《深入Ascend C(上):从零构建你的第一个高性能算子》
本文将作为《深入Ascend C》系列的第一篇,带领读者从零开始,系统性地理解Ascend C的核心设计理念、内存模型、数据搬运机制,并手把手实现一个经典的Vector Add(向量加法)算子,为后续更复杂的算子开发奠定坚实基础。在AI模型训练与推理的浪潮中,硬件性能的提升是永恒的主题。真实的AI算子(如Conv2D, MatMul)远比Vector Add复杂,它们需要更精细的数据排布(tili
摘要:昇腾AI处理器是华为打造的全栈AI计算基础设施的核心。为了充分释放其硬件潜力,开发者需要一种既能贴近硬件、又能兼顾开发效率的编程范式。Ascend C应运而生,它作为昇腾CANN(Compute Architecture for Neural Networks)软件栈中的核心编程语言,为开发者提供了直接操控AI Core(达芬奇架构)的强大能力。本文将作为《深入Ascend C》系列的第一篇,带领读者从零开始,系统性地理解Ascend C的核心设计理念、内存模型、数据搬运机制,并手把手实现一个经典的Vector Add(向量加法)算子,为后续更复杂的算子开发奠定坚实基础。
一、引言:为何需要Ascend C?
在AI模型训练与推理的浪潮中,硬件性能的提升是永恒的主题。然而,硬件性能的发挥极度依赖于上层软件的优化。传统的通用编程语言(如Python、C++)虽然开发便捷,但难以精确控制昇腾AI Core内部的复杂计算单元(如Vector、Cube计算单元)和多级缓存体系(Global Memory, L1/L0 Buffer)。这导致了巨大的性能鸿沟。
华为推出的Ascend C,本质上是一种领域特定语言(DSL),它巧妙地融合了C/C++的语法习惯与昇腾硬件的并行计算特性。通过提供一套精简但强大的API,Ascend C允许开发者以近乎“手写汇编”的精度来调度硬件资源,同时又避免了直接编写底层汇编代码的繁琐与晦涩。掌握Ascend C,是成为昇腾生态高级开发者的必经之路。
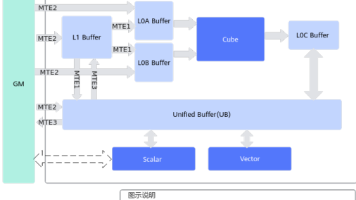
二、Ascend C核心概念全景图
在动手编码之前,我们必须先建立对Ascend C运行环境和核心组件的宏观认知。
-
AI Core架构概览: 昇腾AI Core采用达芬奇3D Cube架构,其核心计算单元包括:
- Scalar Unit (标量单元):负责地址计算、循环控制等逻辑。
- Vector Unit (向量单元):处理1D/2D向量数据的计算,如加减乘除、激活函数等。
- Cube Unit (矩阵计算单元):专为GEMM(通用矩阵乘法)设计,是AI计算的绝对主力。
- Unified Buffer (UB):片上高速缓存,分为L1和L0两级,是数据搬运的核心枢纽。
- MTE (Memory Transfer Engine):独立的DMA引擎,负责在Global Memory和UB之间高效搬运数据,与计算单元并行工作。
-
Ascend C的执行模型: Ascend C程序的执行单位是Kernel(核函数)。一个完整的算子通常由一个或多个Kernel组成。每个Kernel在AI Core上以Block为单位并行执行。一个Block内部又包含多个Thread(线程),这些线程共享同一个Scalar指令流,但可以操作不同的数据(SIMT模型)。
-
核心抽象对象:
GlobalTensor:代表位于设备全局内存(Global Memory)中的张量。LocalTensor:代表位于片上缓存(Unified Buffer)中的张量。Pipe:数据管道,用于在Scalar、Vector、MTE等不同执行单元之间传递数据和同步。这是Ascend C实现计算与数据搬运重叠(Overlap)的关键。
三、动手实践:实现Vector Add算子
理论是灰色的,实践之树常青。现在,让我们通过一个最基础但也最能体现Ascend C精髓的Vector Add算子,来感受其开发流程。
算子描述:给定两个输入向量A和B,以及一个输出向量C,计算 C[i] = A[i] + B[i]。
开发步骤:
第一步:定义算子接口(Host侧)
在正式编写Kernel之前,我们需要在Host(CPU)侧定义算子的元信息,包括输入输出的形状、数据类型等。这部分通常使用Python或C++配合自定义算子注册框架完成。此处我们聚焦于Device(AI Core)侧的Kernel实现。
第二步:编写Kernel函数(Device侧)
这是Ascend C的核心。我们将遵循“分块-搬运-计算-回写”的经典模式。
1#include "kernel_operator.h"
2
3using namespace AscendC;
4
5// 定义常量
6const int32_t BLOCK_NUM = 8; // 启动8个Block并行处理
7const int32_t TOTAL_LENGTH = 512 * 1024; // 总数据长度
8const int32_t TILE_NUM = 8; // 每个Block处理8个Tile
9const int32_t BLOCK_LENGTH = TOTAL_LENGTH / BLOCK_NUM; // 每个Block处理的数据量
10const int32_t TILE_LENGTH = 128; // 每个Tile的大小(128个float)
11
12extern "C" __global__ __aicore__ void VectorAddCustom(GM_ADDR x, GM_ADDR y, GM_ADDR z) {
13 // 1. 获取当前Block的ID
14 uint32_t blockId = GetBlockIdx();
15
16 // 2. 计算当前Block负责处理的数据起始地址
17 uint64_t offset = blockId * BLOCK_LENGTH;
18 GM_ADDR xGm = x + offset;
19 GM_ADDR yGm = y + offset;
20 GM_ADDR zGm = z + offset;
21
22 // 3. 初始化Pipeline管理器
23 // 创建三条独立的数据管道,用于解耦数据搬运和计算
24 TPipe pipeInX;
25 TPipe pipeInY;
26 TPipe pipeOut;
27 pipeInX.InitBuffer(1, TILE_LENGTH * sizeof(float)); // 为X分配1个队列槽位
28 pipeInY.InitBuffer(1, TILE_LENGTH * sizeof(float)); // 为Y分配1个队列槽位
29 pipeOut.InitBuffer(1, TILE_LENGTH * sizeof(float)); // 为输出分配1个队列槽位
30
31 // 4. 声明片上缓存(LocalTensor)
32 // 使用QueInc/QueOut来管理UB中的数据队列
33 LocalTensor<float> xLocal = LocalTensor<float>(QueInc(&pipeInX, 1));
34 LocalTensor<float> yLocal = LocalTensor<float>(QueInc(&pipeInY, 1));
35 LocalTensor<float> zLocal = LocalTensor<float>(QueInc(&pipeOut, 1));
36
37 // 5. 数据预取(Prefetch)
38 // 在计算开始前,先将第一批数据从GM搬运到UB
39 DataCopy(xLocal, xGm, TILE_LENGTH);
40 DataCopy(yLocal, yGm, TILE_LENGTH);
41
42 // 6. 主循环:处理所有Tile
43 for (int32_t i = 0; i < TILE_NUM; ++i) {
44 // 6.1 计算阶段
45 // 执行向量加法,结果存入zLocal
46 // 注意:此时使用的xLocal和yLocal是上一轮或预取阶段搬入的数据
47 Add(zLocal, xLocal, yLocal, TILE_LENGTH);
48
49 // 6.2 数据回写与预取(Overlap)
50 if (i < TILE_NUM - 1) {
51 // 将下一批输入数据从GM预取到UB
52 // 这里复用了xLocal和yLocal,因为它们在本轮计算后已不再需要
53 DataCopy(xLocal, xGm + (i + 1) * TILE_LENGTH, TILE_LENGTH);
54 DataCopy(yLocal, yGm + (i + 1) * TILE_LENGTH, TILE_LENGTH);
55 }
56
57 // 将本轮计算结果从UB写回GM
58 DataCopy(zGm + i * TILE_LENGTH, zLocal, TILE_LENGTH);
59 }
60}第三步:代码详解与关键点剖析
__global__ __aicore__: 这两个关键字至关重要。__global__表示这是一个可以从Host侧调用的Kernel入口;__aicore__则指明该Kernel将在AI Core上执行。GetBlockIdx(): 获取当前执行Block的唯一ID,用于数据分片。TPipe与InitBuffer:TPipe是Ascend C的灵魂之一。InitBuffer并非真的分配物理内存,而是向编译器声明该管道需要多少缓冲区来暂存数据描述符(Descriptor),从而实现高效的异步数据流管理。LocalTensor与QueInc:LocalTensor是对UB内存的抽象。QueInc是一个队列递增操作,它从指定的管道中“取出”一个数据槽位,并将其绑定到LocalTensor上。这种基于队列的模型天然支持流水线。- 计算与搬运重叠(Overlap): 这是高性能的关键。在主循环中,当Vector Unit在执行
Add计算时,MTE引擎可以并行地执行下一轮的DataCopy(预取)和上一轮的DataCopy(回写)。这种重叠极大地隐藏了Global Memory访问的高延迟。
第四步:编译、部署与验证
完成Kernel编写后,需要使用昇腾CANN提供的专用编译器(如aoe或atc)将其编译成.o目标文件或.json算子描述文件。然后,通过自定义算子注册机制将其集成到PyTorch或MindSpore等主流框架中。最后,编写Python测试脚本,使用随机数据验证算子功能的正确性,并通过Profiling工具(如msprof)分析其性能瓶颈。
四、性能优化初探:Tile Size的选择
在上面的例子中,我们硬编码了TILE_LENGTH = 128。这个值并非随意选择,而是经过深思熟虑的。
- UB容量限制:AI Core的UB容量有限(例如,昇腾910B的UB约为2MB)。
TILE_LENGTH必须保证所有参与计算的LocalTensor(xLocal, yLocal, zLocal)的总大小不超过UB容量。 - 计算单元吞吐:Vector Unit有固定的计算吞吐率(例如,每个周期可以处理128个float32数据)。选择128作为Tile Size,可以完美匹配硬件的计算粒度,避免资源浪费。
- 搬运效率:MTE引擎在搬运连续的大块数据时效率最高。过小的Tile会导致频繁的启动开销;过大的Tile则可能超出UB容量或导致流水线阻塞。
因此,TILE_LENGTH 的选择是一个在内存占用、计算效率和搬运效率之间寻找最佳平衡点的过程。这也是Ascend C开发者需要不断实践和调优的核心技能。
五、总结与展望
通过实现一个简单的Vector Add算子,我们初步领略了Ascend C的强大与精妙。它通过GlobalTensor/LocalTensor、TPipe、DataCopy、Add等核心抽象,将复杂的硬件并行性和内存层次结构封装成了直观的编程接口。
然而,这仅仅是冰山一角。真实的AI算子(如Conv2D, MatMul)远比Vector Add复杂,它们需要更精细的数据排布(tiling strategy)、更复杂的计算调度(fusion)以及对Cube Unit的充分利用。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)