
手把手带你用MindSpeed-MM在昇腾910B上训练Qwen-VL:从环境搭建到Loss收敛
一、前言
最近多模态大模型(LMM)火得一塌糊涂,从GPT-4o到国内的Qwen-VL、InternVL,大家都在卷“图文理解”。作为一个长期在英伟达生态里摸爬滚打的炼丹师,最近项目组搞来了几台昇腾910B服务器,任务很明确:把多模态模型在昇腾NPU上跑起来,而且性能不能差。刚开始我是有点虚的,毕竟大模型的训练涉及到复杂的并行策略,还要加上Vision Encoder,异构计算的坑肯定不少。但经过这几周的折腾,依托 MindSpeed-MM 这个开源仓,我发现昇腾现在的生态已经比两年前成熟太多了。
今天这篇博客不讲虚的理论,直接上干货。以Qwen-VL-Chat为例,带大家完整复现一遍从环境配置、数据处理、权重转换到预训练(Pretrain)/微调(SFT)的全流程。
二、架构理解与环境准备
在动手敲代码之前,我们得先搞清楚 MindSpeed-MM 到底是什么。简单来说,它是昇腾官方基于 Megatron-LM 做的多模态扩展。如果说 MindSpeed-LLM 解决了大语言模型在 NPU 上的并行训练问题,那 MindSpeed-MM 就是在此基础上,把 ViT(视觉编码器) 和 Projector(对齐层) 的训练逻辑给补齐了,并且针对昇腾硬件做了算子优化(比如 FlashAttention)。
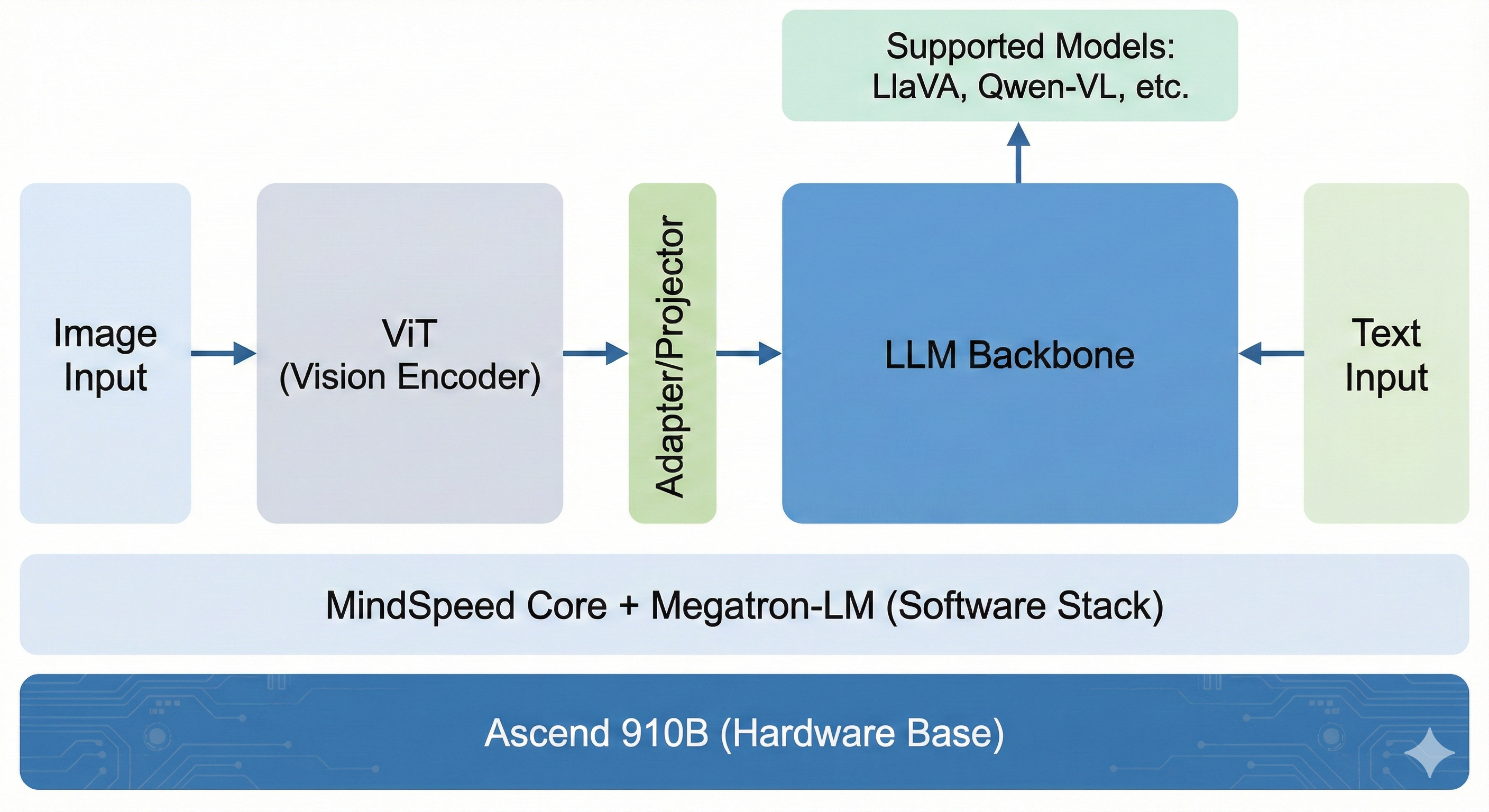
2.1 硬件与软件栈检查
一定要检查 CANN 包版本!很多报错都是因为软硬件版本不匹配导致的。我这次使用的环境如下:
- 硬件:Ascend 910B (64GB显存 x 8卡)
- OS:EulerOS / Ubuntu 20.04
- CANN:8.0.RC1 (建议使用最新版本,对FlashAttn支持更好)
- Python:3.8+
- PyTorch:2.1.0 (基于昇腾的 torch_npu)
2.2 核心依赖安装
别直接 pip install -r requirements.txt 就完事了,有几个包必须手动编译,特别是 AscendSpeed 和 MindSpeed。
# 1. 配置昇腾环境变量(这一步甚至建议写进 ~/.bashrc)
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 2. 安装 MindSpeed
git clone https://gitee.com/ascend/MindSpeed.git
cd MindSpeed
pip install -e .
# 3. 安装 MindSpeed-MM (我们的主角)
git clone https://gitcode.com/Ascend/MindSpeed-MM.git
cd MindSpeed-MM
pip install -e .
这也是我踩的第一个坑: 务必确认 pdsh 已经安装,否则多机多卡启动时脚本会直接卡死不动,没有任何报错。
三、数据准备
多模态训练最烦人的就是数据。既有文本又有图片,路径稍微配错一点,训练直接崩。MindSpeed-MM 推荐使用类似 LLaVA 的 JSON 格式。我们需要把公开数据集(比如 COCO 或 LLaVA-Instruct)清洗成如下格式:
[
{
"id": "000000033471",
"image": "images/coco/train2017/000000033471.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\nWhat is the color of the car?"
},
{
"from": "gpt",
"value": "The car is red."
}
]
}
]
为了提高读取效率,建议尽量把图片放在高速 NVMe SSD 上。如果图片是海量小文件,打包成 Tar 或者利用 Ceph 存储会更好,不过在本次 910B 单机实验中,直接读取本地文件完全扛得住。
四、权重转换:HuggingFace到Megatron
这是很多新手最容易卡住的地方。 一定要明确:HuggingFace 的权重格式(safetensors/bin)是不能直接喂给 Megatron 架构去训练的。 我们需要把 HF 的权重切分,转换成支持张量并行(TP)和流水线并行(PP)的格式。
MindSpeed-MM 提供了很方便的脚本 tools/ckpt_convert/qwen/convert_weights_from_huggingface.py。
假设我们要跑 TP=8(8卡张量并行),命令如下:
python tools/ckpt_convert/qwen/convert_weights_from_huggingface.py \
--input-model-path ./Qwen-VL-Chat \
--output-model-path ./Qwen-VL-Chat-TP8 \
--tensor-model-parallel-size 8 \
--pipeline-model-parallel-size 1 \
--type Qwen-VL
运行截图:

五、训练实战
5.1 启动脚本与参数解析
万事俱备,只欠东风。
MindSpeed-MM 的 examples 目录下有很多现成的脚本。我们要修改 examples/mcore/qwen_vl/pretrain_qwen_vl_7b_ptd.sh。
这里有几个关键参数必须根据你的环境修改,否则必报错:
DATA_PATH: 指向你刚才处理好的数据 json。IMAGE_PATH: 图片的根目录。CKPT_LOAD_DIR: 指向刚才转换好的 TP8 权重目录。TP和PP: 必须和转换权重时保持一致(这里 TP=8, PP=1)。
#!/bin/bash
# ... (省略头部定义)
GPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=6000
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="
--nproc_per_node $GPUS_PER_NODE \
--nnodes $NNODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT
"
# 核心训练参数
GPT_ARGS="
--tensor-model-parallel-size 8 \
--pipeline-model-parallel-size 1 \
--sequence-parallel \
--use-flash-attn \ # 重点:昇腾上一定要开这个,速度提升巨大
--use-fused-rmsnorm \
--use-fused-swiglu \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--num-attention-heads 32 \
--seq-length 2048 \
--max-position-embeddings 2048 \
--micro-batch-size 2 \ # 显存不够就调小这个
--global-batch-size 128 \
...
"
torchrun $DISTRIBUTED_ARGS pretrain_qwen_vl.py ...
5.2 踩坑记录:OOM(显存溢出)怎么办?
刚开始跑的时候,我设置 micro-batch-size=4,结果直接报 OOM。 解决思路:
- 开启重计算(Recomputation):加上
--recompute-granularity full --recompute-method block。虽然稍微牺牲一点计算速度,但能省下大量显存。 - 降低
micro-batch-size:降到 1 或者 2。 - 检查分辨率:Qwen-VL 默认支持高分辨率输入,如果图片太大,ViT 产生的 token 会暴增。可以限制输入图片的分辨率。
六、训练过程可视化与性能分析
运行脚本后,盯着终端滚动的日志,这是程序员最解压的时刻。
sh examples/mcore/qwen_vl/pretrain_qwen_vl_7b_ptd.sh
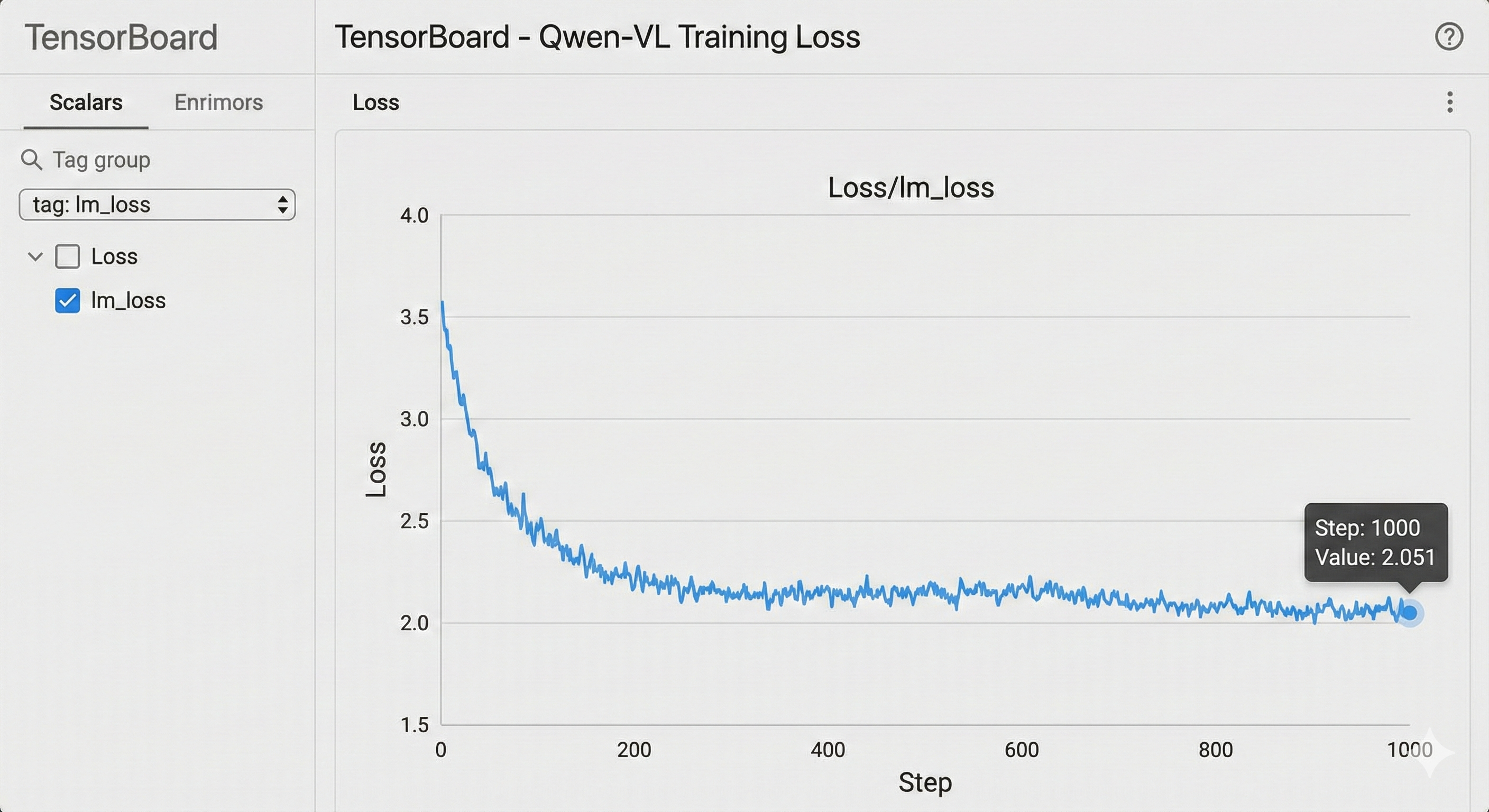
大概几分钟的编译(JIT Compile)后,Loss 开始打印了:
iteration 10/ 1000 | consumed samples: 1280 | elapsed time per iteration (ms): 4502.5 | learning rate: 1.000E-05 | global batch size: 128 | lm loss: 2.843211 | loss scale: 1.0
iteration 20/ 1000 | consumed samples: 2560 | elapsed time per iteration (ms): 4489.1 | learning rate: 1.500E-05 | global batch size: 128 | lm loss: 2.412033 | loss scale: 1.0
...
我们可以看到 elapsed time per iteration 稳定在 4.5秒左右。对于 TP8 的 7B 模型来说,这个吞吐量在 910B 上是非常可观的,基本利用满了算力。
此外,强烈建议大家学会看 Profiling 数据。使用昇腾的 msprof 工具,可以看到算子的具体执行时间。在多模态训练中,你会发现大量的计算耗时在 MatMul 和 FlashAttentionVarLen 上,这说明计算是密集的,而不是卡在 IO 上。
七、效果验证
训练完几个 epoch 后,我们需要把权重转回 HF 格式(使用对应的逆向转换脚本),然后起一个简单的推理脚本来验证。
测试用例: 输入一张这几天很火的“雪地里的哈士奇”图片。 Prompt: “Describe this image in detail.”
模型输出(Ascend 910B 推理结果):
“The image features a husky dog running joyfully in a snowy field. The dog has black and white fur and blue eyes…”

看到这个输出,我就知道这次“炼丹”成功了。
八、总结与展望
这几天在昇腾上折腾 MindSpeed-MM,最大的感受就是:坑确实有,但路已经通了。
相比于一年前还要自己手写算子适配,现在 MindSpeed-MM 基本上把脏活累活都干完了。对于想在国产算力上布局多模态大模型的团队来说,这绝对是目前最佳的切入点。
几个核心建议:
- 环境隔离:不同版本的 CANN 包尽量用 Docker 隔离,不然环境变量会教你做人。
- 数据质量:多模态模型对数据非常敏感,清洗逻辑比调参更重要。
- 关注社区:MindSpeed-MM 的更新频率很高,遇到问题多去 Issue 区看看,很多时候是因为代码没拉到最新。
下一步,我准备研究一下 MindSpeed-MM 里的 Video-LLM 训练,听说支持视频理解了,到时候再来给大家汇报战况!
参考资料
- 昇腾 CANN 官方文档
- MindSpeed-MM 代码仓: https://gitcode.com/Ascend/MindSpeed-MM
- Megatron-LM 论文
注明:昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 19
19 1
1- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)