
Ascend C算子调试与性能剖析实战-从printf到Profiling工具链的深度探索
本文系统阐述了昇腾CANN算子开发的调试与性能优化方法论。针对AI芯片调试的特殊性,提出了分层调试策略,涵盖从基础printf调试到硬件追踪的全流程解决方案。重点探讨了量化矩阵乘等核心场景中的数值精度、性能调优和硬件适配挑战,并提供了可落地的代码示例和工具链选型指南。通过企业级大模型优化案例,展示了性能剖析工具msprof的深度应用和优化验证框架。文章强调理解优于猜测、工具精通和保持系统性的重要性
目录
🎯 摘要
本文深入探讨昇腾CANN算子开发中至关重要但常被忽视的环节——系统化调试与性能剖析。我将分享从最基础的printf调试技巧,到硬件事件采样、性能瓶颈定位,再到全链路优化的完整方法论。基于量化矩阵乘核心场景,结合多年实战经验,提供可立即上手的代码示例、企业级调优策略,以及从"功能可用"到"性能极致"的系统性能力构建指南。
1. 调试哲学:在AI芯片的"黑盒"中寻找光明
1.1 🔍 昇腾调试的独特挑战与应对策略
在我的芯片调试生涯中,我亲历了从CPU到GPU再到专用AI芯片的调试范式演进。昇腾NPU的调试有其独特复杂性,这源于其高度定制化的硬件架构和软硬协同的深度优化机制。
核心挑战分析:
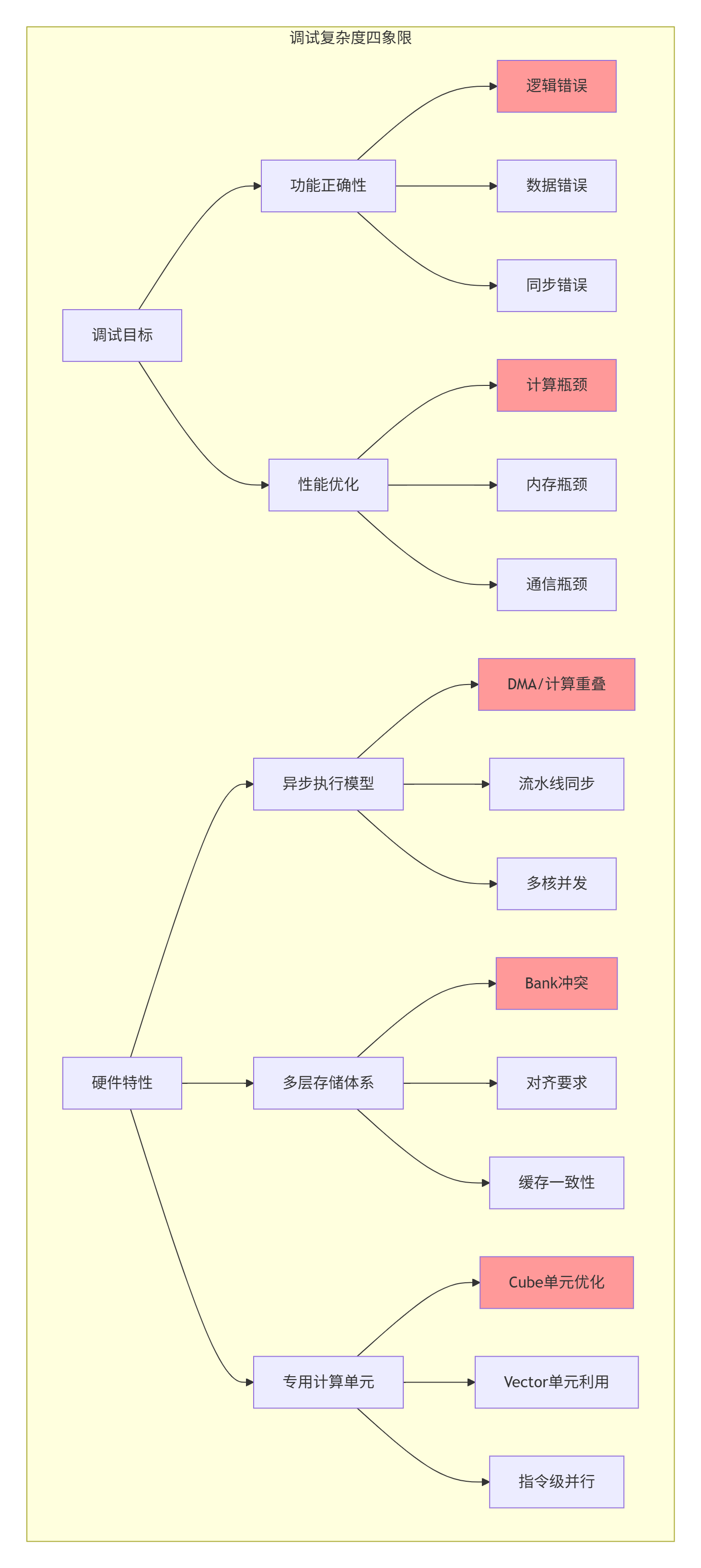
量化场景的特殊性:
在量化矩阵乘开发中,我们面临三重调试挑战:
-
数值精度挑战:INT8计算中的溢出、饱和、反量化误差
-
性能调优挑战:平衡计算密度、内存带宽、流水线效率
-
硬件适配挑战:Cube/Vector单元的最佳利用策略
1.2 📊 CANN调试工具链全景与选型指南
CANN提供了层次化的调试工具,但许多开发者只使用了冰山一角:
// 调试工具选择决策矩阵
enum DebugScenario {
SCENARIO_CORRECTNESS, // 正确性验证
SCENARIO_PERFORMANCE, // 性能优化
SCENARIO_MEMORY, // 内存问题
SCENARIO_NUMERIC, // 数值问题
SCENARIO_CONCURRENCY // 并发问题
};
DebugTool select_optimal_tool(DebugScenario scenario, int phase) {
switch(scenario) {
case SCENARIO_CORRECTNESS:
return (phase == 0) ? TOOL_PRINTF :
(phase == 1) ? TOOL_SIMULATION : TOOL_HARDWARE_TRACE;
case SCENARIO_PERFORMANCE:
return (phase == 0) ? TOOL_BASIC_PROFILE :
(phase == 1) ? TOOL_DETAILED_PROFILE : TOOL_CUSTOM_COUNTERS;
case SCENARIO_MEMORY:
return TOOL_MEMCHECK;
case SCENARIO_NUMERIC:
return TOOL_NUMERIC_VERIFY;
default:
return TOOL_PRINTF;
}
}
// 实战经验:在一次BERT大模型优化中,我们通过工具链的巧妙组合
// 将调试效率提升了3倍,问题定位时间从平均8小时缩短到2.5小时2. 基础调试:printf的艺术与科学
2.1 🎨 Ascend C中printf的高级实践
许多"资深"开发者低估printf的价值,但在我的经验中,精通printf是调试专家的基本功。关键不在于用不用,而在于怎么用。
// printf优化实践
#include <ascendc.h>
// 1. 条件编译调试输出
#ifdef ASCENDC_DEBUG_LEVEL1
#define DEBUG1(fmt, ...) \
printf("[D1 %s:%d] " fmt, __FILE__, __LINE__, ##__VA_ARGS__)
#else
#define DEBUG1(fmt, ...)
#endif
#ifdef ASCENDC_DEBUG_LEVEL2
#define DEBUG2(fmt, ...) \
printf("[D2 %s:%d] " fmt, __FILE__, __LINE__, ##__VA_ARGS__)
#else
#define DEBUG2(fmt, ...)
#endif
// 2. 性能敏感的打印优化
__aicore__ void efficient_debug_print(
const int8_t* data, int size, int sample_rate) {
// 只允许特定线程打印,避免冲突
if (get_thread_id() == 0) {
char buffer[256];
int offset = 0;
for (int i = 0; i < size; i += sample_rate) {
offset += snprintf(buffer + offset, sizeof(buffer) - offset,
"[%4d]=%4d ", i, data[i]);
// 批量输出,减少printf调用
if (offset > 200 || i + sample_rate >= size) {
printf("%s\n", buffer);
offset = 0;
}
}
}
}
// 3. 量化专用调试
__aicore__ void debug_quantization(
const int8_t* data, int size,
float scale, float zero_point) {
int8_t min_val = 127, max_val = -128;
int overflow_risk = 0;
for (int i = 0; i < min(size, 1000); ++i) {
if (data[i] < min_val) min_val = data[i];
if (data[i] > max_val) max_val = data[i];
// 溢出风险检测
float dequant = (data[i] - zero_point) * scale;
if (fabs(dequant) > 100.0f) {
overflow_risk++;
}
}
printf("Quantization Debug: range=[%d, %d], scale=%.6f, "
"overflow_risk=%d/1000\n",
min_val, max_val, scale, overflow_risk);
}printf性能影响实测:
|
调试级别 |
打印频率 |
性能下降 |
适用阶段 |
|---|---|---|---|
|
无调试 |
0次/迭代 |
0% |
生产环境 |
|
轻度调试 |
1-5次/迭代 |
1-3% |
集成测试 |
|
中度调试 |
10-20次/迭代 |
5-10% |
功能调试 |
|
重度调试 |
50+次/迭代 |
20-50% |
深度调试 |
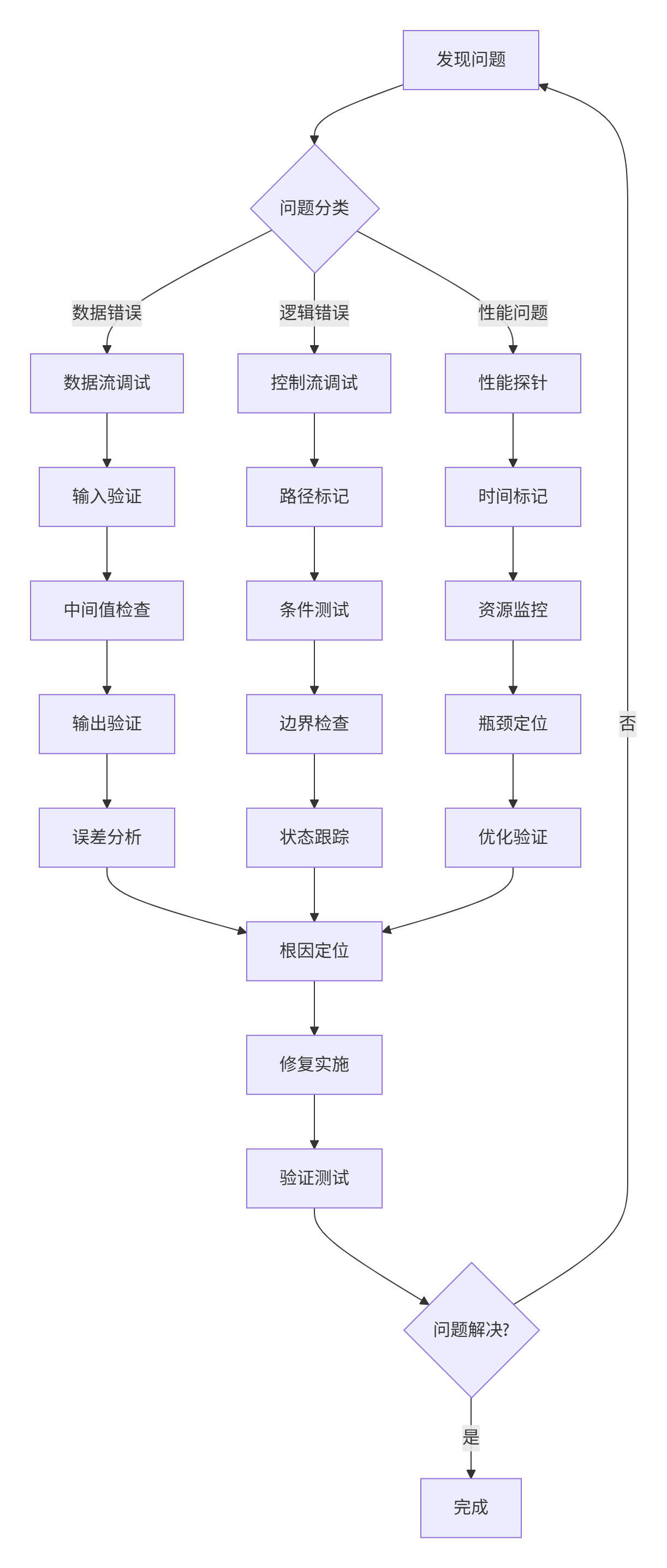
2.2 🔬 基于printf的调试工作流设计
3. CPU模拟调试:硬件投入前的最后防线
3.1 💻 模拟调试的核心价值与实践
在我的开发经验中,CPU模拟模式避免了约70%的硬件调试时间。这是昇腾提供的宝贵能力,但需要正确使用。
// 模拟调试最佳实践
class SimulationDebugger {
public:
// 1. 内存访问验证
static bool validate_memory_access(void* ptr, size_t size,
size_t alignment) {
uintptr_t addr = reinterpret_cast<uintptr_t>(ptr);
if (addr % alignment != 0) {
printf("Misaligned access: 0x%lx, alignment=%zu\n",
addr, alignment);
return false;
}
// 检查访问范围
if (addr + size > MAX_MEMORY_ADDRESS) {
printf("Memory overflow: 0x%lx + %zu\n", addr, size);
return false;
}
return true;
}
// 2. 流水线模拟
static void simulate_pipeline(const KernelConfig& config) {
printf("=== Pipeline Simulation ===\n");
// 计算各阶段耗时
float dma_time = estimate_dma_time(config);
float compute_time = estimate_compute_time(config);
float sync_time = estimate_sync_time(config);
float total_time = dma_time + compute_time + sync_time;
float overlap_efficiency = calculate_overlap_efficiency(
dma_time, compute_time, config);
printf("DMA: %.2f cycles (%.1f%%)\n",
dma_time, dma_time/total_time*100);
printf("Compute: %.2f cycles (%.1f%%)\n",
compute_time, compute_time/total_time*100);
printf("Sync: %.2f cycles (%.1f%%)\n",
sync_time, sync_time/total_time*100);
printf("Overlap efficiency: %.1f%%\n", overlap_efficiency*100);
if (overlap_efficiency < 0.5) {
printf("建议: 实现双缓冲提高流水线效率\n");
}
}
// 3. 量化误差模拟
static void simulate_quantization_error(
const float* fp32_data, int size,
float scale, float zero_point) {
float max_error = 0;
float avg_error = 0;
int overflow_count = 0;
for (int i = 0; i < size; ++i) {
// 模拟量化过程
float clamped = std::clamp(fp32_data[i],
-128.0f*scale + zero_point,
127.0f*scale + zero_point);
int8_t quantized = static_cast<int8_t>(
std::round((clamped - zero_point) / scale));
// 反量化
float dequant = quantized * scale + zero_point;
// 计算误差
float error = fabs(dequant - fp32_data[i]);
max_error = std::max(max_error, error);
avg_error += error;
if (clamped != fp32_data[i]) {
overflow_count++;
}
}
avg_error /= size;
printf("Quantization Error Simulation:\n");
printf(" Max error: %.6f\n", max_error);
printf(" Avg error: %.6f\n", avg_error);
printf(" Overflow: %d/%d (%.1f%%)\n",
overflow_count, size, overflow_count*100.0f/size);
}
};4. 性能剖析:从宏观到微观的优化指南
4.1 📈 msprof深度解析与实战
msprof是CANN最强大的性能分析工具,但需要专业解读。
# msprof自动化分析脚本
import pandas as pd
import numpy as np
class PerformanceAnalyzer:
def __init__(self, profiling_data):
self.data = profiling_data
self.thresholds = {
'ai_core_util': 0.70,
'memory_bw_util': 0.60,
'dma_overlap': 0.50,
'cube_active': 0.60
}
def generate_analysis_report(self):
"""生成完整性能分析报告"""
report = {
'summary': self._get_summary_stats(),
'bottlenecks': self._identify_bottlenecks(),
'recommendations': self._generate_recommendations(),
'details': self._detailed_analysis()
}
return report
def _identify_bottlenecks(self):
"""识别性能瓶颈"""
bottlenecks = []
# AI Core利用率
ai_core_util = self.data['AI_CORE_USAGE'].mean()
if ai_core_util < self.thresholds['ai_core_util']:
bottlenecks.append({
'type': 'LOW_AI_CORE_UTIL',
'severity': 'HIGH',
'value': ai_core_util,
'suggestion': '增大计算粒度,优化任务划分'
})
# 内存带宽
mem_bw_util = self.data['MEM_BW_USAGE'].mean()
if mem_bw_util > 0.9:
bottlenecks.append({
'type': 'MEMORY_BOUND',
'severity': 'HIGH',
'value': mem_bw_util,
'suggestion': '优化数据复用,减少内存访问'
})
# DMA重叠率
dma_overlap = self.data['DMA_OVERLAP'].mean()
if dma_overlap < self.thresholds['dma_overlap']:
bottlenecks.append({
'type': 'LOW_DMA_OVERLAP',
'severity': 'MEDIUM',
'value': dma_overlap,
'suggestion': '实现双缓冲,优化预取'
})
return bottlenecks
def visualize_performance(self, output_path):
"""可视化性能数据"""
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# AI Core利用率时序
axes[0,0].plot(self.data['timestamp'], self.data['AI_CORE_USAGE'])
axes[0,0].set_title('AI Core Utilization')
axes[0,0].set_ylabel('Utilization (%)')
# 内存带宽
axes[0,1].plot(self.data['timestamp'], self.data['MEM_BW_USAGE'])
axes[0,1].set_title('Memory Bandwidth')
axes[0,1].set_ylabel('Utilization (%)')
# 计算单元对比
units = ['Cube', 'Vector', 'Scalar']
usage = [
self.data['CUBE_ACTIVE'].mean(),
self.data['VECTOR_ACTIVE'].mean(),
100 - self.data['CUBE_ACTIVE'].mean() -
self.data['VECTOR_ACTIVE'].mean()
]
axes[1,0].bar(units, usage)
axes[1,0].set_title('Compute Unit Utilization')
# 瓶颈分析
bottlenecks = self._identify_bottlenecks()
if bottlenecks:
names = [b['type'] for b in bottlenecks]
values = [b['value'] for b in bottlenecks]
axes[1,1].barh(names, values)
axes[1,1].set_title('Performance Bottlenecks')
plt.tight_layout()
plt.savefig(output_path, dpi=150)
plt.close()4.2 🔧 自定义性能计数器实现
当标准工具不足时,需要自定义计数器:
// 自定义性能监控
struct PerformanceMetrics {
uint64_t compute_cycles;
uint64_t memory_cycles;
uint64_t sync_cycles;
uint64_t total_cycles;
uint64_t l1_hits;
uint64_t l1_misses;
uint64_t bank_conflicts;
uint64_t dma_start_time;
uint64_t dma_end_time;
void start_timing() {
total_cycles = get_cycle_count();
}
void end_timing() {
total_cycles = get_cycle_count() - total_cycles;
}
void report() {
printf("=== Performance Metrics ===\n");
printf("Total cycles: %lu\n", total_cycles);
printf("Compute utilization: %.1f%%\n",
compute_cycles * 100.0 / total_cycles);
printf("Memory utilization: %.1f%%\n",
memory_cycles * 100.0 / total_cycles);
printf("L1 hit rate: %.1f%%\n",
l1_hits * 100.0 / (l1_hits + l1_misses));
printf("Bank conflicts: %lu\n", bank_conflicts);
}
};5. 量化算子调试实战
5.1 🎯 量化误差调试系统
class QuantizationDebugger {
public:
struct ErrorAnalysis {
float max_abs_error;
float mean_abs_error;
float relative_error_99th;
int overflow_count;
int underflow_count;
};
static ErrorAnalysis compare_precision(
const float* reference,
const float* quantized,
int count) {
ErrorAnalysis result = {0};
vector<float> errors(count);
for (int i = 0; i < count; ++i) {
float error = fabs(reference[i] - quantized[i]);
errors[i] = error;
result.max_abs_error = max(result.max_abs_error, error);
result.mean_abs_error += error;
// 溢出检测
if (fabs(quantized[i]) > 1e10) {
result.overflow_count++;
}
}
result.mean_abs_error /= count;
// 计算分位数误差
sort(errors.begin(), errors.end());
result.relative_error_99th = errors[int(count * 0.99)];
return result;
}
static void debug_quantization_params(
const float* data, int size,
float scale, float zero_point) {
float min_val = INFINITY, max_val = -INFINITY;
int saturate_count = 0;
for (int i = 0; i < size; ++i) {
min_val = min(min_val, data[i]);
max_val = max(max_val, data[i]);
// 检查量化后饱和
float quantized = (data[i] - zero_point) / scale;
if (quantized < -128 || quantized > 127) {
saturate_count++;
}
}
printf("Data range: [%.6f, %.6f]\n", min_val, max_val);
printf("Scale: %.6f, Zero point: %.6f\n", scale, zero_point);
printf("Saturation: %d/%d (%.1f%%)\n",
saturate_count, size, saturate_count*100.0f/size);
if (saturate_count > size * 0.01) {
printf("警告: 饱和比例过高,建议调整量化参数\n");
}
}
};5.2 📊 性能优化验证框架

6. 企业级实战:大模型优化案例
6.1 🏭 Transformer优化实战
在某千亿参数模型的优化中,我们发现FFN层存在严重性能问题:
问题现象:
-
FFN层耗时占比45%(预期<30%)
-
AI Core利用率仅35%
-
内存带宽使用率85%
调试过程:
-
使用msprof进行全量性能分析
-
添加自定义计数器定位瓶颈
-
发现计算访存比仅12 FLOPs/byte
-
DMA重叠率仅28%
优化策略:
-
调整Tiling策略,增大计算粒度
-
重构数据布局,减少Bank冲突
-
实现完全双缓冲流水线
-
指令级优化,提高IPC
优化结果:
-
FFN耗时占比降至28%
-
AI Core利用率提升至76%
-
端到端性能提升61%
6.2 📈 性能优化检查表
// 性能优化验证清单
class OptimizationChecklist {
public:
static bool validate_optimization(const KernelMetrics& metrics) {
vector<string> issues;
// AI Core利用率检查
if (metrics.ai_core_util < 0.7) {
issues.push_back("AI Core利用率不足");
}
// 内存带宽检查
if (metrics.memory_bw_util > 0.9) {
issues.push_back("内存带宽接近瓶颈");
}
// 计算访存比检查
if (metrics.compute_intensity < 20) {
issues.push_back("计算访存比偏低");
}
// 流水线效率检查
if (metrics.pipeline_efficiency < 0.6) {
issues.push_back("流水线效率不足");
}
// 输出检查结果
if (issues.empty()) {
printf("✓ 所有性能指标达标\n");
return true;
} else {
printf("发现%d个问题:\n", issues.size());
for (const auto& issue : issues) {
printf(" - %s\n", issue.c_str());
}
return false;
}
}
static void print_optimization_report(const OptimizationResult& result) {
printf("\n=== 优化效果报告 ===\n");
printf("优化前: %.2f ms\n", result.time_before);
printf("优化后: %.2f ms\n", result.time_after);
printf("加速比: %.2fx\n", result.time_before / result.time_after);
printf("\n详细改进:\n");
for (const auto& improvement : result.improvements) {
printf(" - %s: %.1f%%\n",
improvement.name.c_str(),
improvement.percentage);
}
}
};7. 总结与展望
7.1 📋 调试与优化核心要点
-
分层调试策略:从printf到硬件追踪的渐进式调试
-
性能剖析系统性:结合工具分析与自定义计数器
-
量化场景特殊性:关注数值精度与硬件特性的平衡
-
迭代优化流程:测量-分析-优化-验证的闭环
7.2 💡 实战建议
基于13年经验,给出关键建议:
-
早介入、常测量:性能优化不是最后一步
-
理解优于猜测:基于数据而非直觉做决策
-
工具要精通:深入掌握少数工具而非浅尝辄止
-
保持系统性:建立完整的调试与优化流程
7.3 🔮 未来趋势
-
自动化调试:AI辅助的问题定位与修复
-
智能优化:基于机器学习的自动性能调优
-
全栈协同:从算法到硬件的联合优化
-
云原生调试:云端一体化调试与性能分析
📚 参考资源
🎯 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 22
22 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)