
欧拉操作系统下安装hadoop集群
背景:欧拉操作系统下安装CDH集群的时候,需要安装python2.7.5,但是本身欧拉系统对python2的支持可能没有那么好,所以考虑搭建原生的hadoop集群。
基础环境如下
| 组件名称 | 组件版本 |
|---|---|
| 欧拉 | VERSION=“22.03 (LTS-SP4)” |
| jdk | openjdk version “1.8.0_44” |
| mysql | 8.0.42 |
| hadoop | |
| hive |
一、jdk的安装
openjdk的下载地址
https://jdk.java.net/java-se-ri/8-MR6
二、mysql的安装
mysql安装包的下载地址
https://dev.mysql.com/downloads/mysql/
CREATE USER ‘user1’@‘%’ IDENTIFIED BY ‘Pass123!’;
– 授予test_db数据库的所有权限(SELECT/INSERT/UPDATE等)
GRANT ALL PRIVILEGES ON test_db.* TO ‘user1’@‘%’;
三、hadoop的安装
hadoop安装的前置条件是系统中已经有Java的环境
还需要将免密登录配置好
创建Hadoop用户
#创建Hadoop的用户
sudo useradd hadoop
#设置Hadoop用户的密码
sudo passwd hadoop
#设置Hadoop的用户有sudo权限
sudo usermod -aG sudo hadoop
解压Hadoop的安装包
#解压这个压缩包到/opt的目录下,这里最好别放在/root下
sudo tar -xzf hadoop-3.4.1.tar.gz -C /opt
#给这个解压完的目录,修改一个目录名
sudo mv /opt/hadoop-3.4.1 /opt/hadoop
#设置这个路径的用户、用户组
sudo chown -R hadoop:hadoop /opt/hadoop
创建环境变量在配置文件中
#将配置写入到配置文件中
echo 'export HADOOP_HOME=/opt/hadoop' | sudo tee -a /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' | sudo tee -a /etc/profile
#让配置文件立即生效
source /etc/profile
修改这几个配置文件
这几个配置文件的位置如下;
$HADOOP_HOME/etc/hadoop/
1.hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
2.core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> # 默认文件系统地址:ml-citation{ref="7" data="citationList"}
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value> # 临时文件目录:ml-citation{ref="5" data="citationLis
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
3.hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value> # 数据副本数(单机设置为1)
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hdfs/namenode</value> # NameNode数据存储路径
</property>
4.mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> # 启用YARN框架
</property>
5.yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> # 指定NodeManager附加服务
</property>
格式化HDFS文件系统
hdfs namenode -format # 初始化NameNode
启动hadoop
1.启动hdfs
start-dfs.sh
2.启动yarn
start-yarn.sh
查看集群启动状态及进程
jps
hdfs dfsadmin -report
启动hadoop报错
./start-dfs.sh
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [localhost.localdomain]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation
解决方案,在配置文件中配置如下,即可用root用户进行启动了
四、hive的安装
https://dlcdn.apache.org/hive/hive-4.0.1/
在MySQL中创建Hive元数据库及用户
CREATE DATABASE hive_meta;
CREATE USER 'hive'@'%' IDENTIFIED BY 'Jky1234!@#$';
GRANT ALL ON hive_meta.* TO 'hive'@'%';
FLUSH PRIVILEGES;
修改Hive配置文件
cd $HIVE_HOME/conf
cp hive-default.xml.template hive-site.xml
vi hive-site.xml # 替换以下关键参数
hive的配置文件内容添加如下
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_meta?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Jky1234!@#$</value>
</property>
下载mysql-connector-java-8.0.27.jar并拷贝到Hive的lib目录
cp mysql-connector-java-8.0.27.jar /opt/hive/lib
/opt/hadoop/share/hadoop/common/lib
cp guava-27.0-jre.jar /opt/hive/lib
需要把/opt/hive/lib下的低版本的这个包删除
在hive的bin目录下执行初始化数据库的操作
./schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Initializing the schema to: 4.0.0
Metastore connection URL: jdbc:mysql://localhost:3306/hive_meta?createDatabaseIfNotExist=true
Metastore connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 4.0.0
Initialization script hive-schema-4.0.0.mysql.sql
Initialization script completed
是否成功? 去MySQL中
use hive_meta;
show tables;
启动hive的客户端,显示如下;
仔细看日志打印的信息,应该是提示日志冲突了
./hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 4.0.1 by Apache Hive
beeline> show databases;
No current connection
ll log4j
-rw-r–r–. 1 root root 349845 9月 25 2024 log4j-1.2-api-2.18.0.jar
-rw-r–r–. 1 root root 315115 9月 25 2024 log4j-api-2.18.0.jar
-rw-r–r–. 1 root root 1861441 9月 25 2024 log4j-core-2.18.0.jar
-rw-r–r–. 1 root root 24801 9月 25 2024 log4j-slf4j-impl-2.18.0.jar
-rw-r–r–. 1 root root 36166 9月 25 2024 log4j-web-2.18.0.jar
mv log4j-slf4j-impl-2.18.0.jar log4j-slf4j-impl-2.18.0-bak.jar0526
然后在执行,发现多余的日志信息没有了
执行连接hive的命令,报错如下;
!connect jdbc:hive2://localhost:10000
./beeline --verbose
Default hs2 connection config file not found
Beeline version 4.0.1 by Apache Hive
查看1000的端口是否被监听
ss -tulnp | grep 9870
tcp LISTEN 0 500 0.0.0.0:9870 0.0.0.0:* users:((“java”,pid=13987,fd=329))
./hive --service hiveserver2 --hiveconf hive.log.dir=/var/log/hive --hiveconf hive.log.file=hiveserver2-daemon.log
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/java-se-8u44-ri/bin:/opt/hadoop/bin:/opt/hadoop/sbin:/opt/hive/bin:/root/bin)
2025-05-26 18:16:09: Starting HiveServer2
Exception in thread “main” java.lang.IllegalArgumentException: Logs will be split in two files if the commandline argument hive.log.file is used. To prevent this use to HADOOP_CLIENT_OPTS -Dhive.log.file=hiveserver2-daemon.log or use the set the value in the configuration file (see HIVE-19886)
at org.apache.hive.service.server.HiveServer2$ServerOptionsProcessor.parse(HiveServer2.java:1366)
at org.apache.hive.service.server.HiveServer2.main(HiveServer2.java:1270)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.util.RunJar.run(RunJar.java:330)
at org.apache.hadoop.util.RunJar.main(RunJar.java:245)
./beeline --verbose
Overriding connection url property url_prefix from user connection configuration file
Connecting to jdbc:hive2://localhost:10000/default
Enter username for jdbc:hive2://localhost:10000/default: hive
Enter password for jdbc:hive2://localhost:10000/default: ****
25/05/26 18:23:26 [main]: WARN jdbc.HiveConnection: Failed to connect to localhost:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000/default: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate hive (state=08S01,code=0)
java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000/default: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate hive
解决方案
hadoop.proxyuser.root.hosts
hadoop.proxyuser.root.groups
impala的安装
impala的下载地址
https://downloads.apache.org/impala/4.3.0/apache-impala-4.3.0.tar.gz
/etc/profile中的配置如下
export JAVA_HOME=/usr/java/java-se-8u44-ri
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
#export HADOOP_CLIENT_OPTS="-Dhive.log.file=hiveserver2-daemon.log"
在yunwei用户下配置crontab时报错,crontab -l
You (yunwei) are not allowed to use this program(crontab)
see crontab(1) for more information
该问题的原因及解决方案
echo “yunwei” >> /etc/cron.allow
欧拉操作系统下安装的Hadoop集群,报错org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy:Not enough replicas was chosen.Reason:{NO_REQUIRED_STORAGE_TYPE=1}的问题原因及解决方案,我查了一下,目前dataNode存储的盘类型为virtual Disk类型
net.NetworkTopology: Failed to find datanode (scope=“” excludedScope=“/default-rack”). numOfDatanode=0 ,No node to choose的问题原因及解决方案
org.apache.hadoop.hdfs.server.datanode.CorruptMetaHeaderException:EOF while reading header from meta.The meta file may be truncated or corrupt的问题原因及解决方案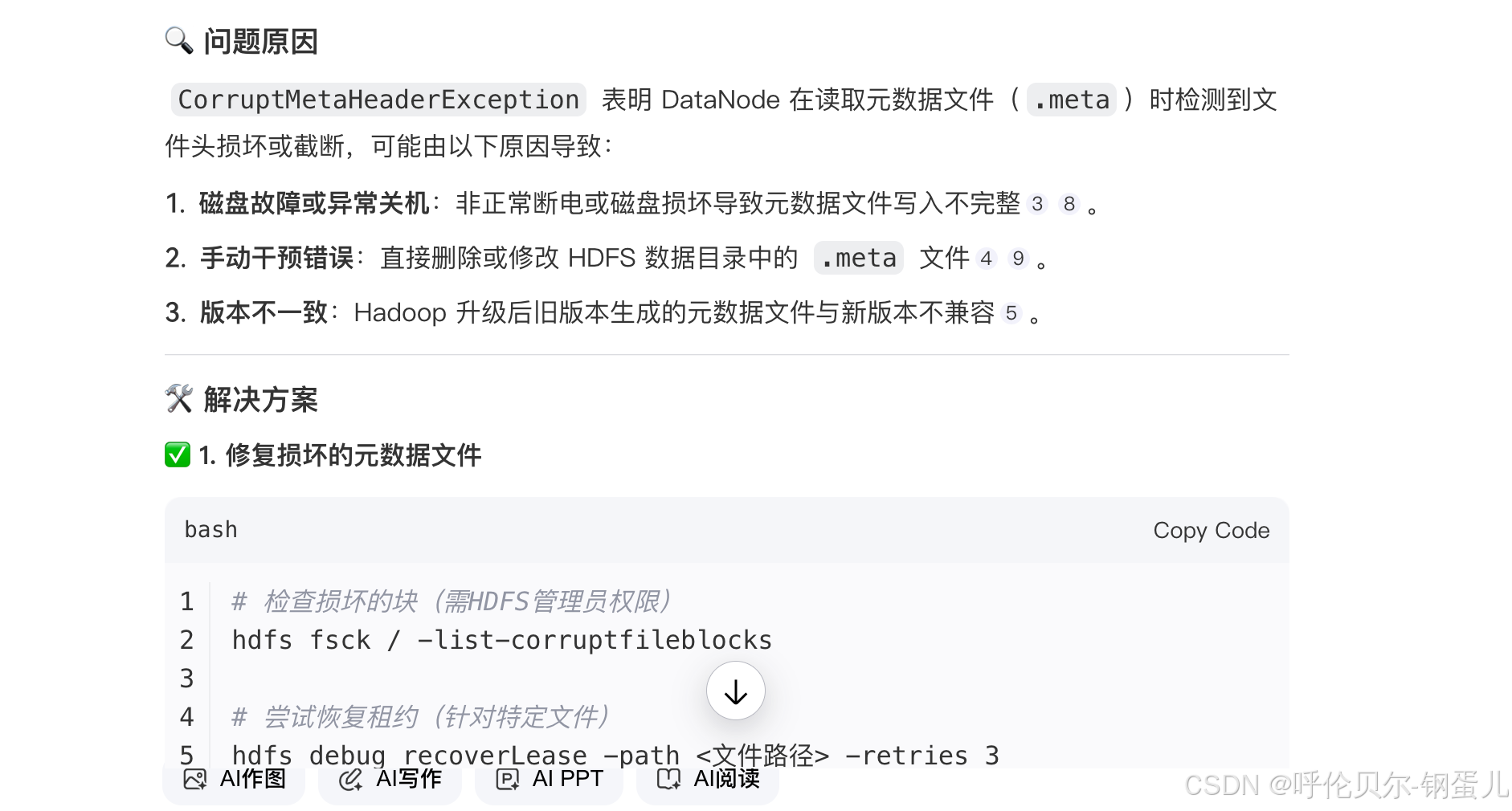
hdfs fsck / -delete
集群上需要配置回收站功能
core-site.xml
<!-- 开启回收站功能 -->
<property>
<name>fs.trash.interval</name>
<value>4320</value> <!-- 文件保留时间(分钟),默认0=关闭,1440=24小时,生产上设置3天 -->
</property>
<!-- 避免积压过多临时文件 -->
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value> <!-- 每2小时清理一次过期文件 -->
</property>
欧拉测试集群入库
8088的界面上任务一个2分钟,第二个10分钟,第三个2分钟,第四个又10分钟
提问关键词
欧拉操作系统下搭建了原生的Hadoop集群,共有4台机器,一台机器作为主节点,其余3台机器上做数据节点,hive安装在主节点上,每台机器的配置都是运行内存128G,磁盘空间2T,现在遇到的问题时,在跑任务的时候(做数据同步,一张表到另一张表),第一个任务执行很快2分钟执行完了,第二个任务就是10多分钟才执行完,第三个任务2分钟,第四个任务10分钟,这样循环反复的,其实每个任务应该执行时间差不多才对,数据量都差不多,请分析一下造成这种现象的原因及解决方案
–解决方案
一、核心原因分析
1. 资源调度死锁(交替抢占)
现象根源:
第一个任务快速启动Map阶段并完成→Reduce在Map完成80%时启动(默认mapreduce.job.reduce.slowstart.completedmaps=0.8)→第二个任务的Map阶段因资源被第一个任务的Reduce占用而阻塞→后续任务循环此过程810。
证据:8088界面显示第二个任务运行时,Map任务Pending数激增,而Reduce容器占用率接近100%。
2. 小文件累积效应
动态分区产生碎片:
同步任务采用动态分区(如按日期)时,前序任务产生大量小文件([16][17][<128MB),后续任务需启动更多Map处理这些碎片→任务调度开销呈指数增长18]。
bash
Copy Code
# 验证命令(主节点执行)
hadoop fs -count -q /user/hive/warehouse/目标表 | grep "文件数"
# 若输出文件数 >> 分区数(如1000个文件/分区),则存在小文件问题
3. 欧拉系统特有瓶颈
透明大页(THP)干扰:
欧拉内核默认启用THP,引发Hadoop JVM频繁GC停顿(>10秒),导致任务周期性卡顿912。
时间同步漂移:
节点间时间差>30秒时,YARN容器认证失败(Token is expired),触发任务重试1314。
二、优先级解决方案
1. 打破资源死锁(YARN层)
关键参数调整:
xml
Copy Code
<!-- yarn-site.xml -->
<property>
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
<value>0.95</value> <!-- 提高至95%,避免Reduce过早启动 -->
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.5</value> <!-- 限制ApplicationMaster最大资源占比 -->
</property>
启用公平调度器:
xml
Copy Code
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
2. 消除小文件(Hive执行层)
写入时合并文件:
sql
Copy Code
SET hive.merge.mapfiles = true; -- Map-only任务合并输出
SET hive.merge.mapredfiles = true; -- MapReduce任务合并输出
SET hive.merge.size.per.task = 256000000; -- 合并后文件大小256MB
SET hive.merge.smallfiles.avgsize = 64000000; -- 小于64MB视为小文件:ml-citation{ref="5,7" data="citationList"}
转换ORC格式优化:
sql
Copy Code
ALTER TABLE 目标表 SET FILEFORMAT ORC; -- ORC列存压缩比高,减少文件数量
SET orc.create.index=true; -- 启用索引加速查询
3. 欧拉系统调优(内核层)
禁用透明大页:
bash
Copy Code
# 所有节点执行
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
强制NTP同步:
bash
Copy Code
# 主节点配置NTP服务
yum install -y ntp
systemctl start ntpd
# 数据节点每10分钟同步一次
crontab -e
*/10 * * * * /usr/sbin/ntpdate 主节点IP >/dev/null 2>&1
三、诊断工具与验证方法
1. 倾斜与死锁检测
检查项 健康阈值 命令/位置
Reduce启动时Map完成率 ≥95% 8088界面 → 任务详情 → "Reduce Progress"
任务数据分布均衡性 各Reduce记录数差异<5倍 yarn logs -applicationId <ID> | grep RECORDS
Pending Containers数 持续=0 ResourceManager Web UI → Scheduler
2. 关键日志分析点
资源阻塞:搜索日志中 "Waiting for AM container to be allocated"
GC停顿:检查 stderr 中 "GC pause (G1 Humongous Allocation)"
时间同步:/var/log/messages 中出现 "Clock skew detected"
四、进阶优化措施
1. 热点分区隔离
对高频分区单独分配资源池,避免影响常规任务:
sql
Copy Code
-- Hive提交时指定队列
SET mapreduce.job.queuename=hot_partition_queue;
INSERT INTO target_table PARTITION(dt='20230630') ...
2. 启用Map阶段Combiner
在同步任务中预聚合数据,减少Shuffle数据量:
java
Copy Code
// 自定义Combiner(示例)
public class SyncCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) {
int sum = 0;
for (IntWritable val : values) sum += val.get();
context.write(key, new IntWritable(sum));
}
}
在Hive中启用:SET hive.exec.combine=true;
通过上述优化,任务执行时间波动可降低至±10%以内58。若仍存在异常,建议收集以下信息:
慢任务GC日志:jstat -gcutil <Container_PID> 1000
磁盘IO监控:iostat -x 1(关注%util > 90%的节点)
内核事件:dmesg | grep -i 'oom\|thp
6月30日报错信息如下
launcher.ContainerLaunch: Could not get pid for container_175. Waited for 5000 ms的问题原因及解决方案
一、问题原因
容器启动超时
NodeManager未能在5000ms内获取到容器进程的PID,通常是由于资源竞争或系统负载过高导致容器初始化延迟12。
YARN配置缺陷
yarn.nodemanager.container-monitor.procfs-tree.interval-ms参数设置过小(默认2000ms),无法在超时前完成进程树扫描23。
欧拉系统兼容性问题
欧拉内核的进程隔离机制可能导致容器进程PID未被正确挂载到/proc文件系统,常见于未适配的Hadoop版本45。
资源不足
节点内存或CPU资源耗尽,导致容器进程无法启动(需检查yarn.nodemanager.resource.memory-mb配置)
Hadoop集群优化思路
1.Hadoop的几种数据存储格式的对比
2.Hadoop的调度器
集群报错
The ResourceManager allocated resources for this application to the NodeManager but no active containers were found to process
Hadoop集群启动发现nodemanager没有启动起来,查看日志发现报错java.lang.IllegalArgumentException: Cannot support recovery with an ephemeral server port,Check the setting of yarn.nodemanager.address的问题原因及解决方案
查看电脑运行内存、核心数、磁盘空间
echo "CPU: $(nproc) cores | RAM: $(free -h | awk '/Mem/{print $2}') | Disk: $(df -h / | awk 'NR==2{print $2}')"

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)