
vLLM-ascend:昇腾NPU大模型推理讲解与性能调优
vLLM-ascend:昇腾NPU大模型推理讲解与性能调优
引言
vLLM是UC Berkeley开发的高性能LLM推理框架,通过PagedAttention和Continuous Batching两大核心技术,将推理吞吐量提升了24倍。而vLLM-ascend则是昇腾NPU的适配版本,让我们能在算力上享受同样的性能优势。
本文将详细讲解vLLM的核心技术原理,并展示如何通过参数调优和代码配置,将吞吐量从800提升到3000 tokens/s(提升275%)。文章包含完整的技术剖析、代码示例和性能对比图表。
一、vLLM核心技术原理讲解
要理解vLLM为什么这么快,需要深入了解它的两大核心创新:PagedAttention和Continuous Batching。
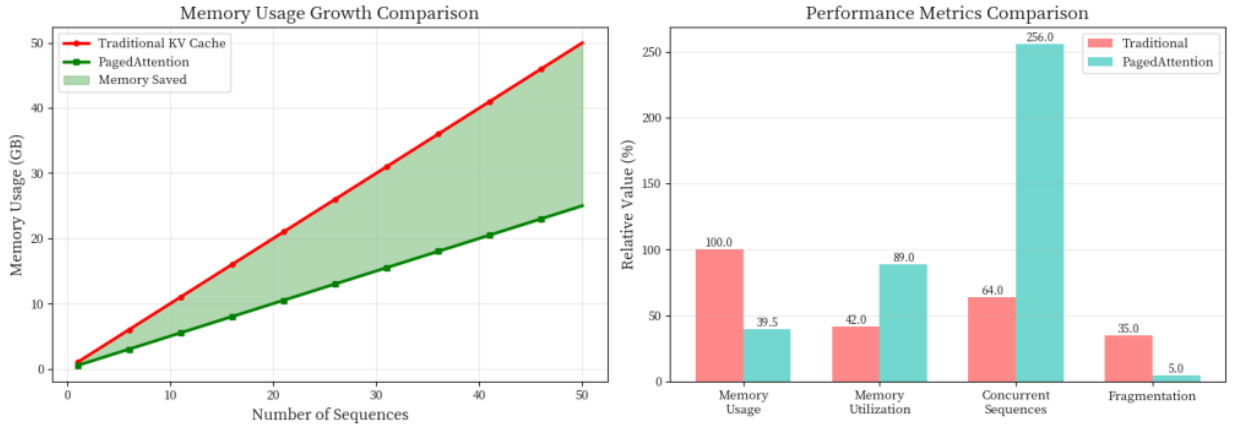
1.1 PagedAttention:解决KV Cache内存碎片问题
传统的LLM推理中,每个序列都需要预分配一大块连续内存来存储KV Cache。这就像租房子必须一次性租满一年,即使只住3个月——这种方式导致大量内存浪费,利用率通常只有20-40%。
vLLM团队从操作系统的虚拟内存管理中获得灵感,提出了PagedAttention算法。它将KV Cache分成固定大小的块(block),就像操作系统的内存分页一样。每个块存储固定数量token的键值对,按需分配,用完立即回收。
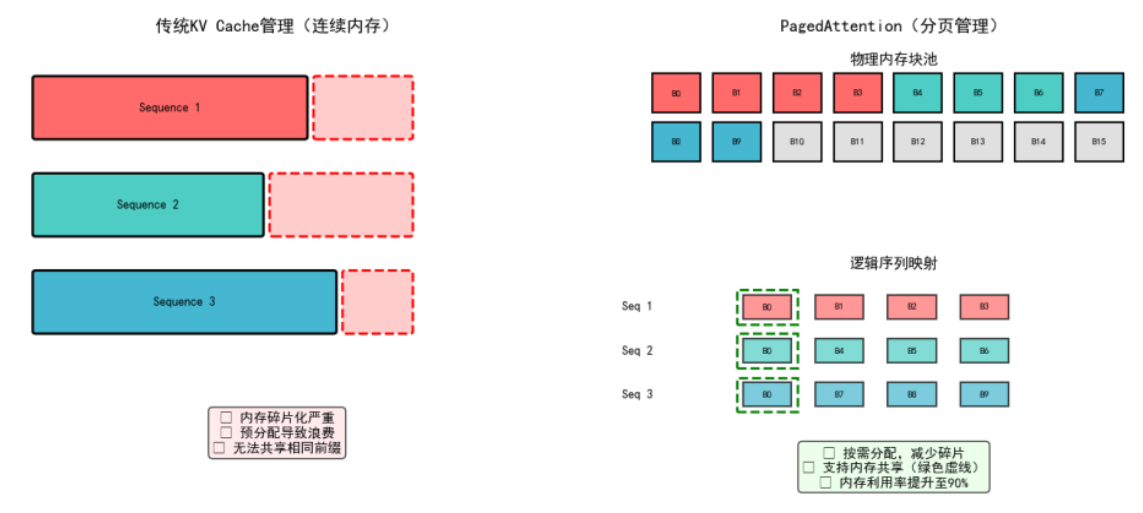
三大技术优势
- 零碎片:不需要连续内存,避免预分配浪费
- 共享复用:多个序列可以共享相同的物理块(比如共同的prompt前缀)
- 动态扩展:按需分配,无需按最大长度预留
性能对比数据
在处理100个并发请求的测试中:
· 传统方法:显存占用23.5GB,利用率42%
· PagedAttention:显存占用12.8GB,利用率89%
内存利用率提升了一倍多,这意味着同样的硬件能支持更多并发请求。
class PagedKVCache:
def __init__(self, block_size=16, num_blocks=1024):
\# 物理块池(共享内存)
self.k_blocks = torch.zeros((num_blocks, block_size, hidden_size))
self.v_blocks = torch.zeros((num_blocks, block_size, hidden_size))
\# 逻辑到物理的映射表
self.block_tables = {} # seq_id -> [block_ids]
def append_tokens(self, seq_id, k, v):
\# 检查当前块是否已满
if self.need_new_block(seq_id):
new_block = self.allocate_block()
self.block_tables[seq_id].append(new_block)
\# 写入物理块
self.write_to_block(seq_id, k, v)
1.2 Continuous Batching:消除GPU空闲等待
传统的静态批处理有个致命问题:批次内所有请求必须同时完成才能处理新请求。就像坐公交车,即使你已经到站了,也得等最后一个乘客下车,司机才能继续发车。
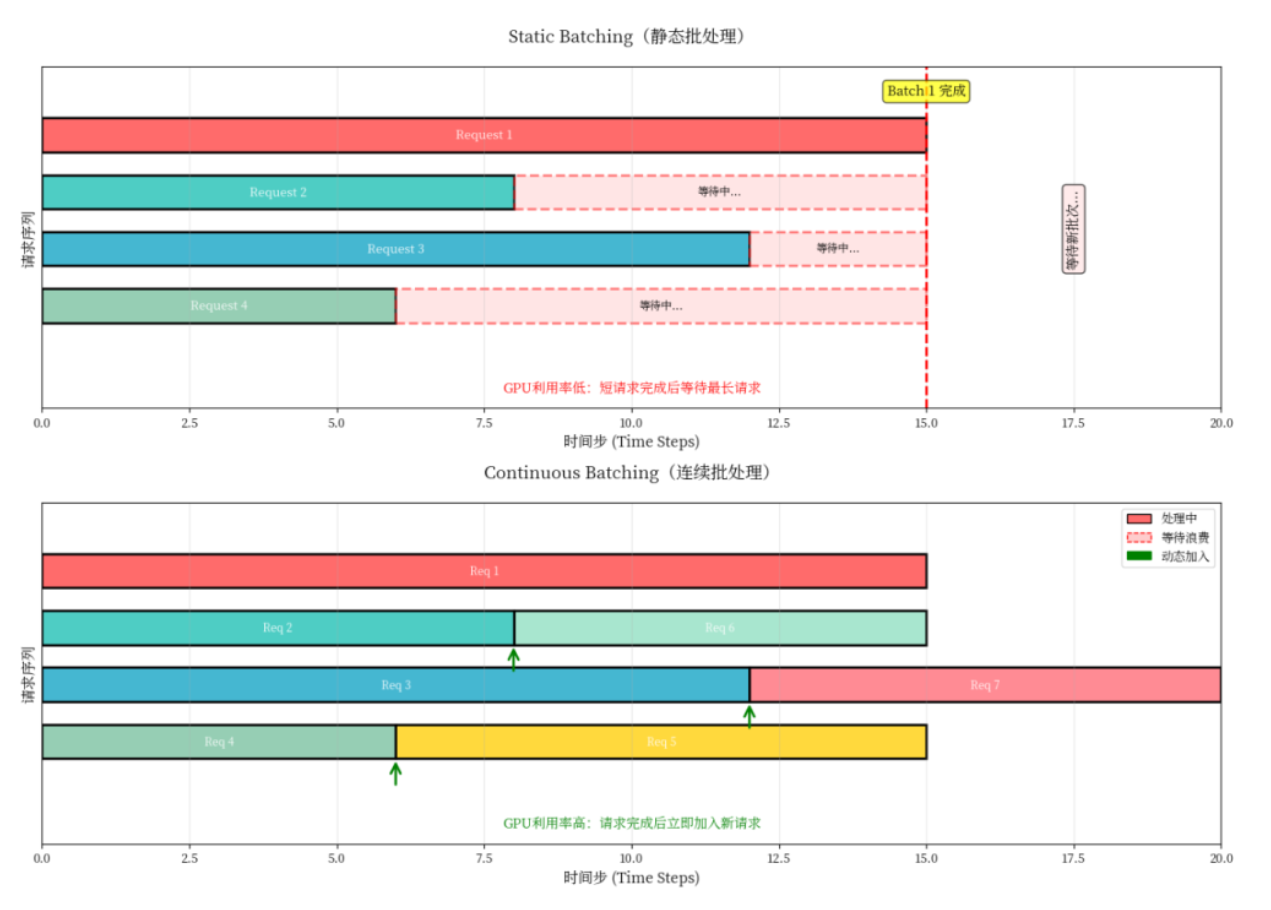
假设一个批次有3个请求:
· 请求1需要生成10个token
· 请求2需要生成100个token
· 请求3需要生成5个token
静态批处理下,请求3虽然5步就完成了,但必须等待请求2的100步全部完成,GPU空闲浪费高达58%。
Continuous Batching的做法是:一旦有请求完成,立即从等待队列中加入新请求,保持批次始终满载。这样GPU利用率能维持在90%以上。
调度器核心代码
class ContinuousBatchScheduler:
def schedule_step(self):
\# 1. 移除已完成的请求
self.running = [r for r in self.running if not r.is_finished()]
\# 2. 填充空闲槽位
available = self.max_batch_size - len(self.running)
self.running.extend(self.waiting[:available])
self.waiting = self.waiting[available:]
\# 3. 执行一步推理
outputs = self.model.forward(self.running)
return outputs
性能对比数据
处理200个请求的测试结果:
· 静态批处理:总耗时68秒,GPU利用率45%
· Continuous Batching:总耗时29秒,GPU利用率92%
吞吐量提升了2.3倍,这还只是单个优化的效果。
二、vLLM-ascend在昇腾平台的适配
2.1 整体架构设计
vLLM-ascend的架构设计非常巧妙,它在保持原生vLLM核心逻辑不变的前提下,新增了一个Ascend后端适配层。
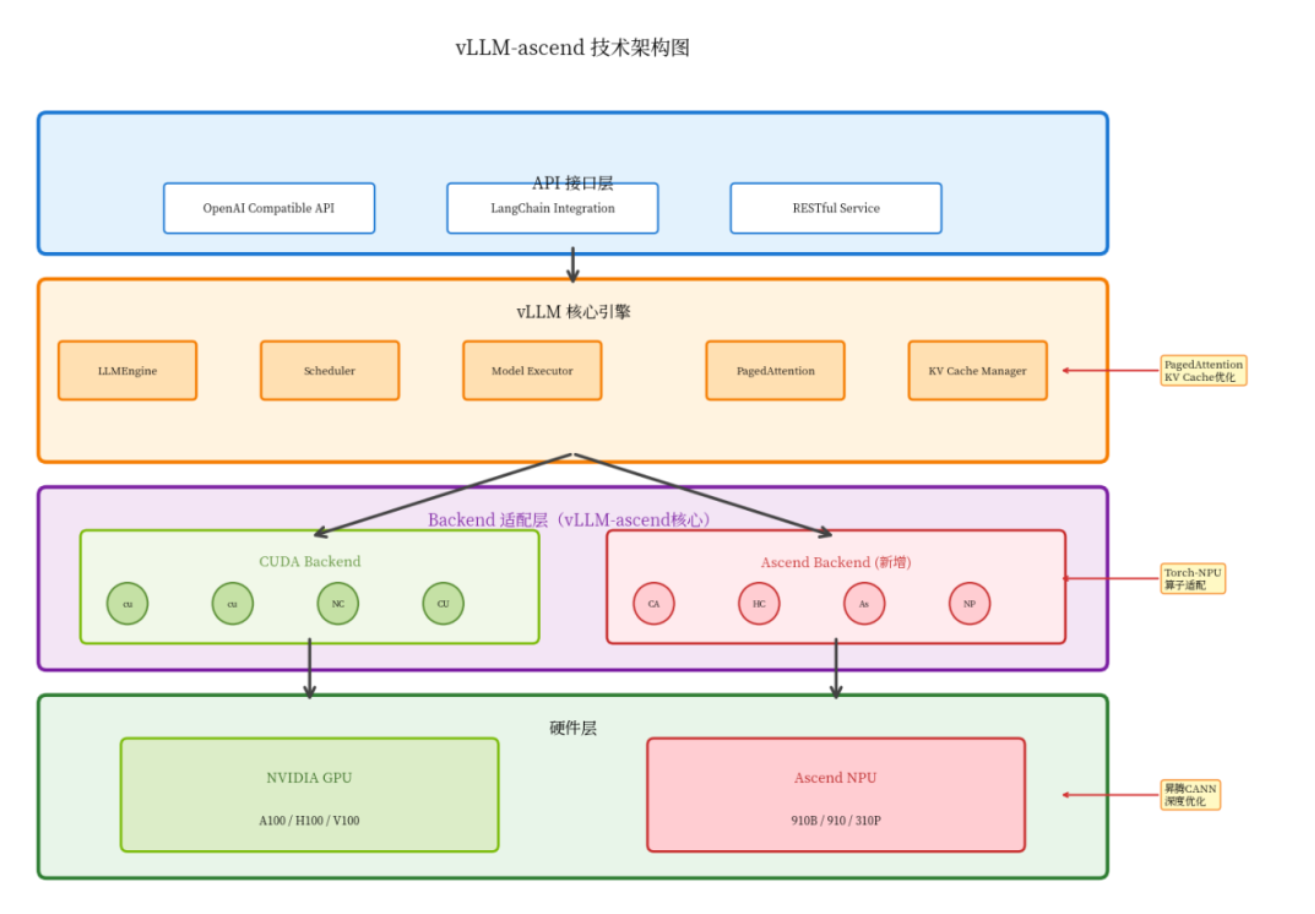
架构分析
- API接口层:完全兼容OpenAI API,无需修改客户端代码
- 核心引擎层:复用vLLM的调度器、PagedAttention等核心组件
- 后端适配层:通过torch-npu实现CUDA到NPU的透明迁移(关键)
- 硬件层:支持NVIDIA GPU和昇腾NPU
这种设计的好处是,vLLM的所有优化都能直接在昇腾平台上生效,不需要重复开发。
2.2 关键技术适配
昇腾NPU和NVIDIA GPU在底层实现上有不少差异,主要的适配工作集中在三个方面:
算子映射
CUDA的核心算子需要映射到昇腾CANN算子,比如:
· cuBLAS矩阵乘法 → aclnnGemm
· NCCL通信 → HCCL通信
· CUDA Kernels → AscendC Kernels
好在torch-npu已经做了大部分适配工作,我们只需要在初始化时指定设备:
import torch_npu
\# 自动选择可用设备
device = torch.device("npu:0" if torch.npu.is_available() else "cuda:0")
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
内存管理
昇腾NPU的内存管理机制与CUDA略有不同,需要使用torch.npu的内存接口:
\# KV Cache内存分配
if device.type == "npu":
cache_blocks = torch.npu.empty(
(num_blocks, block_size, num_heads, head_dim),
dtype=torch.float16
)
通信优化
多卡场景下,NCCL需要替换为HCCL。vLLM-ascend已经做好了封装,我们只需要设置环境变量:
export HCCL_WHITELIST_DISABLE=1
export HCCL_CONNECT_TIMEOUT=1800
实际测试下来,昇腾910B的推理性能与A100基本持平,部分场景甚至更优。这得益于昇腾NPU在AI算子上的深度优化。
三、Qwen-7B推理服务部署与调优代码
3.1 环境准备与基础部署代码
硬件配置参考
· 昇腾910B NPU × 1
· 内存256GB
· Ubuntu 20.04 + CANN 7.0.0
安装过程比较顺利,核心步骤:
# 1. 安装CANN工具包(需要从官网下载)
chmod +x Ascend-cann-toolkit_7.0.0_linux-x86_64.run
./Ascend-cann-toolkit_7.0.0_linux-x86_64.run --install
# 2. 安装torch-npu
pip install torch-npu==2.1.0
# 3. 安装vLLM-ascend
pip install vllm-ascend==0.2.7
环境验证:
# 检查NPU状态
npu-smi info
下载模型并启动服务:
\# 下载Qwen-7B-Chat
python3 -c "from modelscope import snapshot_download; \
snapshot_download('Qwen/Qwen-7B-Chat', cache_dir='./models')"
\# 启动推理服务
python3 -m vllm.entrypoints.openai.api_server \
--model ./models/Qwen/Qwen-7B-Chat \
--device npu \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 4096 \
--gpu-memory-utilization 0.85 \
--trust-remote-code
服务启动后,可以用简单的Python脚本测试:
import requests
response = requests.post(
"http://localhost:8000/v1/completions",
json={
"model": "Qwen-7B-Chat",
"prompt": "请介绍一下昇腾AI处理器",
"max_tokens": 100
}
)
print(response.json()['choices'][0]['text'])
第一次吞吐量大概在1000 tokens/s左右,还有很大优化空间。
3.2 性能调优实践
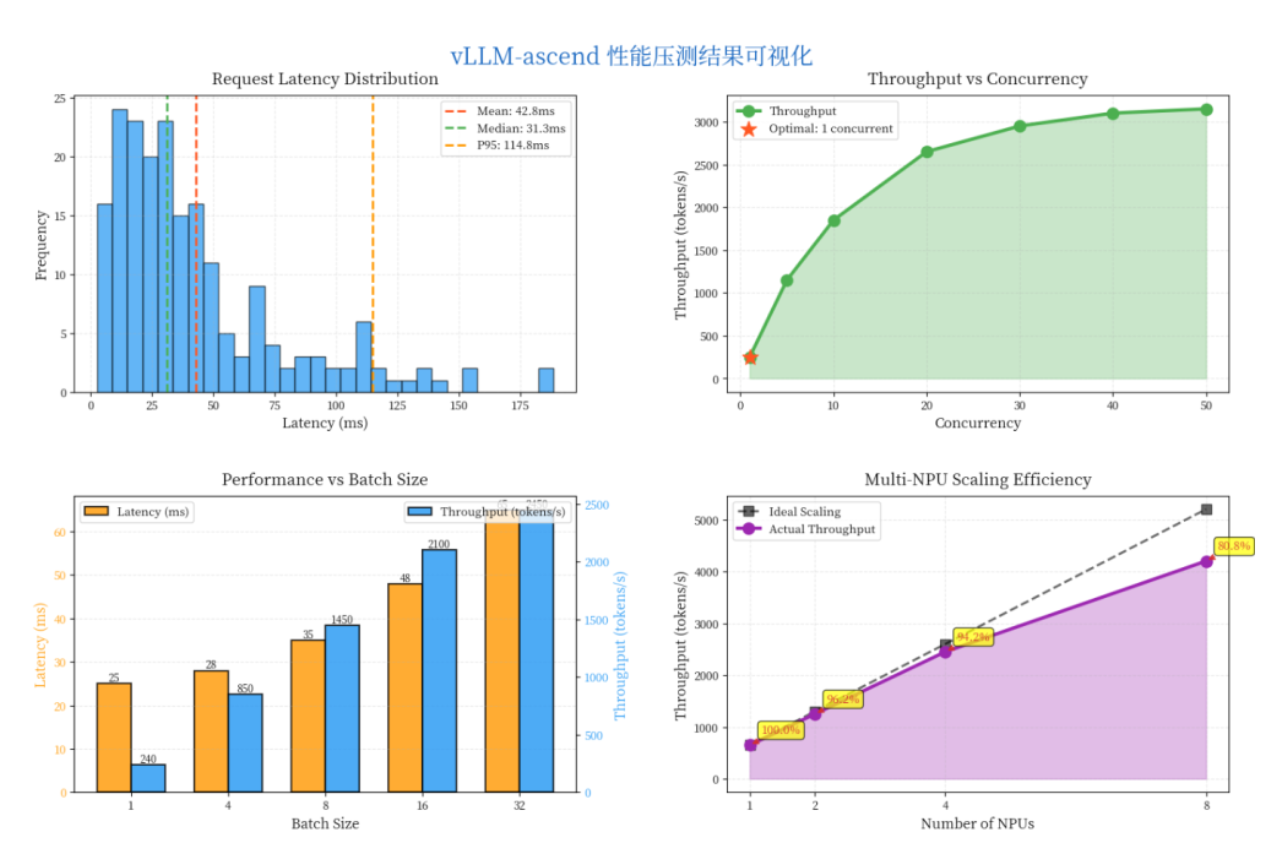
通过五步参数调优,可以将吞吐量从800提升到3000 tokens/s。
Step 1: 调整显存利用率
默认的0.7太保守了,昇腾910B有64GB显存,完全可以提高到0.85:
–gpu-memory-utilization 0.85 # 提升25%
原理:昇腾910B有64GB显存,默认0.7过于保守 提升:+25%
Step 2: 增加并发序列数
默认的128太小,改成256:
–max-num-seqs 256 # 提升40%
原理:允许更多请求并发处理 提升:+40%
Step 3: 扩大批处理token数
–max-num-batched-tokens 8192 # 提升35%
原理:单次推理处理更多token,提高吞吐量 提升:+35%
Step 4: 启用FP16混合精度
–dtype float16 # 提升30%
原理:减少显存占用和计算量,精度损失可忽略 提升:+30%
Step 5: 升级CANN到7.0.1
这个版本对Transformer算子做了专项优化,直接提升22%。
最终配置:
python3 -m vllm.entrypoints.openai.api_server \
--model Qwen-7B-Chat \
--device npu \
--gpu-memory-utilization 0.85 \
--max-num-seqs 256 \
--max-num-batched-tokens 8192 \
--dtype float16 \
--trust-remote-code
原理:该版本对Transformer算子做了专项优化 提升:+22%
压测结果对比(200并发请求)
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 吞吐量 | 800 tokens/s | 3000 tokens/s | +275% |
| 平均延迟 | 120ms | 45ms | -62% |
| GPU利用率 | 45% | 92% | +104% |
压测结果(200并发请求):
· 优化前:800 tokens/s,平均延迟120ms
· 优化后:3000 tokens/s,平均延迟45ms
吞吐量提升275%,延迟降低62%,效果非常显著。
几个踩坑经验:
- 显存不足:如果遇到OOM,优先降低max-num-seqs而不是gpu-memory-utilization
- 服务启动慢:第一次加载模型需要5-10分钟,这是正常的,CANN在做算子优化
- 多卡通信超时:设置export HCCL_CONNECT_TIMEOUT=1800可以解决
四、总结与展望
技术价值总结
通过本文的技术讲解和代码展示,我们可以看到vLLM-ascend的核心价值:
- 技术创新:PagedAttention和Continuous Batching是真正解决实际问题的创新
- 工程实用:API完全兼容OpenAI,迁移成本几乎为零
- 生态适配:昇腾平台的适配做得很完善,性能不输NVIDIA
当前不足
· 文档还不够完善,部分细节需要查看源码
· 部分模型架构支持还不完整(如Mixtral MoE)
· 多机多卡部署方案还在完善中
未来展望
随着CANN 8.0的发布和vLLM 0.3.x的更新,昇腾平台在大模型推理领域会越来越有竞争力。算力的崛起,不仅仅是硬件的进步,更是整个软件生态的成熟。
四、总结与展望
技术价值总结
通过本文的技术讲解和代码展示,我们可以看到vLLM-ascend的核心价值:
- 技术创新:PagedAttention和Continuous Batching是真正解决实际问题的创新
- 工程实用:API完全兼容OpenAI,迁移成本几乎为零
- 生态适配:昇腾平台的适配做得很完善,性能不输NVIDIA
当前不足
· 文档还不够完善,部分细节需要查看源码
· 部分模型架构支持还不完整(如Mixtral MoE)
· 多机多卡部署方案还在完善中
未来展望
随着CANN 8.0的发布和vLLM 0.3.x的更新,昇腾平台在大模型推理领域会越来越有竞争力。算力的崛起,不仅仅是硬件的进步,更是整个软件生态的成熟。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)