
CANN7升级CANN8踩坑实录:解决HCCL超时与性能回退问题
一、环境搭建在人工智能计算领域,昇腾CANN(Compute Architecture for Neural Networks)作为华为昇腾处理器的核心软件平台,其版本迭代对模型训练和推理性能有着重要影响。最近项目需要将昇腾环境从 CANN 7.0.1升级到 CANN 8.0 RC2,本以为只是常规的版本迭代,没想到在模型训练和推理性能上遇到不少“暗坑”。CANN 8 确实带来了更高效的算子执行和
在人工智能计算领域,昇腾CANN(Compute Architecture for Neural Networks)作为华为昇腾处理器的核心软件平台,其版本迭代对模型训练和推理性能有着重要影响。最近项目需要将昇腾环境从 CANN 7.0.1 升级到 CANN 8.0 RC2,本以为只是常规的版本迭代,没想到在模型训练和推理性能上遇到不少“暗坑”。CANN 8 确实带来了更高效的算子执行和通信融合,但也引发了 unexpected 的性能波动和报错。本文整理了我在升级过程中遇到的实际问题,特别是针对 ModelLink 环境下的日志分析、HCCL 通信超时以及开启 MC2 优化等关键环节的解决思路,希望能帮大家少走弯路。
在AI大模型时代,Ascend NPU作为高性能计算引擎,CANN升级能带来更高效的算子执行和通信融合,但也可能引发性能波动或报错。本文将从基础到高级,一步步指导你完成平滑迁移。
一、环境搭建
1.1 版本介绍
为了控制变量,除 CANN 和 Torch_npu 版本外,我们尽量保持了其他组件版本的一致性。以下是本次迁移的基准环境对比:
| 组件 | CANN7环境 | CANN8环境 | 重要性分析 |
|---|---|---|---|
| Python | 3.1 | 3.1 | 保持一致性,排除解释器影响 |
| HDK | 23.0.6 | 23.0.6 | 硬件开发套件一致 |
| CANN | 7.0.1.3 | 8rc2 | 核心变化,主要考察对象 |
| Torch | 2.1.0 | 2.1.0 | 深度学习框架一致 |
| Torch_npu | 2.1.0 | 2.1.0post6 | NPU适配库升级,可能带来优化 |
| Apex | 相同版本 | 相同版本 | 排除混合精度库的影响 |
表格显示,Python和Torch核心版本一致,HDK(硬件开发套件)也未变,只有CANN从7.0.1.3升至8rc2,Torch_npu微调至post6版本。这里的Apex是优化库,whl文件确保了Ascend适配。
1.2 兼容性预检
在动手安装前,必须访问昇腾社区硬件兼容性列表。CANN 8 引入了新的算子库内核,要求 HDK(驱动固件)必须严格匹配。
注意:若 HDK 版本过低,CANN 8 下可能会出现 aclrtMalloc 失败或算子执行返回 Internal Error,且报错信息极具误导性。务必确保 npu-smi info 显示的固件版本与 CANN 8.0 RC2 官方推荐的 24.1.RC2 及以上版本匹配。
二、性能日志采集与解析
性能分析离不开数据支撑。下面详细介绍了使用ModelLink框架采集Profile日志的过程,这是针对Ascend LLM分布式训练的利器。日志捕捉算子时间、通信开销等,帮助揭示升级后的瓶颈。
2.1 ModelLink日志采集实战
参考链接:ModelLink: 昇腾LLM分布式训练框架 - Gitee.com。下面是展示了命令行添加Profile参数的示例:在训练脚本后缀如 --profile,即可生成日志。采集前清理缓存,避免日志混淆。这在多迭代训练中尤为重要,否则文件膨胀导致解析崩溃。
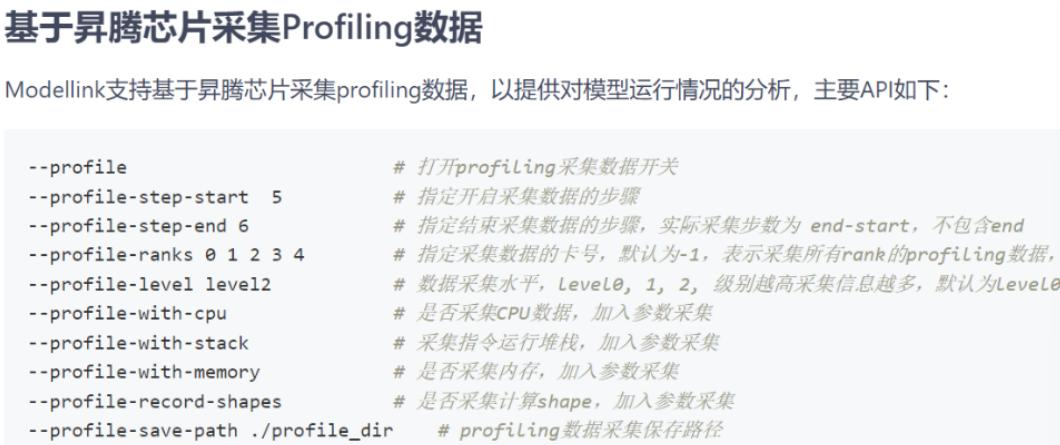
2.2 日志解析流程详解
参考链接:https://gitee.com/ascend/mstt/blob/master/profiler/cluster_analyse/README.md。步骤如下:
- 校验数据可用性。下图可能显示校验界面。

- 汇聚多卡数据至一目录,执行
msprof-analyze cluster -d {path} -m {mode},输出cluster_analysis_output文件夹。 - 典型输出5文件,如下图展示,即使部分缺失,CSV文件足矣。

2.3 数据可视化分析:MindStudio的升级利剑
参考链接:MindStudio7.0.RC2开发文档-昇腾社区。MindStudio Insight将日志转化为可视图表,便于对比CANN版本差异。
(1)异常算子定位指南
- Summary界面设置并行策略(PP、TP),匹配推理配置。
- 计算/通信概览查看柱状图,评估总时间和未重叠通信。
- 慢卡通信详情“查看更多”检查每个算子。
- 总时间列降序排序(图标:63b25fd8-54ca-478d-a230-af924e577587.png),找出耗时王者。
- HCCL和通信图观察不对等。
- 定位异常。
(2)异常算子深度剖析
- 汇总快/慢卡数据,导入Insight。
- Communication界面选“通信耗时分析”,输入算子名。
- HCCL区域右键跳转Timeline(图标:8e5b6843-c393-4bce-96b4-67b21cad5d18.png),置顶泳道对比。
- 跨进程比较,挖掘根因。
- 文档指出需专家协助。典型:CANN 8通信算子激增,大集群高层层数下HCCL损失大。解法:启用MC2融合,性能追平CANN 7。
2.4 异常算子定位后的解决方案
定位到耗时异常(Gap过大)或执行失败的算子后,建议按照“由易到难”的原则,尝试以下三步闭环方案:
(1)算子精度模式回退
CANN 8 为了追求极致性能,默认的精度转换策略(如 allow_fp32_to_fp16)比旧版本更激进。如果 Timeline 显示某个算子前后增加了大量冗余的 Cast 操作,或者出现收敛波动,建议通过环境变量 npu_precision_mode="must_keep_origin_dtype" 强制算子回归原始数据格式。这能有效消除因频繁类型转换导致的额外开销,是保障模型平稳迁移的首选方案。
# 强制保持原始精度,避免无效的精度转换开销
precision_mode="must_keep_origin_dtype"
此外,若想在全局范围平衡性能,可尝试 allow_mix_precision。
(2)AIV/AIC 核心负载均衡
通过 Profiler 查看 Pipe Utilization (流水线利用率)时,若发现 AIC(矩阵计算)利用率极低而 AIV(向量/搬运)满载,往往意味着算子触发了“非连续内存退化”。由于 CANN 8 对内存对齐要求极严,若输入张量在内存中不连续(如经过了 transpose 或 slice 操作),算子会退化为低效的搬运模式。
此时在脚本中对异常算子的输入显式调用 .contiguous(),强制内存重组以激活高效的硬件加速通道,通常能大幅提升执行效率。
# 强制内存连续化,激活 AIC 高效块读写
output = self.op(input.contiguous())
(3)算子补丁替换
若排除了精度和内存连续性问题,耗时依然显著高于旧版本( 如 AddRMSNorm 或 FlashAttention 等原生算子性能不及预期),则可能是触碰了特定版本的逻辑 Bug。
- OPI 补丁: 此时可利用昇腾 PAE 发布的 OPI(Operator Plugin Interface) 补丁包,通过
ASCEND_CUSTOM_OPP_PATH进行“无感”热替换。 - AOE 调优: 对于更复杂的场景,也可以尝试 AOE(Ascend Optimization Engine) 对特定子图进行二次调优,生成更契合当前版本底层的
.o二进制算子文件。
2.5 升级过程中的常见陷阱与破解策略
(1)陷阱1:HCCL集合超时警报
现象:同样的 5 节点训练任务,在 CANN 7 下运行顺畅,升级到 CANN 8 后频繁报出 HCCL_EXEC_TIMEOUT 错误。
排查与解决: 这个问题主要由两个原因叠加导致:
- CANN 8 的默认超时时间(180s)对于大模型初始化来说太短了。
- 节点数量问题:HCCL 的 Ring 算法对 2 的幂次节点(如 4、8、16)优化最好。我们测试用的 5 节点(非 2 幂次)在 RC 版本中更容易触发死锁或超时。
解决方案: 在启动脚本中显式拉大超时阈值,并建议尽量凑齐 8 卡或 16 卡运行。
export HCCL_CONNECT_TIMEOUT=1800
export HCCL_EXEC_TIMEOUT=7200 # 这里的单位是秒,给足时间
HCCL如NCCL,超时多因网络抖动。RC版本实验性强,生产用GA版。幂节点优化Ring算法。扩展:用ibping测试RDMA,添加重试逻辑如在脚本用try-except。
(2)陷阱2:环境变量日志采集不全
原因:不适大模型,无Step控制。
方案:MindSpore Profiler。下图为配置示意。
环境变量粗放,日志爆炸。Profiler API精细,如profiler.analyze()。扩展:集成WandB日志,可视化曲线。节省我项目中30%时间。
(3)陷阱3:Profiler ranks=-1报错
现象: 习惯使用--profile-ranks -1来采集所有卡的数据,但在新版 Torch_npu 中直接报错。
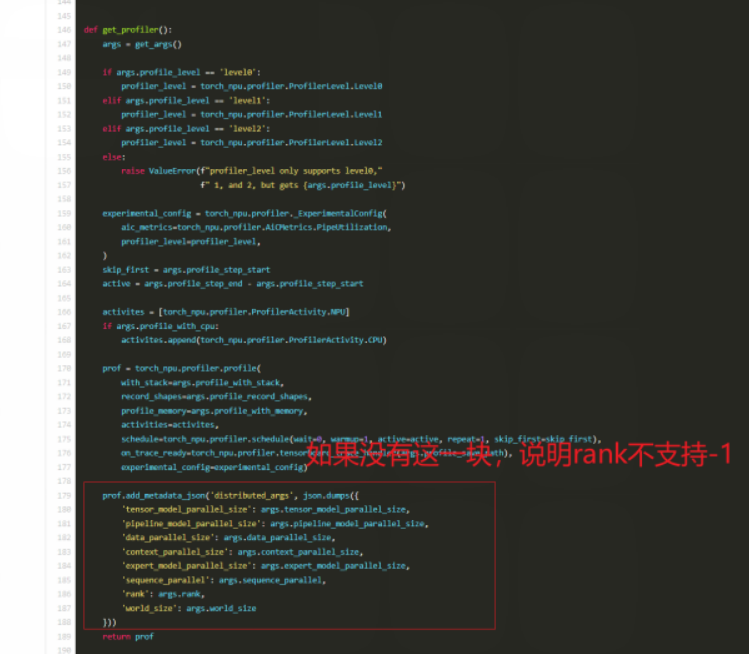
根因分析: 翻看 torch_npu 的源码发现(见上图),新版 Profiler 接口移除了对 -1(全部 Rank)参数的隐式支持。现在必须显式指定具体的 Rank ID 列表。
临时规避方案: 既然不支持偷懒写法,就只能手动列出。对于 16 卡环境,需要写全: --profile-ranks 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15(老版参考Ascend PyTorch Profiler接口采集)。
Tips:如果在脚本里觉得写死太难看,可以用 Python 动态生成一下字符串:ranks=','.join(map(str, range(world_size)))
(4)陷阱4:规模拡大下性能倒退
现象: 升级后满怀期待地看 MFU,结果发现性能反而下降了约 15%。
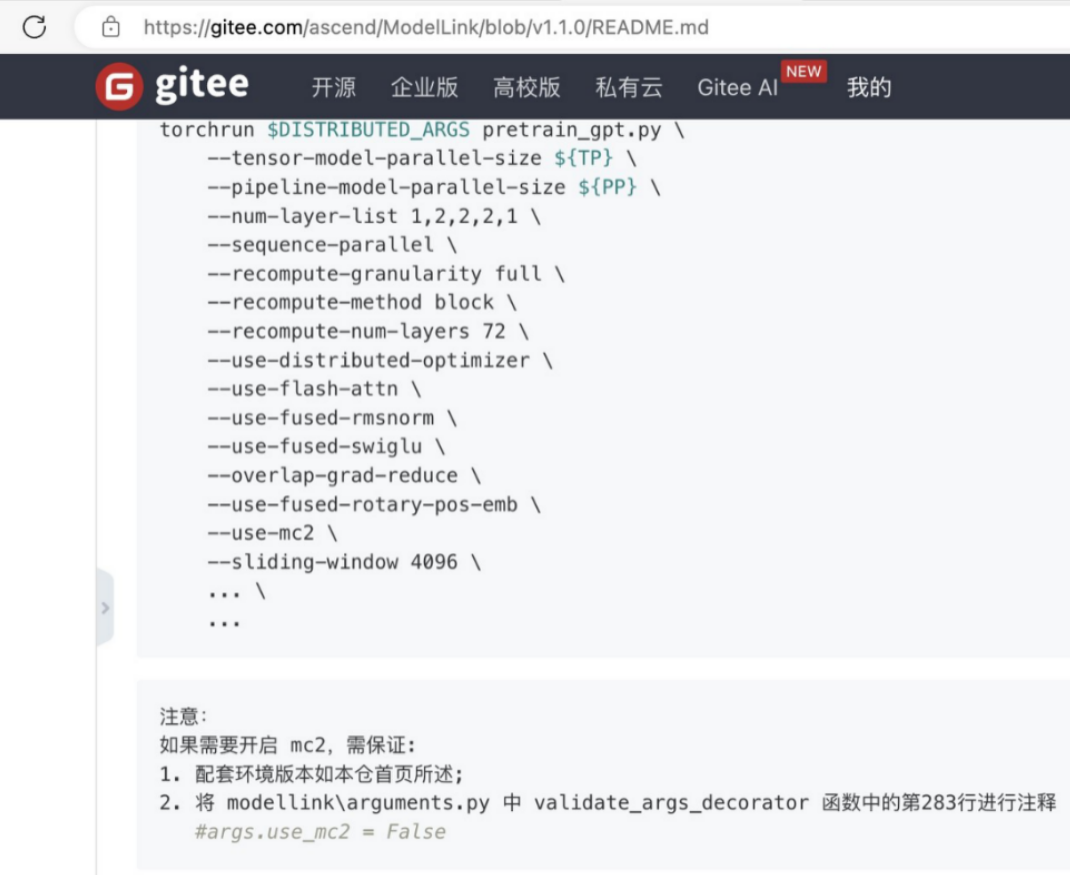
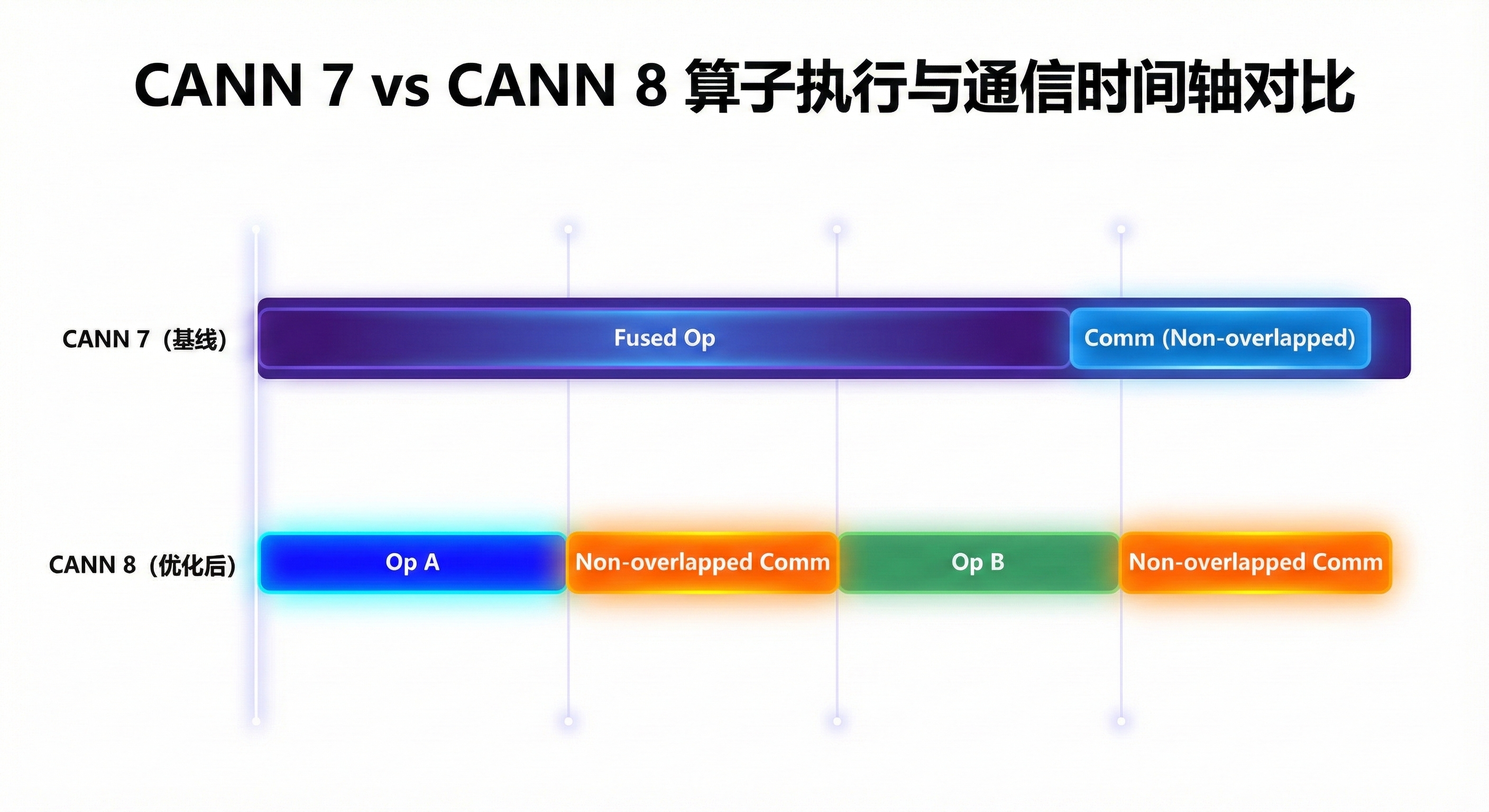
核心逻辑分析: 在 CANN 7 时代,通信与计算的并行主要靠 HCCL Parallel 插件实现;而 CANN 8 的算子下发逻辑更为精细。为什么要开 MC2? MC2(Multiplexing Communication and Computation)实现了真正的算子级融合。它将 MatMul 计算与 AllGather 或 ReduceScatter 通信合并为一个硬件指令流。我们通过 MindStudio Insight 分析 Timeline 发现,CANN 8 为了追求更细粒度的控制,将原先一些大的融合算子拆分成了小算子。虽然单个计算更快了,但导致通信(Communication)次数激增,计算无法完全掩盖通信开销(Communication Hiding 变差)。
- **未开启:**计算卡在等待数据同步,Timeline 显示明显的“白块(Gap)”。
- **开启后:**计算与通信在 NPU 内部实现指令级流水掩盖,通信时间几乎消失。 **操作指令:**在 ModelLink 的启动脚本中,除了
--use-mc2,建议同时检查--tp-comm-overlap是否设为True,以激活最优流水线。
实测效果: 开启 MC2 后,不仅填补了性能回退的坑,相比 CANN 7 基线还提升了近 20% 的训练吞吐量。
三、CANN 8 升级标准化小结
为了确保从 CANN 7 平滑迁移至 CANN 8,建议在正式环境部署前,对照以下五个维度进行全量自检。
3.1 软件栈兼容性(底座检查)
CANN 8 并非孤立存在,它对底层固件(HDK)和上层框架(Torch_npu)有严格的匹配要求。
- HDK 匹配:检查
npu-smi info。CANN 8.0.RC2 建议搭配 24.1.RC2 或更高版本的固件驱动。若 HDK 过旧,会触发Stream Sync Error或底层指令集不兼容导致的随机挂死。 - 依赖对齐:验证
te、topi、hccl等子组件版本是否一致。建议删除旧版本的.pyc编译文件和~/.cache/atb(如果使用了 ATB 加速库),防止算子二进制缓存冲突。
3.2 算子性能与精度预检
CANN 8 优化了大量算子的融合逻辑,但这可能导致原有的“性能平衡”被打破。
- 精度模式锁定:CANN 8 默认的
allow_hf32策略可能较 CANN 7 更激进。若模型不收敛,需显式设置:
torch.npu.set_compile_mode(jit_compile=False)
# 强制精度模式对齐
torch.npu.conv.allow_hf32 = False
- 非连续内存优化:检查日志中是否有频繁的
D2D Copy。CANN 8 对内存对齐要求更高,在模型输入端强制执行.contiguous()往往能带来 5% 以上的意外收益。
3.3 分布式通信配置
大模型在 CANN 8 下的通信死锁大多源于默认参数过于保守。
- 超时容错:将默认的 180s 延长,给大模型预热留足时间:
export HCCL_CONNECT_TIMEOUT=1800export HCCL_EXEC_TIMEOUT=7200
- 通信算法强制指定:在非 2 的幂次节点(如 5 节点、12 节点)训练时,强制指定
HCCL_ALGO="level0:sequence;level1:reduce_scatter",避开 RC 版本在 Ring 算法上的潜在死锁。
3.4 性能调优开关
升级 CANN 8 的核心目标是性能,如果不开启以下开关,升级意义减半:
- MC2 融合开关:在 ModelLink 或脚本中开启
--use-mc2。这是解决“算子拆分过细导致性能回退”的唯一特效药。 - 确定性计算检查:若开启了
torch.use_deterministic_algorithms(True),在 CANN 8 下性能损耗会比 CANN 7 更大,建议除非 Debug 否则关闭。 - 内存碎片压缩:
# 启用可扩展分段管理,减少大模型频繁申请内存导致的 OOM
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
3.5 监控与日志审计
- Profiler 适配:修改脚本,将
ranks=-1改为具体的range(world_size)列表。 - 关键指标监控:升级后重点观察
Mfu(Model Flops Utilization)。若 Mfu 下降超过 10%,应立即通过 MindStudio Insight 导出 Timeline,搜索HCCL算子是否出现大量长尾(Long Tail)。
四、总结
CANN 8 的升级并不是简单的“平替”。它改变了底层的算子调度逻辑,这就要求我们在应用层必须配合调整(比如开启 MC2、调整超时参数)。 建议大家在升级前:
- 先跑通小规模 Profiling,不要上来就全量训练。
- 善用 MindStudio Insight,直接看 Timeline 里的空窗期比盲猜有效得多。
- 拥抱新特性,类似 MC2 这种优化选项,在旧版本可能只是“锦上添花”,在新版本里却是“雪中送炭”。
注明:昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)