
从+NV+Apex+到+Apex+for+Ascend:混合精度训练在昇腾平台的适配与编译全流程解析

从 NV Apex 到 Apex for Ascend:混合精度训练在昇腾平台的适配与编译全流程解析
一、背景:从 NV Apex 到 Ascend 适配
在 PyTorch 生态中,NVIDIA Apex 一直是混合精度训练(Automatic Mixed Precision, AMP)的核心工具。它能有效降低显存占用、加快模型训练速度,是深度学习训练中极为重要的性能优化手段。
随着华为昇腾 NPU 在 AI 训练领域的广泛应用,社区基于 Apex 的实现逻辑推出了 “Apex for Ascend”——这是一套面向昇腾平台的 Apex Patch 适配方案,用户可通过对原版 NV Apex 打补丁(patch)的方式,让其支持 Ascend 架构,从而在昇腾平台上实现混合精度与分布式训练。
该项目已在 GitCode 与 GitHub 平台同步开源:
- Ascend 适配仓库:https://gitcode.com/Ascend/apex
- NVIDIA 原版仓库:https://github.com/NVIDIA/apex
二、适配机制:Apex Patch 的意义
Apex for Ascend 不仅仅是简单的“可编译”版本,而是一个针对 NPU 体系的深度适配。 它主要带来了三类能力提升:
- 混合精度训练支持 在昇腾平台上实现自动混合精度(AMP),提升训练吞吐的同时保持数值精度稳定性。
- 性能优化特性扩展 提供如梯度融合、融合优化器(Fused Optimizer)等额外模块,用于减少通信与算子调用开销。
- 生态兼容性增强 与 PyTorch 2.x 保持良好兼容,支持 Ascend NPU 的底层算子调用与 MindIE 容器镜像集成。
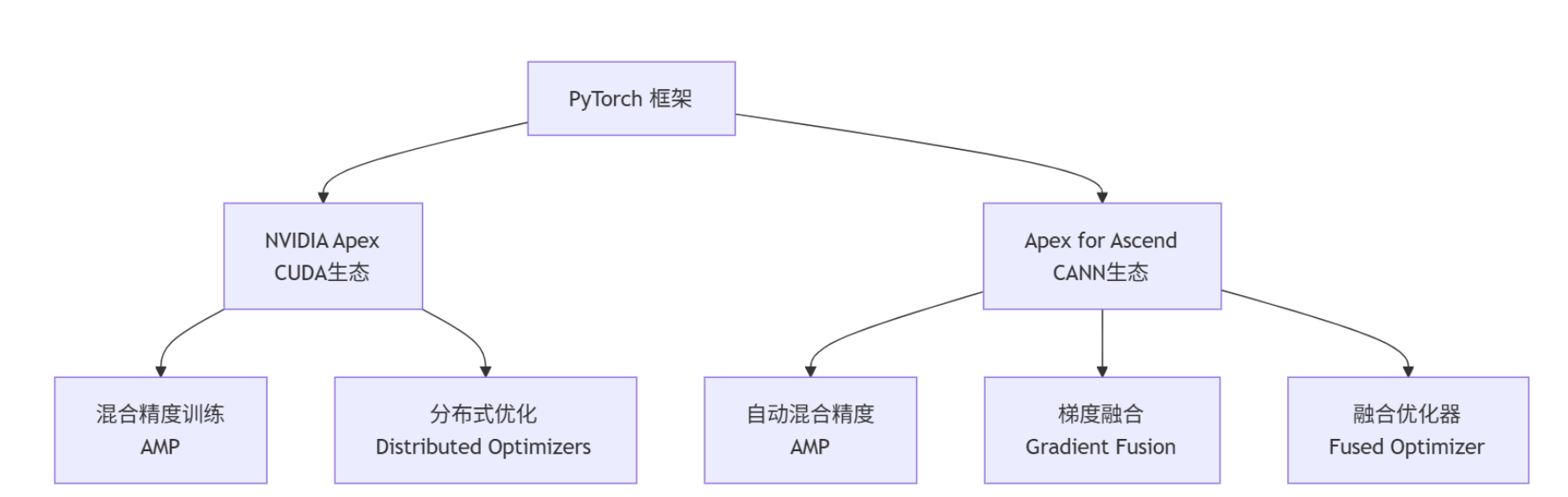
三、混合精度训练原理与 Ascend 平台优化机制
在传统全精度训练(FP32)中,模型参数与梯度都以 32 位浮点数形式存储与计算,虽然精度高,但显存与计算开销巨大。 混合精度训练(AMP) 的核心思路是:
“在不影响数值稳定性的前提下,将部分计算转为半精度(FP16),以换取更高的吞吐率和更低的显存占用。”
在 GPU 平台上,Apex 借助 TensorCore 实现 FP16 运算加速;而在 昇腾 NPU 上,Apex Patch 则基于 昇腾自研的 Cube Unit(矩阵计算单元)和 算子融合优化机制 实现类似的加速效果。
Apex for Ascend 的优化关键包括:
- 自动精度切换 (AMP):根据算子类型动态选择 FP16 或 FP32。
- Loss Scaling 机制:通过动态缩放损失值防止数值下溢。
- 梯度融合与算子融合:减少 Kernel Launch 开销与通信代价。
这些机制协同作用,使得在昇腾 NPU 上的训练速度可提升 20%~50%(视模型规模而定),同时保持与 FP32 训练一致的精度表现。
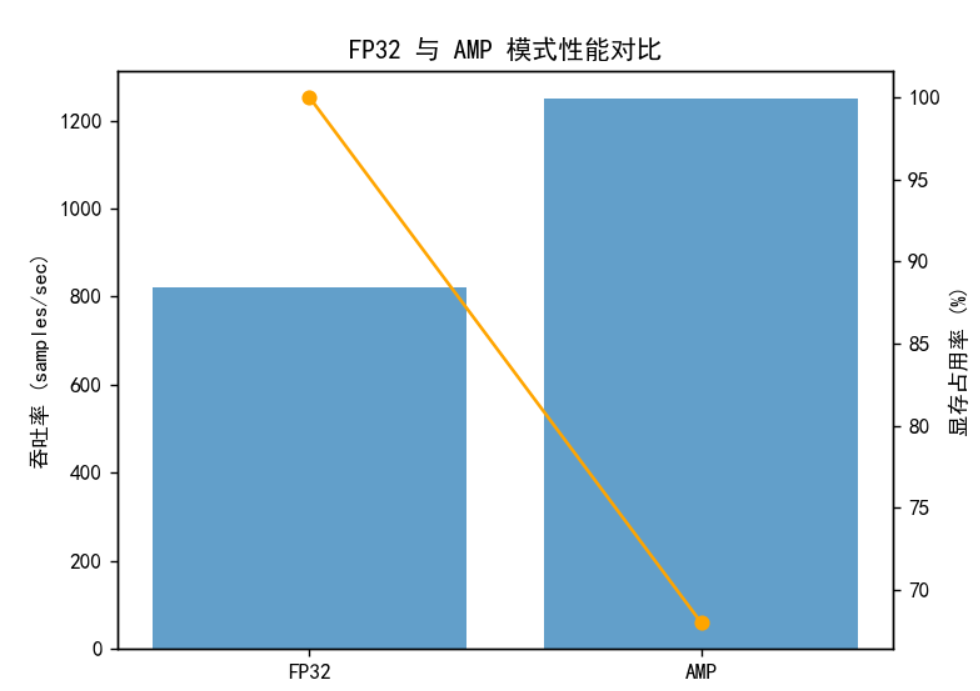
使用一个小模型在 Ascend 上运行 AMP,显示训练损失变化与显存占用对比
示例代码:
import torch
from torch import nn, optim
from apex import amp
# 简单模型
model = nn.Linear(10, 1).cuda()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# 初始化混合精度
model, optimizer = amp.initialize(model, optimizer, opt_level='O2')
# dummy data
x = torch.randn(64, 10).cuda()
y = torch.randn(64, 1).cuda()
for i in range(5):
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
print(f"Step {i}, Loss: {loss.item()}")
示例结果:
四、编译流程
(1)容器环境准备
在昇腾平台部署 Apex 最推荐的方式是使用容器编译。 首先需确保服务器具备网络访问能力。若处于内网环境,可以通过设置以下代理变量:
ip=代理服务器地址
port=代理服务器端口
export http_proxy="http://${ip}:${port}"
export https_proxy="http://${ip}:${port}"
提示:仅配置 Shell 代理并不能让 Docker 使用相同代理,因为 Docker 守护进程独立运行,需要单独配置。
为此,我们需要在 /etc/systemd/system/docker.service.d 目录下新增配置:
[Service]
Environment="HTTP_PROXY=http://代理地址:端口"
Environment="HTTPS_PROXY=http://代理地址:端口"
保存后执行:
sudo systemctl daemon-reload
sudo systemctl restart docker
这样 Docker 拉取镜像与构建过程才可正常联网。
小测试确认网络可达
# 设置代理
export http_proxy="http://127.0.0.1:1080"
export https_proxy="http://127.0.0.1:1080"
# 测试网络连通性
curl -I https://gitcode.com
(2)容器构建与进入
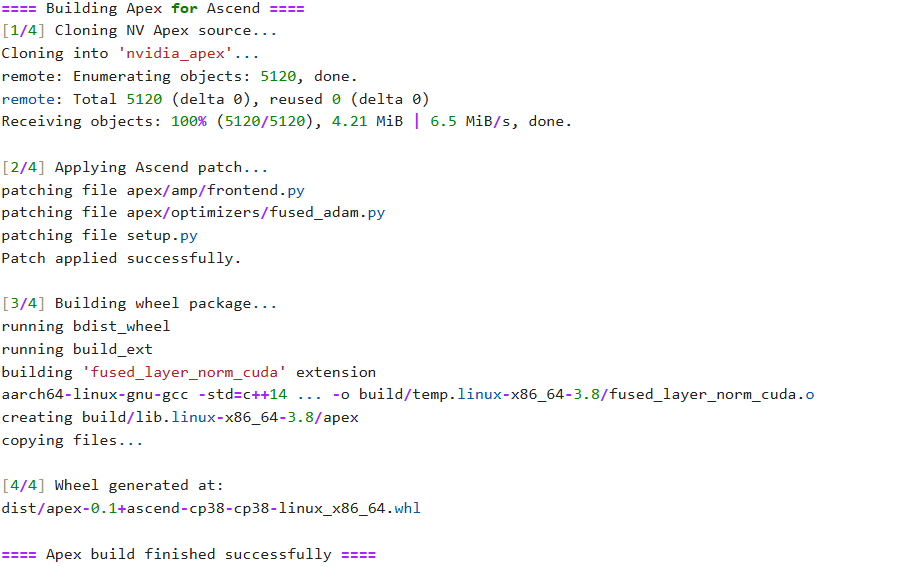
在配置好代理后,使用 Apex 官方脚本构建容器镜像:
git clone -b master https://gitcode.com/Ascend/apex.git
cd apex/scripts/docker/{arch} # {arch} 为 X86 或 ARM
docker build -t manylinux-builder:v1 .
进入容器:
docker run -it -v /{code_path}/apex:/home/apex manylinux-builder:v1 bash
其中 {code_path} 为源码路径挂载点。
演示如何进入容器,确认代码挂载成功
git clone -b master https://gitcode.com/Ascend/apex.git
cd apex/scripts/docker/X86
docker build -t manylinux-builder:v1 .
docker run -it -v /home/user/apex:/home/apex manylinux-builder:v1 bash
(3)Torch 环境与 Apex 编译
容器内安装匹配版本的 Torch(示例为 Python 3.8, Torch 2.1.0):
pip3.8 install torch==2.1.0
然后执行编译脚本:
cd /home/apex
bash scripts/build.sh --python=3.8
执行完成后,会在 dist 目录下生成 Apex 的 .whl 安装包。
(4)安装 Apex
cd apex/dist/
pip3 uninstall apex
pip3 install --upgrade apex-0.1+ascend-{version}.whl
其中 {version} 需对应 Python 版本与 CPU 架构。
五、编译脚本与 Patch 机制
很多开发者在初次构建 Apex for Ascend 时,会疑惑 scripts/build.sh 和 setup.py 到底做了什么。 实际上,Apex Patch 的核心逻辑是:
- 克隆原始 NV Apex 源码 → 通过
git clone获取最新主干版本。 - 应用 Ascend Patch → 将针对 NPU 的适配代码与混合精度实现覆盖到原始模块中。
- 重新构建 Python 扩展模块 → 调用
setup.py编译 C++ 与 CUDA(或 NPU CANN)扩展。
在这一步中,setup.py 脚本会根据系统架构(X86/ARM)与 Python 环境动态定位 torch 依赖,并生成 .whl 安装包。
PS:如果想定制构建过程,可直接修改 scripts/build.sh 内的 --python 参数与编译选项,或在 setup.py 中新增 extra_compile_args 进行优化。
六、常见问题
1. Dockerfile 拉取镜像失败

通常是代理未生效导致。 解决方案:按照前文 Docker 代理配置 部分重新设置 /etc/systemd/system/docker.service.d。
2. OpenEuler 环境下编译 Torch 链接失败

在部分 MindIE OpenEuler 镜像下,执行编译会提示找不到 libtorch.so。 问题原因在于 OpenEuler 遵循 RedHat 系规范,区分 lib 与 lib64 目录,而默认 setup.py 假设路径为 /usr/local/lib,从而导致库定位失败。
解决方法: 修改 apex/apex/setup.py 中的路径配置:
package_dir = f'{sys.prefix}/lib/python{py_version}/site-packages'
# 修改为:
package_dir = f'{sys.prefix}/lib64/python{py_version}/site-packages'
重新执行:
python setup.py --cpp_ext bdist_wheel
七、差异
在 Ubuntu 与 OpenEuler 两种体系下,Python 库路径的差异往往是潜在的编译坑:
| 操作系统 | 库路径规范 | 特点 |
|---|---|---|
| OpenEuler / CentOS / RedHat 系 | /usr/local/lib64 |
区分 32/64 位库 |
| Ubuntu / Debian 系 | /usr/local/lib |
统一使用 lib,依靠 multiarch 管理多架构 |
因此,在移植 Apex for Ascend 或构建自定义镜像时,务必确认 Python 与 Torch 的实际安装路径保持一致,否则容易出现 link torch failed 问题。
八、总结
Apex for Ascend 的意义不止于“能编译通过”。 它背后体现了昇腾团队在 PyTorch 生态兼容性、算子性能调优与工程集成 上的持续投入。 通过 Patch 机制让成熟的 GPU 工具在 NPU 架构上延续生命力,这不仅优化了开发者迁移成本,也让昇腾生态在深度学习训练中拥有更高的开放度与灵活性。
对开发者而言,理解这些编译细节,不仅是为了“装得上包”,更是深入掌握 NPU 平台编译体系与软件栈差异的过程。
注明:昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 24
24 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)