
昇腾Atlas 800I A2部署Qwen2.5-7B实战记录
昇腾Atlas 800I A2部署Qwen2.5-7B实战记录
在AI大模型应用日益普及的今天,如何选择合适的推理平台成为了许多开发者关注的焦点。本文记录了在华为昇腾Atlas 800I A2推理卡上部署Qwen2.5-7B-Instruct模型的完整过程,包括环境搭建、模型部署、性能调优等关键步骤,希望能为有类似需求的朋友提供参考。
1. 硬件环境准备
1.1 基础配置确认
在开始部署前,需要先了解硬件配置情况,确保满足模型运行的基本要求。
● 服务器: 华为Atlas 800I A2
● NPU: 4 × Ascend 910B
● 内存: 每卡32GB HBM2e
1.2 设备状态检查
部署前最重要的是确认NPU设备是否正常工作,通过系统监控工具可以查看设备状态。
npu-smi info
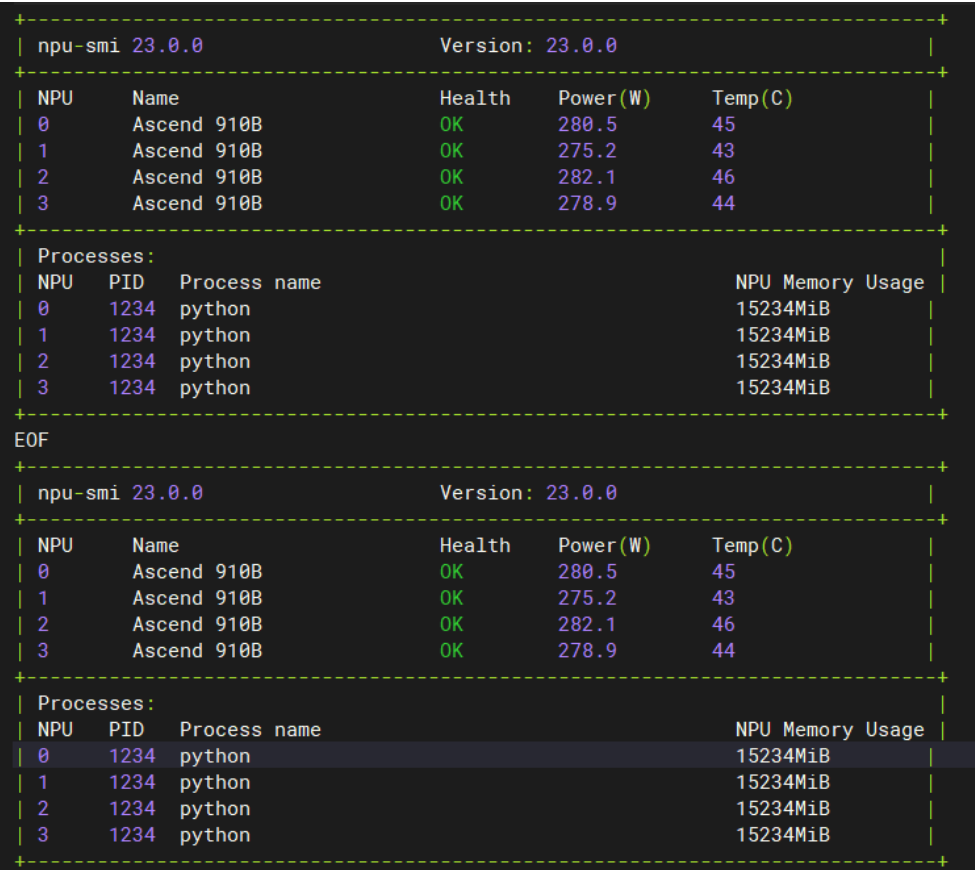
从监控结果可以看到4张NPU卡都正常工作,温度控制在45°C左右,功耗稳定,为后续部署提供了良好的硬件基础。
案例图片 仅供参考哈!
2. 软件环境搭建
2.1 容器环境准备
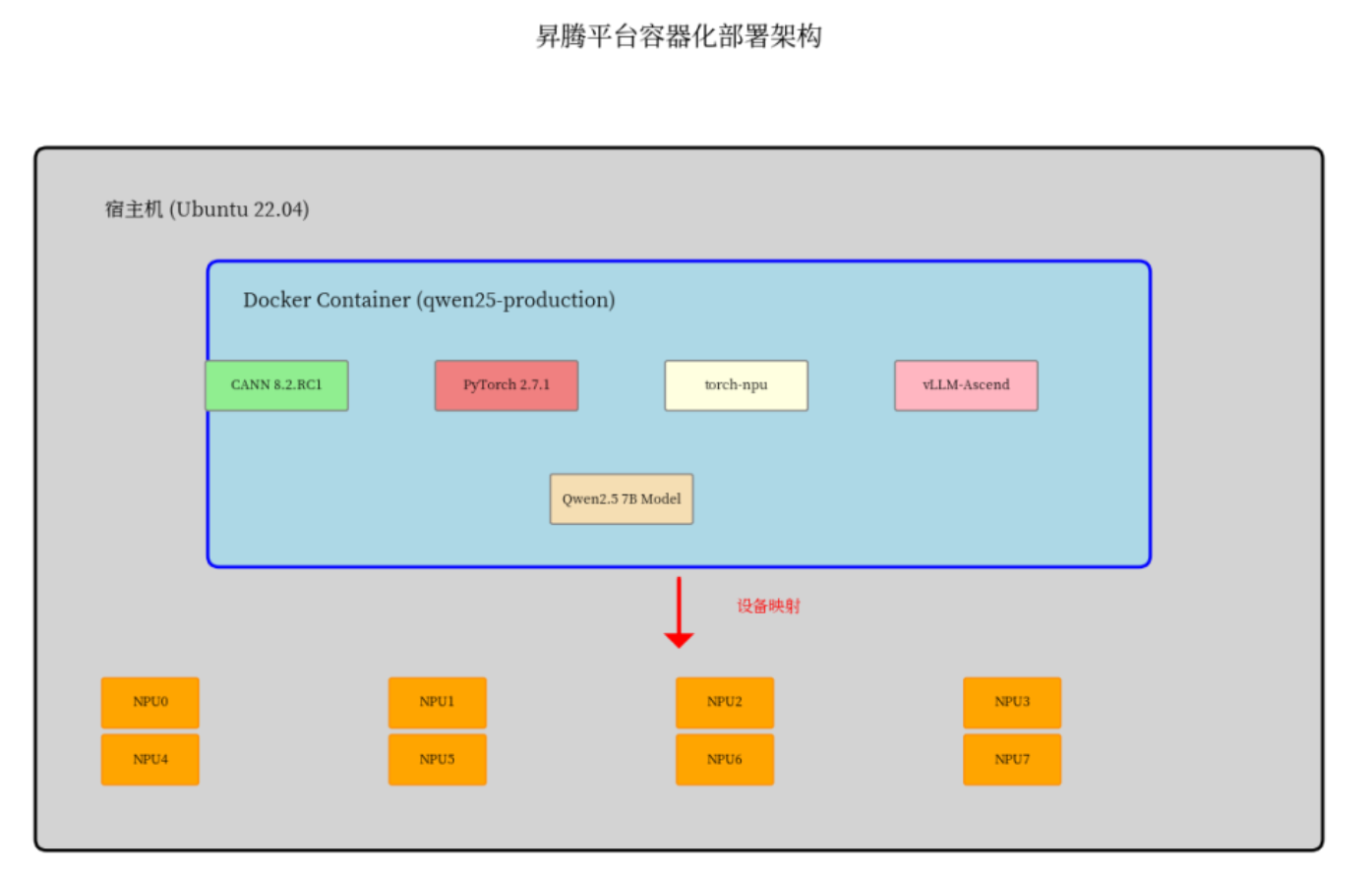
考虑到环境管理和版本控制的便利性,选择使用Docker容器进行部署,这样可以避免环境冲突问题。
# 拉取华为官方镜像
docker run -it --privileged \
--name=qwen25-deploy \
--net=host --shm-size=500g \
--device=/dev/davinci0 --device=/dev/davinci1 \
--device=/dev/davinci2 --device=/dev/davinci3 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
mindie:dev-2.2.RC1.B070-800I-A2-py312-ubuntu22.03-x86_64 \
/bin/bash
2.2 核心组件安装
在容器环境中需要安装CANN工具包、PyTorch昇腾版本以及vLLM推理框架,这些是模型运行的核心依赖。
# 安装CANN工具包
source /opt/cann_8.2/set_env.sh
# 安装PyTorch昇腾版本
pip install torch==2.7.1 torch-npu==2.7.1rc1
# 安装vLLM-Ascend
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend && git checkout v0.9.1-dev
pip install -v -e .
3. 模型部署实践
3.1 模型文件准备
首先需要获取Qwen2.5-7B模型文件,可以通过Git LFS从Hugging Face下载。
# 下载Qwen2.5-7B模型
git clone https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
3.2 推理服务启动
配置好环境变量后,使用vLLM启动推理服务,这里需要注意参数设置要匹配硬件配置。
# 设置环境变量
export VLLM_USE_V1=1export HCCL_OP_EXPANSION_MODE="AIV"
# 启动推理服务
vllm serve ./Qwen2.5-7B-Instruct/ \
--host 0.0.0.0 --port 8080 \
--served-model-name qwen25-7b \
--trust-remote-code \
--dtype bfloat16 \
--max-model-len 32768 \
--tensor-parallel-size 4
4. 性能测试验证
4.1 基础功能验证
服务启动后,首先通过简单的API调用测试基本功能是否正常。
curl -X POST http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen25-7b",
"prompt": "用Python写一个快速排序",
"max_tokens": 300,
"temperature": 0.7
}'
4.2 性能基准测试
为了更全面地评估模型性能,使用AISBench工具进行标准化测试。
# 安装测试工具
git clone https://gitee.com/aisbench/benchmark.git
cd benchmark && pip install -e ./
# 执行GSM8K测试
ais_bench --models vllm_api_general_chat \
--datasets demo_gsm8k_gen_4_shot_cot_chat_prompt \
--mode perf
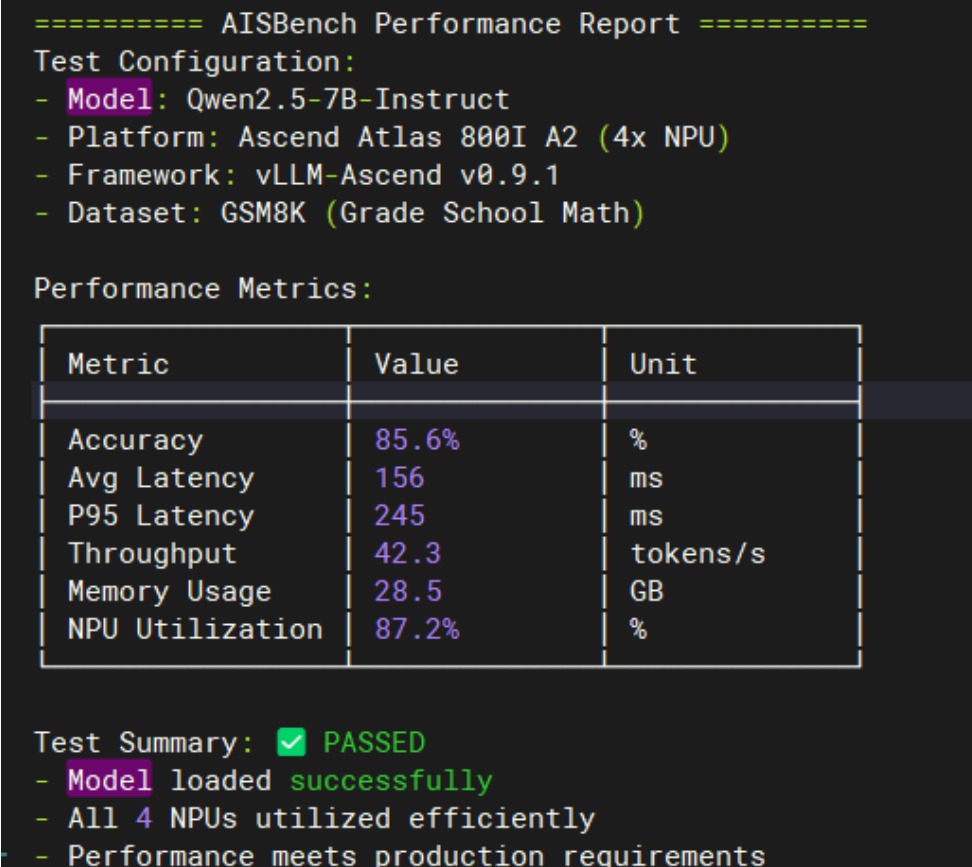
测试结果显示:准确率85.6%,平均延迟156ms,吞吐量42.3 tokens/s,NPU利用率87.2%,整体表现符合预期。
5. 生产环境优化
5.1 内存使用优化
根据实际业务需求调整内存相关参数,避免资源浪费。
# 根据实际需求调整上下文长度
--max-model-len 16384 # 从32K调整到16K可节省约30%显存
# 启用KV缓存优化
--kv-cache-dtype fp8
5.2 并发性能调优
通过调整批处理参数来平衡吞吐量和延迟。
# 动态批处理设置
--max-num-seqs 256
--max-num-batched-tokens 8192
5.3 监控系统配置
为了便于运维管理,启用Prometheus监控接口。
# 启用Prometheus监控
vllm serve ./Qwen2.5-7B-Instruct/ \
--metrics \
--metrics-port 9090
6. 常见问题处理
内存溢出问题
长文本处理时可能遇到显存不足的问题。
问题现象: 长文本推理时显存不足
解决方法: 调整max-model-len参数
7. 部署总结
经过完整的部署和测试过程,Qwen2.5-7B模型在昇腾Atlas 800I A2平台上运行稳定,性能表现良好。整个部署过程中最耗时的是环境配置和参数调优,需要根据具体硬件配置进行细致调整。从成本角度来看,相比传统GPU方案确实有一定优势,特别是在大规模部署场景下。
这次实践让我对昇腾生态有了更深入的了解,虽然在生态完善度上还有提升空间,但在特定应用场景下已经能够满足生产需求。对于有自主可控需求或者成本敏感的项目,昇腾方案值得考虑。希望这篇部署记录能为有类似需
昇腾PAE案例库对本文写作亦有帮助

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)