
前馈神经网络(FNN)概述
本文介绍了前馈神经网络(FNN)的基本概念及其应用。FNN由输入层、隐藏层和输出层组成,核心组件包括单层感知器、激活函数(如ReLU、Sigmoid)和训练法则(如梯度下降)。文章详细阐述了权重初始化、损失函数、优化算法等关键技术,并提供了避免过拟合的策略(L2正则化、Dropout等)。最后以MNIST手写数字识别为例,展示了使用PyTorch实现FNN的完整代码流程,包括数据预处理、模型定义、
Feedforward Neural Network(前馈神经网络)在 1986 年由 Rumelhart、Hinton 和 Williams 在论文《Learning representations by back-propagating errors》中系统提出并普及。
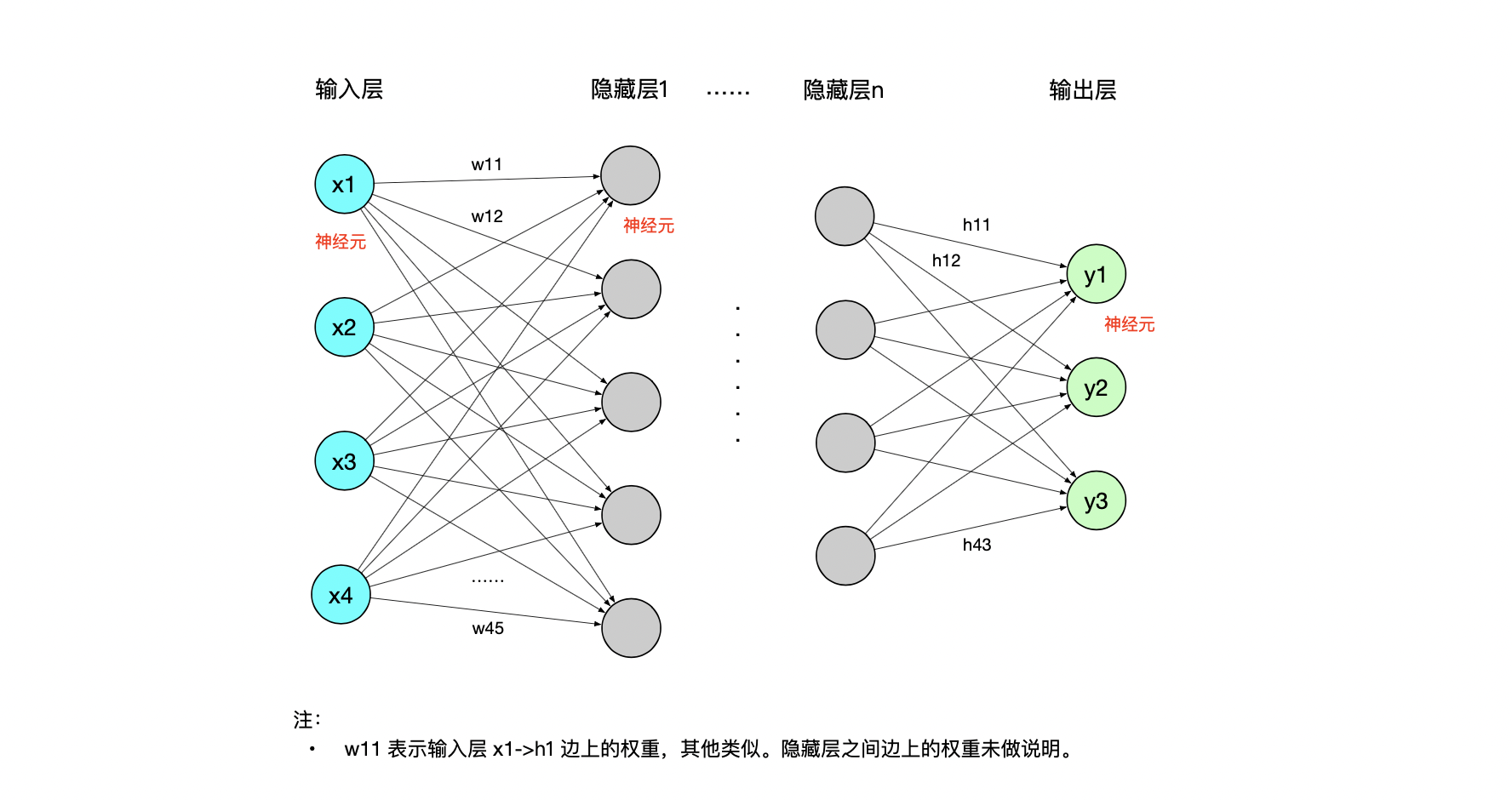
上图是前馈神经网络(也称为多层感知器,multilayer perceptrons,简写MLP)示意图,由三个主要部分组成:
-
输入层: 负责接收原始数据,“输入层神经元”数量对应于样本数据特征的维度。
-
隐藏层: 包含一个或多个层,每层由多个“隐藏层神经元”组成,用于提取输入数据的抽象(中间)特征。
-
输出层: 产生网络的最终预测或分类结果。
下面针对FNN涉及的核心组件简要说明:
1)单层感知器
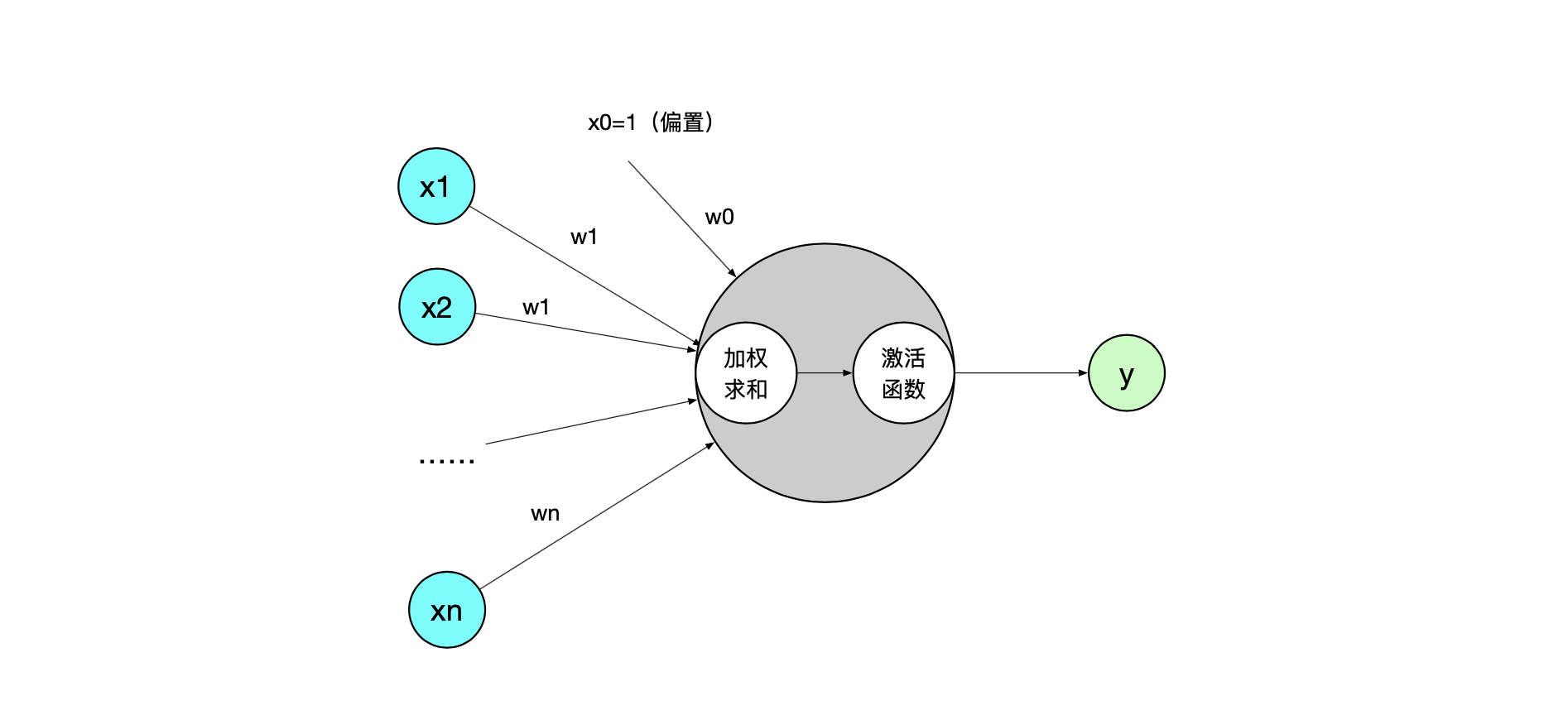
前馈神经网络又称为多层感知器,先拆解一下单层感知器,它是最简单的神经网络模型,由输入层、权重、偏置、加权和、激活函数、输出组成。在 FNN 中每个隐藏层单元自身都是一个感知器。如下图示:
2)激活函数
| 激活函数 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Sigmoid | 输出在(0,1)区间,可解释为概率 | 梯度饱和严重、输出非零中心、计算慢 | 早期神经网络,较少用于现代FNN |
| Tanh | 输出在(-1,1)区间,以0为中心 | 输入很大/很小时梯度小 | 早期网络,较少用于现代FNN |
| ReLU | 无梯度饱和(正输入)、计算快 | 负输入时"死亡"、输出非零中心 | FNN隐藏层首选 |
| Leaky ReLU/PReLU | 负输入有小输出,避免"死亡" | 参数需调整 | ReLU的改进,适用于FNN隐藏层 |
| ELU | 负输入有小输出,抗干扰能力强 | 计算复杂(指数运算) | FNN隐藏层的替代选择 |
注:大模型总结。
3) 训练法则
FNN 训练的核心目标是学习网络中的权重和偏置,可视样本特性选择不同的训练法则:
-
样本线性可分:感知器法则,如下:

-
样本非线性可分:采用 delta 法则,该法则使用梯度下降搜索可能的权向量的假设空间,以找到最佳拟合训练样例的权向量。同时通过链式法则,从输出层向输入层逐层计算损失函数等)对权重和偏置的梯度。
附 FNN 常见的函数如下:
-
权重初始化方法:零初始化、随机初始化、Xavier/Glorot初始化等。
-
损失函数:均方误差MSE、交叉熵损失等。
-
优化算法:随机梯度下降(SGD,最基础的算法)、AdaGrad(自适应学习率)、Adam(FNN的默认训练优化器)等。
4)避免过拟合策略
-
L2正则化:通过在损失函数中添加权重的平方和,限制模型参数的大小,防止模型过度拟合训练数据。
-
Dropout:在训练过程中随机"丢弃"一部分神经元,减少神经元之间的相互依赖,从而提高模型的泛化能力。
-
早停:在训练过程中监控验证集的性能,当验证集性能不再提升时提前终止训练,防止模型过拟合。
5)Transformer 中 FNN 的应用
在 Transformer 中,FNN 是一个特定的两层前馈神经网络,其中第一层:d_model × d_ff,第二层:d_ff × d_model),且满足:d_ff = 4 × d_model,其中
-
d_ff 表示 FNN 的隐藏层维度
-
d_model 表示输入/输出的维度
另外 FNN 使用了 GELU 激活函数、Adam 优化算法(学习率 0.0001)、交叉熵损失函数和 Dropout 过拟合策略。
6)FNN 代码示例
该示例使用 MNIST 数据集作为训练数据,定义了 FNN 训练模型,其中输入层784个节点;隐藏层有256个节点,并使用 ReLU 激活;输出层有10个节点(10个数字类别);其中:
-
激活函数:ReLU
-
优化算法:Adam
-
损失函数:交叉熵损失函数。即 pythorch 中的 CrossEntropyLoss 函数,该函数是深度学习中多分类的标准损失函数,实现层面上将 Softmax (即计算 Softmax 的对数,为了预测数值稳定和避免数值溢出)和 NLLLoss (计算负对数似然)合并为一步。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
# 设置随机种子确保可复现性
torch.manual_seed(42)
# =====================
# 1. 数据预处理
# =====================
# 定义数据转换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST的均值和标准差
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 划分训练集和验证集 (80%训练, 20%验证)
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
# 创建DataLoader
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
print(f"训练集大小: {len(train_dataset)}, 验证集大小: {len(val_dataset)}, 测试集大小: {len(test_dataset)}")
# =====================
# 2. 定义前馈神经网络
# =====================
class FeedForwardNN(nn.Module):
def __init__(self, input_size=784, hidden_size=256, num_classes=10):
super(FeedForwardNN, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 初始化模型
model = FeedForwardNN()
print(model)
# =====================
# 3. 训练配置
# =====================
criterion = nn.CrossEntropyLoss() # 多分类损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器,负责根据损失梯度更新模型参数(权重和偏置)
num_epochs = 10 # 模型遍历整个训练集的次数
# =====================
# 4. 训练与验证
# =====================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
best_val_acc = 0.0
for epoch in range(num_epochs):
# 训练阶段
model.train()
train_loss = 0.0
correct_train = 0
total_train = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 交叉熵损失
# 反向传播和优化
optimizer.zero_grad() # 清零梯度
loss.backward() # 计算梯度
optimizer.step() # Adam 更新权重
# 计算损失和准确率
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
train_acc = 100 * correct_train / total_train
# 验证阶段
model.eval()
val_loss = 0.0
correct_val = 0
total_val = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).sum().item()
val_acc = 100 * correct_val / total_val
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), 'best_model.pth')
print(f"新最佳模型保存! 验证准确率: {val_acc:.2f}%")
# 打印训练日志
print(f'Epoch [{epoch + 1}/{num_epochs}], '
f'Train Loss: {train_loss / len(train_loader):.4f}, '
f'Train Acc: {train_acc:.2f}%, '
f'Val Loss: {val_loss / len(val_loader):.4f}, '
f'Val Acc: {val_acc:.2f}%')
print("训练完成!")
# =====================
# 5. 最终测试
# =====================
model.load_state_dict(torch.load('best_model.pth'))
model.eval()
test_loss = 0.0
correct_test = 0
total_test = 0
with torch.no_grad(): # 禁用梯度计算
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_test += labels.size(0)
correct_test += (predicted == labels).sum().item()
test_acc = 100 * correct_test / total_test
print(f'\n最终测试准确率: {test_acc:.2f}% (最佳验证模型)')
# =====================
# 6. 模型预测示例
# =====================
def predict_image(model, image):
"""预测单张图像的类别"""
model.eval() # 将模型切换到评估模式
with torch.no_grad(): # 禁用梯度计算
image = image.unsqueeze(0).to(device) # 添加batch维度
output = model(image)
_, predicted = torch.max(output, 1)
return predicted.item()
# 从测试集中取一张图片测试
test_image, test_label = test_dataset[0]
print(f"\n预测示例: 输入图像标签 = {test_label}, 预测结果 = {predict_image(model, test_image)}")附
-
数据说明:MNIST 数据集(Modified National Institute of Standards and Technology,修改后的美国国家标准与技术研究院)是一个包含大量手写数字的大型数据集。用于图像分类中的手写数字识别任务。它来源于 NIST 的原始手写数字库。
-
运行环境:Pycharm、python3

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)