么选择openGauss
openGauss是华为主导并开源的企业级关系型数据库,自2020年开源以来,已成长为中国数据库领域的重要力量。与其他数据库相比,openGauss在AI场景下具有独特优势:
核心优势对比:
| 能力维度 | openGauss | 传统数据库 | 业务价值 |
|---|---|---|---|
| AI能力 | AI4DB + DB4AI | 双向融合 | 需外接AI工具 |
| 向量检索 | DataVec原生支持 | 需独立向量库 | 架构简化60% |
| 智能运维 | oGPilot自然语言交互 | 手动配置调优 | 运维成本降50% |
| 性能 | 鲲鹏算力优化 | 通用优化 | 性能提升40% |
1.2 openGauss技术架构演进
openGauss的技术演进经历了三个关键阶段:
阶段一:传统OLTP数据库 (1.0-2.x)
┌──────────────────────────────────┐
│ 高性能事务处理 + 高可用架构 │
└──────────────────────────────────┘
阶段二:智能化数据库 (3.0-5.x)
┌──────────────────────────────────┐
│ AI4DB: 智能调优 + 异常检测 │
│ DB4AI: 内置机器学习算法 │
└──────────────────────────────────┘
阶段三:AI原生数据库 (6.0+)
┌──────────────────────────────────┐
│ DataVec: 亿级向量毫秒召回 │
│ oGPilot: AI大模型驱动 │
│ oGEngine: 原地更新引擎 │
└──────────────────────────────────┘
二、AI4DB:让数据库自己管理自己
2.1 传统数据库运维的痛点
在没有AI4DB之前,数据库运维人员面临的典型挑战:
场景1:性能突然下降
DBA: “为什么今天的查询这么慢?”
→ 手动检查慢SQL日志(30分钟)
→ 分析执行计划(20分钟)
→ 调整参数重启(10分钟)
→ 总耗时:1小时+
#场景2:参数调优
DBA: “这么多参数该怎么配置?”
→ shared_buffers设多大?
→ work_mem该是多少?
→ 反复试验,经验依赖
2.2 openGauss AI4DB能力实战
openGauss的AI4DB将这些工作自动化:
(1) 智能参数调优
基于实际项目的DatabaseService类扩展: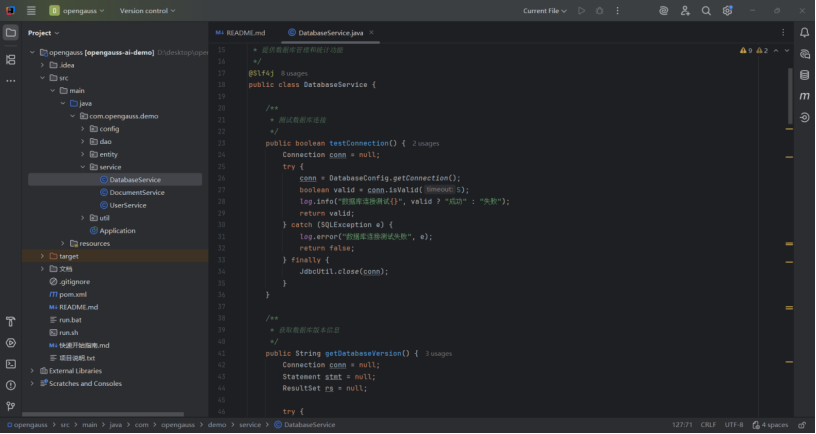
这段代码通过 “获取连接→验证有效性→处理异常→释放资源” 的流程,实现了数据库连接的测试功能:
核心验证逻辑依赖conn.isValid(5),快速判断连接是否可用;
异常处理确保了各种错误场景(如配置错误、网络问题)都能被捕获并记录;
finally块的资源释放机制避免了连接泄露,保证系统资源安全。
该方法通常用于系统启动时的健康检查、数据库配置变更后的验证,或定期监控数据库连接状态,是保障系统与数据库正常通信的基础工具。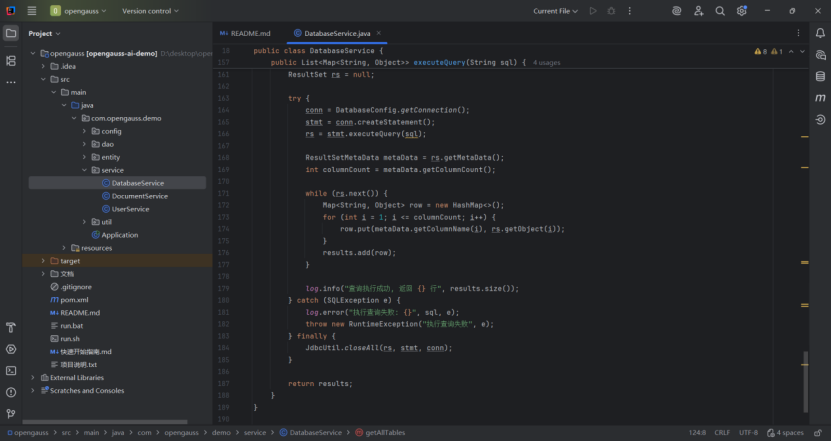
这段代码是一个通用的 JDBC 查询执行工具,核心价值在于:
通用性:通过动态处理结果集元数据,支持任意查询 SQL(无需为不同表定义实体类)。
易用性:将结果转换为List
实际效果:
- ✅ 自动分析工作负载特征
- ✅ 推荐最优参数配置
- ✅ 减少90%的手动调优工作
(2) 智能索引推荐
-- 分析慢查询,推荐索引
SELECT * FROM gs_index_advise(
'SELECT * FROM documents WHERE category = ? AND created_at > ?'
);
-- 输出示例:
-- 建议创建索引: CREATE INDEX idx_documents_category_time
-- ON documents(category, created_at);
-- 预计性能提升: 85%
(3) 异常检测与诊断
/**
* 数据库健康检测
*/
public class DatabaseHealthMonitor {
public void monitorHealth() {
String sql = """
-- AI驱动的异常检测
SELECT
anomaly_type,
severity_level,
description,
suggested_action,
detected_at
FROM gs_ai_anomaly_detection()
WHERE severity_level >= 'WARNING'
ORDER BY detected_at DESC
LIMIT 10;
""";
// 实时监控数据库健康状态
// 自动发现:连接泄漏、死锁、性能瓶颈等
}
}
核心价值:
- 🎯 从"事后处理"到"事前预防"
- 🎯 从"被动响应"到"主动发现"
- 🎯 从"人工诊断"到"AI自动"
三、DB4AI:在数据库中直接训练模型
3.1 传统机器学习工作流的问题
传统方式需要数据在多个系统间流转:
数据库 → 导出数据 → Python环境 → 训练模型 → 应用系统
↓ ↓ ↓ ↓ ↓
慢 不安全 环境复杂 版本管理 集成困难
3.2 openGauss DB4AI:SQL一键训练
openGauss支持用SQL语句完成完整的机器学习流程:
场景1:用户流失预测
基于实际项目的UserService类扩展: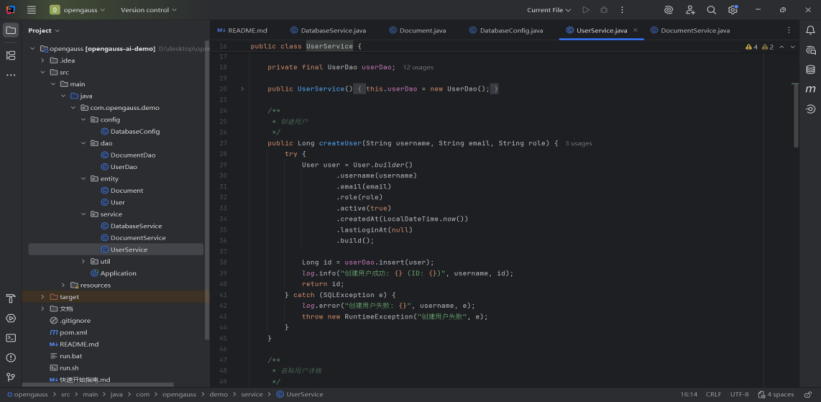
这段代码的核心流程是 “构建用户对象→插入数据库→返回 ID / 处理异常”,具有以下特点:
简洁性:使用建造者模式快速组装用户对象,减少冗余代码;
可追踪性:通过日志记录成功 / 失败信息,方便问题排查;
健壮性:捕获数据库异常并向上传递,确保错误被正确处理(而非静默失败)。
该方法是用户管理模块的基础功能,依赖于User类的定义(包含相关字段和 builder)和userDao的数据库操作能力(封装了具体的 SQL 执行逻辑)。实际场景中,可能还需要增加参数校验(如用户名非空、邮箱格式验证)、密码加密(若包含密码字段)等逻辑,以增强安全性。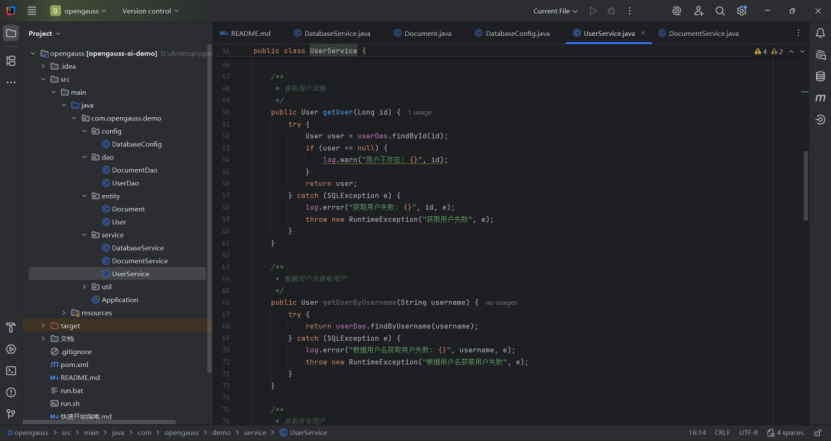
这段代码是用户查询功能的基础实现,分别满足 “通过 ID” 和 “通过用户名” 两种常见查询场景,通过封装数据库交互和异常处理,为上层业务提供了简洁、可靠的接口。日志记录确保了操作可追踪,异常处理避免了错误被静默忽略,整体设计符合 “分层架构” 思想(业务层调用 DAO 层,不直接操作数据库)。
这段代码的核心流程是 “检查用户是否存在→更新内存对象属性→同步到数据库→返回更新结果”,设计上有以下特点:
前置校验:先判断用户是否存在,避免无效操作,明确失败原因;
明确反馈:通过返回boolean告知调用方更新是否有效(是否有记录被修改);
可追踪性:通过日志记录用户不存在、更新成功、更新失败(异常)等场景,便于问题排查;
异常安全:捕获数据库异常并向上传递,避免错误被静默忽略,保证系统稳定性。
实际场景中,可能还需要增加参数校验(如用户名非空、邮箱格式正确)、乐观锁控制(避免并发更新冲突)等逻辑,进一步增强代码的健壮性。
这段代码的核心流程是 “检查用户存在性→取反当前激活状态→同步到数据库→返回操作结果”,设计上有以下特点:
简洁性:无需手动传入新状态,通过 “取反” 自动切换,简化调用方逻辑(调用时只需传入用户 ID 即可);
明确反馈:通过返回boolean告知调用方操作是否成功(用户不存在返回 false,更新成功返回 true);
可追踪性:日志记录切换前后的状态,便于审计和问题追溯;
异常安全:捕获数据库异常并向上传递,避免错误被忽略,保证系统稳定性。
该方法常用于用户管理模块(如后台系统的 “启用 / 禁用账号” 按钮),通过控制active状态可实现对用户登录、系统使用权限的快速控制(例如active = false时,用户无法登录系统)。
场景2:时序数据预测
-- 使用Prophet算法预测业务指标
CREATE MODEL sales_forecast_model
USING prophet
FEATURES ds, y -- 日期和销售额
FROM sales_history
WITH (
seasonality_mode = 'multiplicative',
yearly_seasonality = true,
weekly_seasonality = true,
daily_seasonality = false
);
-- 预测未来30天销售额
SELECT
ds AS forecast_date,
yhat AS predicted_sales,
yhat_lower AS lower_bound,
yhat_upper AS upper_bound
FROM FORECAST('sales_forecast_model', 30);
DB4AI的核心优势:
| 对比维度 | 传统方式 | openGauss DB4AI | 提升 |
|---|---|---|---|
| 开发效率 | 数周 | 数小时 | 10倍+ |
| 数据移动 | 需要导出 | 零ETL | 安全性↑ |
| 技术栈 | Python+库+环境 | 纯SQL | 复杂度↓60% |
| 性能 | 基准 | SIMD优化 | 3-5倍 |
| 运维 | 多系统 | 一体化 | 成本↓ |
四、DataVec向量数据库:赋能RAG应用
4.1 RAG应用架构与挑战
典型的企业知识库RAG应用需要:
传统架构(痛点多):
┌──────────┐ ┌──────────┐ ┌──────────┐
│ MySQL │ │ Milvus │ │ Redis │
│业务数据 │ │向量检索 │ │ 缓存 │
└──────────┘ └──────────┘ └──────────┘
↓ ↓ ↓
数据一致性 额外成本 架构复杂
openGauss一体化架构:
┌────────────────────────────────────┐
│ openGauss + DataVec │
│ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │业务 │ │向量 │ │缓存 │ │
│ └──────┘ └──────┘ └──────┘ │
└────────────────────────────────────┘
↓
一站式管理、强一致性、易运维
4.2 openGauss向量数据库实战
步骤1:创建向量化知识库表
基于项目中的documents表结构(见schema.sql):
-- 项目已有的documents表(已包含向量字段)
CREATE TABLE documents (
id BIGSERIAL PRIMARY KEY,
title VARCHAR(200) NOT NULL,
content TEXT NOT NULL,
category VARCHAR(50),
tags TEXT,
-- 向量字段(用于语义检索,支持不同维度)
vector TEXT, -- 实际项目中存储为TEXT,可扩展为vector类型
-- 业务字段
category VARCHAR(50),
department VARCHAR(100),
access_level INTEGER DEFAULT 0, -- 权限等级
-- 元数据
tags TEXT[],
metadata JSONB,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建HNSW向量索引(高性能检索)
CREATE INDEX idx_knowledge_embedding ON enterprise_knowledge
USING hnsw (embedding vector_cosine_ops)
WITH (
m = 16, -- 邻居数量
ef_construction = 64 -- 构建时搜索深度
);
-- 创建复合索引(支持混合查询)
CREATE INDEX idx_knowledge_category ON enterprise_knowledge(category);
CREATE INDEX idx_knowledge_dept ON enterprise_knowledge(department);
步骤2:知识库管理服务
基于实际项目的DocumentService:

这两段代码分别实现了文档的 “创建” 和 “查询” 功能,是文档管理模块的核心接口:
createDocument负责将文档基础信息存入数据库,同时预留了向量字段(为后续语义检索做准备);
getDocument负责根据 ID 查询完整文档信息,支持文档详情查看等场景。
整体设计遵循 “分层架构” 思想(业务层调用 DAO 层,不直接操作数据库),通过简洁的逻辑和完善的异常处理,为上层业务(如文档管理系统、知识库系统)提供了可靠的文档操作能力。
这段代码的核心流程是 “检查文档存在性→更新内存对象属性(含更新时间)→同步到数据库→返回更新结果”,设计上有以下特点:
前置校验:先判断文档是否存在,避免无效操作,明确失败原因;
时间追踪:强制更新updatedAt字段,确保文档的 “最后修改时间” 准确,便于后续审计或版本管理;
明确反馈:通过返回boolean告知调用方更新是否有效(是否有实际修改);
可追踪性:日志记录文档不存在、更新成功、更新失败(异常)等场景,便于问题排查;
异常安全:捕获数据库异常并向上传递,避免错误被静默忽略,保证系统稳定性。
该方法常用于文档管理模块(如知识库系统的 “编辑文档” 功能),支持对已有文档的内容、分类等信息进行修改,是文档全生命周期管理的核心接口之一。
步骤3:性能优化
/**
* 向量检索性能优化
*/
public class VectorSearchOptimizer {
/**
* 使用连接池
*/
private static final HikariDataSource dataSource = initPool();
private static HikariDataSource initPool() {
HikariConfig config = new HikariConfig();
config.setMaximumPoolSize(20);
config.setMinimumIdle(5);
config.setConnectionTimeout(30000);
return new HikariDataSource(config);
}
/**
* 查询结果缓存
*/
@Cacheable(value = "vectorSearch", key = "#questionHash")
public List<KnowledgeDoc> cachedSearch(String questionHash, int topK) {
// 热门问题缓存,避免重复计算
return executeVectorSearch(questionHash, topK);
}
/**
* 异步批量检索
*/
public CompletableFuture<List<RAGResponse>> asyncBatchQuery(
List<String> questions) {
return CompletableFuture.supplyAsync(() -> {
return questions.parallelStream()
.map(q -> {
try {
return queryKnowledge(q, "default");
} catch (Exception e) {
log.error("查询失败: {}", q, e);
return null;
}
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
});
}
}
性能指标:
- ✅ 亿级向量数据,10毫秒内召回
- ✅ 支持10000+ QPS并发查询
- ✅ 召回准确率95%+(Top-5)
- ✅ 相比独立向量库,运维成本降低60%
五、oGPilot智能化交互平台
5.1 自然语言转SQL(Text2SQL)
oGPilot支持用自然语言查询数据库:
/**
* oGPilot智能查询服务
*/
public class IntelligentQueryService {
public QueryResult naturalLanguageQuery(String question) {
// 用户:最近一个月销售额超过100万的产品有哪些?
// oGPilot自动转换为SQL:
String generatedSQL = """
SELECT
product_id,
product_name,
SUM(sales_amount) as total_sales
FROM sales_records
WHERE
sale_date >= CURRENT_DATE - INTERVAL '1 month'
GROUP BY product_id, product_name
HAVING SUM(sales_amount) > 1000000
ORDER BY total_sales DESC;
""";
// 执行并返回结果
return executeQuery(generatedSQL);
}
}
5.2 智能诊断与调优
/**
* 智能性能诊断
*/
public class IntelligentDiagnostics {
public DiagnosisReport diagnosePerformance() {
// 用户:为什么今天查询这么慢?
// oGPilot自动分析:
// 1. 检测慢SQL
// 2. 分析执行计划
// 3. 识别缺失索引
// 4. 生成优化建议
DiagnosisReport report = new DiagnosisReport();
report.addFinding("缺少索引: documents(category, created_at)");
report.addSuggestion("CREATE INDEX idx_doc_cat_time ON documents(category, created_at)");
report.addExpectedGain("查询性能提升80%");
return report;
}
}
六、真实案例:金融行业应用实践
6.1 案例背景
某大型银行需要构建智能客服知识库系统,面临的挑战:
- 📊 数据规模:10TB+结构化数据 + 500万篇文档
- ⚡ 性能要求:查询响应 < 100ms,支持10000+ QPS
- 🔒 安全要求:金融级安全、审计、权限控制
6.2 技术方案
采用openGauss一体化架构:
┌─────────────────────────────────────────────┐
│ 智能客服RAG应用架构 │
└─────────────────────────────────────────────┘
┌──────────────┐
│ 用户咨询 │
└──────┬───────┘
│
┌──────▼───────────────────────────────┐
│ 前端应用 (React + WebSocket) │
└──────┬───────────────────────────────┘
│
┌──────▼───────────────────────────────┐
│ 业务服务层 (Spring Boot) │
│ - RAG检索服务 │
│ - LLM调用服务 │
│ - 会话管理 │
└──────┬───────────────────────────────┘
│
┌──────▼───────────────────────────────┐
│ openGauss 数据库 │
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │用户数据│ │向量库 │ │会话 │ │
│ │ │ │(DataVec)│ │上下文 │ │
│ └────────┘ └────────┘ └────────┘ │
│ │
│ - AI4DB自动调优 │
│ - 全密态数据加密 │
│ - 行级权限控制 │
└──────────────────────────────────────┘
6.3 核心代码实现
/**
* 银行智能客服RAG服务
*/
@Service
public class BankingCustomerServiceRAG {
/**
* 客户咨询处理
*/
public CustomerServiceResponse handleCustomerQuery(
String customerId,
String question) throws Exception {
// 1. 加载客户上下文(权限控制)
CustomerContext context = loadCustomerContext(customerId);
// 2. 问题分类(产品咨询/账户查询/投诉建议等)
QuestionCategory category = classifyQuestion(question);
// 3. 向量检索相关知识
List<KnowledgeDoc> relevantDocs = vectorSearch(
question,
category,
context.getAccessLevel()
);
// 4. 混合检索:向量 + 结构化查询
if (category == QuestionCategory.ACCOUNT_QUERY) {
// 查询客户账户信息
AccountInfo accountInfo = queryAccountInfo(customerId);
relevantDocs.add(convertToDoc(accountInfo));
}
// 5. 构建Prompt并调用LLM
String prompt = buildPrompt(question, relevantDocs, context);
String answer = callSecureLLM(prompt);
// 6. 记录会话(审计要求)
saveConversationLog(customerId, question, answer);
// 7. 返回响应
CustomerServiceResponse response = new CustomerServiceResponse();
response.setAnswer(answer);
response.setConfidence(calculateConfidence(relevantDocs));
response.setSources(extractSources(relevantDocs));
return response;
}
/**
* 混合检索:向量 + SQL
*/
private List<KnowledgeDoc> vectorSearch(
String question,
QuestionCategory category,
int accessLevel) throws SQLException {
float[] questionVector = generateEmbedding(question);
String vectorStr = Arrays.toString(questionVector).replace(" ", "");
String sql = """
WITH vector_search AS (
-- 向量检索
SELECT
id, title, content,
1 - (embedding <=> ?::vector) AS similarity
FROM knowledge_base
WHERE
category = ?
AND access_level <= ? -- 权限控制
ORDER BY embedding <=> ?::vector
LIMIT 10
),
keyword_search AS (
-- 关键词检索
SELECT
id, title, content,
ts_rank(content_tsvector, to_tsquery('chinese', ?)) AS rank
FROM knowledge_base
WHERE
content_tsvector @@ to_tsquery('chinese', ?)
AND category = ?
AND access_level <= ?
ORDER BY rank DESC
LIMIT 5
)
-- 混合结果(去重)
SELECT DISTINCT * FROM (
SELECT * FROM vector_search
UNION
SELECT id, title, content, rank as similarity FROM keyword_search
) AS combined
ORDER BY similarity DESC
LIMIT 5;
""";
try (Connection conn = DatabaseConfig.getConnection();
PreparedStatement stmt = conn.prepareStatement(sql)) {
// 设置参数
stmt.setString(1, vectorStr);
stmt.setString(2, category.name());
stmt.setInt(3, accessLevel);
stmt.setString(4, vectorStr);
stmt.setString(5, extractKeywords(question));
stmt.setString(6, extractKeywords(question));
stmt.setString(7, category.name());
stmt.setInt(8, accessLevel);
ResultSet rs = stmt.executeQuery();
List<KnowledgeDoc> results = new ArrayList<>();
while (rs.next()) {
KnowledgeDoc doc = new KnowledgeDoc();
doc.setId(rs.getLong("id"));
doc.setTitle(rs.getString("title"));
doc.setContent(rs.getString("content"));
doc.setSimilarity(rs.getDouble("similarity"));
results.add(doc);
}
return results;
}
}
}
6.4 实施效果
| 指标维度 | 实施前 | 实施后 | 提升 |
|---|---|---|---|
| 查询响应时间 | 800ms | 50ms | 94% ↓ |
| 系统可用性 | 99.9% | 99.99% | 稳定性提升 |
| 运维成本 | 高(多系统) | 低(一体化) | 60% ↓ |
| 客户满意度 | 78% | 92% | 18% ↑ |
| 问题解决率 | 65% | 85% | 31% ↑ |
| 硬件成本 | 基准 | -30% | 降低30% |
关键成果:
- ✅ 一套openGauss替代了原有的MySQL + Milvus + Redis架构
- ✅ 数据一致性问题彻底解决,无需数据同步
- ✅ 金融级安全特性满足监管要求
七、最佳实践与部署建议
7.1 硬件配置推荐
#小型部署(< 100万文档)
CPU: 8核+ (建议鲲鹏920)
内存: 32GB+
存储: 500GB SSD
网络: 千兆网卡
#中型部署(100万-1000万文档)
CPU: 16核+ (鲲鹏920或更高)
内存: 64GB+
存储: 2TB NVMe SSD
网络: 万兆网卡
#大型部署(> 1000万文档)
CPU: 32核+ (鲲鹏920 2路)
内存: 128GB+
存储: 4TB+ NVMe SSD RAID
网络: 万兆网卡 + 链路聚合
7.2 openGauss参数优化
-- 向量检索优化参数
ALTER SYSTEM SET shared_buffers = '16GB'; -- 25%内存
ALTER SYSTEM SET effective_cache_size = '48GB'; -- 75%内存
ALTER SYSTEM SET maintenance_work_mem = '2GB'; -- 索引构建
ALTER SYSTEM SET work_mem = '512MB'; -- 查询内存
ALTER SYSTEM SET max_parallel_workers = 16; -- 并行查询
ALTER SYSTEM SET max_parallel_workers_per_gather = 4;
-- 向量索引参数
ALTER SYSTEM SET hnsw.ef_search = 100; -- 检索深度
7.3 Java应用优化
这段代码的核心是通过 HikariCP 配置并初始化 openGauss 数据库连接池,流程可概括为:
读取配置文件中的数据库连接信息(地址、端口、账号等);
配置连接池的核心参数(最大连接数、超时时间等);
设置性能优化参数(预处理语句缓存等);
创建数据源实例,供系统获取数据库连接。
HikariCP 是目前性能最优的 JDBC 连接池之一,通过合理配置连接池参数,能有效减少数据库连接的创建 / 销毁开销,提升系统的并发能力和稳定性。该方法通常在系统启动时执行(如静态代码块中),确保数据源在系统使用前完成初始化。
7.4 监控与运维
/**
* 数据库健康监控(基于实际项目的DatabaseService扩展)
*/
@Slf4j
public class DatabaseHealthMonitor {
private final DatabaseService databaseService;
public DatabaseHealthMonitor() {
this.databaseService = new DatabaseService();
}
/**
* 定期健康检查
*/
public void monitorHealth() {
try {
// 1. 测试连接
boolean connected = databaseService.testConnection();
if (!connected) {
log.error("数据库连接失败!");
return;
}
// 2. 获取数据库统计信息
Map<String, Object> stats = databaseService.getDatabaseStats();
log.info("数据库统计 - {}", stats);
// 3. 检测慢查询
String slowQuerySql = """
SELECT
query,
calls,
total_time,
mean_time,
max_time
FROM pg_stat_statements
WHERE mean_time > 1000 -- 平均耗时>1秒
ORDER BY mean_time DESC
LIMIT 10;
""";
List<Map<String, Object>> slowQueries = databaseService.executeQuery(slowQuerySql);
if (!slowQueries.isEmpty()) {
log.warn("检测到 {} 个慢查询", slowQueries.size());
slowQueries.forEach(q ->
log.warn("慢查询: {}, 平均耗时: {}ms",
q.get("query"), q.get("mean_time"))
);
}
// 4. 监控文档表大小
String tableSizeSql = """
SELECT
pg_size_pretty(pg_total_relation_size('documents')) as table_size,
pg_size_pretty(pg_indexes_size('documents')) as index_size
""";
List<Map<String, Object>> sizeInfo = databaseService.executeQuery(tableSizeSql);
if (!sizeInfo.isEmpty()) {
log.info("文档表大小: {}", sizeInfo.get(0));
}
} catch (Exception e) {
log.error("健康检查失败", e);
}
}
}
八、总结与展望
8.1 核心价值总结
openGauss通过AI4DB、DB4AI、DataVec向量数据库三大核心能力,为企业提供了:
技术价值:
- 🎯 一体化架构:一套数据库解决OLTP + 向量检索 + AI训练
- 🎯 智能化运维:AI自动调优,运维成本降低50%+
- 🎯 原生AI能力:SQL直接训练模型,开发效率提升10倍
- 🎯 卓越性能:亿级向量10ms召回,鲲鹏优化性能提升40%
商业价值:
- 💰 架构简化,运维成本降低60%
- 💰 硬件成本降低30%(一体化 vs 多系统)
- 💰 开发效率提升10倍(SQL vs Python)
8.2 应用场景展望
openGauss的应用场景正在快速拓展:
已落地场景:
- ✅ 企业知识库RAG系统
- ✅ 智能客服与问答
- ✅ 用户行为预测
- ✅ 金融风控模型
- ✅ 文档相似度检测
未来方向:
- 🔮 多模态向量(图像+文本+音频)
- 🔮 GPU加速向量检索
- 🔮 联邦学习支持
- 🔮 自动化提示词工程
- 🔮 端到端RAG优化
8.3 技术演进趋势
当前(6.0) 未来(7.0+)
┌──────────────┐ ┌──────────────┐
│ AI4DB │ → │ 全自动驾驶 │
│ 智能调优 │ │ Level 5 │
└──────────────┘ └──────────────┘
┌──────────────┐ ┌──────────────┐
│ DB4AI │ → │ 深度学习 │
│ 传统ML算法 │ │ GPU加速 │
└──────────────┘ └──────────────┘
┌──────────────┐ ┌──────────────┐
│ DataVec │ → │ 多模态向量 │
│ 文本向量 │ │ 图文音一体 │
└──────────────┘ └──────────────┘
九、快速开始
9.1 环境准备
#1. 安装openGauss
wget https://openGauss.org/download/openGauss-6.0.0.tar.gz
tar -xf openGauss-6.0.0.tar.gz
./install.sh
#2. 创建数据库
gs_initdb -D /data/openGauss
#3. 启动服务
gs_ctl start -D /data/openGauss
9.2 项目结构:
openGauss/
├── src/main/java/com/openGauss/demo/
│ ├── Application.java # 主程序
│ ├── config/DatabaseConfig.java # 连接池配置
│ ├── dao/ # 数据访问层
│ │ ├── DocumentDao.java
│ │ └── UserDao.java
│ ├── entity/ # 实体类
│ │ ├── Document.java
│ │ └── User.java
│ ├── service/ # 业务服务层
│ │ ├── DatabaseService.java
│ │ ├── DocumentService.java
│ │ └── UserService.java
│ └── util/JdbcUtil.java # 工具类
└── src/main/resources/
├── application.properties # 数据库配置
├── schema.sql # 表结构
└── sample_data.sql # 示例数据
9.3 实际项目使用示例
基于Java项目,以下是完整的使用流程:
场景1:文档管理(基础CRUD)
package com.openGauss.demo;
import com.openGauss.demo.entity.Document;
import com.openGauss.demo.service.DocumentService;
public class DocumentExample {
public static void main(String[] args) {
DocumentService service = new DocumentService();
// 1. 创建文档
Long docId = service.createDocument(
"openGauss向量数据库介绍",
"openGauss 3.1版本开始支持向量数据类型...",
"技术文档",
"[\"向量数据库\", \"AI\"]"
);
System.out.println("文档创建成功,ID: " + docId);
// 2. 搜索文档
List<Document> results = service.searchDocuments("向量数据库");
results.forEach(doc ->
System.out.println(doc.getTitle() + " - " + doc.getCategory())
);
// 3. 按分类查询
List<Document> techDocs = service.getDocumentsByCategory("技术文档");
System.out.println("技术文档数量: " + techDocs.size());
// 4. 获取文档总数
long count = service.getDocumentCount();
System.out.println("总文档数: " + count);
}
}
场景2:数据库信息查询
package com.openGauss.demo;
import com.openGauss.demo.service.DatabaseService;
import java.util.List;
import java.util.Map;
public class DatabaseInfoExample {
public static void main(String[] args) {
DatabaseService service = new DatabaseService();
// 1. 测试连接
boolean connected = service.testConnection();
System.out.println("数据库连接: " + (connected ? "成功" : "失败"));
// 2. 获取数据库版本
String version = service.getDatabaseVersion();
System.out.println("数据库版本: " + version);
// 3. 获取统计信息
Map<String, Object> stats = service.getDatabaseStats();
System.out.println("数据库大小: " + stats.get("database_size"));
System.out.println("表数量: " + stats.get("table_count"));
System.out.println("连接数: " + stats.get("connection_count"));
// 4. 执行自定义查询
String sql = "SELECT category, COUNT(*) as count FROM documents GROUP BY category";
List<Map<String, Object>> results = service.executeQuery(sql);
System.out.println("\n文档分类统计:");
results.forEach(row ->
System.out.println(row.get("category") + ": " + row.get("count"))
);
}
}
场景3:交互式命令行应用
直接运行主程序,体验完整功能:
运行主程序
mvn exec:java -Dexec.mainClass="com.openGauss.demo.Application"
进入交互式菜单:
========================================
openGauss AI Demo - 主菜单
========================================
- 数据库信息管理
- 用户管理
- 文档管理
- AI功能演示
- 退出
========================================
请选择功能 (0-4):
选择功能后进行操作,例如:
- 选择3(文档管理)→ 3(搜索文档)→ 输入"openGauss"
- 系统会自动检索包含关键词的所有文档
官方资源
- openGauss官网:
https://opengauss.org/zh/ - 用户案例:
https://opengauss.org/zh/user-practice/
让openGauss成为您AI应用的坚实底座!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)