
在大模型推理中避开 HostBound:一次IRQ中断-绑核优化的完整实战
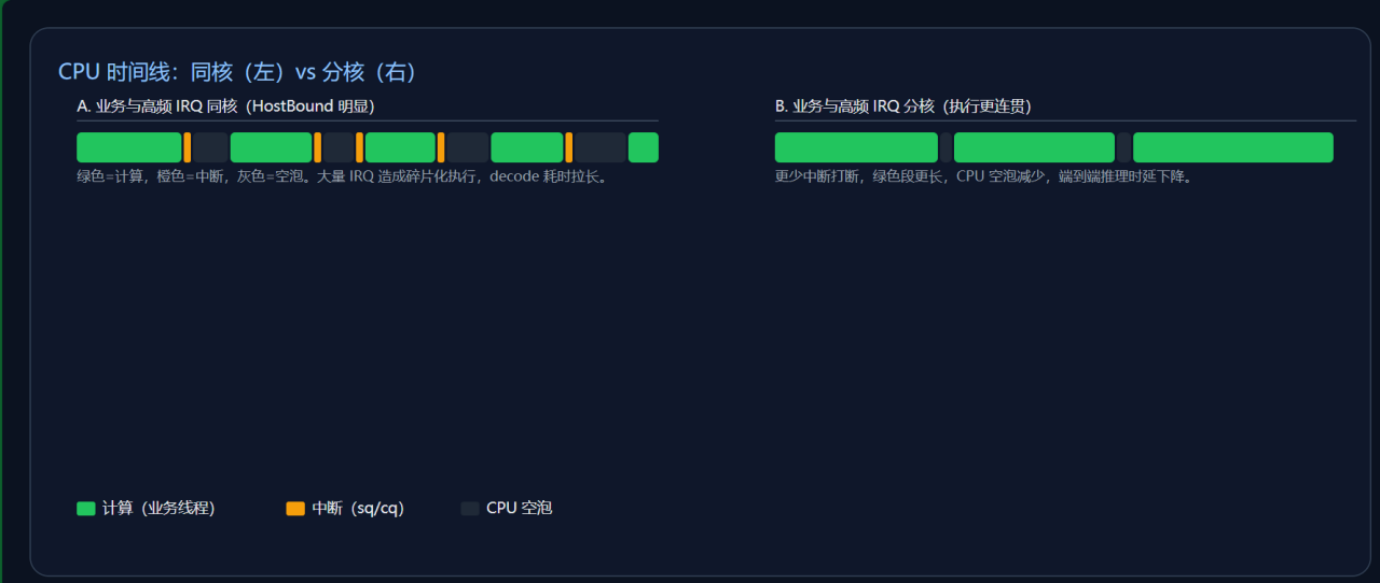
A 组(分离):Node@launch 正常,中断对业务线程干扰小,CPU 空泡可控。B 组(同核):Node@launch 略增,但更关键的是CPU 空泡显著增大。在我们样本中,推理过程中一秒内发生了两万次中断,业务线程被持续打断,decode 阶段耗时明显拉长。中断-业务同核是 HostBound 的重要诱因;只要把高频 IRQ 和核心推理线程错开,就能显著改善 Host 侧连贯性。
在大模型推理中避开 HostBound:一次IRQ中断-绑核优化的完整实战
在大模型推理场景,Host(CPU)侧常见的 HostBound 问题,往往不是算力不够,而是中断(IRQ)把计算线程不断打断。
当 NPU 触发的 sq_send_trigger_irq / cq_update_irq 等高频中断,与业务线程恰好落在同一 CPU 核上时,CPU 侧就会出现密集空泡,推理耗时被拉长。本文基于 800I(A2-A+K)平台的实测,从 中断与 irqbalance 机制 入手,给出 定位-验证-改进 的闭环方案:
1)识别并统计 NPU 相关中断
2)理解 irqbalance 如何调度中断
3)在 NUMA 约束下进行合理绑核
4)给出 实验复现与结果对比
5)沉淀 工程化清单 方便落地。
1. 为什么会 HostBound?
大模型推理过程中,Host 侧会不断向设备侧下发算子并收取完成事件。
底层驱动在下发阶段触发 sq_send_trigger_irq,在完成阶段触发 cq_update_irq。
如果这些高频中断与我们的推理线程绑定在同一颗 CPU 核上,那么每次中断到来都会打断当前执行流,哪怕中断处理只有微秒级,也会在高频触发下造成显著的 HostBound。
|
典型误区:看到CPU 使用率不高就以为 Host 侧没问题。 实际上 irq 处理优先级高,中断密度才是关键变量——它会无视你是否在跑计算密集任务。 |
2. 环境与版本
硬件与系统
- 800I(A2-A + K,8 卡 × 64GB)
- openEuler 22.03 LTS
- 驱动:25.0.rc1.1
- Python:3.11.10
关键软件

点击图片可查看完整电子表格
|
后续在其他版本上复现时,注意对应驱动/CANN/框架的兼容矩阵,优先参考官方兼容口径。 |
3. 基础知识:中断与 irqbalance
- 设备侧向 CPU 发出“我有事要处理”的信号,CPU 立即打断当前执行,转去跑中断处理程序(ISR)。
- 对推理/训练这类实时性强、密集通信的工作负载,高频中断会显著影响 Host 侧连续执行。
3.2 /proc/interrupts 的含义
/proc/interrupts 展示了 IRQ ID → 各 CPU 上的计数,并包含控制器类型、触发方式、源名称等。关键字段速查:

点击图片可查看完整电子表格
- 守护进程,定期(默认 10s)扫描 /proc/interrupts,在NUMA 拓扑约束下把中断尽可能均匀分散到不同 CPU 核。
- 它不关注你那个核是否在跑计算密集任务,只看中断分布是否均衡。
- 绑定通过写 /proc/irq/<IRQ ID>/smp_affinity 完成;若关闭 irqbalance,该值就不会被它改写。
|
对于高频 NPU 中断,不要让它和推理线程落在同一个核;对齐 NUMA,减少跨节点访问延迟。 |

4. 实战定位:找到 NPU 的中断集合
- 由命令ls /sys/bus/pci/devices/<bus id>/msi_irqs(内核接口)我们可以看到对应物理设备所有中断的 IRQ ID
- 由命令cat /proc/interrupts | grep sq_send_trigger_irq | cut -d: -f1我们可以看到所有 NPU 卡的 sq_send_trigger_irq 中断 ID,每个 NPU 设备会有1个 sq_send_trigger_irq 中断和16个 cq_update_irq,但一般中断发生频率较高的只有 sq_send_trigger_irq 和第一个 cq_update_irq (sq_send_trigger_irq 的 IRQ ID + 1)
- 对照2中每张NPU卡的irq范围以及3中所有NPU卡的sq_send_trigger_irq中断号可以识别到每张NPU卡的关键sq、cq中断号
4.2 扒出 NPU 相关的 IRQ ID
1)查起始 IRQ(命名依环境不同,如 devdrv_load_irq):
|
Bash |
2)再在 /proc/interrupts 中按需筛选关键 NPU 中断源(如 sq_send_trigger_irq、cq_update_irq、消息通道通知等),观察它们在各 CPU 的触发计数。
|
把同一张卡的一组 IRQ ID 收集到列表中,后续统一绑核/统一 banirq 友好得多。 |
5. 绑核方法与 irqbalance 配置
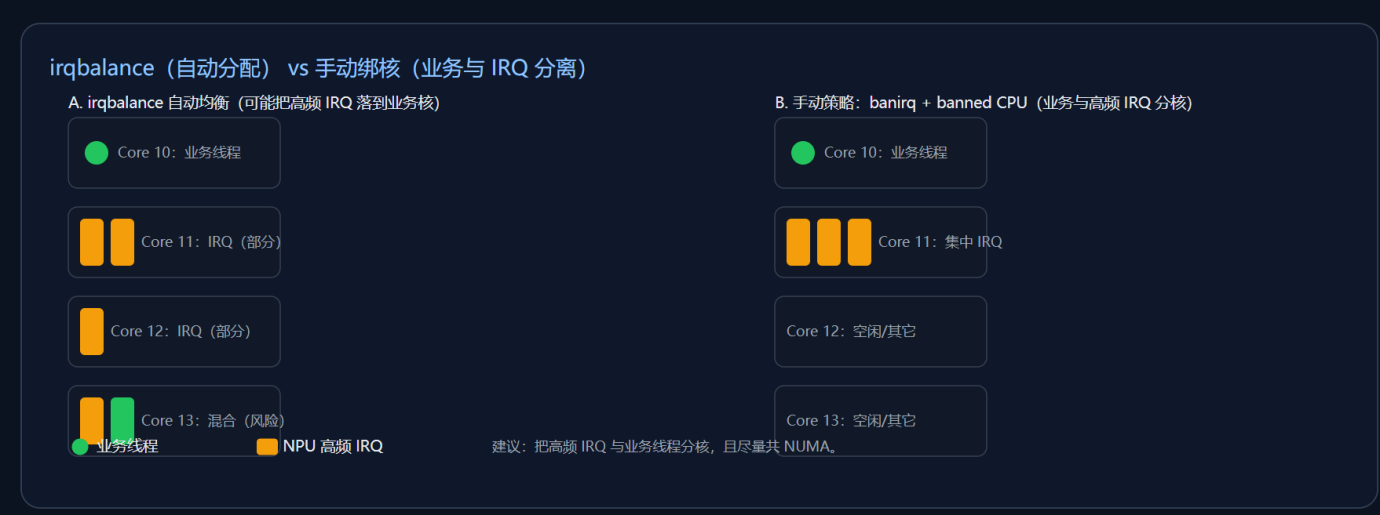
- 直接停掉 irqbalance(粗暴稳定)
|
Bash |
优点:你的中断绑定不会被自动改写,稳定性高。
缺点:全局中断不再动态均衡,系统整体中断负载可能失衡,系统性风险上升。
- 拉长 irqbalance 周期(折中)
|
Bash |
优点:将重平衡周期从默认的 10 秒延长至 300 秒,减少对关键路径的干扰。
补充说明:irqbalance 是一个普通优先级的守护进程,在系统 CPU 负载较高时,其实际执行间隔可能略大于设定值(如 300 秒),但偏差通常不大;只要系统中没有实时进程(SCHED_FIFO/SCHED_RR)或通过 chrt 修改过调度策略的高优先级任务,irqbalance 仍能较快获得 CPU 时间完成中断重分配。
- 精细化封印策略(推荐)
禁止特定 CPU或特定 IRQ参与自动分配,既保留 irqbalance 的全局均衡,又保护关键核/关键中断不被动:
|
Bash # RHEL/CentOS: /etc/sysconfig/irqbalance # Debian/Ubuntu: /etc/default/irqbalance IRQBALANCE_BANNED_CPULIST="10,11" # 这些 CPU 不会被分配任何中断 IRQBALANCE_ARGS="--banirq=1144,1145,..." # 这些 IRQ 不参与自动分配 |
然后重启服务使配置生效:
|
Bash systemctl restart irqbalance |
|
建议顺序:先 banirq(保护 NPU 高频 IRQ)→ 再 banned CPU(保护业务线程核)→ 必要时再停服务。 |
6. 实验复现与结果
下面示例用循环 POST 触发高频算子下发(仅示意,按你环境改 URL / 模型)并周期打印目标 IRQ 的分布:
|
Bash |
- 环境:两卡空载,qwen2.5-7B 推理。
- 使用 export CPU_AFFINITY_CONF=1,npu2:10,npu3:11 约束 算子执行的业务线程 到指定 CPU。
- 分两组实验:
A:NPU2 的高频中断 不与 业务线程落在同一核;
B:NPU2 的高频中断 与 业务线程同核(如都在 CPU10)。
- 观察项:profiling 中 Node@launch、CPU idle/空泡、单位时间内中断触发次数等。
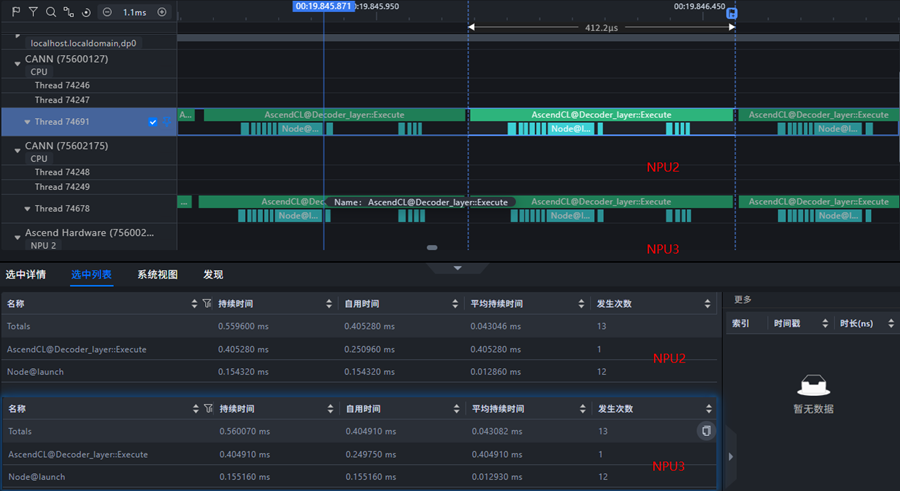
- A 组(分离):Node@launch 正常,中断对业务线程干扰小,CPU 空泡可控。
- B 组(同核):Node@launch 略增,但更关键的是 CPU 空泡显著增大。在我们样本中,推理过程中一秒内发生了两万次中断,业务线程被持续打断,decode 阶段耗时明显拉长。
|
结论:中断-业务同核 是 HostBound 的重要诱因;只要把高频 IRQ 和核心推理线程错开,就能显著改善 Host 侧连贯性。 |
7. 工程化落地清单(Checklist)
识别阶段
- 用 dmesg + npu-smi info 对齐 NPU ↔ Bus-ID ↔ 注册顺序
- 在 /proc/interrupts 中收集 NPU 高频中断(sq_send_trigger_irq / cq_update_irq / 消息通道等)
- 建立 卡级 IRQ 列表,用于统一 ban/统一绑核
策略阶段
- 选择策略:banirq(推荐)/ banned CPU / 停掉 irqbalance
- 约束 业务线程核(环境变量、任务集、或 taskset/cset)与中断核不重叠
- NUMA 亲和:尽量让业务线程与其服务的 NPU 的 IRQ 在同一 NUMA,减少跨节点
验证阶段
- 期间观测 /proc/interrupts 中目标 IRQ 的 CPU 分布是否稳定
- profiling 核查:Node@launch、CPU 空泡、单位时间中断数、端到端延迟
- 记录基线(优化前)与对比(优化后)
维护阶段
- 版本升级/内核更新后,重新校验 IRQ 命名与分布
- 新增卡/更换拓扑后,重做一次识别与策略回放
- 将 IRQ 列表/绑核规则 收进 CMDB/Ansible,变更可审计、可回滚
8. 常见问答(FAQ)
Q1:irqbalance 一定要关吗?
不一定。优先用 --banirq + BANNED_CPULIST 精细化控制,让全局仍保持均衡,只屏蔽关键中断/关键 CPU。仅在确实需要完全手控时,才考虑停服务。
Q2:如何选择被“保护”的 CPU?
- 先看业务线程的亲和核(或它所在 NUMA)
- 再观察目标 IRQ 的触发密度
- 原则:错开 + 同 NUMA 优先
Q3:为什么我绑核后效果一般?
排查:
1)是否只绑了一部分高频 IRQ;
2)irqbalance 是否把你的绑定改走了(没做 banirq);
3)业务线程是否真的按预期落在指定核;
4)模型/框架本身是否引入了其他 Host 侧瓶颈(I/O、日志、频繁小 alloc 等)。
9. 结论
在大模型推理/训练场景,高频 NPU 中断若与业务线程落在同一 CPU 核,极易诱发 HostBound。
最佳实践是:
- 识别 NPU 高频 IRQ →
- 用 banirq / banned CPU 精细化约束 →
- 在 NUMA 友好前提下让中断与业务线程错核 →
- 用 profiling 与 /proc/interrupts 量化验证。
按本文清单落地后,你会发现:不动模型参数、不改引擎栈,仅靠“中断-绑核”这一项,也能让 Host 侧的一致性和端到端时延肉眼可见地稳定下来。
|
Bash |
另外需要说明的是:
昇腾PAE案例库对本文写作亦有帮助

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)