
openGauss 实战指南
本文分享openGauss数据库从部署到运维的实战经验。首先介绍环境准备要点和可视化/脚本两种部署方式,着重强调系统配置检查的重要性。其次详细讲解数据迁移流程,包括工具选择、增量同步策略和常见问题处理。在运维部分,阐述监控告警设置、备份恢复方案和集群维护技巧。开发适配方面,说明openGauss的高兼容特性及SQL语法差异处理。最后提供常见问题排查思路,并总结openGauss开源免费、高效稳定的
作为一名数据库管理员(DBA),我曾在金融项目中主导过从 Oracle 向 openGauss 的迁移,也为中小企业搭建过基于 openGauss 的核心业务数据库。相较于传统商业数据库,openGauss 的开源特性与企业级能力,让使用者在 “成本控制” 与 “业务支撑” 间找到了极佳平衡。本文将从实际操作场景出发,分享 openGauss 的部署、运维、开发全流程经验,帮你避开坑点、提升效率。

一、部署安装(新手请注意!!!)
对于使用者而言,数据库的 “第一印象” 往往来自部署过程。openGauss 的部署工具已相当成熟,无论是单机还是分布式集群,都能通过可视化工具或脚本快速完成。
1. 环境准备
在部署前,需先确认硬件与系统兼容性 —— 这是新手最易踩坑的环节。根据俺的经验,重点关注以下几点:
- 硬件要求:单机部署建议至少 4 核 CPU、16GB 内存(若用于测试,2 核 8GB 可临时使用,但生产环境务必满足官方最低标准);分布式集群每个节点需独立磁盘,避免 IO 争抢。
- 系统配置:推荐使用 CentOS 7.6 或 EulerOS 2.0,需提前关闭 SELinux 和防火墙(或开放 5432、26000 等默认端口),并调整内核参数(如增大文件描述符限制、关闭 swap 分区)。
小贴士:可直接使用 openGauss 官方提供的 “环境检查脚本”(gs_checkos),一键检测并修复系统配置问题,避免手动修改参数出错。
2. 部署方式
l部署1(推荐新手):通过 openGauss工具,上传节点 IP、用户名、密码等信息,可视化配置集群角色(主库、备库、协调器),点击 “部署” 后工具会自动完成软件下载、安装、初始化,全程无需手动输入命令,30 分钟内可完成 3 节点集群部署。
l部署2(适合自动化):编写 XML 配置文件,定义节点信息与部署参数,执行 “gs_install” 命令一键部署。这种方式适合批量部署或集成到自动化运维平台(如 Ansible),我曾用此方式在 1 小时内完成 10 节点分布式集群部署。
<!-- 配置xml -->
<?xml version="1.0" encoding="UTF-8"?>
<ROOT>
<!-- openGauss整体信息 -->
<CLUSTER>
<!-- 数据库名称 -->
<PARAM name="clusterName" value="GaussDB" />
<!-- 数据库节点名称(hostname) -->
<PARAM name="nodeNames" value="node1" />
<!-- 节点IP,与nodeNames一一对应 -->
<PARAM name="backIp1s" value="***.***.***.***87"/>
<!-- 数据库安装目录-->
<PARAM name="gaussdbAppPath" value="/opt/huawei/install/app" />
<!-- 日志目录-->
<PARAM name="gaussdbLogPath" value="/var/log/omm" />
<!-- 临时文件目录-->
<PARAM name="tmpMppdbPath" value="/opt/huawei/tmp"/>
<!--数据库工具目录-->
<PARAM name="gaussdbToolPath" value="/opt/huawei/install/om" />
<!--数据库core文件目录-->
<PARAM name="corePath" value="/opt/huawei/corefile"/>
<!-- openGauss类型,此处示例为单机类型,“single-inst”表示单机一主多备部署形态-->
<PARAM name="clusterType" value="single-inst"/>
</CLUSTER>
<!-- 每台服务器上的节点部署信息 -->
<DEVICELIST>
<!-- node1上的节点部署信息 -->
<DEVICE sn="1000001">
<!-- node1的hostname -->
<PARAM name="name" value="ecs-kc1-large-2-linux-20210605213652"/>
<!-- node1所在的AZ及AZ优先级 -->
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="***.***.***.***87"/>
<PARAM name="sshIp1" value="***.***.***.***87"/>
<!--dbnode-->
<PARAM name="dataNum" value="1"/>
<!--DBnode端口号-->
<PARAM name="dataPortBase" value="26000"/>
<!--DBnode主节点上数据目录,及备机数据目录-->
<PARAM name="dataNode1" value="node1"/>
<!--DBnode节点上设定同步模式的节点数-->
<PARAM name="dataNode1_syncNum" value="0"/>
</DEVICE>
</DEVICELIST>
</ROOT>
3. 部署后验证
部署完成后,无需复杂操作,通过以下命令即可确认数据库状态:
- gs_om -t status --detail:查看集群节点状态,确保所有节点 “Normal”;
- gsql -d postgres -U omm -p 5432:登录数据库(默认用户为 omm,密码在部署时设置);
- select version();:在数据库内执行,确认 openGauss 版本与预期一致。
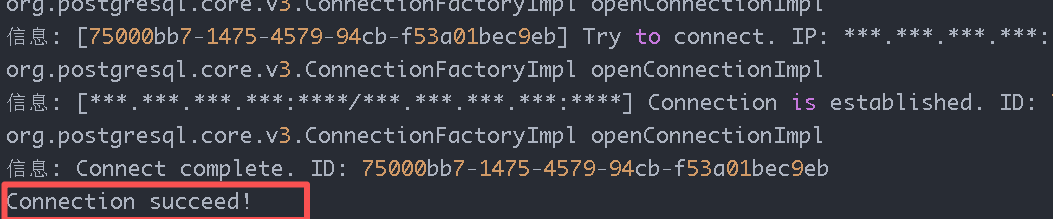
显示Connection succeed即为成功
二、数据迁移
企业使用 openGauss 时,最核心的需求之一是 “将现有数据迁移过来”。我曾处理过日均 1000 万条交易数据的 Oracle 迁移项目,也做过中小企业 MySQL 的轻量迁移,总结出一套低风险迁移流程。

1. 迁移工具选择
openGauss 提供了针对性的迁移工具,避免手动编写脚本的繁琐与风险:
- MySQL 迁移:优先使用 “DMKit 工具”,支持全量数据迁移(表结构 + 数据)与增量数据同步(通过 binlog)。只需在配置文件中填写源库(MySQL)与目标库(openGauss)的连接信息,执行dmkit_mysql2openGauss命令即可
安装包 https://github.com/baidu/unit-dmkit
- 小量数据迁移:若仅需迁移几张表,可直接使用gsql工具的\copy命令,或通过 Data Studio 图形化工具导出 / 导入 CSV 文件,操作类似 Excel,非技术人员也能快速上手。

2. 迁移流程
数据迁移最怕 “业务中断” 与 “数据不一致”,建议按以下流程操作:
- 测试环境验证:先在测试环境复刻生产数据(脱敏处理),完成迁移后执行 “数据一致性校验”(使用gs_checkdata工具对比源库与目标库的表行数、校验和)
- 增量同步准备:生产环境迁移前,先启动增量同步工具(如 DMKit 的 binlog 同步、OGG 的实时同步),确保迁移期间新增的数据能实时同步到 openGauss;
- 切换窗口执行:选择业务低峰期,停止源库写入,等待增量数据同步完成后,将应用连接地址切换为 openGauss,切换后观察 1 小时,无异常则迁移完成。
3. 常见迁移问题
- 字符集不兼容:若源库(如 MySQL)使用 GBK 字符集,而 openGauss 默认 UTF-8,会导致中文乱码。
解决方案:迁移前将 openGauss 数据库字符集改为 GBK(创建数据库时指定WITH ENCODING 'GBK');
- 索引失效:迁移后部分查询性能下降,多因索引未同步或不兼容。解决方案:迁移后执行ANALYZE命令更新统计信息,同时通过EXPLAIN查看执行计划,确认索引是否被正确使用。
三、日常运维
openGauss 的运维设计非常 “人性化”,通过工具与自动化能力,大幅减少 DBA 的重复操作。

1. 监控告警
- 基础监控:部署时默认集成 Prometheus+Grafana 监控面板,可实时查看 CPU 使用率、内存占用、磁盘 IO、SQL 执行耗时等指标,我曾通过 “SQL 执行耗时突增” 告警,及时发现并优化了一条慢查询(从 5 秒优化至 0.1 秒);
- 自定义告警:通过 Grafana 设置阈值告警(如 CPU 使用率超过 80%、连接数超过 1 万),支持邮件、短信、企业微信通知,避免 DBA24 小时盯屏;
- 日志分析:使用gs_logfilter工具快速筛选关键日志(如错误日志、慢查询日志),例如执行gs_logfilter -t error -s 2025-10-30 00:00:00 -e 2025-10-30 23:59:59,可快速定位当天的错误信息。
2. 备份恢复
数据安全是运维核心,openGauss 的备份工具支持多种场景,操作简单:
- 全量备份:执行gs_basebackup -D /backup/full_20251030 -F p -X stream,将全量数据备份到指定目录,建议每天凌晨自动执行(通过 crontab 定时任务);
- 增量备份:基于全量备份,执行gs_probackup backup -b incremental -D /backup/incremental_20251030 -P,仅备份新增数据,节省存储空间;
- 时间点恢复(PITR):若发生误删除数据,可通过gs_probackup restore命令恢复到指定时间点(如--time '2025-10-30 14:30:00')
3. 集群维护
- 主备切换:当主库故障时,无需手动操作,openGauss 会自动将备库切换为主库(秒级完成);若需手动切换(如主库硬件维护),执行gs_om -t switchover -D /opt/openGauss/data即可,切换期间业务无感知;
- 版本升级:从低版本升级到高版本时,使用gs_upgrade工具,支持 “滚动升级”(先升级备库,再切换主库,最后升级原主库),避免集群整体 downtime。我曾将 openGauss 4.0 升级到 5.0,全程无业务中断。
四、开发适配
对于开发人员而言,openGauss 的 “高兼容性” 是一大优势,无需大规模修改现有代码即可适配。
1. 应用连接
openGauss 支持 JDBC、ODBC、Python、Java 等主流开发语言的连接方式,与 MySQL/Oracle 差异极小:
- Java 连接:使用 PostgreSQL 的 JDBC 驱动(openGauss 兼容 PostgreSQL 驱动),连接 URL 格式为jdbc:postgresql://``192.168.1.100:5432/mydb,仅需修改数据库地址与端口,无需修改代码;
- Python 连接:使用psycopg2库,连接代码与 PostgreSQL 完全一致,例如:
import psycopg2
conn = psycopg2.connect(database="mydb", user="omm", password="123456", host="192.168.1.100", port="5432")连接池配置:支持 Druid、HikariCP 等主流连接池,配置参数与 MySQL/Oracle 类似,我曾将一个使用 Druid 连接池的 Java 应用从 MySQL 迁移到 openGauss,仅修改了连接 URL 与驱动类名,10 分钟完成适配。

2. SQL 语法95% 以上兼容,少数场景需调整
openGauss 高度兼容 PostgreSQL 语法,同时支持大部分 MySQL/Oracle 常用 SQL,开发人员几乎无需学习新语法:
- 兼容场景:SELECT/INSERT/UPDATE/DELETE等基础 SQL、JOIN关联查询、GROUP BY聚合计算等,完全无需修改;
- 需调整场景:少数 Oracle 特有语法(如CONNECT BY递归查询需改为WITH RECURSIVE,NVL函数需改为COALESCE),但可通过 openGauss 的 “兼容模式”(设置oracle_compatibility = on)减少修改量。

五、问题排查
在使用 openGauss 过程中,难免遇到问题,掌握以下排查思路,可快速定位并解决。
|
问题类型 |
常见现象 |
排查步骤与解决方案 |
|
登录失败 |
gsql: FATAL: password authentication failed for user "omm" |
1. 确认密码是否正确(可通过gs_om -t resetpw重置密码);2. 检查 pg_hba.conf 文件是否允许当前 IP 访问;3. 确认数据库服务是否正常(gs_om -t status)。 |
|
慢查询 |
SQL 执行时间超过 5 秒 |
1. 执行EXPLAIN ANALYZE查看执行计划,确认是否全表扫描;2. 使用gs_index_advise获取索引推荐;3. 检查是否存在锁等待(SELECT * FROM pg_locks WHERE granted = false;)。 |
|
节点故障 |
集群状态显示 “Abnormal” |
1. 查看节点日志(/var/log/openGauss/),定位故障原因(如磁盘满、内存不足);2. 若磁盘满,清理日志或无用数据;3. 重启节点(gs_om -t start -h 192.168.1.101)。 |
|
数据不一致 |
主备库数据行数不同 |
1. 执行gs_checkdata -s primary -t standby校验数据一致性;2. 若不一致,重建备库(gs_om -t build -h 192.168.1.102);3. 检查网络是否稳定(备库需能正常访问主库)。 |
六、总结
六字真言
- 省心:自动化部署、智能监控、故障自动恢复,大幅减少运维工作量;
- 省钱:开源免费,无需支付商业数据库的高昂授权费,同时支持 ARM 架构服务器(硬件成本更低);
- 高效:向量化执行引擎、AI 索引推荐、分布式架构,满足高并发与海量数据需求,同时兼容现有应用,迁移与开发成本低。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)